Hive 出力コンポーネントは、データを Hive データソースに書き込みます。他のデータソースから Hive へデータを同期する場合、まずソースデータソースの設定を行い、その後で Hive 出力コンポーネントを設定します。本トピックでは、Hive 出力コンポーネントの設定方法について説明します。
制限事項
Hive 出力コンポーネントは、以下のファイル形式の Hive テーブルへのデータ書き込みをサポートしています:orc、parquet、text、Hudi、Iceberg、および Paimon。Hudi 形式は、Hive コンピュートソースまたは Cloudera Data Platform 7.x 上のデータソースでのみサポートされます。Iceberg および Paimon 形式は、E-MapReduce 5.x 上の Hive コンピュートソースまたはデータソースでのみサポートされます。また、このコンポーネントは、ORC トランザクションテーブルおよび Kudu テーブルに対するデータ統合には対応していません。
Kudu テーブルのデータ統合では、Impala 出力コンポーネントを使用します。詳細については、「Impala 出力コンポーネントの設定」をご参照ください。
前提条件
Hive データソースが作成されています。詳細については、「Hive データソースを作成する」をご参照ください。
Hive 出力コンポーネントのプロパティを設定するアカウントには、データソースに対するリードスルー権限が必要です。この権限がない場合は、データソースの権限をリクエストできます。詳細については、「データソースの権限をリクエストする」をご参照ください。
操作手順
Dataphin のホームページで、上部メニューバーから [開発者] > [Data Integration] を選択します。
統合ページの上部メニューバーで、[プロジェクト] を選択します。Dev-Prod モードを使用している場合は、さらに [環境] も選択します。
左側ナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] 一覧から、開発対象のバッチパイプラインをクリックし、その構成ページを開きます。
ページ右上隅で、[コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] を選択します。出力コンポーネント一覧から [Hive] コンポーネントを見つけ、キャンバスにドラッグします。
対象の入力・変換・フローウィジェットの
 アイコンをクリックしてドラッグし、現在の Hive 出力ウィジェットに接続します。
アイコンをクリックしてドラッグし、現在の Hive 出力ウィジェットに接続します。Hive 出力コンポーネントカード上の
 アイコンをクリックして、[Hive 出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[Hive 出力設定] ダイアログボックスを開きます。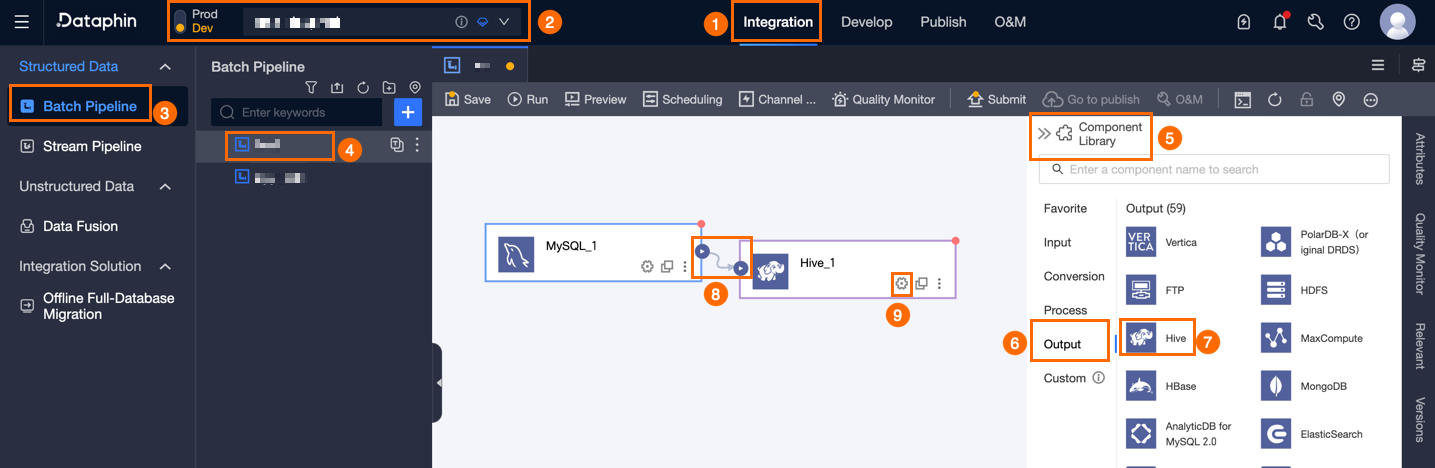
[Hive 出力設定] ダイアログボックスで、パラメーターを設定します。
パラメーターは、Hive テーブルと Hudi テーブルで異なります。
出力先テーブルが Hive テーブルの場合
パラメーター
説明
[基本設定]
[ステップ名]
Hive 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
名前には、漢字、英字、アンダースコア (_ )、数字を含めることができます。
名前の長さは最大 64 文字までです。
データソース
ドロップダウンリストには、ライトスルー権限を持つものも含め、すべての Hive データソースが表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限がないデータソースの場合、データソースの横にある[適用]をクリックして、データソースのライトスルー権限を申請できます。詳細については、「データソース権限の申請」をご参照ください。
Hive データソースがない場合は、[新規データソース] をクリックして作成します。詳細については、「Hive データソースの作成」をご参照ください。
テーブル
