DataWorks では、個人開発環境でカスタムイメージを作成する際に、MaxCompute カスタムイメージを同時に生成できます。これにより、PyODPS 3 や Notebook ノードなどの DataWorks ノードで MaxCompute カスタムイメージを簡単に使用できます。このトピックでは、DataWorks で MaxCompute カスタムイメージをビルドして使用する方法について説明します。
背景情報
MaxCompute のイメージ管理機能を使用すると、カスタムイメージを作成できます。これらのイメージは、SQL UDF、PyODPS、MaxFrame 開発などのシナリオで直接参照できるため、複雑なリソースのパッケージングとアップロードは不要です。DataWorks では、個人開発環境から DataWorks イメージをビルドすると同時に MaxCompute イメージをビルドできます。
前提条件
新しいバージョンの Data Studio を使用するワークスペースを作成し、MaxCompute コンピューティングリソースをアタッチ済みであること。
Serverless リソースグループを作成し、ワークスペースに関連付け済みであること。
MaxCompute カスタムイメージの作成
事前準備
Alibaba Cloud Container Registry (ACR) を有効化し、Standard Edition 以上のバージョンの ACR インスタンスを作成済みであること。詳細については、「Enterprise 版インスタンスの作成」、「名前空間の作成」、および「イメージリポジトリの作成」をご参照ください。
Virtual Private Cloud (VPC) 経由での ACR インスタンスへのアクセス制御を設定済みであること。詳細については、「VPC のアクセス制御の設定」をご参照ください。
ACR および MaxCompute カスタムイメージを管理するために必要な権限が付与されていること。詳細については、「カスタムイメージ」をご参照ください。
注意事項
MaxCompute カスタムイメージを作成する場合:
イメージサイズ:単一の MaxCompute イメージの最大サイズは
10 GBです。イメージ数:単一の MaxCompute テナントは最大
10個のイメージをアップロードできます。
MaxCompute イメージを使用する場合、DataWorks は Python 3.11 環境に基づいて MaxCompute イメージをビルドすることにご注意ください。DataWorks によってビルドされた MaxCompute イメージを実行するには、ご利用の Python 環境がバージョン 3.11 であることを確認する必要があります。
個人開発環境インスタンスの作成
Data Studio に移動し、個人開発環境インスタンスを作成します。MaxCompute カスタムイメージを同時に作成するには、dataworks-maxcompute:py3.11-ubuntu20.04 イメージを使用する必要があります。
Data Studio に移動します。
DataWorks コンソールの [ワークスペース] ページに移動します。上部のナビゲーションバーで、目的のリージョンを選択します。目的のワークスペースを見つけ、[操作] 列の を選択します。
Data Studio ページの左側のナビゲーションウィンドウで、
 アイコンをクリックして [Data Studio] ページに移動します。
アイコンをクリックして [Data Studio] ページに移動します。
個人開発環境の作成ページに移動します。ページの上部で [個人開発環境] をクリックし、個人開発環境インスタンスを作成します。
個人開発環境インスタンスがない場合は、[新しいインスタンス] をクリックして作成します。
パーソナル開発環境インスタンスが既に存在する場合は、[管理] [環境] をクリックします。次に、パーソナル開発環境インスタンスの一覧で、[新規インスタンス] をクリックします。
個人開発環境を設定します。DataWorks で MaxCompute カスタムイメージを作成する場合、個人開発環境の次のパラメーターを設定する必要があります。その他のパラメーターについては、「個人開発環境インスタンスの作成」をご参照ください。
イメージ構成:
dataworks-maxcompute:py3.11-ubuntu20.04を選択します。説明MaxCompute カスタムイメージを作成するには、
dataworks-maxcompute:py3.11-ubuntu20.04イメージを選択する必要があります。dataworks-maxcompute:py3.11-ubuntu20.04ベースイメージからビルドされた DataWorks カスタムイメージは、DataWorks Notebook、汎用 Python、および Shell ノードでの MaxFrame ジョブの開発に使用できます。
ネットワーク設定:ACR インスタンスに設定されている VPC を選択します。これにより、個人開発環境インスタンスがイメージを ACR インスタンスにプッシュできるようになります。
イメージ環境の設定
個人開発環境インスタンスのターミナルで、MaxCompute 開発に必要なサードパーティの依存関係をインストールします。このトピックでは、jieba を例として使用します。
