このトピックでは、新しいリリースにおける DataHub の変更点について説明します。このトピックでは、主にバッチシリアル化の原則と実装、およびバッチシリアル化によってもたらされるパフォーマンスの向上とコスト削減について紹介します。バッチシリアル化は、DataHub のサービス側とユーザー側の両方にメリットがあります。サービス側ではリソース消費を大幅に削減でき、パフォーマンスを大幅に向上させることができ、ユーザーのコストを大幅に削減できます。
アップグレードの詳細
zstd 圧縮のサポート
DataHub は最新バージョンで Zstandard(zstd)をサポートするようになりました。DataHub でもサポートされている LZ4 および Deflate と比較して、zstd はより優れたパフォーマンスを提供できます。
Zstd は Facebook によって開発された高性能な圧縮アルゴリズムです。 2016 年にオープンソース化されました。Zstd は圧縮速度と圧縮率の両方で優れたパフォーマンスを発揮するため、DataHub の使用シナリオに最適です。
シリアル化変換
DataHub にはバッチシリアル化も導入されています。バッチシリアル化は、本質的に DataHub でデータを編成する方法です。「バッチ」という用語は、特定のシリアル化方法を指すのではなく、シリアル化されたデータの二次カプセル化を伴います。たとえば、100 件のデータレコードをバッチで送信する必要があります。これらの 100 件のデータレコードはシリアル化されてバッファが生成され、バッファは圧縮アルゴリズムを使用して圧縮され、次に圧縮されたバッファにヘッダーが追加されて、バッファのサイズ、データレコードの数、圧縮アルゴリズム、CRC 情報、およびその他の情報が記録されます。このヘッダーが追加された最終バッファは、完全なデータバッチを表します。
バッチシリアル化には次の利点があります。
ダーティデータの軽減に非常に効果的です。
バックエンドサーバーの CPU オーバーヘッドを削減し、データ処理パフォーマンスを向上させるのに役立ちます。
読み取りおよび書き込み操作のレイテンシを短縮するのに役立ちます。
バッチバッファがサーバーに送信されると、クライアントはすでに徹底的なデータ有効性チェックを実行しているため、サーバーはデータの CRC 結果を確認してバッファの整合性を確認するだけで済みます。バッチバッファが有効であることが確認されると、サーバーはシリアル化、デシリアル化、圧縮、展開、さらなる検証などの追加操作を行うことなく、バッファをディスクに直接永続化できます。この最適化により、サーバーのパフォーマンスが 80% 以上向上します。複数のデータエントリを一緒に圧縮することにより、圧縮率も向上し、ストレージコストが削減されます。
コスト比較
バッチシリアル化によってもたらされるメリットを検証するために、次のデータを使用して比較テストを実施します。
テストには約 200 列の広告関連データが使用されます。テストデータの NULL 値の比率は約 20% から 30% です。
1,000 件のデータエントリごとに 1 つのバッチを構成します。
バッチシリアル化には Apache Avro が使用されます。
アップグレード前は、デフォルトで LZ4 がデータ圧縮に使用されます。アップグレード後は、デフォルトで zstd がデータ圧縮に使用されます。
次の表にテスト結果を示します。
元のデータサイズ(単位:バイト) | LZ4 を使用して圧縮されたデータのサイズ(単位:バイト) | zstd を使用して圧縮されたデータのサイズ(単位:バイト) | |
Protobuf シリアル化 | 11,506,677 | 3,050,640 | 1,158,868 |
バッチシリアル化 | 11,154,596 | 2,931,729 | 1,112,693 |
コスト削減は、主に DataHub の 2 つの課金ディメンションであるストレージとトラフィックから比較します。その他の課金項目は、主に不正使用を防ぐために設定されており、通常のケースでは無視できます。
ストレージコスト:DataHub が Protobuf シリアル化を使用する場合、ストレージ内のデータは圧縮されませんが、HTTP 経由の転送中にのみデータが圧縮されます。バッチシリアル化 + zstd モードを使用すると、ストレージサイズは 11,506 KB から 1,112 KB に削減されます。これは、ストレージコストが約 90% 削減されることを意味します。