出力データの宛先テーブル(Hive テーブル)を選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して [完全一致検索] をクリックできます。テーブルを選択すると、システムが自動的にテーブルの状態を確認します。現在選択中のテーブル名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。データ同期の対象テーブルが Hive データソースに存在しない場合、ワンクリックテーブル作成機能を使用して素早く作成できます。以下の手順に従ってください:
[ワンクリックテーブル作成] をクリックします。Dataphin が対象テーブル作成用のコードを自動生成します。これには、デフォルトでソーステーブル名が採用される対象テーブル名と、Dataphin フィールドに基づく初期変換後のフィールドタイプが含まれます。
[データレイクテーブル形式] を [なし] または [Iceberg] に設定します。
説明データレイクテーブル形式が選択されたデータソースまたは現在のプロジェクトで使用されるコンピュートソースで有効化されており、かつ Iceberg に設定されている場合にのみ、Iceberg を選択できます。
[実行エンジン] を [Hive] または [Spark] に設定します。
説明データレイクテーブル形式が [Iceberg] に設定されている場合にのみ、実行エンジンを選択できます。選択されたデータソースで Spark が設定されている場合は、Spark がデフォルトで表示・選択されます。それ以外の場合は、Hive のみが表示・選択されます。
選択されたデータレイクテーブル形式および実行エンジンに基づいて DDL 文が自動生成されます。必要に応じて編集可能です。完了後、[作成] をクリックします。対象テーブルが作成されると、Dataphin が自動的にそれを出力先として使用します。
説明開発環境に同名のテーブルが既に存在する場合、Dataphin が「テーブルが既に存在します」というエラーを報告します。
一致する項目がない場合でも、テーブル名を手動で入力することでデータ統合を実行できます。
[本番テーブル未存在時のポリシー]
本番テーブルが存在しない場合に適用するポリシーです。[何もしない] または [自動作成] を選択できます。デフォルトは [自動作成] です。[何もしない] を選択した場合、ノード公開時にテーブルは作成されません。[自動作成] を選択した場合、ノード公開時にターゲット環境に同名のテーブルが作成されます。
[何もしない]:対象テーブルが存在しない場合、ノード送信時に「テーブルが存在しません」というメッセージが表示されますが、公開は可能です。この場合、ノードを実行する前に、本番環境で対象テーブルを作成する必要があります。
[自動作成]:[DDL 文の編集] をクリックします。選択されたテーブルの DDL 文が自動的に挿入され、必要に応じて調整できます。DDL 文内のテーブル名には、
${table_name}プレースホルダーのみ使用可能です。これは実行時に実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはまず DDL 文を使用してテーブルを作成しようと試みます。テーブル作成に失敗した場合、公開前のチェックが失敗します。エラーメッセージに基づいて DDL 文を修正し、再度ノードを公開できます。対象テーブルが既に存在する場合は、DDL 文は実行されません。
説明このパラメーターは、Dev-Prod モードを使用するプロジェクトでのみサポートされます。
ファイルエンコーディング
Hive に格納されるファイルのエンコーディング方式を選択します。[ファイルエンコーディング] には、[UTF-8] および [GBK] があります。
読み込みポリシー
ターゲットデータソース(Hive データソース)のテーブルへのデータ書き込み戦略です。ロードポリシーには、[全データ上書き]、[データ追加]、および [統合タスクによって書き込まれたデータのみ上書き] があります。各シナリオは以下のとおりです:
[全データ上書き]:対象テーブルまたはパーティションからすべてのデータを削除し、テーブル名をプレフィックスとする新しいデータファイルを追加します。
[データ追加]:データを直接対象テーブルに追加します。
[統合ノードによって書き込まれたデータのみ上書き]:対象テーブルまたはパーティションから、テーブル名をプレフィックスとするデータファイルを削除します。SQL ステートメントなど、他の手段で書き込まれたデータは削除されません。
