DataWorks のデータ統合は、異なるデータソース間で低レイテンシかつ高スループットのデータレプリケーションを実現する、リアルタイムの単一テーブル同期タスクを提供します。この機能は、高度なリアルタイムコンピューティングエンジン上で実行され、ソースでのデータ変更 (挿入、削除、更新) をキャプチャし、宛先に適用します。このトピックでは、Kafka から MaxCompute への同期を例に、設定プロセスを説明します。
前提条件
データソースの準備
ソースと宛先のデータソースを作成します。詳細については、「データソース管理」をご参照ください。
データソースがリアルタイム同期をサポートしていることを確認してください。詳細については、「サポートされているデータソースと同期ソリューション」をご参照ください。
Hologres や Oracle などの一部のデータソースでは、ログの有効化が必要です。ログを有効にする方法はデータソースによって異なります。詳細については、「データソースリスト」をご参照ください。
リソースグループ:Serverless リソースグループを購入し、設定します。
ネットワーク接続:リソースグループとデータソース間のネットワーク接続設定を完了します。
ステップ 1:同期タスクの作成
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、データ統合へ をクリックします。
左側のナビゲーションウィンドウで [同期タスク] をクリックします。ページの上部で [同期タスクの作成] をクリックし、タスクパラメーターを設定します。このトピックでは、Kafka から MaxCompute へデータを同期する例を使用します。
[ソースタイプ]:
Kafka。[宛先タイプ]:
MaxCompute。[タスクタイプ]:
単一テーブルリアルタイム。Synchronization Mode:
Schema Migration:ソースに一致するデータベースオブジェクト (テーブル、フィールド、データ型など) を宛先に自動的に作成しますが、データは含まれません。
Incremental Sync (オプション):フル同期が完了した後、このステップではソースからのデータ変更 (挿入、更新、削除) を継続的にキャプチャし、宛先に同期します。
ソースが Hologres の場合、フル同期もサポートされます。これは、既存のデータがまず宛先テーブルに完全に同期され、その後、自動的に増分同期が行われることを意味します。
サポートされているデータソースと同期ソリューションの詳細については、「サポートされているデータソースと同期ソリューション」をご参照ください。
ステップ 2:データソースと実行リソースの設定
Source Information で、設定済みの
Kafkaデータソースを選択します。Destination で、設定済みのMaxComputeデータソースを選択します。Running Resources セクションで、同期タスクの Resource Group を選択し、タスクに Resource Group CU を割り当てます。フル同期と増分同期に CU を個別に設定して、リソースを正確に制御し、無駄を防ぐことができます。リソース不足により同期タスクでメモリ不足 (OOM) エラーが発生した場合は、リソースグループの CU 値を増やしてください。
ソースと宛先の両方のデータソースが Connectivity Check に合格することを確認してください。
ステップ 3:同期計画の設定
1. ソースの設定
Configuration タブで、同期したい Kafka データソース内のトピックを選択します。
他の設定にはデフォルト値を使用するか、必要に応じて変更できます。パラメーターの詳細については、Kafka の公式ドキュメントをご参照ください。
