cron 式では、月末などの相対的な日付を直接指定できません。ブランチノードは、ランタイム時に Python 条件を評価し、スイッチケースモデルを使用して正しいダウンストリームパスに実行をルーティングすることで、この問題を解決します。これにより、cron 単独では表現できないスケジューリングパターンを実装できます。
仕組み
時間ベースの条件付きスケジューリングを実装するために、3 種類のコントロールノードタイプが連携して動作します。
| ノードタイプ | 機能 |
|---|---|
| [代入ノード] | スクリプト (SQL、SHELL、または Python) を実行し、その出力をノードコンテキスト機能を通じてダウンストリームノードに渡します。 |
| ブランチノード | 代入ノードの出力に対して Python 条件を評価し、実行を 1 つ以上のブランチにルーティングします。選択されていないブランチ上のノードはドライランとなります。 |
| マージノード | 先祖ノードがドライランであるかどうかにかかわらず実行されます。ドライラン状態がさらにダウンストリームに伝播するのを停止します。 |
ドライランの伝播方法: ブランチが選択されていない場合、DataWorks はそのブランチ上のすべてのインスタンスをドライランとしてマークします。このドライラン状態は、マージノードに到達するまで、すべてのダウンストリームノードに伝播します。マージノードは常に成功し、そのダウンストリームノードはドライランになりません。
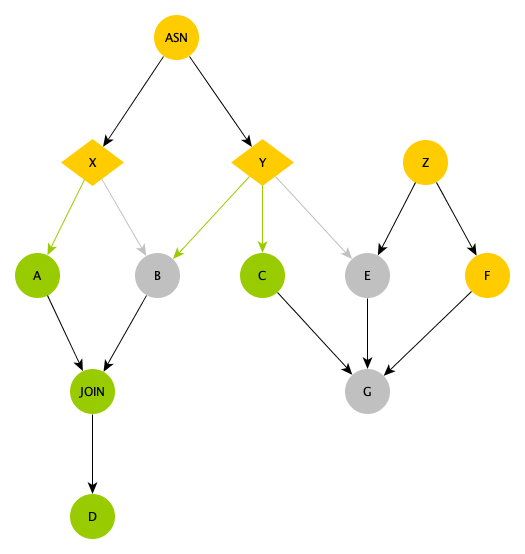
下図は、2 つのブランチノード (X と Y) と 1 つのマージノード (JOIN) を持つ依存関係ツリーを示しています。
-
ASN: ブランチノード X と Y に出力を提供する代入ノード
-
ノード X と Y: ブランチノード。X は左ブランチを選択し、Y は左の 2 つのブランチを選択します (緑色の線)。
-
ノード A: 期待どおりに実行されます (X によって選択されます)。
-
ノード C: 期待どおりに実行されます (Y によって選択されます)。
-
ノード B: ドライラン (Y によって選択されますが、X によっては選択されません)。