[NULL 値の置き換え](任意)
このパラメーターは、
textfileデータストレージ形式のソーステーブルでのみサポートされます。NULLに置き換える文字列を入力します。たとえば、\Nを入力すると、システムが文字列\NをNULLに置き換えます。[フィールド区切り文字](任意)
このパラメーターは、
textfileデータストレージ形式のソーステーブルでのみサポートされます。フィールド間の区切り文字を入力します。空白のままにした場合、システムはデフォルトで\u0001を区切り文字として使用します。[圧縮形式](任意)
ファイルの圧縮形式です。利用可能な形式は、Hive 内のデータストレージ形式によって異なります:
データストレージ形式が orc の場合、zlib または snappy を選択できます。
データストレージ形式が parquet の場合、snappy または gzip を選択できます。
データストレージ形式が textfile の場合、gzip、bzip2、 lzo、lzo_deflate、hadoop-snappy、または zlib を選択できます。
[フィールド区切り文字の処理](任意)
このパラメーターは、
textfileデータストレージ形式の出力テーブルでのみサポートされます。データにデフォルトまたはカスタムのフィールド区切り文字が含まれる場合、[フィールド区切り文字の処理] ポリシーを設定して、データ書き込みエラーを防止できます。[保持]、[削除]、または [置き換え] を選択できます。[行区切り文字の処理](任意)
このパラメーターは、
textfileデータストレージ形式の出力テーブルでのみサポートされます。データにデフォルトまたはカスタムの行区切り文字が含まれる場合、[行区切り文字の処理] ポリシーを設定して、データ書き込みエラーを防止できます。デフォルトの行区切り文字は\nです。データに\rや\nなどの改行文字が含まれる場合、エラーを防ぐために処理ポリシーを選択します。[保持]、[削除]、または [置き換え] を選択できます。[Hadoop パラメーター設定](任意)
書き込みパラメーターを調整するために使用します。テーブルの種類に応じて異なるパラメーターを入力できます。複数のパラメーターはカンマ (,) で区切り、
{"key1":"value1", "key2":"value2"}の形式で指定します。たとえば、多くのフィールドを持つ ORC 出力テーブルの場合、利用可能なメモリ量に基づいて{"hive.exec.orc.default.buffer.size"}パラメーターを調整できます。十分なメモリがある場合は、この値を増加させて書き込みパフォーマンスを向上させることを推奨します。メモリ不足の場合は、GC 時間を短縮して書き込みパフォーマンスを向上させるために、この値を減らすことを推奨します。デフォルト値は 16384 bytes(16 KB)です。推奨上限値は 262144 bytes(256 KB)です。パーティション
選択された対象テーブルがパーティションテーブルである場合、パーティション情報を入力する必要があります。例:
state_date=20190101。また、パラメーターを使用して毎日増分でデータを書き込むこともできます。例:state_date=${bizdate}。[準備ステートメント](任意)
データインポート前にデータベース上で実行する SQL スクリプトです。
たとえば、サービスの継続的な可用性を確保するために、このステップの実行前にターゲットテーブル Target_A を作成できます。このステップでは Target_A にデータを書き込みます。ステップ終了後、既存のサービステーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームしてから Temp_C を削除できます。
[完了ステートメント](任意)
データインポート後にデータベース上で実行する SQL スクリプトです。
フィールド マッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドを表示します。
出力フィールド
出力フィールド領域には、選択されたテーブルのすべてのフィールドが表示されます。
