Dify を使用すると、企業または個人のナレッジベースを大規模言語モデル (LLM) アプリケーションに統合し、高度にカスタマイズされた AI Q&A ソリューションを構築できます。これらのソリューションをビジネスに統合することで、研究開発および管理の効率を向上させることができます。さらに、Container Compute Service (ACS) クラスターに Dify をデプロイすると、変動するビジネス要求に対応するシームレスなスケーリングを実現し、ビジネスの成長を加速できます。
ソリューション概要
|
Dify カスタム AI アプリケーションの例
|
Web 統合 AI アプリケーションの例
|

専用の AI Q&A アシスタントを、3 つのステップでセットアップします。
-
ack-dify コンポーネントのインストール:ACK クラスターを作成し、ack-dify コンポーネントをインストールします。
-
AI Q&A アシスタントの追加:Dify にアクセスし、Web サイトに AI Q&A アシスタントを追加します。
-
AI Q&A アシスタントのカスタマイズ:専用のナレッジベースを用意し、これまで正確に回答できなかった質問にも AI アシスタントが回答できるようにします。これにより、専門的な問い合わせをより効果的に処理できます。
Dify の概要
Dify は、Backend as a Service (BaaS) と LLMOps を組み合わせた、オープンソースの大規模言語モデル (LLM) アプリケーション開発プラットフォームです。開発者だけでなく非技術者も、コアコンポーネントを一から作り直すことなく、プロダクショングレードの生成 AI アプリケーションを構築できます。
Dify のアーキテクチャの主要コンポーネント:
-
コアテクノロジーコンポーネント: Dify は、多数のモデルとの互換性、ユーザーフレンドリーなプロンプト設計インターフェイス、高性能な検索拡張生成 (RAG) システム、カスタマイズ可能なエージェントアーキテクチャなど、LLM アプリケーションの作成に必要な主要コンポーネントを統合しています。
-
