事前準備
MaxCompute テーブルの作成
DataHub を使用すると、MaxCompute テーブルにデータを同期できます。パーティションテーブルと非パーティション化テーブルの両方をサポートしています。MaxCompute でのデータ処理を容易にするために、パーティションテーブルの使用を推奨します。
DataHub を使用して、TUPLE Topic および BLOB Topic から MaxCompute テーブルにデータを同期できます。
TUPLE Topic からデータを同期する場合、送信先 MaxCompute テーブルのデータの型は DataHub のデータの型と一致している必要があります。次の表に、データ型マッピングを示します。
MaxCompute
DataHub
BIGINT
BIGINT
STRING
STRING
BOOLEAN
BOOLEAN
DOUBLE
DOUBLE
DATETIME
TIMESTAMP
DECIMAL
DECIMAL
TINYINT
TINIINT
SMALLINT
SMALLINT
INT
INTEGER
FLOAT
FLOAT
MAP
サポートされていません
ARRAY
サポートされていません
DataHub はすべての MaxCompute のデータの型をサポートしているわけではありません。DataHub のデータの型に基づいて MaxCompute テーブルスキーマを作成する必要があります。
BLOB Topic からデータを同期する場合、MaxCompute テーブルスキーマには STRING 列が 1 つだけ含まれている必要があります。デフォルトでは、DataHub はこの列にデータを同期します。
DataHub
MaxCompute
BLOB
STRING
データ追跡とトラブルシューティングを容易にするために、MaxCompute テーブルスキーマを作成する際に
__rowkey__ STRINGフィールドを追加できます。DataHub は、データのトレース情報をこの列に自動的に同期します。これにより、将来のデータ調査に役立ちます。
同期タスク用アカウントの準備と権限付与
MaxCompute の同期タスクを作成する際は、MaxCompute テーブルにアクセスするために必要なアカウント情報を入力する必要があります。アカウント情報が有効であることを確認してください。通常、MaxCompute RAM ユーザーで十分です。
アカウントには、MaxCompute テーブルにアクセスするために必要な権限を付与する必要があります。これらの権限には、
