Alibaba Cloud Container Compute Service (ACS) は Advanced Horizontal Pod Autoscaler (AHPA) をサポートしています。AHPA は Prometheus の既存データを分析して将来のリソース需要を予測し、Pod レプリカ数を動的に調整します。これにより、トラフィックピーク前にリソースがスケールアウトおよびプリフェッチされ、システムの応答性と安定性が向上します。また、予測されたトラフィックの谷間にはリソースをスケールインしてコストを削減します。
背景情報
AHPA コントローラーは Managed Service for Prometheus と統合し、アプリケーションの既存メトリックデータを取得・処理します。このデータが予測スケーリングの意思決定の基礎となります。機械学習アルゴリズムを使用して、AHPA コントローラーは今後 24 時間に必要な Pod インスタンス数を予測します。これは、周期的なパターンを持つワークロードの処理に特に有効です。積極的予測と受動的予測の戦略を組み合わせることで、AHPA コントローラーは Pod インスタンス数を調整し、今後のトラフィックピークに備えてリソースをプリフェッチします。このアプローチにより、アプリケーションの応答性とパフォーマンスが向上し、コスト管理とサービスの安定性の維持にも貢献します。AHPA の詳細については、「AHPA overview」をご参照ください。
前提条件
-
ACS クラスターを作成しました。
Managed Service for Prometheus は有効になっています。詳細については、「Managed Service for Prometheus を使用して ACS クラスターをモニターする」をご参照ください。
手順 1:AHPA コントローラーのインストール
-
ACS コンソール にログインします。左側のナビゲーションウィンドウで クラスターリスト をクリックします。
-
クラスターリスト ページで、対象クラスターの名前をクリックします。左側のナビゲーションウィンドウで Add-ons をクリックします。
Add-ons ページで、Others カテゴリ内の AHPA コントローラー を見つけ、Install をクリックします。
手順 2:Prometheus の構成と AHPA の統合
ARMS コンソール にログインします。
-
左側のナビゲーションウィンドウで、 を選択します。
インスタンスリスト ページの上部で、ご利用の Prometheus インスタンスがデプロイされているリージョンを選択します。ターゲットインスタンス(ACS クラスターと同じ名前で、インスタンスタイプ が General)の名前をクリックします。左側のナビゲーションウィンドウで、設定 をクリックします。HTTP API アドレス (Grafana 読み取りアドレス) セクションで、以下のパラメーターの値を記録します。
トークンが有効になっている場合は、アクセストークンを記録します。
イントラネット エンドポイント (Prometheus URL) を表示して記録します。
ACS クラスター内で Prometheus クエリ URL を設定します。
application-intelligence.yaml という名前のファイルを作成し、以下の内容を記述します。
prometheusUrl:ARMS Prometheus インスタンスのアクセスエンドポイント。token:Prometheus インスタンスのアクセストークン。
apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-hangzhou-intranet.arms.aliyuncs.com:9443/api/v1/prometheus/da9d7dece901db4c9fc7f5b9c40****/158120454317****/cc6df477a982145d986e3f79c985a****/cn-hangzhou" token: "eyJhxxxxx"説明Managed Service for Prometheus 内で AHPA ダッシュボードを表示するには、この ConfigMap に以下のフィールドも追加で構成する必要があります。
prometheus_writer_url:リモートライトの内部エンドポイントに設定します。prometheus_writer_ak:Alibaba Cloud アカウントの AccessKey ID に設定します。prometheus_writer_sk:Alibaba Cloud アカウントの AccessKey Secret に設定します。
次のコマンドを実行して application-intelligence をデプロイします。
kubectl apply -f application-intelligence.yaml
AHPA を統合します。
ARMS コンソール にログインします。
-
左側のナビゲーションウィンドウで、 を選択します。