重要データがエラーなく Hive に書き込まれるようにするため、すべての出力フィールドを入力フィールドにマッピングする必要があります。
マッピング
上流の入力および対象テーブルのフィールドに基づいて、手動でフィールドマッピングを選択できます。[マッピング] には、[同一行マッピング] および [同一名称マッピング] があります。
[名称によるマッピング]:名称が同じフィールドをマッピングします。
[行によるマッピング]:ソーステーブルとターゲットテーブルのフィールド名が異なっていても、同一行のフィールド間でデータをマッピングします。同一行のフィールドのみがマッピングされます。
出力先テーブルが Hudi テーブルの場合
パラメーター
説明
[基本設定]
[ステップ名]
Hive 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
名前には、漢字、英字、アンダースコア (_ )、数字を含めることができます。
名前の長さは最大 64 文字までです。
[データソース]
ドロップダウンリストには、ライトスルー権限を持つものも含め、すべての Hive データソースが表示されます。現在のデータソース名をコピーするには、
アイコンをクリックします。ライトスルー権限を持たないデータソースについては、データソースの横にある [Apply] をクリックして、ライトスルー権限をリクエストできます。詳細な手順については、「データソースの権限をリクエストする」をご参照ください。
Hive データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「Hive データソースの作成」をご参照ください。
表
出力データの対象テーブル(Hudi テーブル)を選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して [完全一致検索] をクリックできます。テーブルを選択すると、システムが自動的にテーブルの状態を確認します。現在選択中のテーブル名をコピーするには、
アイコンをクリックします。データ同期の対象テーブルが Hive データソースに存在しない場合、ワンクリックテーブル作成機能を使用して素早く作成できます。以下の手順に従ってください:
[ワンクリックテーブル作成] をクリックします。Dataphin が対象テーブル作成用のコードを自動生成します。これには、デフォルトでソーステーブル名が採用される対象テーブル名と、Dataphin フィールドに基づく初期変換後のフィールドタイプが含まれます。
[データレイクテーブル形式] を [Hudi] に設定します。
[Hudi テーブルタイプ]: [MOR (merge on read)] または [COW (copy on write)] を選択できます。デフォルトは MOR (merge on read) です。
[プライマリキーのフィールド](任意):プライマリキーのフィールドを入力します。複数のフィールドはカンマ (,) で区切ります。
[拡張プロパティ](任意):Hudi でサポートされる設定プロパティを
k=vの形式で入力します。説明開発環境に同名のテーブルが既に存在する場合、[作成] をクリックしたときに Dataphin が「テーブルが既に存在します」というエラーを報告します。
一致する項目がない場合でも、テーブル名を手動で入力することでデータ統合を実行できます。
[実行エンジン] を [Hive] または [Spark] に設定します。
説明データレイクテーブル形式が [Hudi] に設定されている場合にのみ、実行エンジンを選択できます。デフォルトの実行エンジンは Hive です。選択されたデータソースで Spark が有効になっている場合は、Spark を選択できます。
選択されたデータレイクテーブル形式および実行エンジンに基づいて DDL 文が自動生成されます。必要に応じて編集可能です。完了後、[作成] をクリックします。
[本番テーブル未存在時のポリシー]
本番テーブルが存在しない場合に適用するポリシーです。[何もしない] または [自動作成] を選択できます。デフォルトは [自動作成] です。[何もしない] を選択した場合、ノード公開時にテーブルは作成されません。[自動作成] を選択した場合、ノード公開時にターゲット環境に同名のテーブルが作成されます。
