このチュートリアルでは、住宅購入者層の分析を通じて、DataWorks のデータ開発およびデータ分析機能の習得を支援します。
ケース紹介
このチュートリアルでは、住宅購入者のデータに基づいて購買行動を分析します。DataWorks を使用してローカルデータを MaxCompute の bank_data テーブルにアップロードし、MaxCompute SQL ノードを使用してユーザーグループを分析して result_table を生成し、結果を可視化してグループプロファイルを作成します。
このチュートリアルではシミュレーションデータを使用します。実際のシナリオでは、お客様自身のビジネスデータに置き換えてください。
以下のフローチャートは、データフローと開発プロセスを示しています。
分析の結果、次のようなプロファイルが明らかになりました:ローンを利用している独身の住宅購入者は、主に university.degree または high.school の学歴を持っています。

前提条件
DataWorks の有効化
このチュートリアルでは、[中国 (上海)] リージョンを使用します。DataWorks コンソールにログインして[中国 (上海)] リージョンに切り替え、DataWorks がそのリージョンでアクティブ化されていることを確認してください。
このチュートリアルでは [中国 (上海)] を使用します。本番環境では、お客様のビジネスデータが存在するリージョンを選択してください:
ビジネスデータが他の Alibaba Cloud サービスにある場合は、同じリージョンを選択してください。
ビジネスがオンプレミスにあり、インターネット経由でのアクセスが必要な場合は、レイテンシーを削減するために地理的に近いリージョンを選択してください。
新規ユーザー
新規ユーザーの場合、現在のリージョンで DataWorks が非アクティブであることを示す以下のページが表示されたら、[0 RMB 購入] をクリックします。

購入ページでパラメーターを設定します。
パラメーター
説明
例
リージョン
DataWorks を有効化するリージョンを選択します。
中国 (上海)
DataWorks エディション
購入する DataWorks のエディションを選択します。
説明このチュートリアルでは、[Basic Edition] を使用します。すべてのエディションで、このチュートリアルで扱う機能を体験できます。DataWorks エディションの詳細を参照し、お客様のビジネスニーズに合ったエディションを選択してください。
Basic Edition
[注文を確定して支払う] をクリックして、支払いを完了します。
期限切れ
DataWorks エディションが期限切れの場合、次のプロンプトが表示されます。[エディションの購入] をクリックします。
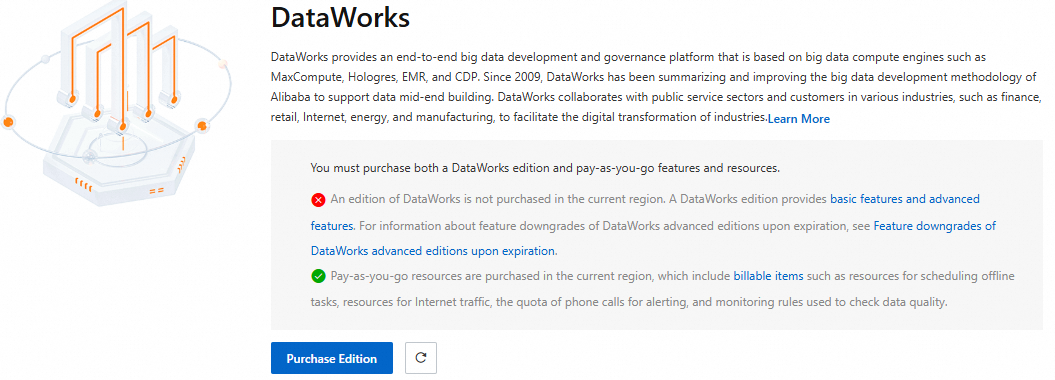
購入ページでパラメーターを設定します。
パラメーター
説明
例
エディション
購入する DataWorks のエディションを選択します。
説明このチュートリアルでは、[Basic Edition] を使用します。すべてのエディションで、このチュートリアルで説明する機能を体験できます。DataWorks エディションの詳細を参照し、ビジネスニーズに合ったエディションを選択してください。
Basic Edition
リージョン
DataWorks を有効化するリージョンを選択します。
中国 (上海)
[今すぐ購入] をクリックして支払いを完了します。
購入後に関連する DataWorks エディションが見つからない場合は、次の操作を実行してください:
システムの更新が遅延している可能性があるため、数分待ってからページをリフレッシュしてください。
現在のリージョンが、DataWorks エディションを購入したリージョンと一致していることを確認してください。