上部のナビゲーションバーで 他のコンポーネントに接続する をクリックします。アクセスセンター で AHPA を検索し、AHPA カードをクリックします。
AHPA コンポーネントを統合します。
ACK AHPA ページで、[Container Service クラスターの選択] > クラスターの選択 を選択し、ドロップダウンリストから統合したいクラスターを選択します。
[構成情報] セクションのパラメーターを以下の表に基づいて設定し、OK をクリックします。
パラメーター
説明
Exporter 名
AHPA Exporter の一意の名前。
メトリック収集間隔 (秒)
モニタリングデータを収集する間隔。
[統合ステータスチェック] が完了したら、アクセス管理 をクリックします。
手順 3:テストサービスのデプロイ
テストサービスには、fib-deployment、fib-svc、およびリクエストのピークと谷をシミュレートするサービスである fib-loader が含まれます。また、AHPA との結果比較用に HPA リソースも含まれています。
demo.yaml という名前のファイルを作成し、以下の内容を記述します。
次のコマンドを実行してテストサービスをデプロイします。
kubectl apply -f demo.yaml
手順 4:AHPA リソースの作成
AdvancedHorizontalPodAutoscaler リソースを送信して、スケーリングポリシーを構成します。
ahpa-demo.yaml という名前のファイルを作成し、以下の内容を記述します。
apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: ahpa-demo spec: scaleStrategy: observer metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 40 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fib-deployment maxReplicas: 100 minReplicas: 2 stabilizationWindowSeconds: 300 prediction: quantile: 95 scaleUpForward: 180 instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2031-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 15 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 15 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 20 minReplicas: 15以下の表は、一部のパラメーターについて説明しています。
パラメーター
必須
説明
scaleTargetRef
はい
ターゲットとなる Deployment を指定します。
metrics
はい
スケーリングのメトリックを構成します。サポートされるメトリックには、CPU、GPU、メモリ、QPS、RT が含まれます。
target
はい
ターゲットしきい値。たとえば、
averageUtilization: 40は、ターゲット CPU 使用率が 40% であることを意味します。scaleStrategy
いいえ
スケーリングモードを指定します。デフォルト値は
observerです。auto:AHPA がスケーリングを管理します。observer:観測のみを行い、実際のスケーリング操作は実行しません。このモードを使用して、AHPA が期待どおりに動作するか確認できます。scalingUpOnly:スケールアウト操作のみを実行します。proactive:積極的予測のみを有効にします。reactive:受動的予測のみを有効にします。
maxReplicas
はい
スケールアウト時の最大レプリカ数。
minReplicas
はい
スケールイン時の最小レプリカ数。
stabilizationWindowSeconds
いいえ
スケールイン時のクールダウン期間。デフォルト値:300 秒。
prediction.quantile
はい
予測分位数。値が大きいほど保守的になり、実際のメトリック値がターゲット以下になる確率が高くなります。有効値:0~100。デフォルト値:99。推奨範囲:90~99。
prediction. scaleUpForward
はい
新しい Pod が準備完了状態になるまでに必要な時間(コールドスタート時間)。
instanceBounds
いいえ
特定の時間範囲内でのレプリカ数の境界を指定します。
startTime:開始時刻。
endTime:終了時刻。
instanceBounds.bounds.cron
いいえ
スケジュールを指定する cron 式。cron 式は、スペースで区切られた 5 つのフィールドで構成されます。たとえば、