[何もしない]:対象テーブルが存在しない場合、ノード送信時に「テーブルが存在しません」というメッセージが表示されますが、公開は可能です。この場合、ノードを実行する前に、本番環境で対象テーブルを作成する必要があります。
[自動作成]:[DDL 文の編集] をクリックします。選択されたテーブルの DDL 文が自動的に挿入され、必要に応じて調整できます。DDL 文内のテーブル名には、
${table_name}プレースホルダーのみ使用可能です。これは実行時に実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはまず DDL 文を使用してテーブルを作成しようと試みます。テーブル作成に失敗した場合、公開前のチェックが失敗します。エラーメッセージに基づいて DDL 文を修正し、再度ノードを公開できます。対象テーブルが既に存在する場合は、DDL 文は実行されません。
説明このパラメーターは、Dev-Prod モードを使用するプロジェクトでのみサポートされます。
パーティション
選択された対象テーブルがパーティションテーブルである場合、パーティション情報を入力する必要があります。例:
state_date=20190101。また、パラメーターを使用して毎日増分でデータを書き込むこともできます。例:state_date=${bizdate}。読み込みポリシー
ターゲットデータソース(Hive)へのデータ書き込みポリシーです。[データ上書き]、[データ追加]、および [データ更新] から選択できます。
[データ上書き]:既存のデータを新しいデータで置き換えます。
[データ追加]:データを直接対象テーブルに追加します。
[データ更新]:プライマリキーに基づいてレコードを更新します。レコードが存在しない場合は挿入されます。
説明SQL ステートメントなど、他の手段で書き込まれたデータは削除されません。
バルクインサート
大量のデータを高速に一括同期するのに適しています。通常、初期データインポートに使用されます。
説明このパラメーターは、ロードポリシーが [データ追加] または [データ上書き] に設定されている場合にのみサポートされ、デフォルトで有効になります。
[バッチ書き込み]
データを対象テーブルにバッチ単位で書き込むことができます。この機能を有効化した場合、[バッチ比率] の設定も必須です。
バッチ比率
Java 仮想マシン (JVM) メモリの合計に対する割合です。デフォルト値は 0.2 です。0.01 ~ 0.50 の範囲で小数値を入力できます。
[Hadoop パラメーター設定](任意)
書き込みパラメーターを調整するために使用します。テーブルの種類に応じて異なるパラメーターを入力できます。複数のパラメーターはカンマ (,) で区切り、
{"key1":"value1", "key2":"value2"}の形式で指定します。{"hoodie.parquet.compression.codec":"snappy"}パラメーターを使用して、圧縮形式を snappy に変更できます。フィールド マッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドを表示します。
[出力フィールド]
出力フィールド領域には、選択されたテーブルのすべてのフィールドが表示されます。
説明Hudi テーブルの場合は、すべてのフィールドをマッピングする必要はありません。
マッピング
上流の入力および対象テーブルのフィールドに基づいて、手動でフィールドマッピングを選択できます。[マッピング] には、[同一行マッピング] および [同一名称マッピング] があります。
[名称によるマッピング]:名称が同じフィールドをマッピングします。
[行によるマッピング]:ソーステーブルとターゲットテーブルのフィールド名が異なっていても、同一行のフィールド間でデータをマッピングします。同一行のフィールドのみがマッピングされます。
出力先テーブルが Paimon テーブルの場合
パラメーター
説明
[基本設定]
[ステップ名]
Hive 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
名前には、漢字、英字、アンダースコア (_ )、数字を含めることができます。
名前の長さは最大 64 文字までです。
[データソース]
ドロップダウンリストには、ライトスルー権限を持つものも含め、すべての Hive データソースが表示されます。現在のデータソース名をコピーするには、