右上隅の Data Sampling をクリックします。
表示されるダイアログボックスで、Start time と Sampled Data Records を指定し、Start Collection をクリックします。これにより、指定された Kafka トピックからデータがサンプリングされ、データをプレビューできます。これは、後続のデータ処理ノードでのデータプレビューとビジュアル設定の入力となります。
Configure Output Field タブで、同期したいフィールドを選択します。
デフォルトでは、Kafka は 6 つのフィールドを提供します。
パラメーター
説明
__key__
Kafka レコードのキー。
__value__
Kafka レコードの値。
__partition__
Kafka レコードが配置されているパーティション番号。パーティション番号は 0 から始まる整数です。
__headers__
Kafka レコードのヘッダー。
__offset__
パーティション内での Kafka レコードのオフセット。オフセットは 0 から始まる整数です。
__timestamp__
Kafka レコードの 13 桁の整数ミリ秒タイムスタンプ。
データ処理ノードでこれらのフィールドに対してさらに変換を実行することもできます。
2. データ処理
Data Processing を有効にします。利用可能なデータ処理メソッドは、データマスキング、文字列置換、データフィルタリング、JSON パース、フィールドの編集と割り当て の 5 つです。これらのステップは任意の順序で配置できます。実行時、処理ステップは指定された順序で実行されます。

各データ処理ノードを設定した後、右上隅の Preview Data Output をクリックします。
入力データの下のテーブルには、Data Sampling ステップの結果が表示されます。Re-obtain Output of Ancestor Node をクリックして結果を更新できます。
上位ノードの出力がない場合は、Manually Construct Data を使用して、先行する出力をシミュレートできます。
Preview をクリックして、データ処理コンポーネントによって処理された後の上位ステージからの出力を表示します。

データ出力のプレビューとデータ処理は、Kafka ソースからの Data Sampling に強く依存します。データ処理を設定する前に、まず Kafka ソース設定でデータサンプリングを完了する必要があります。
3. 宛先の設定
Destination エリアで、トンネルリソースグループを選択します。デフォルトでは、「パブリック転送リソース」が選択されており、これは MaxCompute の無料クォータを指します。
新しいテーブルに書き込むか、既存のテーブルに書き込むかを選択します。Create または [既存のテーブルを使用] を選択します。
新しいテーブルを作成することを選択した場合、デフォルトでソースと同じスキーマを持つテーブルが作成されます。宛先テーブル名とスキーマは手動で変更できます。
既存のテーブルを使用することを選択した場合、ドロップダウンリストからターゲットテーブルを選択します。
(オプション) テーブルスキーマを編集します。
テーブル名の横にある編集アイコンをクリックして、テーブルスキーマを編集します。Re-generate Table Schema Based on Output Column of Ancestor Node をクリックすると、上位ノードの出力列に基づいてスキーマが自動的に生成されます。その後、自動生成されたスキーマ内のフィールドを選択してプライマリーキーにすることができます。
4. フィールドマッピングの設定