CreateInstance、Describe、Alter、およびUpdateが含まれます。DataWorks コンソールを使用して MaxCompute テーブルの権限を管理できます。詳細については、「MaxCompute エンジン権限の設定MaxCompute エンジン権限の設定」をご参照ください。また、MaxCompute コマンドラインインターフェイスを使用して権限を付与することもできます。詳細については、「MaxCompute の使用と権限管理」をご参照ください。
TimestampUnit の確認
コネクタの TimestampUnit パラメーターは TIMESTAMP データを変換します。データは指定した単位に基づいて変換され、ダウンストリームシステムの日付型フィールド (datetime フィールドなど) に書き込まれます。
TIMESTAMP 列の値が秒単位の場合は、コネクタを作成する際に TimestampUnit を "SECOND" に設定します。値がミリ秒単位の場合は "MILLISECOND" に、マイクロ秒単位の場合は "MICROSECOND" に設定します。
多数のパーティションは、DataHub からのデータ同期を遅くする可能性があります。これは、MaxCompute の現在の書き込み標準によるものです。MaxCompute 同期タスクを作成する際は、パーティションの数を制限する必要があります。これは、USER_DEFINE 同期モードの場合に特に重要です。
同じパーティション内のデータは、可能な限り連続した状態に保ちます。頻繁なパーティションの変更は避けてください。
パーティションを作成する際は、作成しすぎないでください。
MaxCompute プロジェクトで ホワイトリスト機能 が有効になっている場合、ホワイトリスト内のデバイスのみがプロジェクトにアクセスできます。MaxCompute IP ホワイトリストを有効にした後、同期サービスにアクセスできるようにサービスホワイトリストを構成する必要があります。ホワイトリストの構成方法の詳細については、「概要」をご参照ください。
同期モード
追加モード
データは送信先テーブルに追加されます。このモードは、データの更新ではなく追加のみが必要なシナリオに適しています。
Upsert モード
Upsert は 更新 と 挿入 操作を組み合わせたものです。ロジックは次のとおりです。
