X-Data Security は、大規模言語モデルを使用して選択されたデータテーブルを分析し、コアフィールドを識別し、対応する分類と等級をインテリジェントに推奨します。推奨された識別結果を適用または拒否できます。このトピックでは、X-Data Security の使用方法について説明します。
前提条件
X-Data Security を構成して有効にする必要があります。詳細については、「インテリジェントアシスタント」をご参照ください。
権限
スーパー管理者、セキュリティ管理者、および [分類結果] - [管理] 権限を持つカスタムグローバルロールは、X-Data Security を使用できます。
データ分類と等級付けのインテリジェント推奨フロー
このセクションでは、大規模言語モデルを使用したデータ分類と等級付けの推奨に関するエンドツーエンドのフローについて説明します。フローは、データ範囲の構成 > コアフィールドの識別 > 分類と等級付けの推奨、のステップで構成されます。
データ範囲:インテリジェントな識別結果が必要なデータ範囲を選択します。
コアフィールドの識別:大規模言語モデルが、選択されたデータ資産に対してセマンティクス分析を実行し、後続の推奨のためのコアフィールドを識別します。
分類と等級付けの推奨:サービスは、分類のセマンティクスとサンプルデータを組み合わせて、分類と等級をインテリジェントに推奨します。これにより、データセキュリティが強化され、機密データの保護が向上します。
手順
Dataphin のホームページの上部のメニューバーで、[Super X] > [X-Data Security] を選択して、X-Data Security ページを開きます。
X-Data Security ページで、推奨される分類と等級を管理して、機密データの保護を強化します。
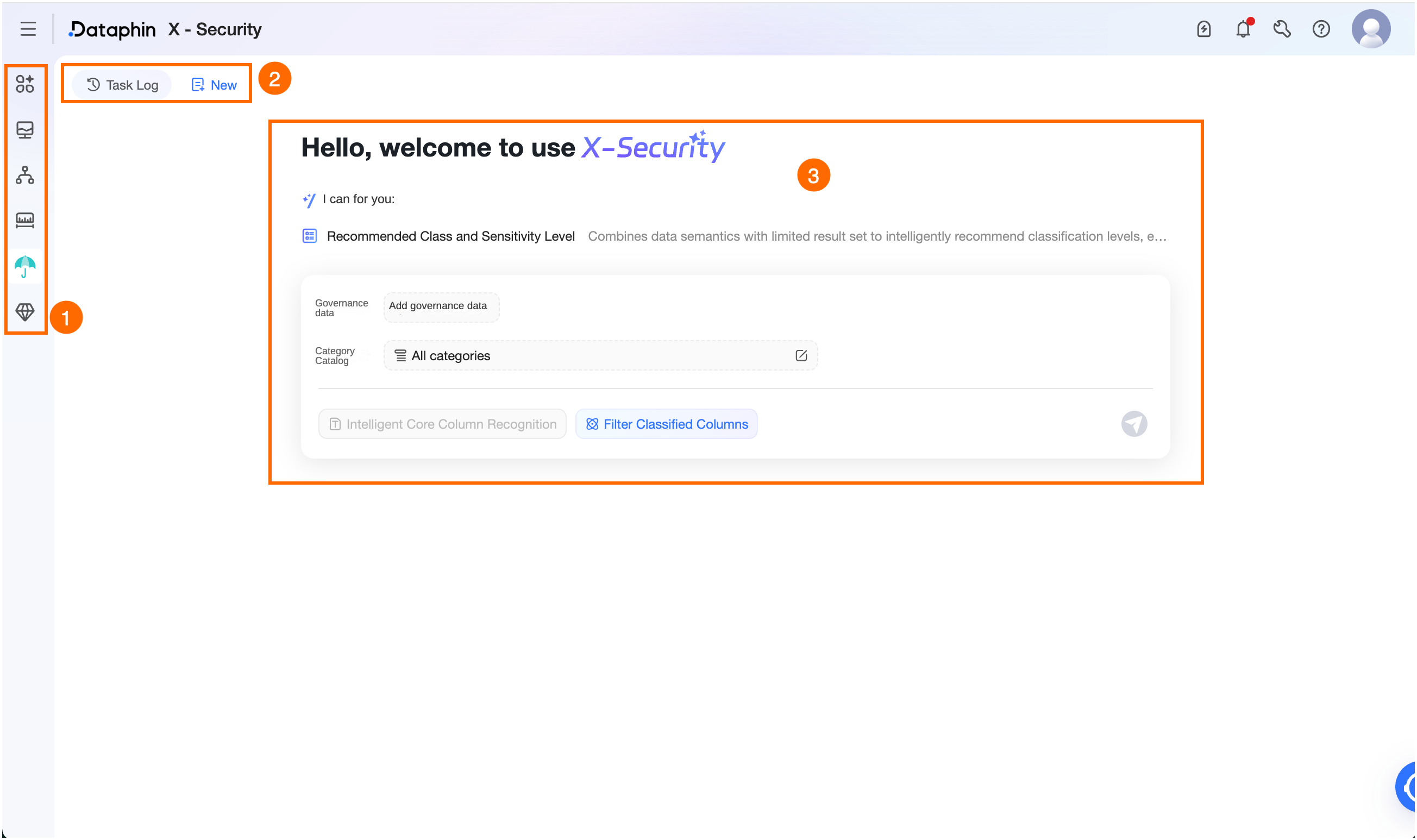
エリア
説明
①インテリジェントアシスタント
使用権限のある有効なインテリジェントアプリケーションを切り替えます。
②タスクレコード/新規タスク
[タスクレコード]:左上隅の [タスクレコード] をクリックします。[タスクレコード] ダイアログボックスで、過去 7 日間または 30 日間の最大 20 件のタスクレコードを表示し、次の操作を実行できます。
検索とフィルター: キーワードでタスクレコードを検索します。フィルターアイコンをクリックして、ガバナンス操作またはデータソースでフィルターすることもできます。
名前の変更: タスクレコード名の横にある 名前の変更 アイコンをクリックして名前を変更します。名前は最大 256 文字です。
削除: タスクレコード名の横にある 削除 アイコンをクリックして、単一のタスクレコードを削除します。
[新規タスク]: 左上隅にある [新規タスク] をクリックして、新しいタスクページを開きます。
③分類と等級付けのためのインテリジェントな推奨
識別結果が必要な資産ソースからデータ範囲を選択します。