有効化済み
すでに [中国 (上海)] リージョンで DataWorks をアクティベートしている場合、DataWorks の概要ページが表示されます。次のステップに進んでください。
ワークスペースの作成
リソースグループの作成
MaxCompute リソースの作成
操作手順
このチュートリアルでは、DataWorks を使用してテストデータを MaxCompute プロジェクトにアップロードします。次に、DataStudio ワークフローを作成してデータのクリーンアップと書き込みを行い、ワークフローをデバッグし、SQL を使用して結果を検証します。
ステップ 1:テーブルの作成
まず、DataWorks のデータカタログを使用して、MaxCompute に bank_data テーブルを作成します。
DataWorks コンソールにログインします。 目的のリージョンに切り替え、左側のナビゲーションウィンドウでをクリックし、ドロップダウンリストから対応するワークスペースを選択し、次に[DataStudio へ移動]をクリックします。
左側のナビゲーションウィンドウで
 アイコンをクリックし、[データカタログ] ページに移動します。
アイコンをクリックし、[データカタログ] ページに移動します。(任意) MaxCompute プロジェクトが Data Catalog にない場合は、
 アイコンをクリックし、[DataWorks データソース] に移動して、プロジェクトを追加します。
アイコンをクリックし、[DataWorks データソース] に移動して、プロジェクトを追加します。[MaxCompute] ディレクトリをクリックして展開し、ターゲット MaxCompute プロジェクトを選択して、[Table] フォルダに MaxCompute テーブルを作成します。
説明MaxCompute プロジェクトでスキーマ機能が有効になっている場合、[テーブル] フォルダに MaxCompute テーブルを作成するには、プロジェクトを選択した後にターゲットスキーマを選択する必要があります。
この例では、標準モードのワークスペースを使用します。開発環境にのみ
bank_dataテーブルを作成します。シンプルモードのワークスペースを使用している場合は、本番環境に対応する MaxCompute プロジェクトにbank_dataテーブルを作成するだけで済みます。
 アイコンをクリックして、テーブル編集ページを開きます。
アイコンをクリックして、テーブル編集ページを開きます。以下の SQL 文を [DDL] セクションに入力してください。システムが自動的にテーブル情報を生成します。
CREATE TABLE IF NOT EXISTS bank_data ( age BIGINT COMMENT '年齢', job STRING COMMENT '職種', marital STRING COMMENT '婚姻状況', education STRING COMMENT '学歴', `default` STRING COMMENT 'クレジットカードの有無', housing STRING COMMENT '住宅ローンの有無', loan STRING COMMENT 'ローンの有無', contact STRING COMMENT '連絡方法', month STRING COMMENT '月', day_of_week STRING COMMENT '曜日', duration STRING COMMENT '期間', campaign BIGINT COMMENT 'このキャンペーンでの接触回数', pdays DOUBLE COMMENT '前回の接触からの間隔', previous DOUBLE COMMENT '前回の接触回数', poutcome STRING COMMENT '前回のマーケティングキャンペーンの結果', emp_var_rate DOUBLE COMMENT '雇用変動率', cons_price_idx DOUBLE COMMENT '消費者物価指数', cons_conf_idx DOUBLE COMMENT '消費者信頼感指数', euribor3m DOUBLE COMMENT 'ユーロ圏3ヶ月物金利', nr_employed DOUBLE COMMENT '従業員数', y BIGINT COMMENT '定期預金の有無' );編集ページで[デプロイ] をクリックして、開発環境に対応する MaxCompute プロジェクトに
bank_dataテーブルを作成します。bank_dataテーブルが作成された後、データカタログでテーブル名をクリックすると、テーブルの詳細を表示できます。
ステップ 2:データのアップロード
banking.csv ファイルをダウンロードします。DataWorks のアップロード機能を使用して、bank_data テーブルにアップロードします。
アップロードする前に、スケジューリングリソースグループとデータ統合リソースグループが設定されていることを確認してください。詳細については、「データアップロードの制限事項」をご参照ください。
 アイコンをクリックし、 を選択して、アップロード&ダウンロードページに移動します。
アイコンをクリックし、 を選択して、アップロード&ダウンロードページに移動します。[データをアップロード] をクリックし、以下の設定を構成します:
パラメーター
説明
データソース
ローカルファイル。
アップロードするデータを指定
データソースタイプ
ローカルの
banking.csvファイルをアップロードします。宛先テーブルの設定
ターゲットエンジン
MaxCompute
MaxCompute プロジェクト名
bank_dataテーブルを含むプロジェクトを選択します。宛先テーブルの選択
ターゲットテーブルとして
bank_dataテーブルを選択します。アップロードファイルのデータプレビュー
[順序どおりにマッピング] をクリックして、データをテーブルフィールドにマップします。
説明ローカルファイルは
.csv、.xls、.xlsx、.json形式をサポートしています。スプレッドシートファイルの場合、デフォルトで最初のシートがアップロードされます。
.csvファイルの最大サイズは 5 GB です。他のファイルタイプの制限は 100 MB です。
[データのアップロード] をクリックして、ダウンロードした CSV ファイルのデータを MaxCompute コンピューティングリソースの
bank_dataテーブルにアップロードします。アップロードの検証。
SQL クエリ (旧バージョン) を介して
bank_dataテーブルのデータを検証します。左上の
アイコンをクリックします。ポップアップページで、 をクリックします。「マイファイル」の横にある
 > [ファイルを作成]をクリックします。任意の[ファイル名]を入力し、[OK]をクリックします。
> [ファイルを作成]をクリックします。任意の[ファイル名]を入力し、[OK]をクリックします。SQL クエリページで、次の SQL を設定します。
SELECT * FROM bank_data limit 10;右上隅で、
bank_dataテーブルが存在するワークスペースと MaxCompute データソースを選択し、[OK] をクリックします。説明この例では、標準モードのワークスペースを使用し、
bank_dataテーブルは開発環境にのみ作成されます。したがって、開発環境用の MaxCompute データソースを選択する必要があります。シンプルモードのワークスペースを使用している場合は、本番環境用の MaxCompute データソースを選択できます。[実行] をクリックします (プロンプトが表示された場合は、コスト見積もりを確認します)。 下部ペインに最初の 10 レコードが表示され、アップロードが完了したことを確認できます。