トラフィックコスト:DataHub が Protobuf + LZ4 モードを使用する場合、データサイズは 3,050 KB です。DataHub がバッチシリアル化 + zstd モードを使用する場合、データサイズは 1,112 KB です。これは、トラフィックコストが約 60% 削減されることを意味します。
上記の表は、サンプルデータに基づくテスト結果を示しています。実際のテスト結果はデータによって異なります。ビジネス要件に基づいてテストを実施できます。
バッチシリアル化を使用する
使用上の注意
バッチ書き込みの主な利点は、データレコードをバッチで収集できることです。クライアントがデータレコードをバッチで収集できない場合、またはバッチ内のデータレコードの数が少ない場合は、期待どおりの改善が得られない可能性があります。
ユーザーの利便性を考慮し、スムーズな移行を確実にするために、さまざまな読み取りメソッドと書き込みメソッド間の互換性を提供しています。つまり、バッチで書き込まれたデータは元のモードで読み取ることができ、元のモードで書き込まれたデータもバッチで読み取ることができます。データをバッチで書き込む場合は、バッチで消費することもお勧めします。[それ以外の場合]、パフォーマンスが低下する可能性があります。
前提条件
[マルチバージョンスキーマ] 機能が有効になっていること。
クライアントライブラリ 1.4 以降を使用していること。
Java 用 DataHub SDK のみがサポートされています。
マルチバージョンスキーマ機能を有効にする
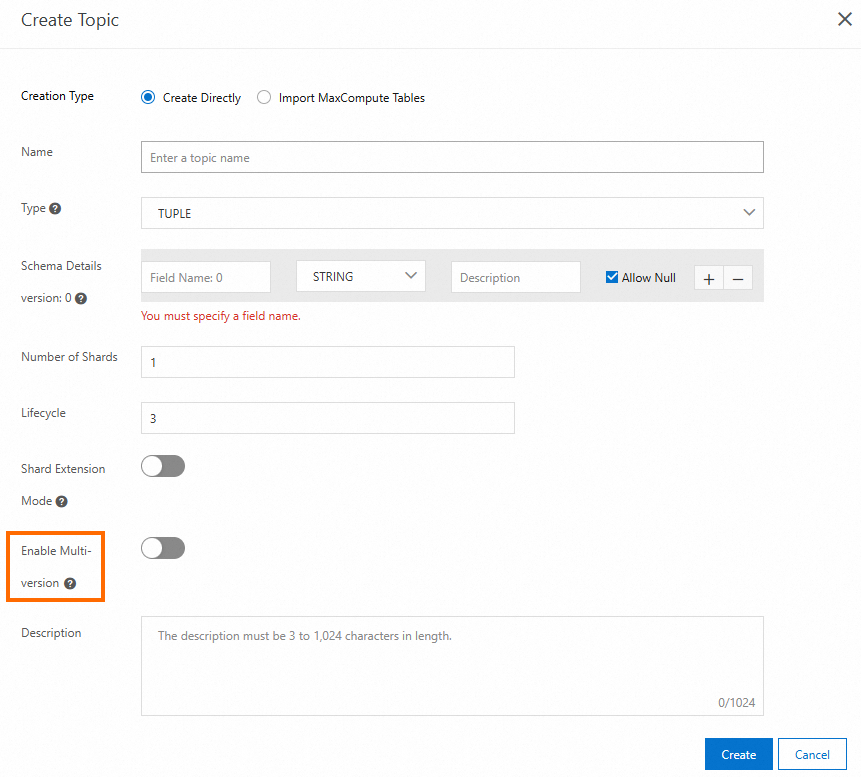
コンソールでマルチバージョンスキーマ機能を有効にする
コンソールで作成済み Topic の情報を変更することはできません。バッチシリアル化を使用する場合は、Topic の作成時に [複数バージョンを有効にする] をオンにする必要があります。Topic の作成方法の詳細については、「Topic を管理する」をご参照ください。
SDK を使用してマルチバージョンスキーマ機能を有効にする
public static void createTopicWithOption() {
try {RecordSchema recordSchema = new RecordSchema() {{
this.addField(new Field("field1", FieldType.STRING));
this.addField(new Field("field2", FieldType.BIGINT));
}};
TopicOption option = new TopicOption();
// マルチバージョンスキーマ機能を有効にします。
option.setEnableSchemaRegistry(true);
option.setComment(Constant.TOPIC_COMMENT);
option.setExpandMode(ExpandMode.ONLY_EXTEND);
option.setLifeCycle(Constant.LIFE_CYCLE);
option.setRecordType(RecordType.TUPLE);
option.setRecordSchema(recordSchema);
option.setShardCount(Constant.SHARD_COUNT);
datahubClient.createTopic(Constant.PROJECT_NAME, Constant.TOPIC_NAME, option);
LOGGER.info("create topic successful");
} catch (ResourceAlreadyExistException e) {
LOGGER.info("topic already exists, please check if it is consistent");
} catch (ResourceNotFoundException e) {
// project not found
e.printStackTrace();
throw e;
} catch (DatahubClientException e) {
// other error
e.printStackTrace();