[データの追加]:資産のソースデータを追加します。プロジェクトには物理テーブルのみが含まれ、ビジネスセグメントには論理テーブルのみが含まれます。[ガバナンス対象データを選択] または [データソースの追加] ボタンをクリックします。[データソースの追加] パネルで、資産オブジェクトを選択し、[OK] をクリックします。最大 5 つのデータソースを選択できます。
資産の検索とフィルター: キーワードで資産を検索します。環境または資産タイプでフィルターすることもできます。
資産ルール構成:資産を選択した後、[データ範囲] の下にある [編集] アイコンをクリックします。[データ範囲の構成] ダイアログボックスで、資産のデータ範囲を構成し、[OK] をクリックします。
[データ範囲]:[すべてのテーブル] または [指定テーブル] を選択できます。[指定テーブル] を選択した場合、完全なテーブル名、資産チェックリストタグ、テーブルの説明、または db/schema (このプロパティはデータソースのオリジンでのみサポートされます) に基づいてフィルター条件を構成し、より細かい粒度で資産をフィルターできます。最大 10 個のフィルター条件を構成できます。フィルター条件間の関係は AND または OR にすることができます。
[完全なテーブル名]/[テーブルの説明]/[db/schema]:サポートされているフィルター条件は、プレフィックス一致、サフィックス一致、次を含む (テーブルの説明のみ)、および次に属する (db/schema のみ) です。
[プレフィックス一致]、[サフィックス一致]、[次を含む]:最大 256 文字を入力します。
[次に属する]:現在の資産ソースから、対応するタイプの資産オブジェクトを最大 500 個選択します。
[資産チェックリストタグ]: サポートされているフィルター条件は、いずれかを含む、およびすべてを含むです。
[いずれかを含む]: 資産チェックリストタグに選択されたタグ値のいずれかが含まれている場合、条件が満たされます。
[すべてを含む]:資産チェックリストタグに選択したすべてのタグ値が含まれている場合、条件が満たされます。
[すべての分類ディレクトリ]:選択したデータ分類ディレクトリに基づいて、選択したデータ資産のデータ分類を推奨します。これにより、分類と等級付けの精度が向上します。新しいデータ分類を作成するには、[移動] をクリックして [ガバナンス] > [データセキュリティ] > [データ分類] ページに移動します。
[コアフィールドのインテリジェント検出]:有効にすると、タスクの実行時に、システムが選択したデータ範囲に対してセマンティクス分析を実行してコアフィールドを検出し、分類と等級を推奨します。無効にすると、システムは選択した資産オブジェクトのすべてのフィールドに対して分類と等級を推奨します。
重要コアフィールドをインテリジェントに識別することで、無関係な情報による干渉を減らすことができます。ただし、これにより、ガバナンスが必要ないくつかのオブジェクトが見過ごされる可能性もあることに注意してください。