ビジュアルオーケストレーションと運用: Dify の直感的なインターフェイスは、プロンプトのビジュアルオーケストレーション、運用ワークフローの効率化、データセットの効率的な管理を可能にします。これにより、AI アプリケーション開発プロセスが大幅に加速し、開発者は迅速にデプロイできるほか、既存システムへの LLM の統合も行えます。また、継続的な運用最適化もサポートします。
-
アプリケーションテンプレートとオーケストレーションフレームワーク: Dify は、すぐに使えるアプリケーションテンプレートとオーケストレーションフレームワークを開発者に提供し、大規模言語モデルに基づく生成 AI アプリケーションを迅速に開発できるようにします。また、変化するビジネスニーズに対応するための即時かつスムーズなスケーリングをサポートし、ビジネスの成長を促進します。
これらのコンポーネントは、生成 AI アプリケーションを迅速に開発してデプロイするための包括的なプラットフォームを提供します。
1. ack-dify コンポーネントのインストール
Container Compute Service (ACS) クラスターの作成に既に精通している場合、ビジネスニーズに適したクラスターの作成に進むことができます。
1.1 前提条件
-
バージョン 1.26 以降の ACS クラスター。
-
動的 NAS ボリュームの設定手順に従います。
-
StorageClass を作成します。
-
PersistentVolumeClaim (PVC) を作成します。
-
1.2 コンポーネントのデプロイ
Dify サービス用に、クラスターに ack-dify コンポーネントをデプロイしてください。
-
Container Compute Service (ACS) コンソールにログオンし、左側のナビゲーションペインからクラスターリストを選択します。対象のクラスターの名前をクリックして詳細ページに移動します。
コンポーネントの [アプリケーション名] と [名前空間] を設定する必要はありません。[次へ] をクリックすると、[確認] ダイアログボックスが表示されます。[はい] をクリックすると、デフォルトのアプリケーション名 (ack-dify) と名前空間 (dify-system) が使用されます。次に、[Chart バージョン] を 1.1.5 に設定し、[OK] をクリックして ack-dify コンポーネントのインストールを完了します。