-
ノード E: ドライラン (共通ノード Z を先祖として持っているにもかかわらず、Y によって選択されません)。
-
ノード G: ドライラン (C と F が正常に実行されていても、その先祖 E がドライランであるため)。
-
ノード D: 期待どおりに実行されます (ドライランの伝播を停止する JOIN マージノードの子孫であるため)。
マージノードは、その境界でドライラン状態を停止します。マージノードの子孫ノードは、先祖ノードのいくつがドライランであったかに関わらず、常に実行されます。
共通ノードとブランチノード: 共通ノードの場合、出力はグローバルに一意な文字列のみです。共通ノードの子孫ノードを設定するには、そのグローバルに一意な文字列を子孫ノードの入力として指定します。ブランチノードの場合、各出力は条件に関連付けられています。子孫ノードは条件に関連付けられた出力を選択し、条件が満たされたもののみが期待どおりに実行され、残りはドライランとなります。
毎月末日のタスクのスケジュール設定
cron 式では、月末を直接指定することはできません。以下の手順は、代入ノード、ブランチノード、および Shell ノードを組み合わせてこのパターンを実装する方法を示しています。
前提条件
開始する前に、以下を確認してください。
-
DataStudio アクセス権を持つ DataWorks ワークスペース
-
ノードを作成およびデプロイする権限
ステップ 1: ノードの依存関係の定義
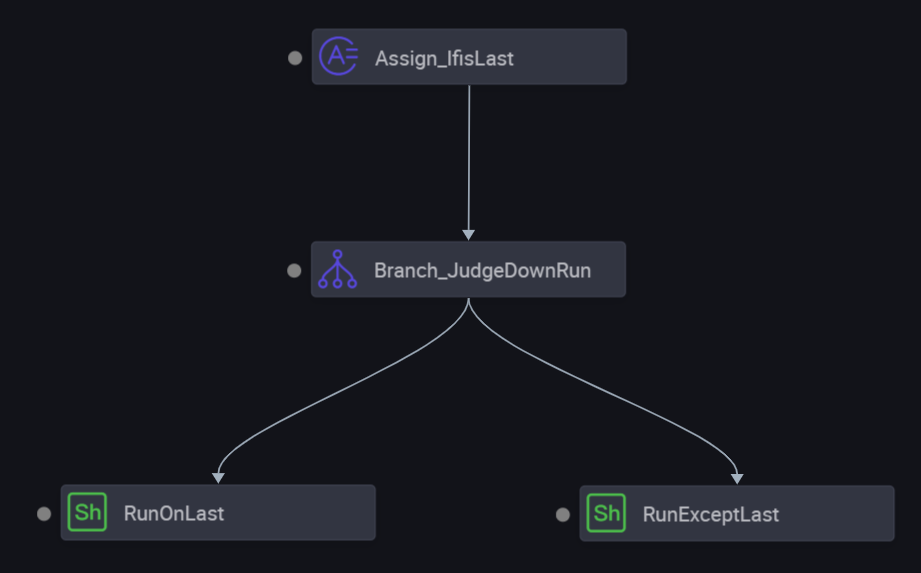
以下のノード構造を設定します。
-
代入ノード (ルート):
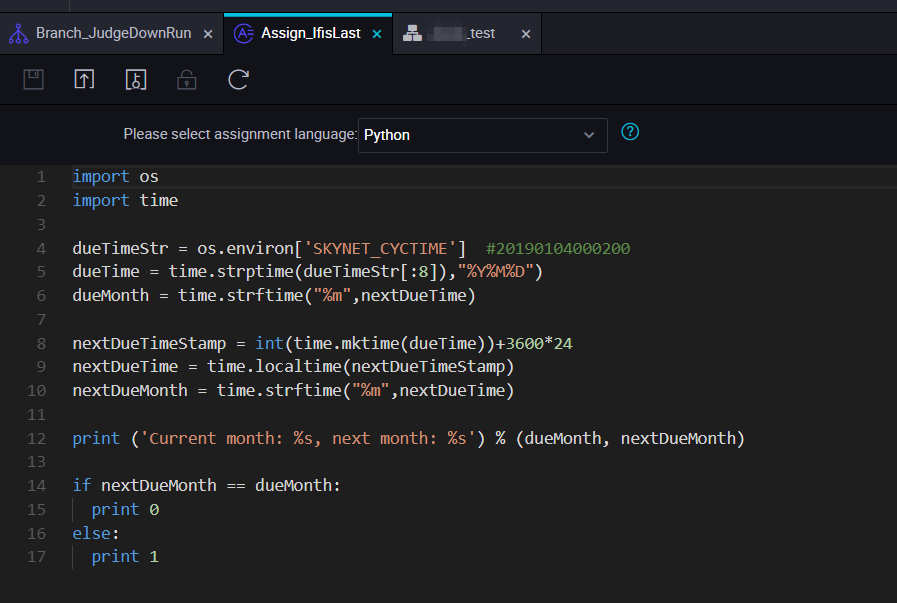
SKYNET_CYCTIMEパラメーターを使用して、当日が月末であるかどうかを判断します。 月末である場合は1を、それ以外の場合は0を返します。 DataWorks はこの出力を取得し、ブランチノードに渡します。 -
[ブランチノード]: 代入ノードの出力に基づいて 2 つのブランチを定義します。
-
Shell ノード (2 つ): 1 つは月末ロジック用、もう 1 つはその他の日用です。それぞれが異なるブランチ上のブランチノードの子孫となります。
