Dataphin は、開発されたリアルタイム タスク コードのローカル デバッグまたはセッション クラスタ デバッグのためにデータ サンプリングまたは手動アップロードをサポートしており、コード タスクの正確性を確保し、人為的なミスや漏れを防ぎます。このトピックでは、リアルタイム タスクをデバッグする方法について説明します。
デバッグ方法
ローカル デバッグ方法: この方法は、クラスタを介したデバッグは行わず、デバッグ用のデータはストリーミング データではありません。比較的速いですが、手動でのデータのアップロードまたは入力が必要であり、特定のデータ ソースの自動サンプリングのみをサポートします。
セッション クラスタ デバッグ方法: この方法は、セッション クラスタを介したデバッグを行い、実際のオンライン データとストリーミング データを使用します(つまり、データがソース テーブルに書き込まれると、そのデータの計算結果が直接出力され、実際のオンライン実行タスクの結果と一致するようになります)。この方法では、セッション クラスタは Flink タスクのステータス、ログ、および出力結果のリアルタイム表示を提供し、タスクの動作と出力を観察することでタスクの正確性を検証できます。これにより、タスク コードの反復的な変更とデバッグがサポートされ、問題を迅速に特定して解決できます。
説明セッション クラスタ デバッグ方法のデバッグ結果は、結果テーブルには書き込まれません。
制限事項
Blink は、エンジン バージョン 3.6.0 以上でのみローカル デバッグをサポートします。
DataStream タスクはデバッグではサポートされていません。
セッション クラスタ デバッグ方法は、現在、オープンソースの Flink エンジンを使用し、最新アーキテクチャに基づいてデプロイされているお客様のみをサポートしています。詳細については、プロダクト運用チームにお問い合わせください。
タスクのデバッグ操作エントリ
Dataphin ホームページで、トップメニューバーの [開発] をクリックします。
以下の図の操作ガイドに従って、デバッグするタスクを選択し、タスクの [デバッグ構成] ダイアログ ボックスを開きます。
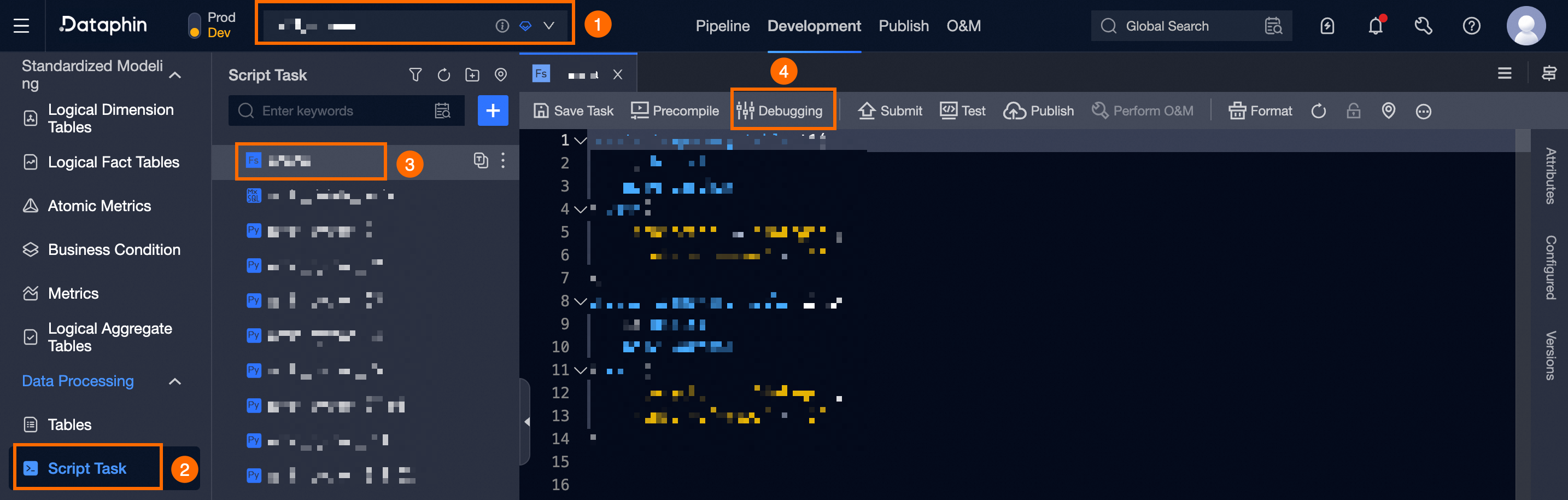
現在、シングル モード デバッグのみがサポートされています。モードを選択した後、対応するモード テーブル データをサンプリングしてデバッグします。
[リアルタイム モード デバッグ]: 対応するリアルタイム物理テーブル データをサンプリングします。データ サンプリングが完了したら、FLINK ストリーム モードローカル デバッグまたはセッション クラスタ デバッグでリアルタイムモードのデバッグを実行します。具体的な操作については、「」をご参照ください。
[オフライン モード デバッグ]: 対応するオフライン物理テーブル データをサンプリングします。データ サンプリングが完了したら、FLINK バッチ モードでローカル デバッグを実行します。具体的な操作については、「オフライン モード デバッグ」をご参照ください。
リアルタイム モード デバッグ
[デバッグ構成] ダイアログ ボックスの [サンプリング モードの選択] タブで、[リアルタイム モード - Flink ストリーム タスク] を選択します。
[次へ] をクリックします。
デバッグ構成ダイアログ ボックスで、デバッグ データ ソースを選択します。
手動でデータをアップロードする (ローカル デバッグ方法)