「クラスター詳細」ページの左側のナビゲーションバーで、[アプリケーション] > [Helm] をクリックします。「Helm」ページで、[作成] ボタンをクリックします。「作成」パネルの「アプリケーションシナリオ」タブで、[AIGC/LLM] を選択し、次に [ack-dify] チャートを選択します。
-
約 1 分待ってから、次のコマンドを実行します。
dify-system名前空間内のすべての Pod がRunning状態になったら、ack-dify コンポーネントがインストールされています。kubectl get pod -n dify-systemPod が Pending 状態にある場合、クラスターに ack-dify に必要な PVC 依存関係が不足している可能性があります。この場合は、「前提条件」の説明に従って、クラスター用の NAS StorageClass を作成してください。Pod の例外のトラブルシューティング方法の詳細については、「Pod の例外のトラブルシューティング」をご参照ください。
2. AI Q&A アシスタントの追加
2.1 Dify Service へのアクセス
-
ack-dify Service のパブリックアクセスを有効にします。
説明パブリックアクセスはデモ用です。本番環境でデータセキュリティを確保するには、[アクセス制御] 機能を有効にしてください。

-
設定後、[Network] > [Services] > [ack-dify] を選択し、名前空間を dify-system に設定します。ack-dify Service の [外部 IP アドレス (External IP)] が表示されます。この IP をブラウザで開き、Dify にアクセスします。

-
アカウントを登録します。
[外部 IP アドレス (External IP)] にアクセスし、画面の案内に従って 管理者アカウント (メールアドレス、ユーザー名、パスワード) を作成します。