送信先テーブルに同じプライマリキーを持つレコードが存在する場合、既存のレコードが更新されます。
同じプライマリキーを持つレコードが存在しない場合、新しいレコードが挿入されます。
Upsert モードを使用すると、データ更新と挿入をより柔軟に処理できます。これにより、送信先テーブルのデータが常に最新の状態に保たれます。
MaxCompute Upsert 機能の詳細については、「用語」をご参照ください。
シナリオ
プライマリキーに基づくデータ更新: データは時間の経過とともに変化する可能性があり、そのプライマリキーに基づいて更新する必要があります。
送信先テーブルでのデータの一意性の維持: データ重複を避けるために、送信先テーブルの各レコードが一意であることを確認します。
重複データの処理: プライマリキーに基づいて大量のデータから重複を削除します。
構成の説明
DataHub Topic タイプ: TUPLE Topic である必要があります。
DataHub Topic スキーマ: 次の 2 種類のタイプがサポートされています。
DTS から DataHub に同期されるデータのスキーマタイプ。これは DTS 形式と呼ばれます。
作成するスキーマでは、操作列として String 列を選択する必要があります。これにより、スキーマがカスタム形式として定義されます。
ODPS 送信先テーブル: トランザクションテーブル 2.0 である必要があります。
同期ルール
1. DTS 形式
DTS から DataHub にデータを同期する場合、DataHub はスキーマ内の operation_flag、before_flag、および after_flag 列を使用して、ODPS 送信先テーブルにデータを同期する方法を決定します。ルールは次のとおりです。
operation_flag | before_flag | after_flag | OperationType | 送信先テーブルへの同期 |
I | * | * | UPSERT | プライマリキーに基づいて送信先テーブルのレコードを更新します。 |
U | Y | N | DELETE | プライマリキーに基づいて送信先テーブルからレコードを削除します。 |
U | N | Y | UPSERT | プライマリキーに基づいて送信先テーブルのレコードを更新します。 |
D | * | * | DELETE | プライマリキーに基づいて送信先テーブルからレコードを削除します。 |
2. カスタム形式
