Amazon RDS for MySQL 出力コンポーネントは、Amazon RDS for MySQL データソースにデータを書き込みます。他のデータソースから Amazon RDS for MySQL データソースにデータを同期する場合、ソースデータソースを設定した後に、このコンポーネントを設定する必要があります。このトピックでは、Amazon RDS for MySQL 出力コンポーネントの設定方法について説明します。
前提条件
Amazon RDS for MySQL データソースが作成済みであること。詳細については、「Amazon RDS for MySQL データソースの作成」をご参照ください。
Amazon RDS for MySQL 出力コンポーネントを設定するために使用するアカウントには、データソースに対する書き込み権限が必要です。アカウントにこの権限がない場合は、権限を申請する必要があります。詳細については、「データソース権限の申請、更新、または解放」をご参照ください。
操作手順
Dataphin ホームページの上部のメニューバーで、[開発] > [データ統合] を選択します。
統合ページの上部のメニューバーで、[プロジェクト] を選択します。Dev-Prod モードでは、[環境] を選択します。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、開発するオフラインパイプラインをクリックします。パイプラインの設定ページが開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] をクリックします。右側の出力コンポーネントリストで [Amazon RDS for MySQL] コンポーネントを見つけ、キャンバスにドラッグします。
入力、変換、またはフローコンポーネントから
 アイコンをクリックしてドラッグし、Amazon RDS for MySQL 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、Amazon RDS for MySQL 出力コンポーネントに接続します。Amazon RDS for MySQL 出力コンポーネントカードの
 アイコンをクリックして、[Amazon RDS for MySQL 出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[Amazon RDS for MySQL 出力設定] ダイアログボックスを開きます。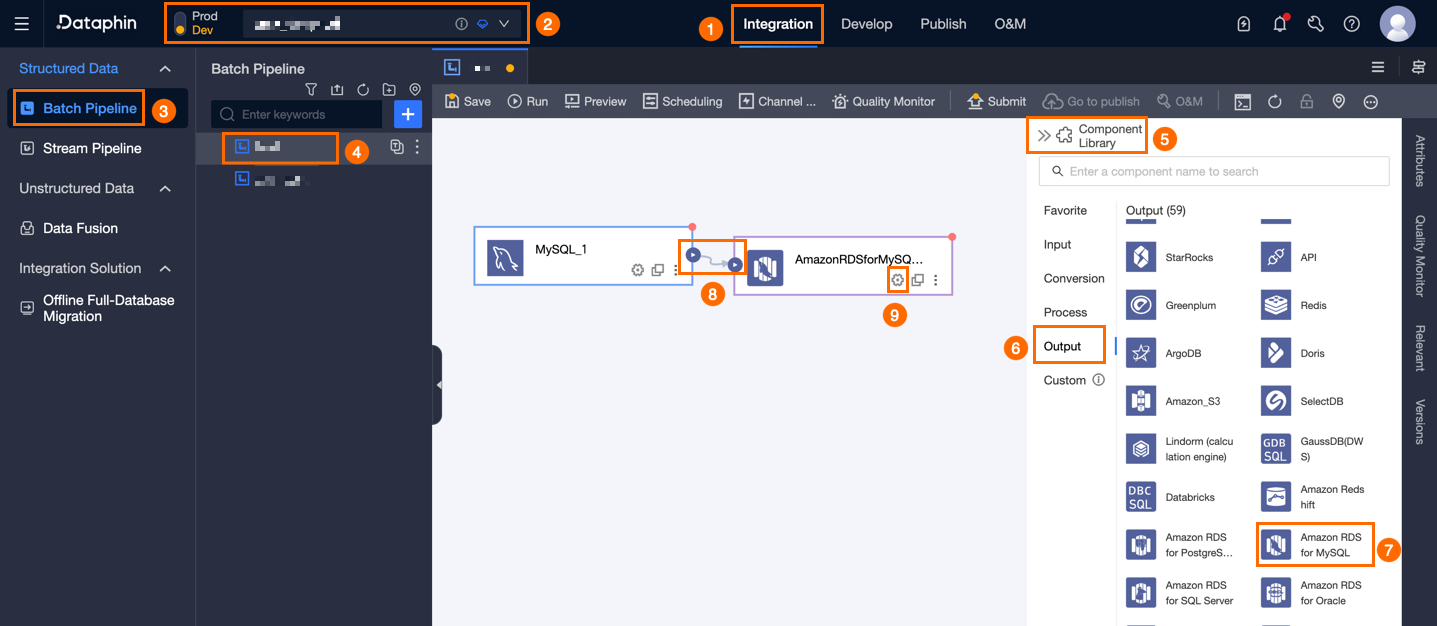
[Amazon RDS for MySQL 出力設定] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
Amazon RDS for MySQL 出力コンポーネントの名前です。Dataphin はステップ名を自動的に生成します。ビジネスシナリオに基づいて変更できます。命名ルールは次のとおりです:
中国語文字、英字、アンダースコア (_)、数字のみを使用できます。
64 文字以内にする必要があります。
データソース
ドロップダウンリストには、すべての Amazon RDS for MySQL データソースが表示されます。これには、書き込み権限を持つデータソースと持たないデータソースの両方が含まれます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。データソースに対する書き込み権限がない場合は、データソースの横にある [申請] をクリックして書き込み権限を申請します。詳細については、「データソース権限の申請、更新、または解放」をご参照ください。
Amazon RDS for MySQL データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「Amazon RDS for MySQL データソースの作成」をご参照ください。
データベース (任意)
