このトピックでは、データ統合専用リソースグループを使用して、Elastic Compute Service (ECS) インスタンス上の自己管理 MySQL データベースから MaxCompute にデータを移行する方法について説明します。
前提条件
VPC に関連付けられた Elastic Compute Service (ECS) インスタンスが少なくとも 1 つ必要です。クラシックネットワーク上のインスタンスは使用しないでください。ECS インスタンスには MySQL データベースがインストールされており、データベース内にユーザーとテストデータが作成されている必要があります。このトピックでは、次の文を使用して自己管理 MySQL データベースにテストデータを作成します。
CREATE TABLE IF NOT EXISTS good_sale( create_time timestamp, category varchar(20), brand varchar(20), buyer_id varchar(20), trans_num varchar(20), trans_amount DOUBLE, click_cnt varchar(20) ); insert into good_sale values('2018-08-21','coat','brandA','lilei',3,500.6,7), ('2018-08-22','food','brandB','lilei',1,303,8), ('2018-08-22','coat','brandC','hanmeimei',2,510,2), ('2018-08-22','bath','brandA','hanmeimei',1,442.5,1), ('2018-08-22','food','brandD','hanmeimei',2,234,3), ('2018-08-23','coat','brandB','jimmy',9,2000,7), ('2018-08-23','food','brandA','jimmy',5,45.1,5), ('2018-08-23','coat','brandE','jimmy',5,100.2,4), ('2018-08-24','food','brandG','peiqi',10,5560,7), ('2018-08-24','bath','brandF','peiqi',1,445.6,2), ('2018-08-24','coat','brandA','ray',3,777,3), ('2018-08-24','bath','brandG','ray',3,122,3), ('2018-08-24','coat','brandC','ray',1,62,7) ;ECS インスタンスの[プライマリプライベートIPアドレス]、[VPC]、および[vSwitch]情報を確認してください。
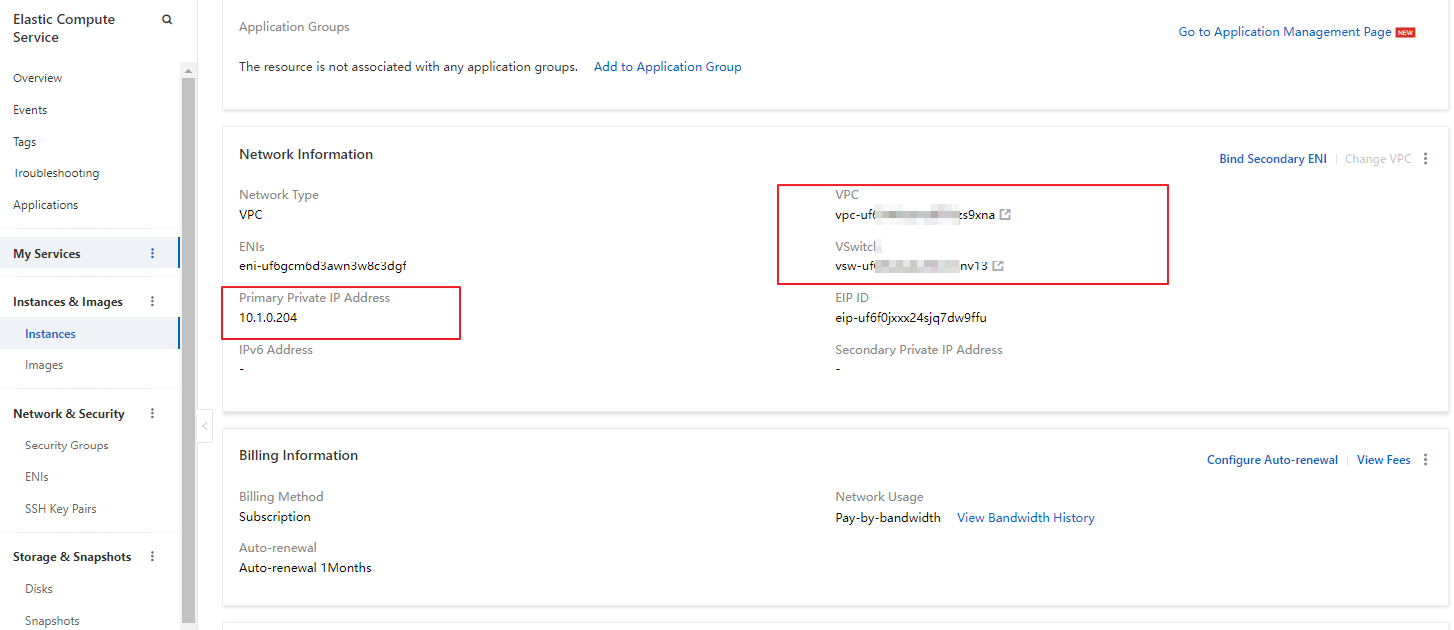
ECS インスタンスにセキュリティグループルールを追加して、MySQL データベースが使用するポートでのアクセスを許可します。デフォルトのポートは 3306 です。詳細については、「セキュリティグループルールの追加」をご参照ください。ご利用のセキュリティグループの名前をメモしておきます。
DataWorks ワークスペースが作成されている必要があります。このトピックでは、MaxCompute コンピュートエンジンを使用する基本モードの DataWorks ワークスペースを使用します。ご利用の ECS インスタンスと DataWorks ワークスペースが同じリージョンにあることを確認してください。ワークスペースの作成方法の詳細については、「ワークスペースの作成」をご参照ください。
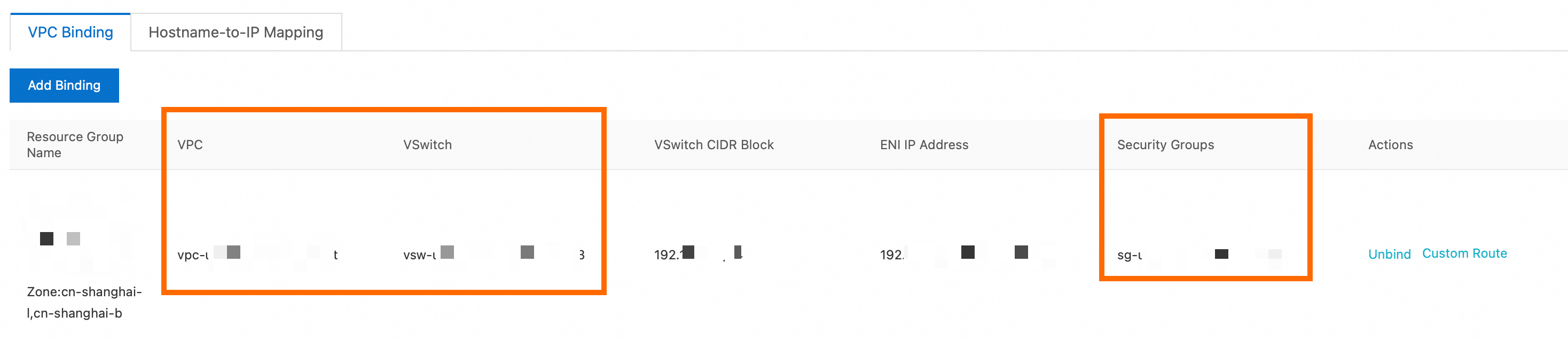