カスタムデータの場合、DataHub は選択した操作列に基づいて、ODPS 送信先テーブルにデータを同期する方法を決定します。
ddddd | OperationType | 送信先テーブルへの同期 |
U | UPSERT | プライマリキーに基づいて送信先テーブルのレコードを更新します。 |
D | DELETE | プライマリキーに基づいて送信先テーブルからレコードを削除します。 |
同期タスクの作成
DataHub で、Topic をクリックしてその詳細ページに移動します。
Topic 詳細ページで、右上隅にある [同期] ボタンをクリックして同期タスクを作成します。

[MaxCompute] ジョブタイプを選択して、コネクタ作成ページに移動します。
構成項目説明:
パラメーター
オプション
必須
説明
プロジェクト名
/
はい
MaxCompute プロジェクトの名前。
スキーマ
/
いいえ
MaxCompute スキーマの名前。
説明スキーマ機能を使用するには、スキーマ構文開発を有効化する必要があります。詳細については、「スキーマ関連操作」をご参照ください。
テーブル
/
はい
MaxCompute テーブルの名前。
説明Upsert モードを使用する場合、送信先テーブルはトランザクションテーブル 2.0 である必要があります。
同期モード
追加
はい
MaxCompute 送信先テーブルにデータを追加します。
Upsert
プライマリキーに基づいて MaxCompute トランザクションテーブルのレコードを更新または削除します。
詳細については、このトピックの「同期モード」セクションをご参照ください。
Upsert メソッド
SYNC_CUSTOM
同期モードを [Upsert] に設定した場合に必須です。同期モードを [追加] に設定した場合は適用されません。
upsert 操作のカスタムフィールド。
SYNC_NONE
すべてのデータは upsert 操作として送信先テーブルに書き込まれます。
SYNC_DTS
DTS から DataHub にデータが書き込まれ、新しい DTS 添付列ルールが有効になっている場合に使用されます。
SYNC_DTS_OLD
これは、DTS を使用して DataHub にデータを書き込み、新しい添付列ルールを有効にするシナリオに適用されます。
プライマリキーフィールド
/
Upsert 同期モードのダウンストリームテーブルを作成する際に指定するプライマリキー列。
Upsert 操作フィールド
/