テーブルが存在するデータベースを選択します。このフィールドを空白のままにすると、データソースの登録時に指定したデータベースが使用されます。
テーブル
出力データの宛先テーブルを選択します。キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致検索] をクリックします。テーブルを選択すると、システムが自動的にそのステータスを確認します。
 アイコンをクリックすると、選択したテーブル名をコピーできます。
アイコンをクリックすると、選択したテーブル名をコピーできます。ターゲットテーブルが Amazon RDS for MySQL データソースに存在しない場合は、ワンクリックでのテーブル作成機能を使用して迅速に生成できます。手順は次のとおりです:
[ワンクリックでのテーブル作成] をクリックします。Dataphin は、テーブル名 (デフォルト:ソーステーブル名) とフィールドタイプ (Dataphin フィールドに基づいて事前に変換) を含む、宛先テーブルを作成するためのコードを自動的に照合します。
必要に応じてテーブル作成用の SQL スクリプトを修正し、[作成] をクリックします。テーブルが作成されると、Dataphin は自動的にそれを出力データの宛先テーブルとして使用します。
説明開発環境に同じ名前のテーブルが存在する場合、[作成] をクリックすると、テーブルが既に存在するというエラーが返されます。
一致するテーブルが見つからない場合でも、手動で入力したテーブル名を使用して統合できます。
本番テーブルが存在しない場合のポリシー
本番テーブルが存在しない場合に実行する操作です。[何も実行しない] または [自動作成] を選択します。デフォルト: [自動作成]。[何も実行しない] を選択した場合、タスクは本番テーブルを作成せずに公開されます。[自動作成] を選択した場合、タスクは公開時にターゲット環境に同じ名前のテーブルを作成します。
[何も実行しない]: 宛先テーブルが存在しない場合、システムは提出時に警告を表示しますが、公開は許可されます。タスクを実行する前に、本番環境で宛先テーブルを作成する必要があります。
[自動作成]: [CREATE TABLE 文の編集] を行う必要があります。これは、デフォルトで選択されたテーブルの CREATE TABLE 文が事前に入力されています。必要に応じて調整できます。CREATE TABLE 文のテーブル名にはプレースホルダー
${table_name}が使用され、このプレースホルダーのみが許可されます。実行時に、実際のテーブル名に置き換えられます。宛先テーブルが存在しない場合、Dataphin はまずその文を使用してテーブルを作成します。作成に失敗すると、公開も失敗します。エラーメッセージに基づいて文を修正し、再公開してください。宛先テーブルが既に存在する場合、Dataphin はテーブルの作成をスキップします。
説明この設定は、Dev-Prod モードのプロジェクトでのみ利用できます。
読み込みポリシー
宛先テーブルにデータを書き込むためのポリシーを選択します。[ロードポリシー] のオプションは次のとおりです:
[データを追加 (INSERT INTO)]: 宛先テーブルの既存データを変更せずに、データを追加します。プライマリキーまたは制約の違反が発生すると、ダーティデータのエラーが表示されます。
[プライマリキーの競合時に置換 (REPLACE INTO)]: プライマリキーまたは制約が重複する行全体を削除し、新しい行を挿入します。
[プライマリキーの競合時に更新 (ON DUPLICATE KEY UPDATE)]: プライマリキーまたは制約の違反が発生した場合、既存のレコードのマッピングされたフィールドを更新します。
バッチ書き込みサイズ (任意)
一度に書き込まれるデータのサイズです。[バッチ書き込み件数] も設定できます。書き込み中、システムはサイズまたは件数のいずれか先に達した方の制限を使用します。デフォルト: 32 MB。
バッチ書き込み件数 (任意)