データ統合専用リソースグループを購入し、ECS インスタンスが存在する VPC に関連付けます。データ統合専用リソースグループは、ECS インスタンスと同じゾーン内にある必要があります。詳細については、「データ統合専用リソースグループの使用」をご参照ください。関連付けが完了すると、リソースグループ でデータ統合専用リソースグループを表示できます。
[] タブで、[VPC]、[VSwitch]、および[セキュリティグループ] の情報が ECS インスタンスの情報と一致していることを確認します。
MaxCompute データソースが追加されている必要があります。詳細については、「MaxCompute コンピューティングリソースの関連付け」をご参照ください。
背景情報
データ統合専用リソースグループは、高速で安定したデータ転送を保証します。購入した専用リソースグループとアクセスしたいデータソースは、同じリージョンの同じゾーンにある必要があります。このトピックでは、データソースは ECS インスタンス上の自己管理 MySQL データベースです。リソースグループも、ご利用の DataWorks ワークスペースと同じリージョンにある必要があります。
操作手順
DataWorks で MySQL データソースを作成します。
[データソース] ページに移動します。
DataWorks コンソールにログインします。 上部のナビゲーションバーで、目的のリージョンを選択します。 左側のナビゲーションウィンドウで、を選択します。 表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[管理センターへ移動]をクリックします。
SettingCenter ページの左側のナビゲーションウィンドウで、[Data Sources] をクリックします。
[データソースの追加] をクリックします。
「[データソースの追加]」ダイアログボックスで、[MySQL] をクリックします。
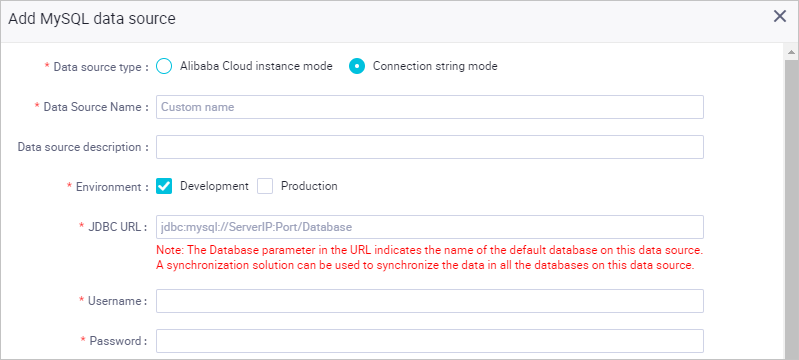
[MySQL データソースの作成] ダイアログボックスで、パラメーターを設定します。詳細については、「MySQL データソースを設定する」をご参照ください。
このトピックでは、[接続文字列モード] を例として使用します。[接続アドレス] には、メモした ECS インスタンスのプライベート IP アドレスとデフォルトの MySQL ポート番号 3306 を入力します。
 説明
説明VPC 内のセルフマネージド MySQL データソースでは、[接続性テスト]機能はサポートされていません。そのため、接続性テストが失敗するのは正常です。
[接続のテスト] をリソースグループに対してクリックします。
データ統合専用リソースグループを使用して、データ同期タスクを実行できます。タスクは、実行ごとに 1 つのリソースグループしか使用できません。複数のリソースグループが利用可能な場合は、使用したい各リソースグループの接続性をテストする必要があります。これにより、同期タスクで使用されるリソースグループがデータソースに接続できることが保証されます。そうしないと、データ同期タスクは期待どおりに実行できません。詳細については、「ネットワーク接続ソリューション」をご参照ください。
接続性テストが成功した後、[完了] をクリックします。
MaxCompute テーブルを作成します。
DataWorks でテーブルを作成し、MySQL データベースからのテストデータを受け取ります。
左上隅の
 アイコンをクリックして、 を選択します。
アイコンをクリックして、 を選択します。[ワークフロー] を作成します。詳細については、「スケジュールされたワークフローの作成」をご参照ください。
新しいワークフローを右クリックし、 を選択します。