[分類済みフィールドをフィルター]:選択すると、自動または手動識別によって既に識別結果があるフィールドに対しては、識別結果の推奨は提供されません。
実行開始:データ範囲を構成した後、
 アイコンをクリックしてタスクをトリガーします。
アイコンをクリックしてタスクをトリガーします。タスク実行フローの詳細については、「データ分類と等級付けのインテリジェント推奨フロー」をご参照ください。タスクが正常に実行された後、インテリジェントな識別結果を表示できます。
識別結果の管理
識別結果の推奨リストには、構成した資産に対して生成された結果が表示されます。これらの結果は、セマンティクス分析、分類、および等級付けに基づいて大規模言語モデルからインテリジェントに推奨されたものです。
データテーブル、フィールド、または分類の名前で検索できます。データソースまたは分類ディレクトリでフィルターしたり、ステータスが [レビュー待ち] または [適用失敗] の識別結果をフィルターしたりすることもできます。
リストには、識別された各オブジェクトの親テーブル/データソース、フィールド、データ分類、データ等級、およびレビューのステータスが表示されます。
親テーブル/データソース:Dataphin の物理テーブルの場合、プロジェクト名が表示されます。論理テーブルの場合、ビジネスセグメント名が表示されます。データソースの場合、db/schema (親データソース) が表示されます。名前をクリックすると、[ガバナンス] > [資産チェックリスト] のオブジェクトの詳細ページに移動して、より多くの資産情報を表示できます。
データ分類:分類名をクリックすると、[分類の表示] ダイアログボックスでオブジェクトに適用されている分類の詳細を表示できます。
識別結果に対して次の操作を実行できます。
操作
説明
適用
この操作は、レビュー ステータスが [レビュー待ち]、[適用失敗]、または [破棄済み] の場合に利用できます。これにより、現在の識別結果が [ガバナンス] > [データセキュリティ] > [識別結果] リストに追加されます。単一の結果を適用するには、[操作] 列の [適用] アイコンをクリックします。バッチ適用の場合は、ステータスが [レビュー待ち] または [適用失敗] の結果を選択して適用できます。
破棄
この操作は、レビュー ステータスが [レビュー待ち] または [適用失敗] の場合に利用できます。単一の識別結果を破棄するには、[操作] 列の [破棄] アイコンをクリックします。バッチ破棄の場合は、ステータスが [レビュー待ち] または [適用失敗] の結果を選択して破棄できます。結果が破棄された後、変更を加えれば再度適用できます。
識別結果の削除
この操作は、レビュー ステータスが [適用済み] の場合に利用できます。これにより、現在の識別結果が削除されます。[データセキュリティ] ページで、識別結果をバッチでインポートするか、識別ルールを作成することで、再度追加できます。