ステップ 3:データ処理
MaxCompute SQL ノードを使用して bank_data テーブルをフィルタリングし、ローンを組んでいる独身の住宅購入者の学歴を抽出し、その結果を result_table に書き込みます。
データ処理パイプラインの構築
左上の
 アイコンをクリックし、 を選択します。
アイコンをクリックし、 を選択します。ページの上部で、このチュートリアルで作成したワークスペースに切り替えます。左側のナビゲーションウィンドウで
 をクリックして、 [Data Studio] に移動します。
をクリックして、 [Data Studio] に移動します。[ワークスペースディレクトリ] で
 > [ワークフローの作成] をクリックし、
> [ワークフローの作成] をクリックし、dw_basic_caseと名前を付けて [OK] をクリックします。[ゼロロードノード] を 1 つと [MaxCompute SQL] ノードを 2 つキャンバスにドラッグし、次のように名前を変更します。
このチュートリアルで使用されるノード名と機能は次のとおりです:
タイプ
名前
機能
 ゼロロード
ゼロロードworkshop_startワークフローの構造を管理します。これはコードを必要としないノーオペレーションタスクです。
 MaxCompute SQL
MaxCompute SQLddl_result_tablebank_data からクリーンアップされたデータを格納するための result_table を作成します。
MaxCompute SQLinsert_result_tablebank_data をフィルタリングし、結果を result_table に書き込みます。
図のようにノードを接続します:
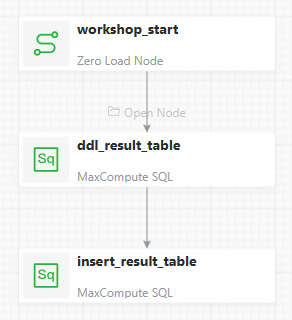 説明
説明ワークフローは、手動接続またはコード解析による依存関係の自動識別を介して上流/下流の依存関係を設定することをサポートしています。このチュートリアルでは手動接続方法を使用します。詳細については、「依存関係の自動解析」をご参照ください。
ノードツールバーの[保存]をクリックします。
データ処理ノードの設定
ステップ 4:デバッグと実行
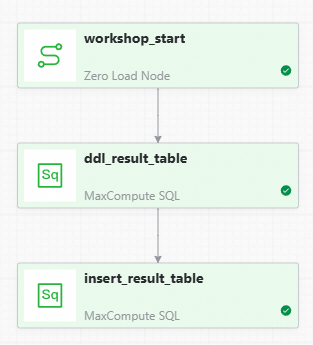
 アイコンをクリックしてワークフローを実行します。失敗した場合はログを確認してください。
アイコンをクリックしてワークフローを実行します。失敗した場合はログを確認してください。
ステップ 5:データのクエリと表示
データ処理が完了しました。SQL クエリ (旧バージョン) で result_table をクエリし、データを分析します。
左上の
アイコンをクリックします。ポップアップページで、 をクリックします。My Files の横にある
> [ファイルを作成]をクリックします。任意の[ファイル名]を入力し、[OK]をクリックします。SQL クエリページで、次の SQL を設定します。
SELECT * FROM result_table;右上隅で、
result_tableテーブルが存在するワークスペースと MaxCompute データソースを選択し、[OK] をクリックします。説明この例では、標準モードのワークスペースを使用します。
result_tableは開発環境にのみ存在するため、対応するデータソースを選択します。シンプルモードのワークスペースを使用している場合は、本番環境用の MaxCompute データソースを選択できます。上部にある [実行] ボタンをクリックします。コスト見積もりページで、[実行] をクリックします。
クエリ結果の