Data Studio ページの上部で、[個人開発環境] をクリックし、「個人開発環境インスタンスの作成」で作成した個人開発環境インスタンスをクリックします。
Data Studio の下部にあるツールバーで、左側の
 アイコンをクリックしてターミナルを開きます。
アイコンをクリックしてターミナルを開きます。個人開発環境のターミナルで、次のコマンドを実行して、サードパーティの依存関係である
jiebaをダウンロードし、そのインストールを検証します。## サードパーティの依存関係をインストールします。 pip install jieba; ## サードパーティの依存関係を表示します。 pip show jieba;
カスタムイメージの保存
個人開発環境から DataWorks イメージを作成し、同時に MaxCompute イメージを作成することを選択します。システムは、生成されたイメージを同じアカウントで管理されている ACR インスタンスに自動的にアップロードします。
個人開発環境インスタンスの管理ページに移動します。
ページの上部で、[個人開発環境] セクションに表示されている、作成した個人開発環境インスタンスの名前をクリックします。
表示されたダイアログボックスで、[環境の管理] を選択して [個人開発環境インスタンス] ページに移動します。
イメージ作成ページに移動します。
個人開発環境インスタンスのページで、作成した個人開発環境インスタンスを見つけます。
インスタンスの [操作] 列で、[イメージの作成] をクリックします。
次の表の説明に従ってイメージを設定します。設定が完了したら、[確認] をクリックします。
パラメーター
説明
[イメージ名]
DataWorks イメージのカスタム名。イメージが MaxCompute に同期される場合、ここで定義された名前が MaxCompute イメージの名前として使用されます。例:
image_jieba。イメージ インスタンス
Standard Edition 以上の ACR インスタンスを選択します。ACR インスタンスの作成方法の詳細については、「Enterprise 版インスタンスの作成」をご参照ください。
説明Standard Edition 以上の ACR インスタンスのみが MaxCompute カスタムイメージのビルドに使用できます。
名前空間
ACR インスタンスの名前空間を選択します。名前空間の作成方法の詳細については、「名前空間の作成」をご参照ください。
イメージリポジトリ
ACR インスタンスのイメージリポジトリを選択します。イメージリポジトリの作成方法の詳細については、「イメージリポジトリの作成」をご参照ください。
イメージ バージョン
カスタムイメージのバージョン。
MaxCompute に同期
この例では、[はい] を選択します。このオプションを選択すると、DataWorks イメージが公開されるときに、イメージが MaxCompute イメージとしてビルドされます。
説明このオプションは、選択した [イメージインスタンス] に関連しています。インスタンスタイプが Standard Edition 以上の ACR イメージインスタンスを選択できます。他のインスタンスはデフォルトで選択できません。
タスク タイプ
DataWorks イメージを使用できるタスクタイプを選択します。この例では、Notebook 開発にイメージを使用するように選択できます。
Notebook
Python
Shell
イメージの保存ステータスを確認します。
インスタンスのリストで、個人開発環境のイメージ列を見つけて保存ステータスを表示します。
[確認] をクリックしてイメージを作成します。
個人開発環境インスタンスの右側にある
 アイコンをクリックし、[イメージ] チェックボックスを選択して列を表示します。
アイコンをクリックし、[イメージ] チェックボックスを選択して列を表示します。イメージの作成が完了するまでお待ちください。[保存済み] の右側にある
 アイコンにマウスを上に移動し、ポップアップウィンドウで [ここ] をクリックして、[イメージ管理] ページに移動します。
アイコンにマウスを上に移動し、ポップアップウィンドウで [ここ] をクリックして、[イメージ管理] ページに移動します。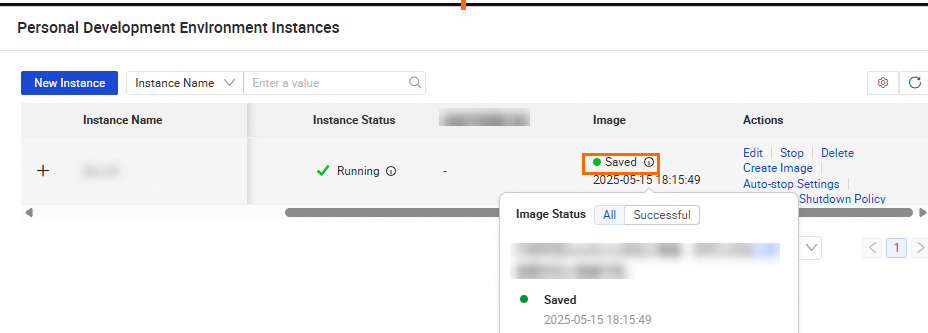
カスタムイメージの公開
Data Studio で個人開発環境インスタンスのイメージが保存された後、カスタムイメージを公開します。この操作により、イメージが ACR インスタンスから DataWorks と MaxCompute に同期され、DataWorks カスタムイメージと MaxCompute カスタムイメージの両方が生成されます。
DataWorks ワークスペースリストページに移動し、上部のナビゲーションバーでターゲットリージョンに切り替えます。
左側のナビゲーションウィンドウで、 タブに移動します。ターゲットイメージを [テスト] します。テストが成功したら、イメージを [公開] します。
説明カスタムイメージをテストする際は、[テストリソースグループ] に Serverless リソースグループを選択します。
テストおよび公開用に選択された Serverless リソースグループにアタッチされている VPC は、ACR で設定されている VPC と同じである必要があります。