Upsert メソッドを [SYNC_CUSTOM] に設定した場合に必須です。
操作列として STRING 列を選択します。この列は、データが upsert 操作として送信先テーブルに同期されるか、削除操作として同期されるかを示します。
Upsert モードの詳細については、このトピックの「Upsert モード」セクションをご参照ください。
フィールドのインポート: DataHub は、設定に基づいて指定された列の内容を MaxCompute テーブルに同期できます。
パーティションモード: このモードは、データが書き込まれる MaxCompute パーティションを決定します。DataHub は次のパーティションモードをサポートしています。
パーティションモード
パーティション基準
サポートされている Topic タイプ
説明
USER_DEFINE
レコード内のパーティションキー列の値。この列は、MaxCompute のパーティションフィールドと同じ名前である必要があります。
TUPLE
(1) DataHub スキーマには MaxCompute パーティションフィールドが含まれている必要があります。(2) この列の値は
UTF-8 文字列である必要があります。値は空にすることができ、これはデータがパーティション化されていないことを示します。SYSTEM_TIME
レコードが DataHub に書き込まれた時間。
TUPLE / BLOB
(1) パーティション構成で、MaxCompute パーティションの時間形式を設定します。(2) タイムゾーンを設定します。
EVENT_TIME
レコード内の
event_time(TIMESTAMP)列の値。TUPLE
(1) パーティション構成で、MaxCompute パーティションの時間形式を設定します。(2) タイムゾーンを設定します。
META_TIME
レコードの
__dh_meta_time__属性フィールドの値。TUPLE / BLOB
(1) パーティション構成で、MaxCompute パーティションの時間形式を設定します。(2) タイムゾーンを設定します。
SYSTEM_TIME、EVENT_TIME、およびMETA_TIMEモードは、タイムスタンプとタイムゾーン構成に基づいてデータをパーティション化します。タイムスタンプのデフォルト単位はマイクロ秒です。パーティション構成: タイムスタンプに基づいてデータをパーティション化するための設定を指定します。コンソールはデフォルトで固定の MaxCompute パーティション形式を使用します。パーティション構成は次のとおりです。