ステップ 2: 代入ノードの設定
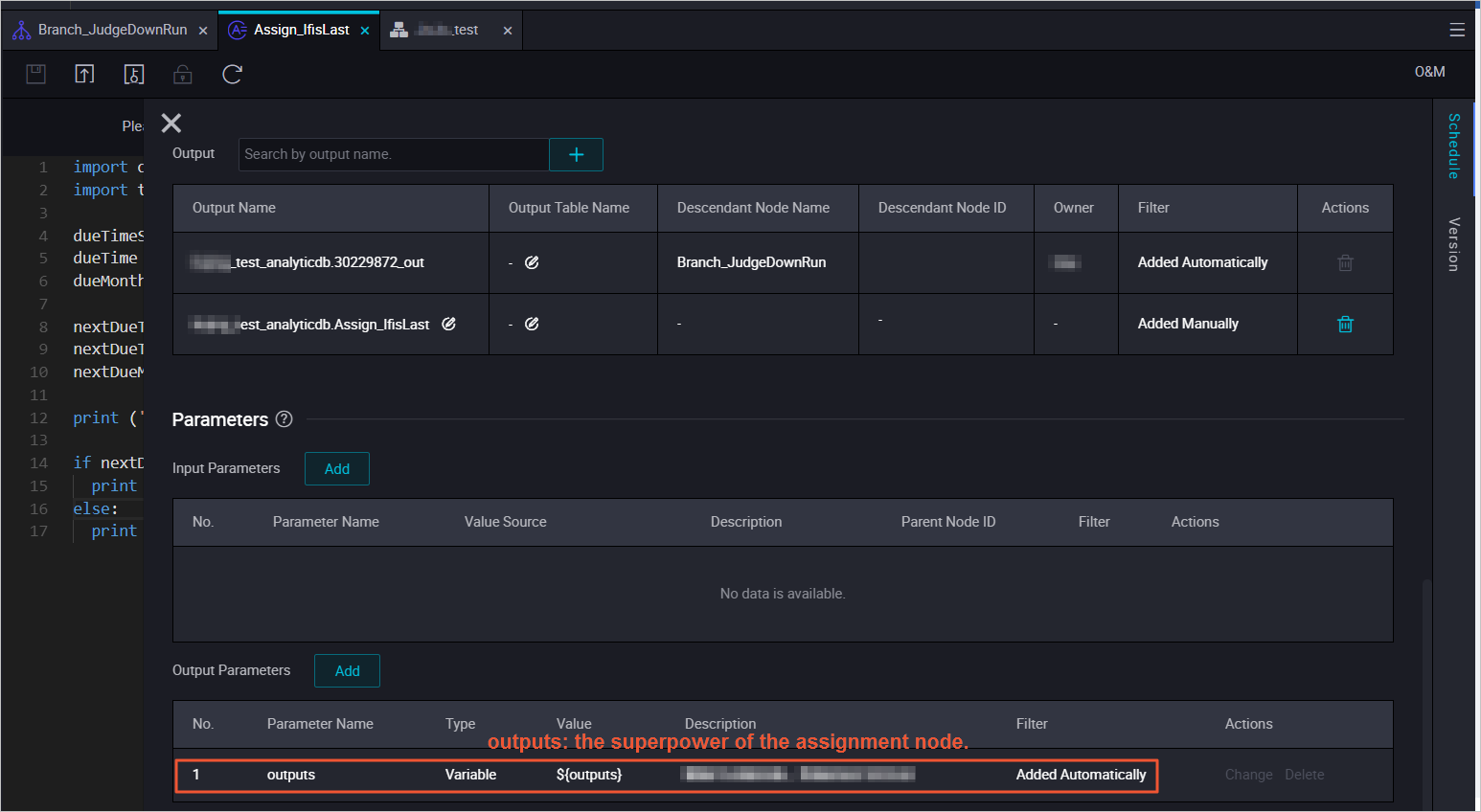
代入ノードのコードは Python で記述されています。DataWorks は、標準出力の最終行 を outputs パラメーターの値として取得し、その後、ブランチノードがこれを読み取ります。
キャプチャルールは言語によって異なります。
| 言語 | キャプチャされた出力 |
|---|---|
| SQL | 最後の SELECT 文 |
| SHELL | 標準出力の最終行 |
| Python | 標準出力の最終行 |
スケジューリングプロパティを設定し、Python コードを貼り付けます。
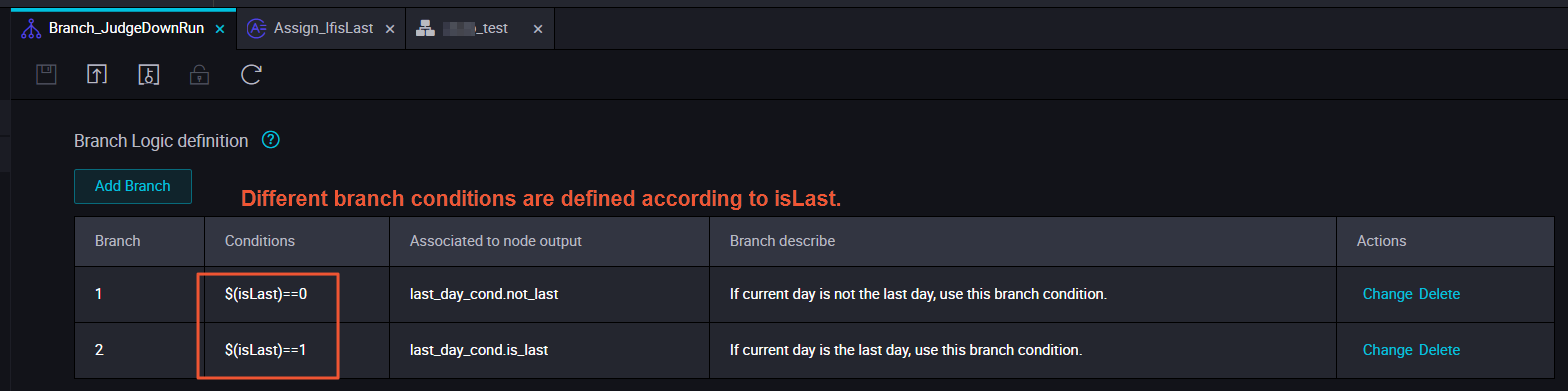
ステップ 3: ブランチ条件の定義
ブランチ条件は Python 式です。各条件はブランチノードの特定の出力にリンクされています。条件が満たされると、その出力に依存する子孫ノードは期待どおりに実行され、他のすべての子孫ノードはドライランとなります。