カスタムイメージがインターネットからサードパーティパッケージを取得し、テストが失敗した場合、[テストリソースグループ] にアタッチされている VPC がインターネットにアクセスできるかどうかを確認してください。VPC のインターネットアクセスを設定するには、「インターネット NAT ゲートウェイの SNAT 機能を使用したインターネットアクセス」をご参照ください。
ページを更新し、イメージリスト内のイメージの [公開ステータス] が [公開済み] に変わったことを確認します。
ターゲットイメージの [操作] 列で、
 > [ワークスペースの変更] をクリックして、カスタムイメージをワークスペースにアタッチします。
> [ワークスペースの変更] をクリックして、カスタムイメージをワークスペースにアタッチします。
MaxCompute イメージのステータスの確認
DataWorks イメージを公開すると、対応する MaxCompute イメージが自動的に作成されます。DataWorks コンソールの タブのイメージステータスが [公開済み] に変わったら、MaxCompute コンソールに移動できます。「MaxCompute へのカスタムイメージの追加」の手順に従って、新しい MaxCompute カスタムイメージを表示します。
MaxCompute カスタムイメージの使用
注意事項
MaxFrame を使用して開発するには、イメージに
MaxFrameサービスが含まれている必要があります。DataWorks で MaxCompute カスタムイメージを実行するには、イメージがPython 3.11環境でビルドされている必要があります。DataWorks で MaxFrame ジョブ開発に MaxCompute カスタムイメージを使用するには、タスクが MaxFrame ランタイム環境を持つ DataWorks イメージで実行されていることを確認してください。要件は次のとおりです:
Notebook ノード:公式イメージ
dataworks-notebook:py3.11-ubuntu22.04、またはこの公式イメージかdataworks-maxcompute:py3.11-ubuntu20.04イメージからビルドされた DataWorks カスタムイメージを選択します。PyODPS 3 ノード:公式イメージ
dataworks_pyodps_py311_task_pod、またはこの公式イメージからビルドされた DataWorks カスタムイメージを選択します。Python ノード:
dataworks-maxcompute:py3.11-ubuntu20.04イメージに基づいて MaxFrame サービスを持つ個人開発環境インスタンスを作成し、それを Python タスクタイプをサポートする DataWorks カスタムイメージとして保存します。その他のノード:DataWorks カスタムイメージに MaxFrame ランタイム環境が含まれ、
Python 3.11環境でビルドされていることを確認してください。
データ開発への移動
DataWorks コンソールの [ワークスペース] ページに移動します。上部のナビゲーションバーで、目的のリージョンを選択します。目的のワークスペースを見つけ、[操作] 列の を選択します。
Data Studio ページの左側のナビゲーションウィンドウで、
アイコンをクリックして [データ開発] ページに移動します。
Notebook ノードでのイメージの使用
次の例は、Notebook ノードで MaxCompute カスタムイメージを使用して MaxFrame 開発を行う方法を示しています。この例では、MaxCompute カスタムイメージの jieba パッケージを使用します。
Notebook ノードを作成します。
ページの上部で、[個人開発環境] をクリックし、作成した個人開発環境インスタンスを選択します。
[ワークスペースディレクトリ] の右側にある
 アイコンをクリックし、 を選択します。[ノードの作成] ダイアログボックスが表示されます。
アイコンをクリックし、 を選択します。[ノードの作成] ダイアログボックスが表示されます。[ノードの作成] ダイアログボックスで、ノードの [名前] を入力し、[OK] をクリックしてノード編集ページに移動します。
Notebook ノードのコードを編集します。
# -*- coding: utf-8 -*- from odps import ODPS from maxframe.session import new_session import maxframe.dataframe as md # maxframe.dataframe モジュールが正しくインポートされていることを確認してください。 from maxframe import config # データセットを準備します。 test_data = [ "Grass growing on the old plain" ] # MaxCompute カスタムイメージの jieba パッケージを使用してデータを処理する関数を定義します。 # MaxCompute カスタムイメージを使用します。 def image_test(): config.options.sql.settings = { "odps.session.image": "image_jieba" # この例では、MaxCompute イメージの名前は image_jieba です。