パーティション
時間形式
説明
ds
%Y%m%d
日
hh
%H
時
mm
%M
分
パーティション間隔は、タイムスタンプを MaxCompute パーティションに変換するために使用される時間間隔を決定します。時間範囲は
15 分から 1440 分 (1 日)であり、ステップ間隔は15 分です。タイムゾーン (TimeZone): タイムスタンプに基づいてデータをパーティション化するためのタイムゾーンを指定します。
区切り文字: BLOB データを同期する際、MaxCompute に同期する前にデータを分割するために 16 進数区切り文字を指定できます。たとえば、
0Aは改行 (\n)を表します。Base64 エンコーディング: デフォルトでは、DataHub は BLOB データをバイナリデータとして保存します。MaxCompute の対応する列は STRING 型です。したがって、コンソールで同期タスクを作成する際、データは同期前にデフォルトで Base64 エンコードされます。より多くのカスタマイズオプションについては、ソフトウェア開発キット (SDK) を使用できます。
同期タスクの表示
コネクタの詳細ページをクリックすると、同期タスクのステータスとチェックポイント情報を表示できます。これには、同期チェックポイント、同期ステータス、および再起動や停止などの操作が含まれます。次の図に例を示します。
同期例
1. USER_DEFINE 同期モード
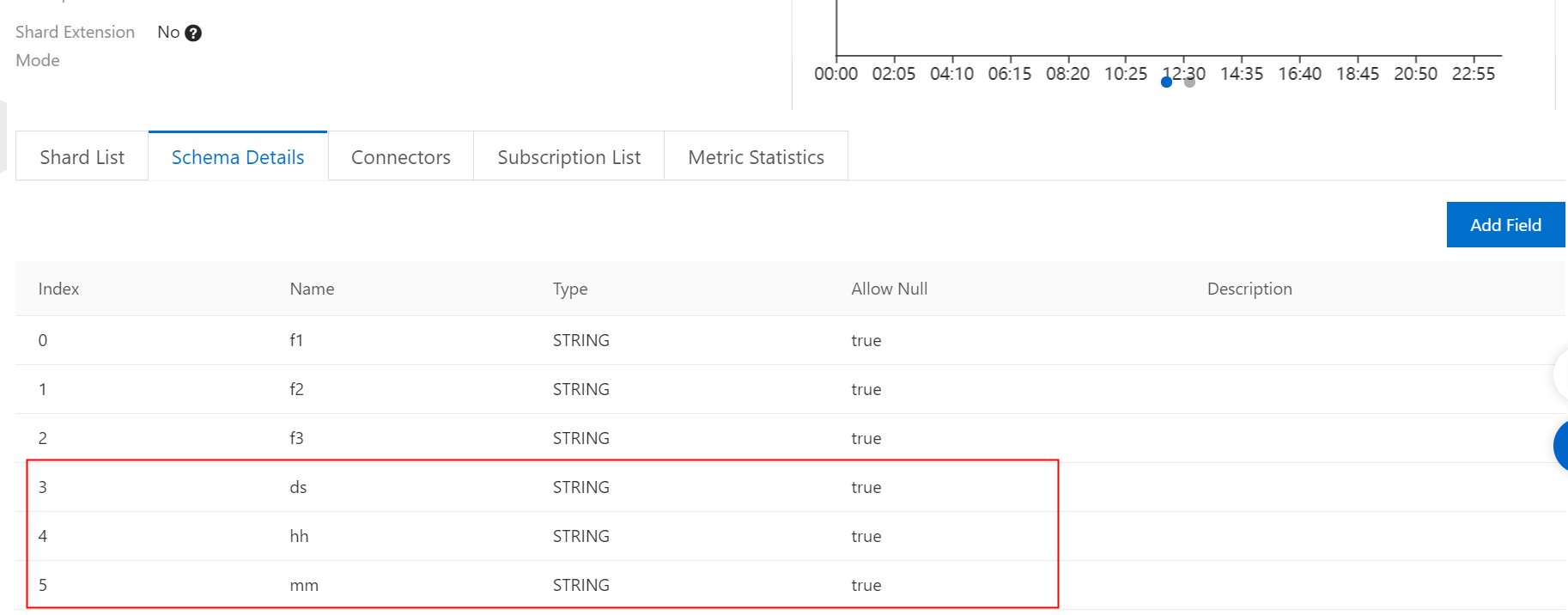
DataHub Topic の作成。
注: Topic スキーマには MaxCompute パーティションフィールドが含まれている必要があります。フィールドは、次の図に示すように STRING 型である必要があります:
DataHub Topic へのデータ書き込み。DataHub SDK を使用してデータを書き込むことができます。
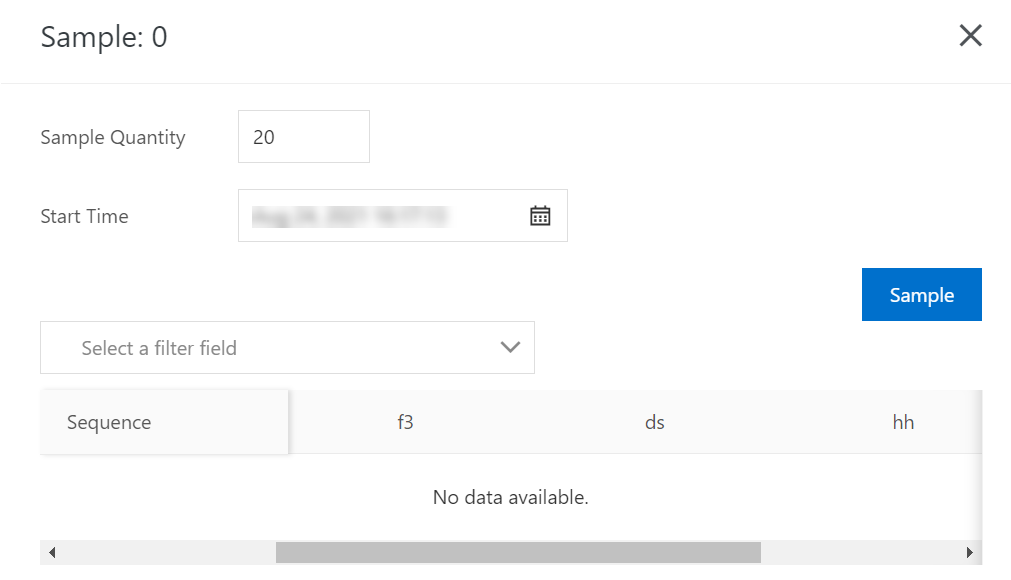
テスト中に、SDK を使用して複数のレコードを書き込みます。[ds,hh,mm] の値は [20210304,01,15] と [20210304,02,15] です。データは次のとおりです。
3. 同期タスクの作成。
USER_DEFINE パーティションモードでは、同期中にパーティション構成フィールドを設定できます。MaxCompute に対応するテーブルが存在しない場合、自動的に作成されます。