スケジューリングプロパティとブランチ条件を設定します。
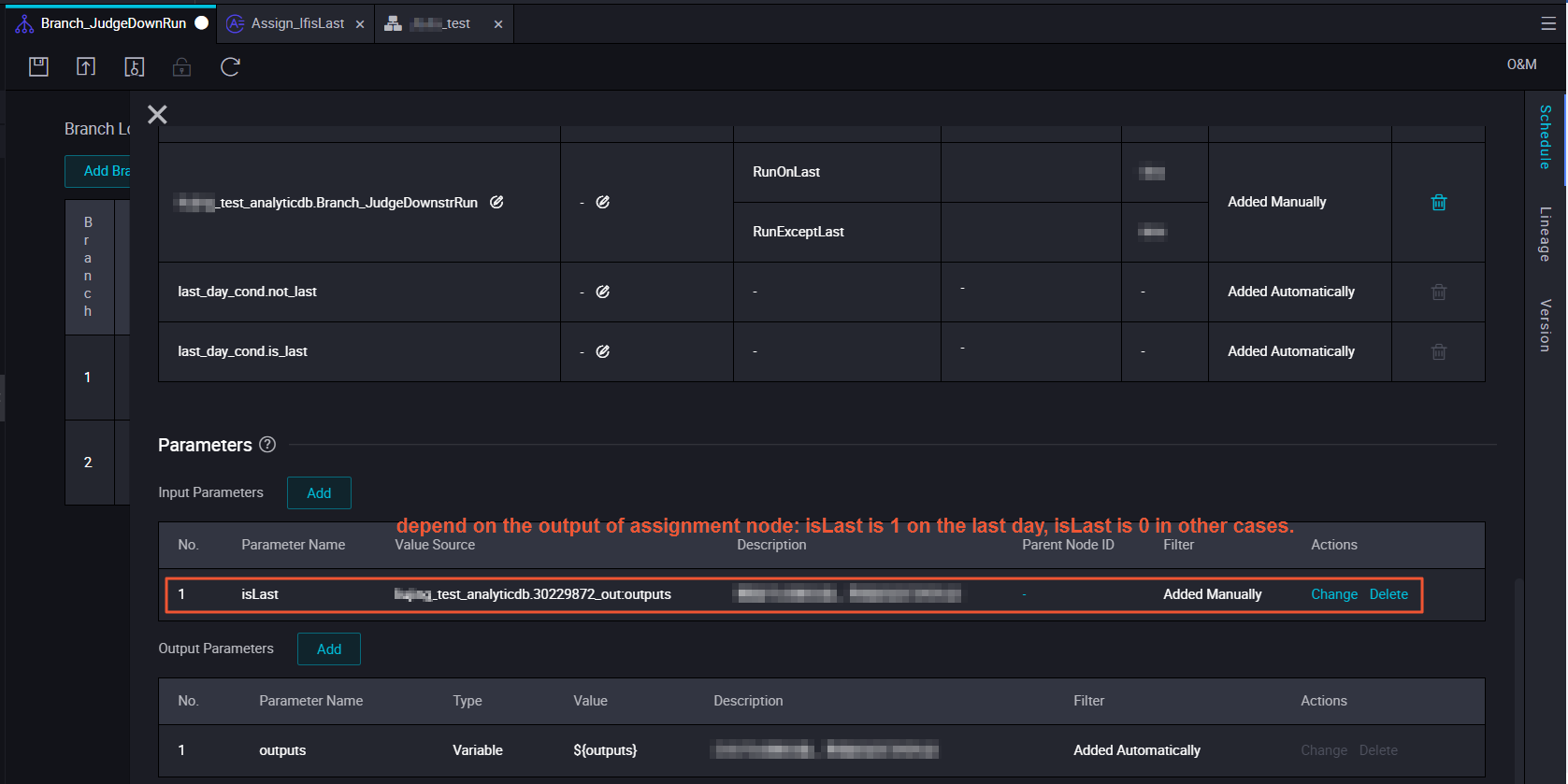
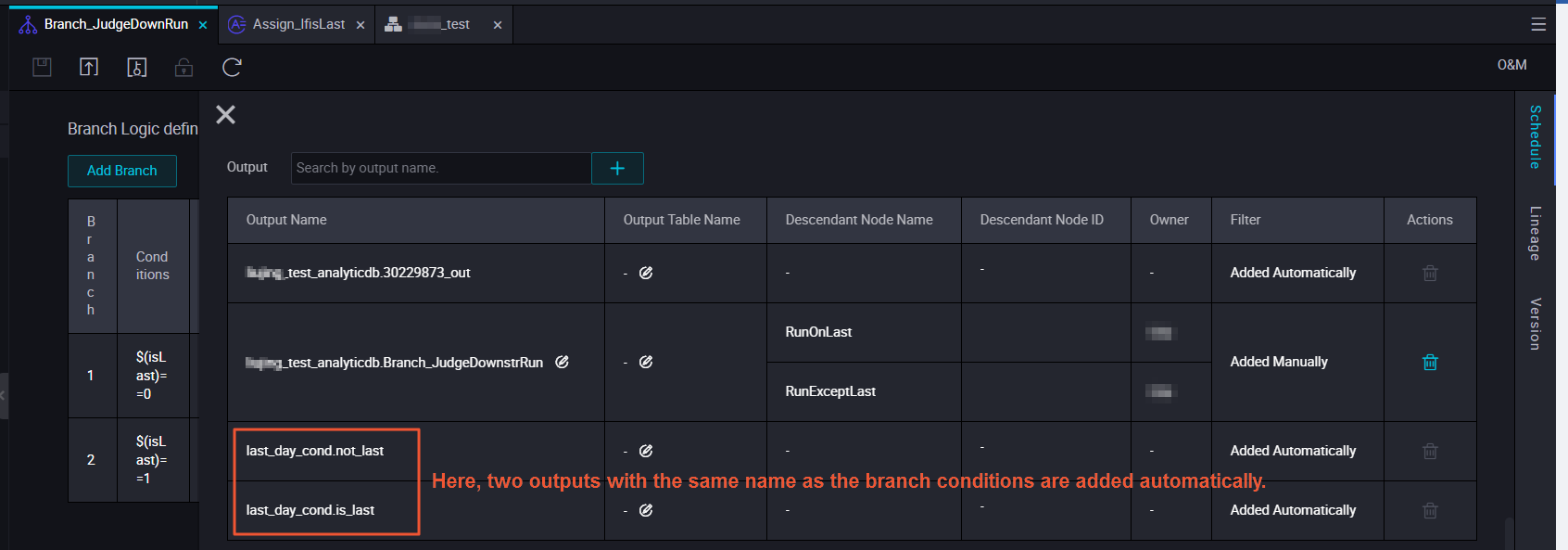
ブランチノードは、各条件に関連付けられた出力を生成します。
ステップ 4: Shell ノードと特定のブランチの関連付け
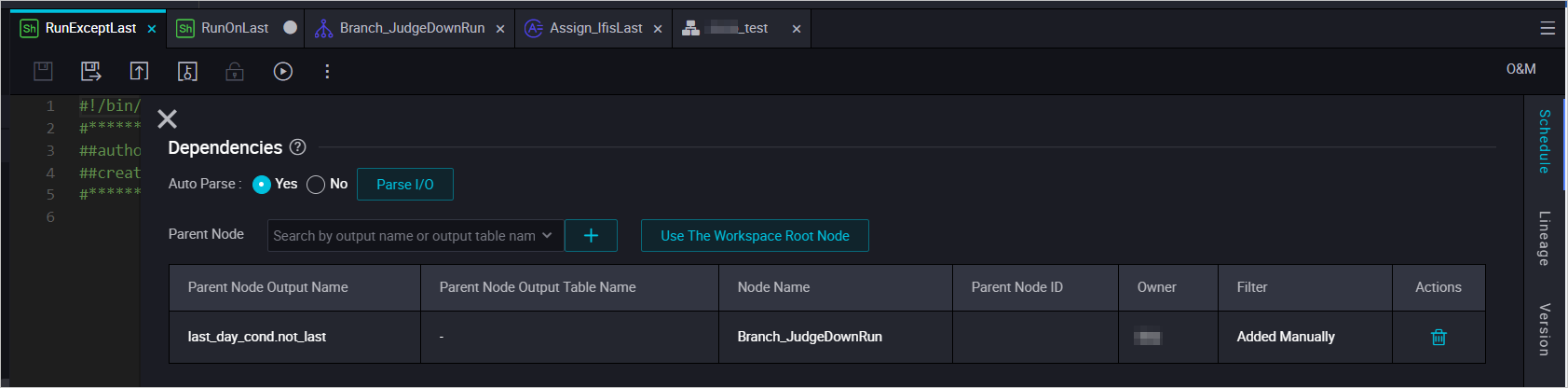
ブランチノードには 3 つの出力があります。各 Shell ノードの依存関係入力として、適切な出力を選択します。各出力は条件に結びついているため、慎重に選択してください。
-
毎月末日に実行される Shell ノードの依存関係:
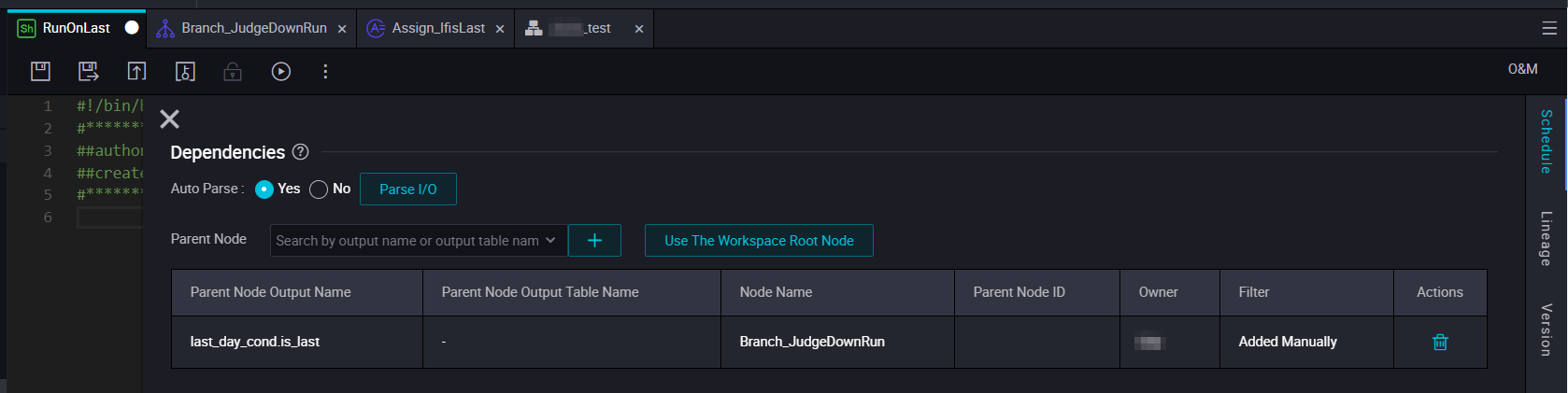
-
その他の日に実行される Shell ノードの依存関係:
ステップ 5: ブランチロジックのデプロイと検証