MaxCompute テーブルの名前を入力します。この例では、MySQL データベースのテーブルと同じ名前の good_sale を使用します。[DDL] をクリックし、テーブル作成文を入力してから、[テーブルスキーマの生成] をクリックします。
この例では、次のテーブル作成文を使用します。データの型の変換にご注意ください。
CREATE TABLE IF NOT EXISTS good_sale( create_time string, category STRING, brand STRING, buyer_id STRING, trans_num BIGINT, trans_amount DOUBLE, click_cnt BIGINT );テーブルの[表示名]を入力し、[本番環境にコミット]をクリックして MaxCompute に good_sale テーブルを作成します。
データ統合タスクを設定します。
ワークフローを右クリックし、 を選択してデータ統合タスクを作成します。
ソースには、追加した MySQL データソースを選択します。送信先には、追加した MaxCompute データソースを選択します。[コードエディタに切り替える] をクリックして、データ統合タスクをコードエディタに切り替えます。
エラーが発生する場合や、ソースの [テーブル] を選択できない場合でも、これは正常な現象です。直接コードエディタに切り替えてください。
右側のペインで、[データ統合リソースグループ設定] タブをクリックし、購入した専用リソースグループを選択します。
タスクをデータ統合専用リソースグループに切り替えないと、タスクは実行できません。
データ統合タスクのスクリプトに次の内容を入力します。
{ "type": "job", "steps": [ { "stepType": "mysql", "parameter": { "column": [// ソース列の名前。 "create_time", "category", "brand", "buyer_id", "trans_num", "trans_amount", "click_cnt" ], "connection": [ { "datasource": "shuai",// ソースデータソース。 "table": [ "good_sale"// ソースデータベースのテーブル名。名前は角括弧 [] で囲まれた配列形式である必要があります。 ] } ], "where": "", "splitPk": "", "encoding": "UTF-8" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "datasource": "odps_source",// 宛先 MaxCompute データソースの名前。 "column": [// 宛先列の名前。 "create_time", "category", "brand", "buyer_id", "trans_num", "trans_amount", "click_cnt" ], "emptyAsNull": false, "table": "good_sale"// 宛先テーブルの名前。 }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "0" }, "speed": { "throttle": false, "concurrent": 2 } } }「実行」をクリックします。データが MaxCompute に転送されたかどうかを確認するには、画面下部の [実行時ログ] を表示します。
結果
[ODPS SQL] ノードを作成して、MaxCompute テーブル内のデータをクエリします。
クエリ文 select * from good_sale; を入力し、[実行] をクリックします。MaxCompute テーブルに転送されたデータを確認できます。