ソースと宛先を選択した後、ソースフィールドと宛先フィールド間のマッピングを指定する必要があります。タスクは、フィールドマッピングに基づいて、ソースフィールドから対応する宛先フィールドにデータを書き込みます。
システムは、[同名マッピング] ルールに基づいて、上位ノードのフィールドとターゲットテーブルのフィールド間のマッピングを自動的に生成します。必要に応じてマッピングを調整できます。1 つの上位ノードのフィールドを複数のターゲットテーブルのフィールドにマッピングできますが、複数の上位ノードのフィールドを 1 つのターゲットテーブルのフィールドにマッピングすることはできません。上位ノードのフィールドがターゲットテーブルの列にマッピングされていない場合、そのフィールドのデータはターゲットテーブルに書き込まれません。
Kafka フィールドに対してカスタムの JSON パースを設定できます。データ処理コンポーネントを使用して value フィールドのコンテンツを抽出し、より詳細なフィールド設定を行います。

パーティションの設定 (オプション)。
時間ベースの自動パーティション分割は、ビジネス時間フィールド (この場合は
__timestamp__) に基づいてパーティションを作成します。第 1 レベルのパーティションは年、第 2 レベルは月、というようになります。フィールドコンテンツによる動的パーティション分割は、ソースフィールドとターゲットパーティションフィールド間のマッピングを定義することにより、指定されたソースフィールドのデータ行を MaxCompute テーブルの対応するパーティションに書き込みます。
ステップ 4:詳細パラメーターの設定
同期タスクでは、詳細な設定を行うための詳細パラメーターが提供されています。システムはデフォルト値を提供しており、通常は変更する必要はありません。必要な場合は、次の手順に従ってください:
インターフェイスの右上隅にある Advanced Settings をクリックして、Advanced Parameters 設定ページに移動します。
説明データ開発の詳細パラメーターは、タスク設定インターフェイスの右側のタブにあります。
同期タスクの reader と writer のパラメーターを個別に設定できます。[ランタイム設定] をカスタマイズするには、[ランタイム設定の自動設定] を false に設定します。
ツールチップと説明に基づいてパラメーター値を変更します。一部のパラメーターの設定に関する推奨事項については、「リアルタイム同期の詳細パラメーター」をご参照ください。
予期しないエラーやデータ品質の問題を避けるため、これらのパラメーターの目的と結果を完全に理解している場合にのみ変更してください。
ステップ 5:テスト実行
すべてのタスク設定が完了したら、左下隅の Perform Simulated Running をクリックしてタスクをデバッグします。これにより、タスク全体の処理が少量のサンプルデータでシミュレートされ、ターゲットテーブルの結果のプレビューを表示できます。設定エラー、テスト実行中の例外、またはダーティデータがある場合、システムはリアルタイムでフィードバックを提供します。これにより、タスク設定の正しさを迅速に評価し、期待される結果が得られるかどうかを判断できます。
表示されるダイアログボックスで、サンプリングパラメーター (Start time と Sampled Data Records) を設定します。
Start Collection をクリックしてサンプルデータを取得します。
[Preview Result] をクリックして、タスクの実行をシミュレートし、出力結果を表示します。
テスト実行の出力はプレビュー専用であり、宛先のデータソースには書き込まれません。本番データには影響しません。
ステップ 6:タスクの公開と実行