すべてのノードをコミットしてデプロイします。次に、データバックフィルを使用してブランチロジックをテストします。データバックフィルを使用すると、過去の日付を含む任意のスケジューリング時間をシミュレートできるため、ライブスケジューリングサイクルを待つことなく、各ブランチが正しく起動するかどうかを確認できます。
データタイムスタンプを **2018 年 12 月 30 日**と **2018 年 12 月 31 日**に設定します。これらは、それぞれ 2018 年 12 月 31 日と 2019 年 1 月 1 日のスケジューリング時間に対応します。
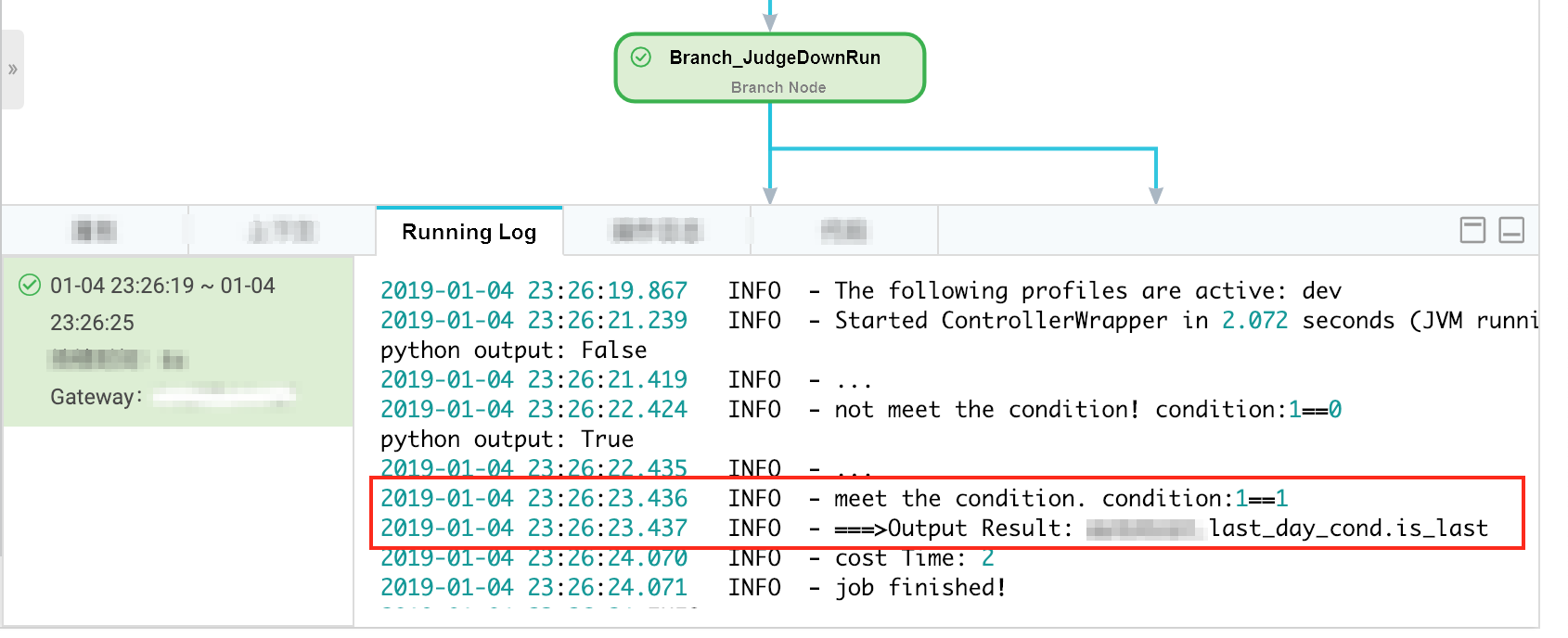
テストケース 1 — 月末ロジック (データタイムスタンプ: 2018 年 12 月 30 日 → スケジューリング時間: 2018 年 12 月 31 日)
ブランチノードは月末ブランチを選択します。
-
月末の Shell ノードは期待どおりに実行されます。
-
その他の日の Shell ノードはドライランとなります。
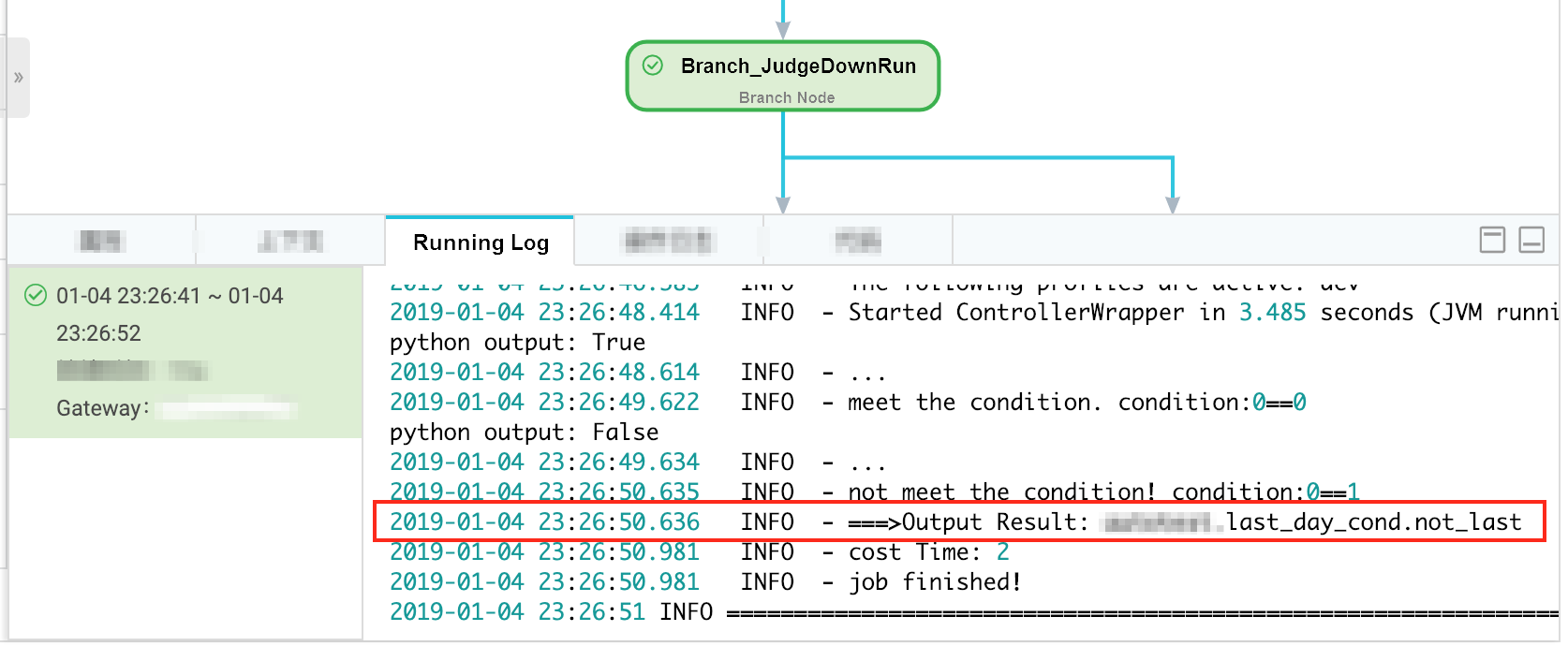
テストケース 2 — 月末以外のロジック (データタイムスタンプ: 2018 年 12 月 31 日 → スケジューリング時間: 2019 年 1 月 1 日)
ブランチノードは月末以外のブランチを選択します。
-
月末の Shell ノードはドライランとなります。
-
その他の日の Shell ノードは期待どおりに実行されます。
主要なルール
| ルール | 詳細 |
|---|---|
| 代入ノードの出力 | DataWorks は、最後の SELECT 文 (SQL) または標準出力の最終行 (SHELL または Python) をキャプチャします。これがダウンストリームノードが参照する値です。 |
| ブランチ出力の選択 | ブランチノードの各出力は条件に関連付けられています。ノードをブランチノードの子孫として設定する前に、選択する出力にどの条件が結びついているかを確認してください。 |
| ドライランの伝播 | ブランチが選択されていない場合、そのブランチ上のすべての子孫ノードはドライランとなります。ドライラン状態は、マージノードに到達するまでダウンストリームに伝播します。 |