これは、ローカル デバッグ方法でデバッグするために手動でデータをアップロードすることを伴います。データのアップロード方法には、[サンプル データ ファイルのアップロード]、[データの手動入力]、[データの自動サンプリング] があります。
サンプル データ ファイルを手動でアップロードする
データをアップロードすることで、ローカル データを手動でアップロードできます。ローカル データをアップロードする前に、最初にサンプルをダウンロードする必要があります。サンプルは、Dataphin によって生成された CSV 形式のサンプル テンプレートであり、読み取りテーブルと書き込みテーブル、およびテーブルのスキーマ情報を自動的に識別します。ダウンロードしたサンプルに従って、アップロードするデータを編集できます。[アップロード] をクリックすると、データは [メタデータ サンプリング] 領域に自動的に入力されます。
データの手動入力
これは、収集されたデータが比較的小さい場合、または収集されたデータを変更する必要がある場合に適しています。
データの自動サンプリング
自動的にサンプリングされたデータはランダムであるため、収集されたデータに制限がないシナリオに適しています。データの自動サンプリングは、HBase、MySQL、MaxCompute、DataHub、Kafka データ ソースでサポートされています。[自動サンプリング] をクリックしてデータをサンプリングできます。
説明Kafka は、json、csv、canal-json、maxwell-json、debezium-json データ形式の自動サンプリングをサポートしています。
Kafka の自動サンプリングは、認証なしとユーザー名 + パスワード認証方式のみをサポートし、SSL はサポートしていません。
Kafka の自動サンプリング中は、読み取るデータ範囲を選択でき、最大 100 エントリをサンプリングできます。
すべてのデータ テーブルのメタデータ サンプリングが完了したら、[OK] をクリックします。
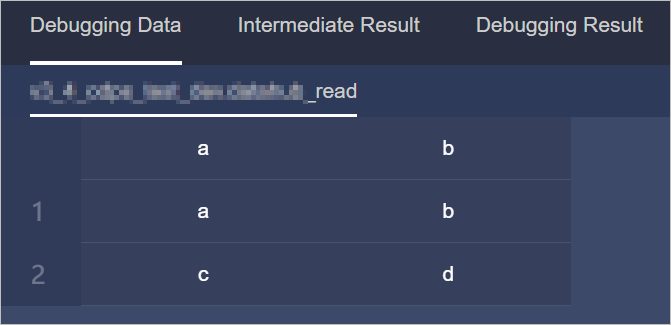
[結果] ページで、[デバッグ結果] を表示できます。
手動でデータをアップロードする (ローカル デバッグ方法)
オンライン データを収集する (セッション クラスタ デバッグ方法)
オフライン モード デバッグ
[デバッグ構成] ダイアログ ボックスの [サンプリング モードの選択] タブで、[オフライン モード - Flink バッチ タスク] を選択します。
[次へ] をクリックします。
デバッグ構成ダイアログ ボックスで、デバッグ データ ソースを選択します。
データを手動でアップロードする (ローカル デバッグ方法)
これは、ローカル デバッグ方法を使用してデバッグするためにデータを手動でアップロードすることを伴います。データ アップロード方法には、[サンプル データ ファイルの手動アップロード]、[データの手動入力]、[データの自動サンプリング] が含まれます。
サンプル データ ファイルを手動でアップロードする
データをアップロードすることで、ローカル データを手動でアップロードできます。ローカル データをアップロードする前に、最初にサンプルをダウンロードする必要があります。サンプルは Dataphin によって生成された CSV 形式のサンプル テンプレートで、読み取りテーブルと書き込みテーブル、およびテーブルのスキーマ情報を自動的に識別します。ダウンロードしたサンプルに従ってアップロードするデータを編集できます。[アップロード] をクリックすると、データは [メタデータ サンプリング] 領域に自動的に入力されます。
データの手動入力