この例では、f1 フィールドと f2 フィールドがインポートされます。f3 フィールドは同期されません。
4. 同期データの確認。
DataHub コンソールで同期タスクの同期情報を表示できます。MaxCompute でデータをクエリします。結果は次のとおりです: 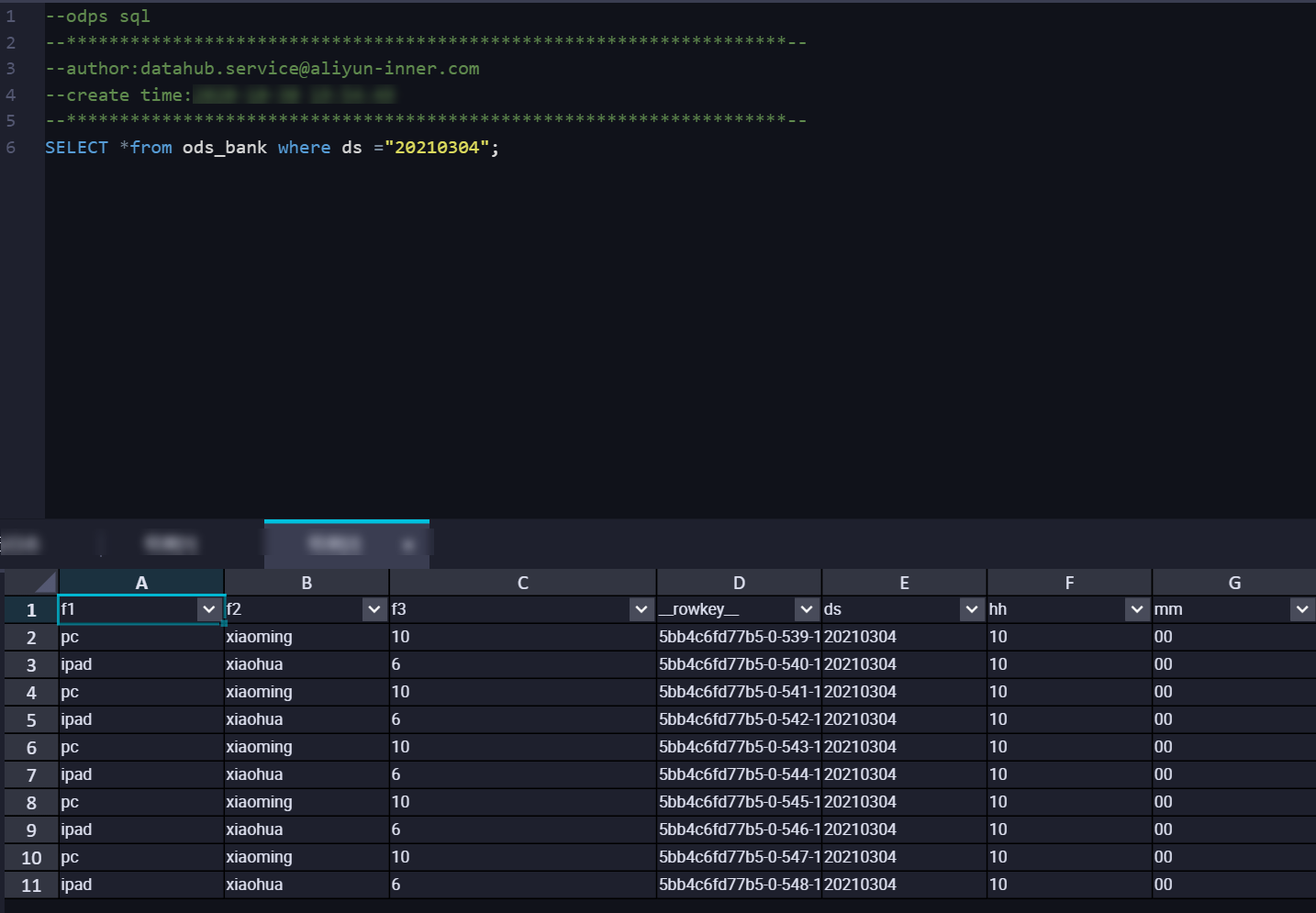 USER_DEFINE モードでは、DataHub は
USER_DEFINE モードでは、DataHub は MaxCompute グループ化フィールドの値に基づいて、対応するパーティションにデータを同期します。
2. SYSTEM_TIME 同期モード
DataHub Topic の作成。
注: パーティションは、データが DataHub に書き込まれた時間に基づいて計算されます。したがって、Topic スキーマには、次の図に示すように、パーティションフィールドではなくデータフィールドのみが含まれている必要があります。

DataHub Topic へのデータ書き込み。DataHub SDK を使用してデータを書き込むことができます。
テスト中に、SDK を使用して複数のレコードを書き込みます。データが DataHub に書き込まれた時間は
2021-03-04 14:02:45です。データは次のとおりです:
同期タスクの作成。
パーティション構成が MaxCompute テーブルパーティションと一致していることを確認します。
4. 同期データの確認。
DataHub コンソールで、DoneTime などの同期タスクの同期情報を表示できます。MaxCompute でデータをクエリします。結果は次のとおりです: 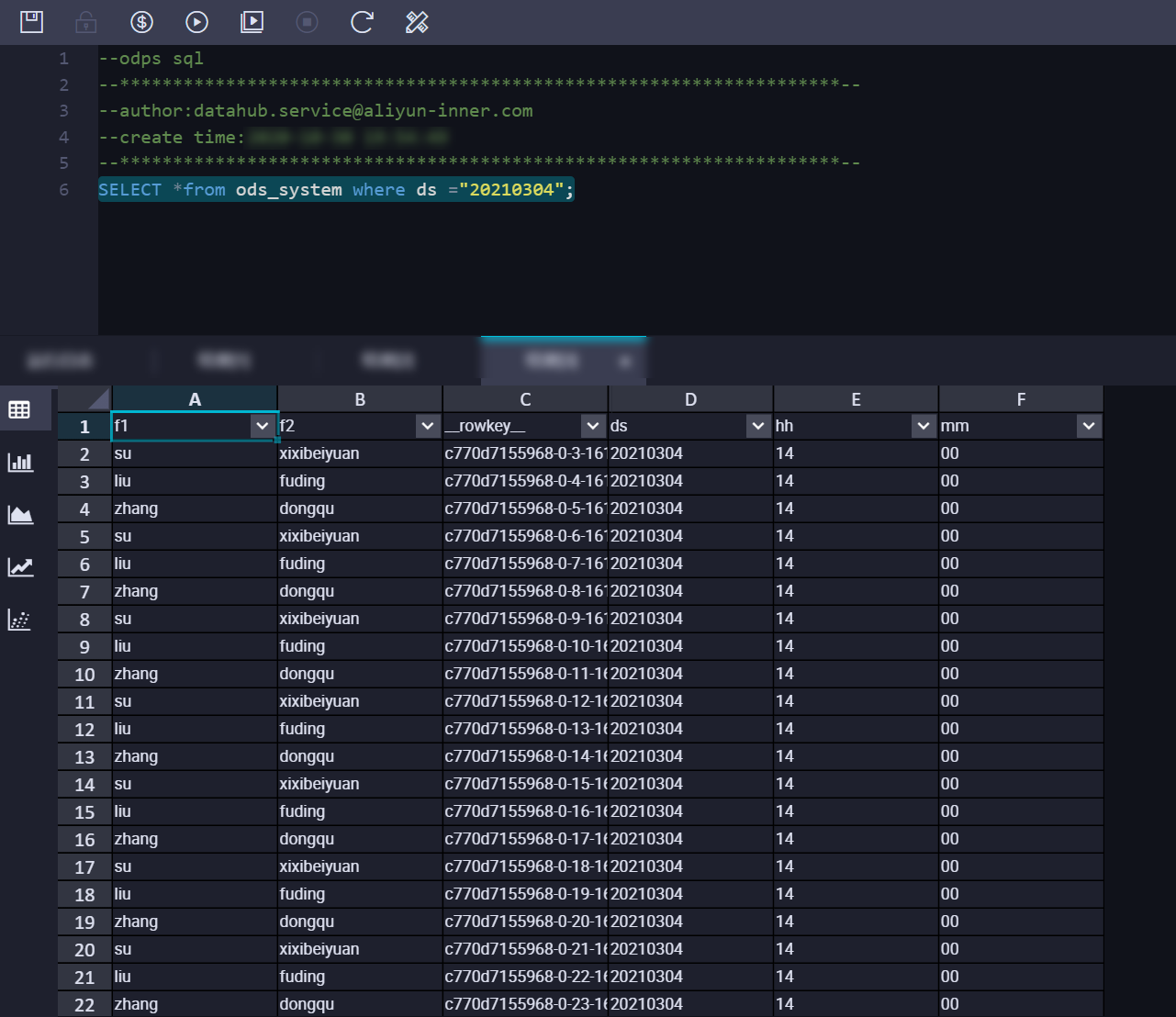 SYSTEM_TIME モードでは、DataHub は
SYSTEM_TIME モードでは、DataHub は データが DataHub に書き込まれた時間に基づいて、対応するパーティションにデータを同期します。
よくある質問
MaxCompute に同期されたタイムスタンプフィールドの時間が 1970-01-19 になります。
原因: DataHub から MaxCompute に同期されるタイムスタンプのデフォルト単位はマイクロ秒です。ユーザーが書き込んだタイムスタンプはミリ秒単位です。ソリューション: タイムスタンプをマイクロ秒単位で DataHub に書き込みます。