アイコンをクリックします。ライトスルー権限がないデータソースの場合、その横にある [要求] をクリックして、権限を申請できます。詳細については、「データソースの権限を申請する」をご参照ください。
Hive データソースがない場合は、[データソースの作成] をクリックしてデータソースを作成します。詳細については、「Hive データソースの作成」をご参照ください。「」をご参照ください。
表
出力データの対象テーブル(Paimon テーブル)を選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して [完全一致検索] をクリックできます。テーブルを選択すると、システムが自動的にテーブルの状態を確認します。現在選択中のテーブル名をコピーするには、
アイコンをクリックします。データ同期の対象テーブルが Hive データソースに存在しない場合、ワンクリックテーブル作成機能を使用して素早く作成できます。以下の手順に従ってください:
[ワンクリックテーブル作成] をクリックします。Dataphin が対象テーブル作成用のコードを自動生成します。これには、デフォルトでソーステーブル名が採用される対象テーブル名と、Dataphin フィールドに基づく初期変換後のフィールドタイプが含まれます。
[データレイクテーブル形式] を [なし]、[Iceberg]、または [Paimon] に設定します。
説明データレイクテーブル形式が選択されたデータソースまたは現在のプロジェクトで使用されるコンピュートソースで有効化されており、かつ Iceberg に設定されている場合にのみ、Iceberg を選択できます。
[実行エンジン] を [Hive] または [Spark] に設定します。
説明データレイクテーブル形式が [Iceberg] または [Paimon] に設定されている場合にのみ、実行エンジンを選択できます。選択されたデータソースで Spark が設定されている場合は、Spark がデフォルトで表示・選択されます。それ以外の場合は、Hive のみが表示・選択されます。
[Paimon テーブルタイプ] については、[MOR](merge on read)、[COW](copy on write)、または [MOW](merge on write)から選択できます。デフォルトは MOR です。
説明データレイクテーブル形式が Paimon に設定されている場合にのみ、Paimon テーブルタイプを設定できます。
選択されたデータレイクテーブル形式および実行エンジンに基づいて DDL 文が自動生成されます。必要に応じて編集可能です。完了後、[作成] をクリックします。対象テーブルが作成されると、Dataphin が自動的にそれを出力先として使用します。
説明開発環境に同名のテーブルが既に存在する場合、[作成] をクリックしたときに Dataphin が「テーブルが既に存在します」というエラーを報告します。
一致する項目がない場合でも、テーブル名を手動で入力することでデータ統合を実行できます。
[本番テーブル未存在時のポリシー]
本番テーブルが存在しない場合に適用するポリシーです。[何もしない] または [自動作成] を選択できます。デフォルトは [自動作成] です。[何もしない] を選択した場合、ノード公開時にテーブルは作成されません。[自動作成] を選択した場合、ノード公開時にターゲット環境に同名のテーブルが作成されます。
[何もしない]:対象テーブルが存在しない場合、ノード送信時に「テーブルが存在しません」というメッセージが表示されますが、公開は可能です。この場合、ノードを実行する前に、本番環境で対象テーブルを作成する必要があります。
[自動作成]:[DDL 文の編集] をクリックします。選択されたテーブルの DDL 文が自動的に挿入され、必要に応じて調整できます。DDL 文内のテーブル名には、
${table_name}プレースホルダーのみ使用可能です。これは実行時に実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはまず DDL 文を使用してテーブルを作成しようと試みます。テーブル作成に失敗した場合、公開前のチェックが失敗します。エラーメッセージに基づいて DDL 文を修正し、再度ノードを公開できます。対象テーブルが既に存在する場合は、DDL 文は実行されません。