イメージ名は MaxCompute コンソールで確認できます。 } def process(row): import jieba result = jieba.cut(row, cut_all=False) return "/".join(result) # MaxFrame 接続を確立します。 odps = %odps session = new_session(odps) # 実行詳細を表示するために Logview URL を出力します。 logview = session.get_logview_address() print("logview:", logview) # MaxFrame DataFrame を作成します。 # ["Grass growing on the old plain"] などのローカルテストデータを MaxFrame DataFrame オブジェクトにカプセル化します。 df = md.DataFrame(test_data, columns=["raw_text"]) # トークン化関数を適用して DataFrame オブジェクト内のデータを処理します。 df["processed_text"] = df["raw_text"].map(process, dtype='object') print("Output:",df.execute().fetch()) image_test() print("Data processing completed!")ノード編集ページの左側で、
 アイコンをクリックします。表示されたダイアログボックスで、[カーネル] に
アイコンをクリックします。表示されたダイアログボックスで、[カーネル] に Python 3.11バージョンを選択します。ノードを実行し、ログ情報を表示します。
PyODPS 3 ノードでのイメージの使用
次の例は、PyODPS 3 ノードで MaxCompute カスタムイメージを使用して MaxFrame 開発を行う方法を示しています。この例では、MaxCompute カスタムイメージの jieba パッケージを使用します。
PyODPS 3 ノードを作成します。
[ワークスペースディレクトリ] の右側にある
アイコンをクリックし、 を選択します。[ノードの作成] ダイアログボックスが表示されます。[ノードの作成] ダイアログボックスで、ノードの [名前] を入力し、[OK] をクリックしてノード編集ページに移動します。
PyODPS 3 ノードのコードを編集します。
# -*- coding: utf-8 -*- from odps import ODPS, options from odps.df import DataFrame import pandas as pd # テーブルデータを準備します。 options.sql.settings = {"odps.isolation.session.enable": True} # テストテーブルを作成します。 table = o.create_table('jieba_work_tb', 'col string', if_not_exists=True) # インスタンスデータを追加します。 instance = o.run_sql("insert into table jieba_work_tb values ('Grass growing on the old plain')") instance.wait_for_success() # MaxCompute カスタムイメージの jieba パッケージを使用してデータを処理する関数を定義します。 def image_test(): def process(row): import jieba result = jieba.cut(row, cut_all=False) return "/".join(result) # テーブルを DataFrame オブジェクトとしてカプセル化します。 df = o.get_table("jieba_work_tb").to_df() # トークン化関数を適用して DataFrame オブジェクト内のデータを処理します。 df = df.col.map(process).execute(image='image_jieba') # この例では、MaxCompute イメージの名前は image_jieba です。イメージ名は MaxCompute コンソールで確認できます。 print("Output:",df) image_test() print("Data processing completed!")PyODPS 3 ノードを設定します。
ノード編集ページの右側で、[デバッグ設定] をクリックし、次のパラメーターに基づいてノードを設定します。
パラメーター
説明
コンピューティングリソース
アタッチした MaxCompute コンピューティングリソースを選択します。
リソースグループ
アタッチした Serverless リソースグループを選択します。
画像
dataworks_pyodps_py311_task_pod:prod_20241210を選択します。ノード編集ページの上部にあるツールバーで、
アイコンをクリックしてノードを実行します。