 をクリックして、可視化されたグラフ結果を表示します。グラフの右上隅にある
をクリックして、可視化されたグラフ結果を表示します。グラフの右上隅にある  をクリックして、グラフのスタイルをカスタマイズできます。
をクリックして、グラフのスタイルをカスタマイズできます。また、チャートの右上隅にある[保存]をクリックしてチャートをカードとして保存し、左側のナビゲーションウィンドウで[カード] (
 ) をクリックして表示することもできます。
) をクリックして表示することもできます。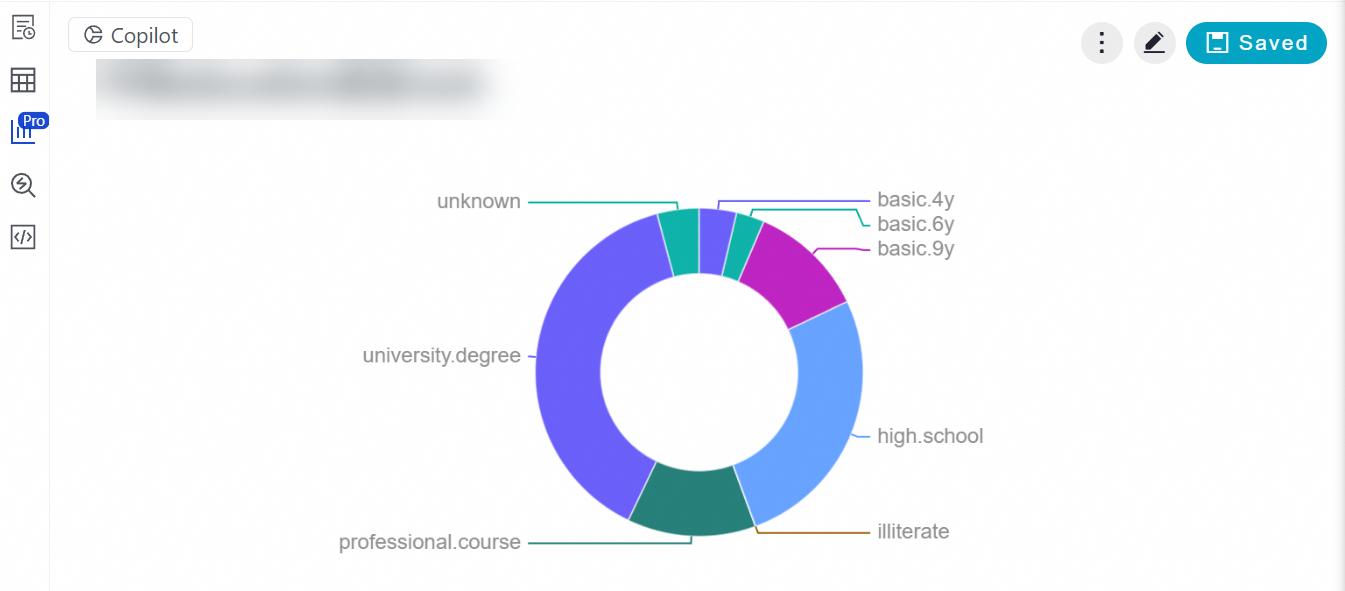
次のステップ
モジュールとパラメーターの詳細については、「Data Studio (新バージョン)」および「データ分析」をご参照ください。
このチュートリアルで紹介したモジュールに加えて、DataWorks は データモデリング、Data Quality、データセキュリティガード、DataService Studio、データ統合、ノードスケジューリング設定など、複数のモジュールをサポートしており、ワンストップのデータ監視と O&M を提供します。
さらに多くの DataWorks 実践チュートリアルを体験することもできます。具体的な内容については、「その他のユースケースとチュートリアル」をご参照ください。
リソースのリリースとクリーンアップ
リソースをリリースするには:
自動トリガータスクの停止。
DataWorks コンソールにログインします。 上部のナビゲーションバーで、目的のリージョンを選択します。 左側のナビゲーションウィンドウで、 を選択します。 表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[オペレーションセンターへ移動] をクリックします。
で、以前に作成したすべての定期タスクを選択します (ワークスペースのルートノードはドロップする必要はありません)。次に、下部で をクリックします。
ノードの削除と MaxCompute リソースのバインド解除。
DataWorks コンソールの [ワークスペース] ページに移動します。 上部ナビゲーションバーで、目的のリージョンを選択します。 目的のワークスペースを見つけ、[操作] 列で を選択します。
DataStudio の左側のナビゲーションウィンドウで、
 をクリックしてデータ開発ページに移動します。次に、[ディレクトリ] エリアで作成したワークフローを検索し、そのワークフローを右クリックして [削除] をクリックします。
をクリックしてデータ開発ページに移動します。次に、[ディレクトリ] エリアで作成したワークフローを検索し、そのワークフローを右クリックして [削除] をクリックします。左側のナビゲーションウィンドウで、
 > [計算リソース] をクリックし、バインドされた MaxCompute 計算リソースを探し、[バインド解除] をクリックします。確認ウィンドウでオプションを確認し、指示に従ってバインド解除を完了します。
> [計算リソース] をクリックし、バインドされた MaxCompute 計算リソースを探し、[バインド解除] をクリックします。確認ウィンドウでオプションを確認し、指示に従ってバインド解除を完了します。
MaxCompute プロジェクトの削除。
MaxCompute プロジェクト管理 ページに移動し、作成した MaxCompute プロジェクトを見つけ、[操作] 列の [削除] をクリックし、指示に従って削除を完了します。
DataWorks ワークスペースの削除。
DataWorks コンソールで、ワークスペースを見つけ、[アクション]
 > [ワークスペースを削除] をクリックします。
> [ワークスペースを削除] をクリックします。[ワークスペースの削除] ダイアログボックスで、[OK] をクリックしてワークスペースを削除します。