- cron: "* 0-8 ? * MON-FRI"は、月曜日から金曜日の 00:00~08:59 にタスクを実行することを指定します。以下の表は、cron 式の各フィールドについて説明しています。詳細については、「Cron expressions」をご参照ください。
フィールド
必須
許容値
許容特殊文字
分
はい
0~59
* / , -
時
はい
0~23
* / , -
日
はい
1~31
* / , – ?
月
はい
1~12 または JAN~DEC
* / , -
曜日
いいえ
0~6 または SUN~SAT
* / , – ?
説明月および曜日のフィールドの値は大文字・小文字を区別しません。たとえば、
SUN、Sun、およびsunは同じ効果を持ちます。曜日のフィールドが構成されていない場合、デフォルト値は
*になります。特殊文字:
*:すべての可能な値を指定します。/:増分を指定します。,:値を列挙します。-:範囲を指定します。?:特定の値を指定しません。
次のコマンドを実行して AHPA スケーリングポリシーを作成します。
kubectl apply -f ahpa-demo.yaml
手順 5:予測結果の確認
アクセス管理 ページで、[Container Service] タブに移動し、ご利用のクラスター名をクリックします。コンポーネントタイプ ドロップダウンリストから ACK AHPA を選択します。最後に、ダッシュボード タブに移動し、ahpa-dashboard をクリックしてモニタリングデータを表示します。
Managed Service for Prometheus が提供する AHPA ダッシュボードには、CPU 使用率、Pod 数、予測 Pod 数などのデータが含まれます。
CPU 使用率 & 実際の POD 数 チャートは、現在のワークロードの平均 CPU 使用率と Pod 数を示します。
実際の CPU 使用量と予測 CPU 使用量 チャートは、現在のワークロードの Pod の合計 CPU 使用量を予測使用量と比較します。予測使用量が実際の使用量より高い場合、予測された CPU 容量が十分であることを示します。
Pod 動向 セクションでは、実際の Pod 数、推奨 Pod 数、および積極的に予測された Pod 数を確認できます。
実際の Pod 数:現在実行中の Pod 数。
推奨 Pod 数:積極的予測、受動的予測、および定義されたインスタンス境界を組み合わせて AHPA が最終的に推奨する Pod 数。
積極的予測:既存データで識別された周期的パターンに基づいて予測された Pod 数。
AHPA は予測を生成するために 7 日間の既存データを必要とします。サンプルをデプロイした後、予測結果を確認するには 7 日間待つ必要があります。既存の本番ワークロードがある場合は、AHPA ダッシュボードで直接対応するデプロイメントを選択できます。
このトピックでは、スケーリングモードが observer モード(観測モード)に設定された例を紹介しています。この例では、アプリケーションに必要な実際のリソースを参照するために HPA ポリシーとの結果を比較し、AHPA の予測結果が期待どおりかどうかを確認します。
以下の図は、AHPA Prometheus ダッシュボード上の予測の例を示しています。
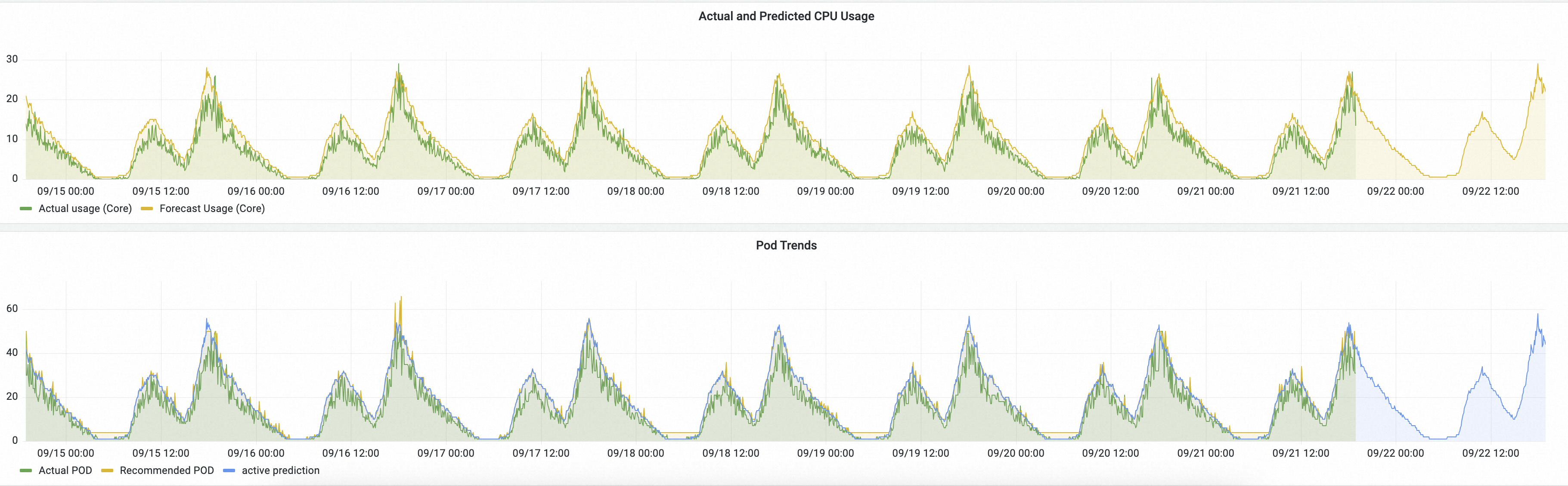
説明:
実際の CPU 使用量と予測 CPU 使用量:緑色の線は HPA による実際の CPU 使用量を、黄色の線は AHPA による予測 CPU 使用量を表します。
黄色の線が緑色の線より上にある場合、予測された CPU 容量が十分であることを示します。
黄色の線が緑色の線より前に上昇している場合、必要なリソースが事前に準備されたことを示します。
Pod 動向:緑色の線は HPA によってスケーリングされた実際の Pod 数を、黄色の線は AHPA によって予測された Pod 数を表します。
黄色の線が緑色の線より下にある場合、予測された Pod 数が少ないことを示します。
黄色の線が緑色の線より滑らかな場合、AHPA によるスケーリングによって変動が少なくなり、サービスの安定性が向上することを示します。
予測結果から、予測スケーリングの傾向が期待どおりであることがわかります。一定期間観察した後も傾向が期待どおりに続く場合は、scaleStrategy を auto に設定して、AHPA にスケーリングを管理させることができます。
主要な AHPA メトリック
メトリック | 説明 |
ahpa_proactive_pods | 積極的予測に基づく Pod 数。 |
ahpa_reactive_pods | 受動的予測に基づく Pod 数。 |
ahpa_requested_pods | 推奨される Pod 数。 |
ahpa_max_pods | 最大 Pod 数。 |
ahpa_min_pods | 最小 Pod 数。 |
ahpa_target_metric | ターゲットしきい値。 |