throw e;
}
}バッチシリアル化を構成する
サーバーがバッチ転送プロトコルをサポートしている場合、DataHub はデフォルトでバッチシリアル化を使用します。サーバーがバッチ転送プロトコルをサポートしていない場合、たとえば、サーバーが最新バージョンの Apsara Stack を使用していない場合、またはサーバーが Apsara Stack V3.16 より前のバージョンを使用している場合、DataHub は自動的に元のシリアル化方法を使用します。クライアントは追加の構成を必要とせずに、シリアル化方法に自動的に適応します。次の例では、クライアントライブラリ 1.4.1 が使用されています。システムは自動的により良い圧縮アルゴリズムに適応します。クライアントライブラリ 1.4 以後のバージョンを使用する場合は、デフォルトで zstd が選択されます。
Maven 依存関係を追加する
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.25.3</version>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>datahub-client-library</artifactId>
<version>1.4.3</version>
</dependency>バッチシリアル化を構成する
ProducerConfig config = new ProducerConfig(endpoint, accessId, accessKey);
DatahubProducer producer = new DatahubProducer(projectName, topicName, config);
RecordSchema schema = producer.getTopicSchema();
List<RecordEntry> recordList = new ArrayList<>();
// パフォーマンスを向上させるために、できるだけ多くのレコードを recordList に追加することをお勧めします。
// 可能であれば、recordList のサイズを 512 KB から 1 MB の範囲に設定します。
for (int i = 0; i < 1000; ++i) {
RecordEntry record = new RecordEntry();
TupleRecordData data = new TupleRecordData(schema);
// 次のスキーマが使用されていると仮定します:{"fields":[{"name":"f1", "type":"STRING"},{"name":"f2", "type":"BIGINT"}]}
data.setField("f1", "value" + i);
data.setField("f2", i);
record.setRecordData(data);
// オプション。カスタム属性を追加します。
record.addAttribute("key1", "value1");
recordList.add(record);
}
try {
// データを 1,000 回繰り返し書き込みます。
for (int i = 0; i < 1000; ++i) {
try {
String shardId = datahubProducer.send(recordList);
LOGGER.info("Write shard {} success, record count:{}", shardId, recordList.size());
} catch (DatahubClientException e) {
if (!ExceptionChecker.isRetryableException(e)) {
LOGGER.info("Write data fail", e);
break;
}
// sleep 文を実行してデータ書き込みを再試行します。
Thread.sleep(1000);
}
}
} finally {
// プロデューサー関連のリソースを無効にします。
datahubProducer.close();
}次のステップ
DataHub の使用に関して問題が発生した場合、または質問がある場合は、チケットを送信するか、DingTalk グループ 33517130 に参加してください。