これは、収集されたデータが比較的小さい、または収集されたデータを変更する必要があるシナリオに適しています。
データの自動サンプリング
自動的にサンプリングされたデータはランダムであるため、特定のデータ要件がないシナリオに最適です。HBase、MySQL、MaxCompute、DataHub、および Kafka データ ソースで自動データ サンプリングを使用できます。[自動サンプリング] をクリックしてデータ サンプリングに進みます。
説明Kafka は、json、csv、canal-json、maxwell-json、debezium-json データ形式の自動サンプリングをサポートしています。
Kafka の自動サンプリングは、認証なしとユーザー名 + パスワード認証方式と互換性がありますが、SSL はサポートしていません。
Kafka の自動サンプリングでは、サンプリング中にデータ範囲を選択でき、最大 100 レコードまでサンプリングできます。
すべてのデータ テーブルのメタデータ サンプリングが完了したら、ページ下部の [OK] をクリックします。
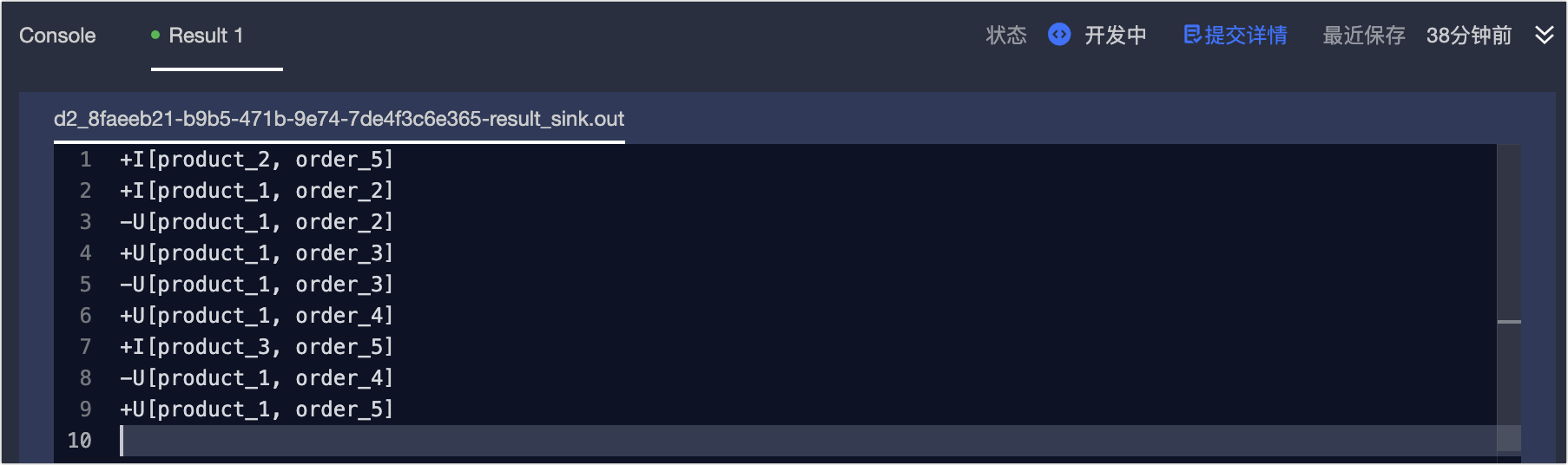
[結果] ページで、[デバッグ データ]、[中間結果]、[デバッグ結果] を確認できます。
付録: 自動的にサンプリングされたデバッグ データ
ローカル デバッグに自動サンプリングを使用する場合、デバッグ データはメタ テーブル構成によって決定されます。以下を考慮してください:
タスクのデバッグ中は、メタ テーブルの [デフォルトの読み取り] プロパティを [開発テーブル] に設定する必要があります。
タスクが
Project_Name_dev.meta_table_nameを参照する場合、開発メタ テーブルがサンプリングされます。データ ソースに開発メタ テーブルが存在しない場合、[自動サンプリング] は使用できません。タスクが
Project_Name.meta_table_nameを使用する場合、本番メタ テーブルが自動的にサンプリングされます。本番環境でこのテーブルに対する権限がない場合は、エラーが発生します。本番テーブルへのアクセスをリクエストする必要があります。詳細については、「テーブル権限を申請する」をご参照ください。タスクが
${Project_Name}.meta_table_nameまたはmeta_table_nameを参照する場合、開発メタ テーブルがサンプリングされます。開発メタ テーブルが使用できない場合、[自動サンプリング] はサポートされていません。
タスクのデバッグ中にメタ テーブルの [デフォルトの読み取り] プロパティが [本番テーブル] に設定されている場合:
タスクが
Project_Name_dev.meta_table_nameを参照する場合、開発テーブルがサンプリングされます。データ ソースに開発メタ テーブルがない場合、[自動サンプリング] は使用できません。タスクが
Project_Name.meta_table_nameを参照する場合、本番メタ テーブルがサンプリングされます。タスクが
${Project_Name}.meta_table_nameまたはmeta_table_nameを参照する場合、システムはパラメータ設定に基づいて${project_name}変数を置き換えます。パラメータで指定された実際のプロジェクト (開発または本番) によって、本番メタ テーブルまたは開発メタ テーブルのどちらが使用されるかが決定されます。${project_name}が設定されていない場合、デフォルトでは本番メタ テーブルがサンプリングされます。