説明このパラメーターは、Dev-Prod モードを使用するプロジェクトでのみサポートされます。
読み込みポリシー
ターゲットデータソース(Hive データソース)のテーブルへのデータ書き込み戦略です。ロードポリシーには、[データ追加]、[データ上書き]、および [データ更新] があります。各シナリオは以下のとおりです:
[データ追加]:データを直接対象テーブルに追加します。
[データ上書き]:既存のデータを新しいデータで置き換えます。
[データ更新]:プライマリキーに基づいてレコードを更新します。レコードが存在しない場合は挿入されます。
[NULL 値の置き換え](任意)
このパラメーターは、
textfileデータストレージ形式のソーステーブルでのみサポートされます。NULLに置き換える文字列を入力します。たとえば、\Nを入力すると、システムが文字列\NをNULLに置き換えます。[フィールド区切り文字](任意)
このパラメーターは、
textfileデータストレージ形式のソーステーブルでのみサポートされます。フィールド間の区切り文字を入力します。空白のままにした場合、システムはデフォルトで\u0001を区切り文字として使用します。[フィールド区切り文字の処理](任意)
このパラメーターは、
textfileデータストレージ形式の出力テーブルでのみサポートされます。データにデフォルトまたはカスタムのフィールド区切り文字が含まれる場合、[フィールド区切り文字の処理] ポリシーを設定して、データ書き込みエラーを防止できます。[保持]、[削除]、または [置き換え] を選択できます。[行区切り文字の処理](任意)
このパラメーターは、
textfileデータストレージ形式の出力テーブルでのみサポートされます。データにデフォルトまたはカスタムの行区切り文字が含まれる場合、[行区切り文字の処理] ポリシーを設定して、データ書き込みエラーを防止できます。デフォルトの行区切り文字は\nです。データに\rや\nなどの改行文字が含まれる場合、エラーを防ぐために処理ポリシーを選択します。[保持]、[削除]、または [置き換え] を選択できます。[Hadoop パラメーター設定](任意)
書き込みパラメーターを調整するために使用します。テーブルの種類に応じて異なるパラメーターを入力できます。複数のパラメーターはカンマ (,) で区切り、
{"key1":"value1", "key2":"value2"}の形式で指定します。たとえば、多くのフィールドを持つ ORC 出力テーブルの場合、利用可能なメモリ量に基づいて{"hive.exec.orc.default.buffer.size"}パラメーターを調整できます。十分なメモリがある場合は、この値を増加させて書き込みパフォーマンスを向上させることを推奨します。メモリ不足の場合は、GC 時間を短縮して書き込みパフォーマンスを向上させるために、この値を減らすことを推奨します。デフォルト値は 16384 bytes(16 KB)です。推奨上限値は 262144 bytes(256 KB)です。パーティション
選択された対象テーブルがパーティションテーブルである場合、パーティション情報を入力する必要があります。例:
state_date=20190101。また、パラメーターを使用して毎日増分でデータを書き込むこともできます。例:state_date=${bizdate}。フィールド マッピング
[入力フィールド]
上流コンポーネントの出力に基づいて入力フィールドを表示します。
[出力フィールド]
出力フィールド領域には、選択されたテーブルのすべてのフィールドが表示されます。
重要データがエラーなく Hive に書き込まれるようにするため、すべての出力フィールドを入力フィールドにマッピングする必要があります。
マッピング
上流の入力および対象テーブルのフィールドに基づいて、手動でフィールドマッピングを選択できます。[マッピング] には、[同一行マッピング] および [同一名称マッピング] があります。
[名称によるマッピング]:名称が同じフィールドをマッピングします。
[行によるマッピング]:ソーステーブルとターゲットテーブルのフィールド名が異なっていても、同一行のフィールド間でデータをマッピングします。同一行のフィールドのみがマッピングされます。
[確認] をクリックして、[Hive 出力コンポーネント] の設定を完了します。