すべての設定が完了したら、ページ下部の Save をクリックします。
データ統合タスクは、実行するために本番環境に公開する必要があります。したがって、新しいタスクを作成する場合でも、既存のタスクを編集する場合でも、変更を有効にするには Deploy 操作を実行する必要があります。公開中に Start immediately after deployment を選択すると、タスクは公開後に自動的に開始されます。それ以外の場合は、公開後、 ページに移動し、[操作] 列からタスクを手動で開始する必要があります。
Tasks で、対応するタスクの Name/ID をクリックして、詳細な実行プロセスを表示します。
ステップ 7:アラートルールの設定
タスクが公開されて実行された後、そのタスクのアラートルールを設定できます。これにより、例外が発生した場合にすぐに通知を受け取ることができ、本番環境の安定性と適時性を確保できます。データ統合タスクリストで、ターゲットタスクの [操作] 列にある をクリックします。
1. アラートルールの追加
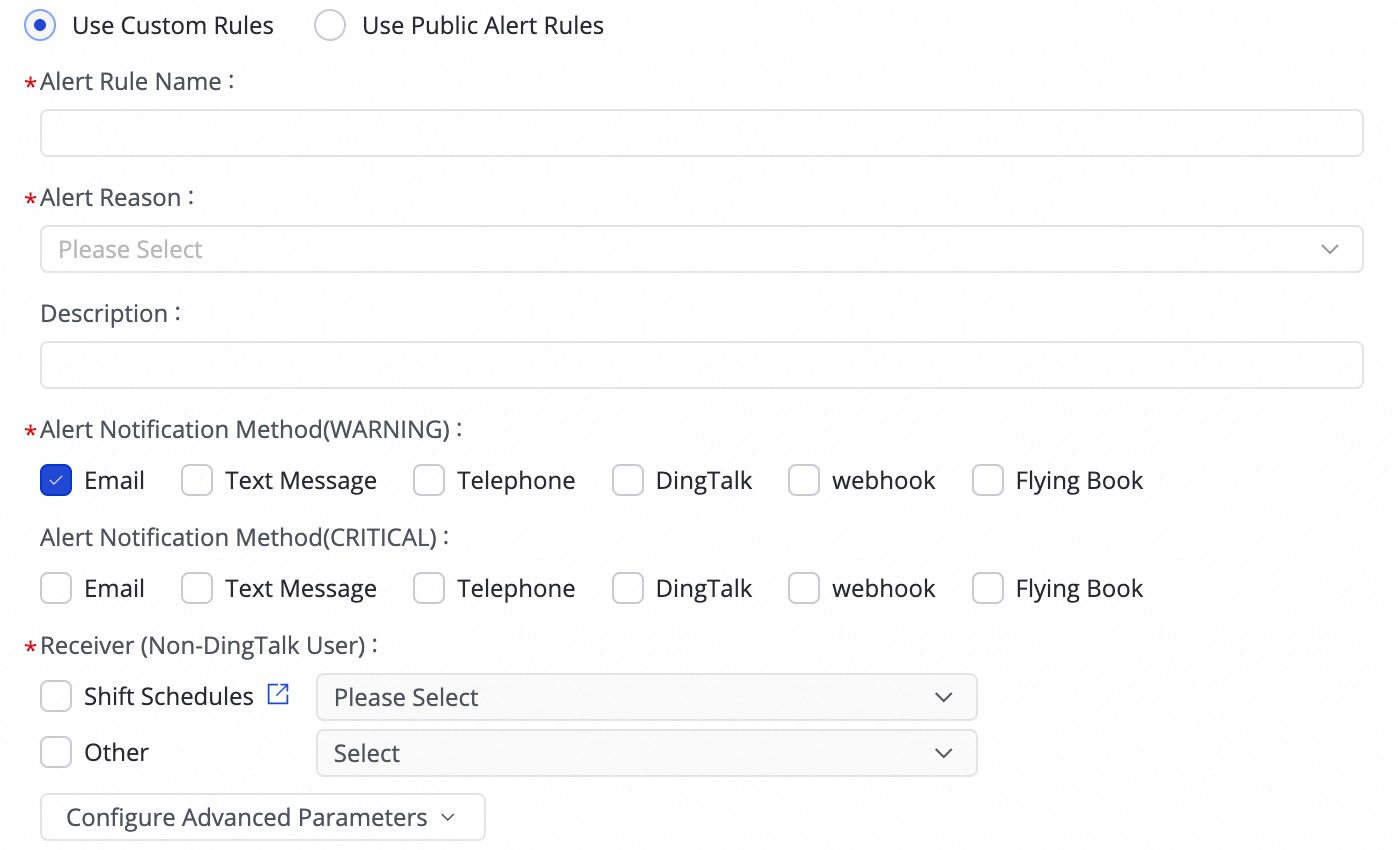
(1) Create Rule をクリックしてアラートルールを設定します。
Alert Reason を設定することで、Business delay、[フェイルオーバー]、Task status、DDL Notification、Task Resource Utilization などのメトリックをモニターできます。指定されたしきい値に基づいて、CRITICAL または WARNING レベルのアラートを設定できます。
アラートメソッドを設定した後、Configure Advanced Parameters を使用して、アラートメッセージの送信間隔を制御できます。これにより、過剰な通知による無駄やバックログの発生を防ぎます。
アラート条件が Business delay、Task status、または Task Resource Utilization に設定されている場合、タスクが正常状態に戻ったときに受信者に通知する回復通知を有効化することもできます。
(2) アラートルールの管理
作成されたアラートルールについては、アラートスイッチを使用して有効または無効にできます。また、アラートレベルに基づいて異なる担当者にアラートを送信することもできます。
2. アラートの表示
タスクリストで、 をクリックし、[アラートイベント] タブに移動して、トリガーされたアラートの履歴を表示します。
次のステップ
タスクが開始された後、タスク名をクリックして、タスクの運用、メンテナンス、最適化に関する実行詳細を表示できます。
よくある質問
リアルタイム同期タスクに関するよくある質問については、「リアルタイム同期に関するよくある質問」をご参照ください。
その他の例
Kafka から ApsaraDB for OceanBase への単一テーブルのリアルタイム同期
Log Service (SLS) から Data Lake Formation への単一テーブルのリアルタイム取り込み
Hologres から Doris への単一テーブルのリアルタイム同期
Hologres から Hologres への単一テーブルのリアルタイム同期
Kafka から Hologres への単一テーブルのリアルタイム同期
Log Service (SLS) から Hologres への単一テーブルのリアルタイム同期
Kafka から Hologres への単一テーブルのリアルタイム同期
Hologres から Kafka への単一テーブルのリアルタイム同期
Log Service (SLS) から MaxCompute への単一テーブルのリアルタイム同期
Kafka から OSS データレイクへの単一テーブルのリアルタイム同期