デフォルト: 2,048 行。データ同期ではバッチ書き込みが使用されます。パラメーターには [バッチ書き込み件数] と [バッチ書き込みサイズ] があります。
蓄積されたデータ量が、設定されたサイズまたは件数のいずれかの制限に達すると、システムはそれを完全なバッチとみなし、すぐに宛先に書き込みます。
バッチ書き込みサイズを 32 MB に設定することを推奨します。平均レコードサイズに基づいてバッチ書き込み件数を調整してください。バッチ効率を最大化するために、高く設定します。たとえば、各レコードが約 1 KB の場合、バッチ書き込みサイズを 16 MB に設定し、バッチ書き込み件数を 16,384 (16 MB ÷ 1 KB) 以上に設定します。ここでは、20,000 行 を使用します。この設定では、蓄積されたデータが 16 MB に達すると、システムはバッチ書き込みをトリガーします。
事前 SQL 文 (任意)
データインポート前にデータベースで実行する SQL スクリプトです。
たとえば、サービスの可用性を維持するために、データ書き込み前にターゲットテーブル Target_A を作成します。Target_A への書き込み後、本番サービスで利用中のテーブル Service_B を Temp_C に名前変更します。次に、Target_A を Service_B に名前変更します。最後に、Temp_C を削除します。
事後 SQL 文 (任意)
データインポート後にデータベースで実行する SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントからの入力フィールドを一覧表示します。
出力フィールド
出力フィールドを一覧表示します。次の操作が可能です:
フィールドの管理: [フィールド管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、[選択済みの入力フィールド] を [未選択の入力フィールド] に移動します。
アイコンをクリックして、[選択済みの入力フィールド] を [未選択の入力フィールド] に移動します。 アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
バッチ追加: [バッチ追加] をクリックして、JSON、TEXT、または DDL フォーマットでフィールドを設定します。
JSON フォーマットを使用してバッチで設定を構成します。例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name フィールドはフィールド名、type フィールドはデータの型です。たとえば、
"name":"user_id","type":"String"は user_id という名前のフィールドをインポートし、その型を String に設定します。TEXT フォーマットでバッチ設定します。例:
// 例: user_id,String user_name,String行区切り文字はフィールドエントリを区切ります。デフォルト: 改行 (\n)。サポートされている区切り文字: \n、セミコロン (;)、ピリオド (.)。
列区切り文字はフィールド名と型を区切ります。デフォルト: カンマ (,)。
DDL フォーマットの例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: [+ 出力フィールドの作成] をクリックします。[列] 名を入力し、[型] を選択します。
 アイコンをクリックして行を保存します。
アイコンをクリックして行を保存します。
マッピング
上流の入力フィールドと宛先テーブルのフィールドを手動でマッピングします。[マッピング] のオプション: [行マッピング] と [名前マッピング]。
名前マッピング: 同じ名前のフィールドをマッピングします。
行マッピング: ソースと宛先のフィールド名が異なる場合に、位置に基づいてフィールドをマッピングします。
[確認] をクリックして、[Amazon RDS for MySQL] 出力コンポーネントの設定を完了します。