2.2 AI Q&A アシスタントの作成
-
ブラウザに [外部 IP アドレス (External IP)] を入力し、Dify プラットフォームにログインします。
-
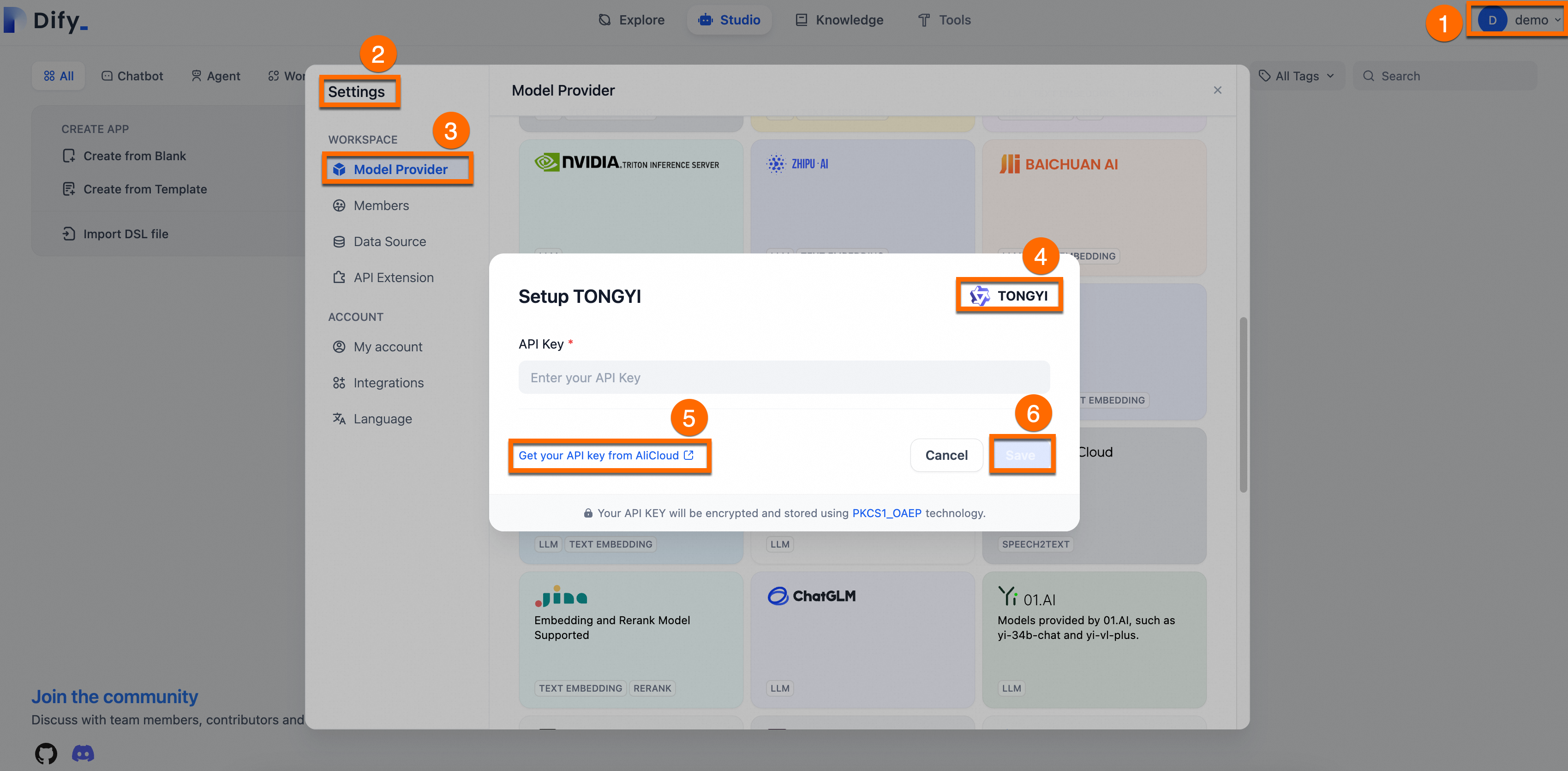
AI モデル (この例では Qwen) を追加し、Alibaba Cloud の API キーを設定します。次の図を参照してください:
Qwen の無料クォータを使い切ると、トークン使用量に基づいて課金されます。これは、モデルのセルフホスティングと比べて初期費用を抑えられます。
-
API キーの取得:ユーザー名 > 設定 > [Model Provider] を選択し、[Qwen] プラグインをインストールして設定してから、[Get API Key From Alibaba Cloud] を選択します。
-
API キーを入力し、保存 をクリックします。
-
-
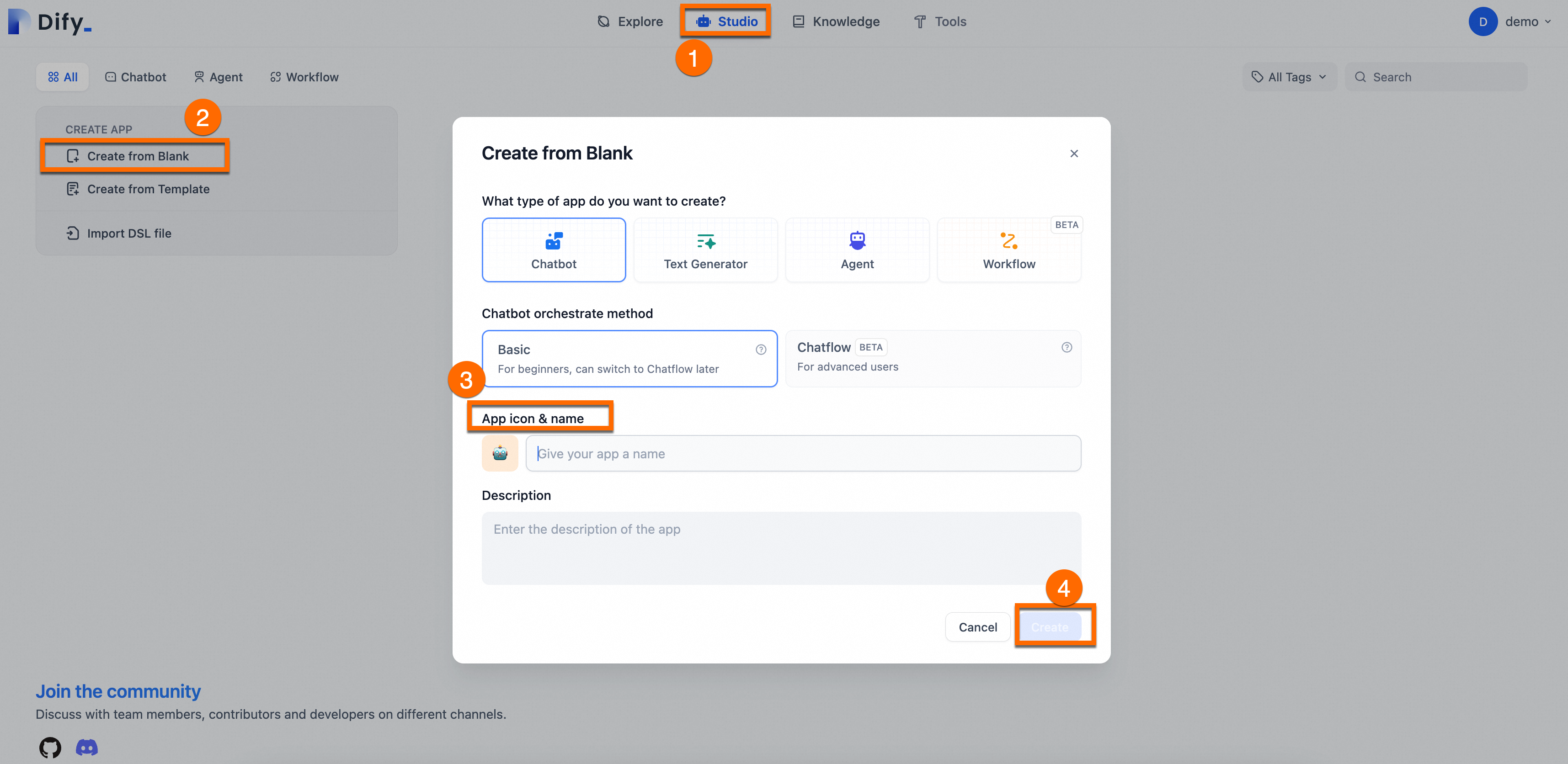
汎用の AI Q&A アシスタントを作成します。
[Studio] > [Create from Blank] を選択し、アシスタントの 名前 と [Description] を入力します。その他のパラメーターはデフォルトのままにします。
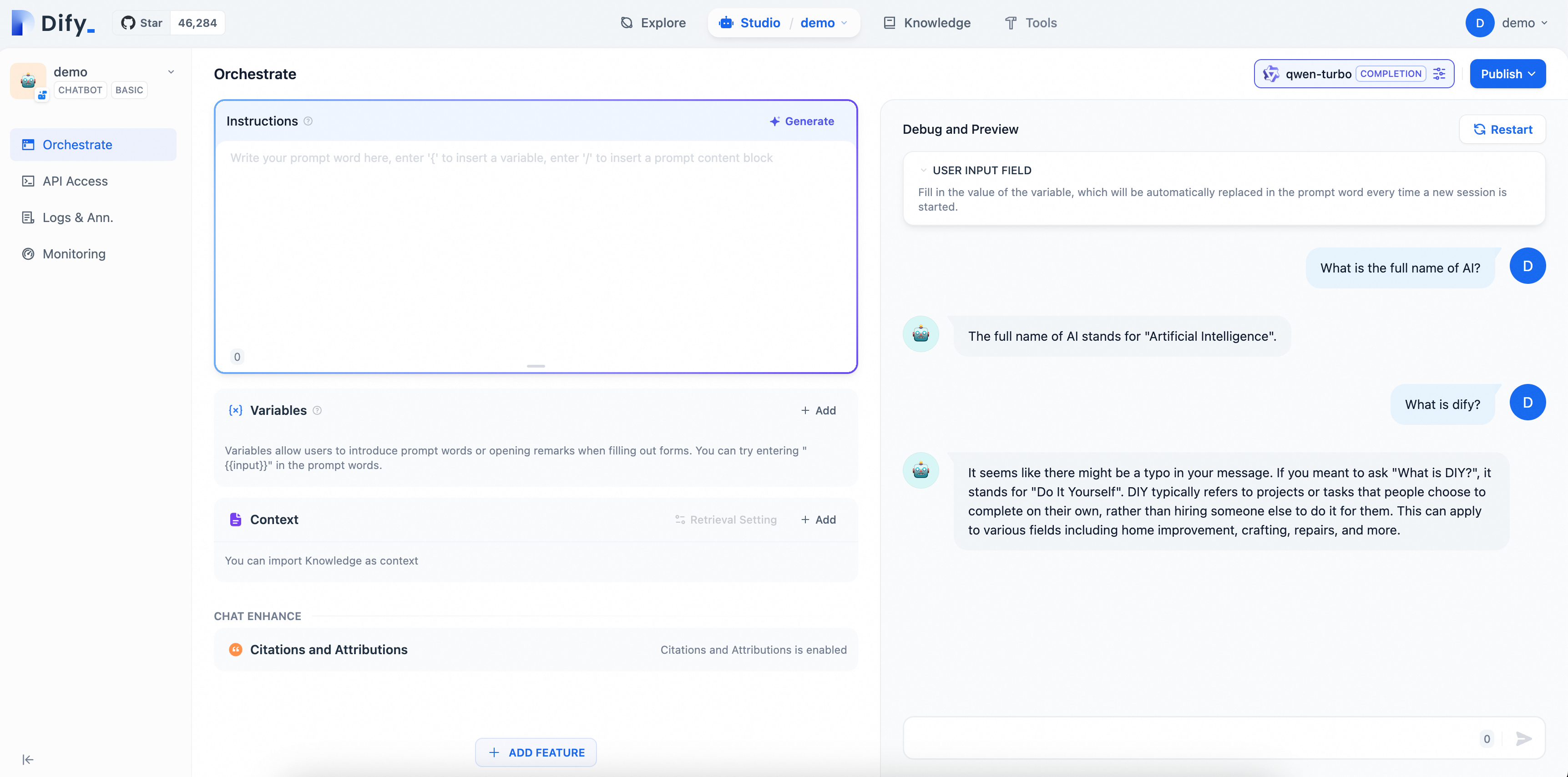
2.3 AI Q&A アシスタントの検証
質問を入力してアシスタントをテストします。汎用チャットボットは簡単な会話には対応できますが、現時点では Dify 固有の質問には回答できません。
3. AI アシスタントのカスタマイズ
3.1 ナレッジベースの作成
Dify 関連の技術的な質問に正確に回答するために、アシスタント専用のナレッジベースを構成します。
この例では、コーパスファイル dify_doc.md を使用します。以下の手順でナレッジベースを作成してアップロードします。
-
準備したコーパスファイル dify_doc.md をナレッジベースにアップロードします。
[ナレッジ] > [ナレッジを作成] > [ファイルからインポート] > [ファイルを選択] > [次へ] の順に選択します。
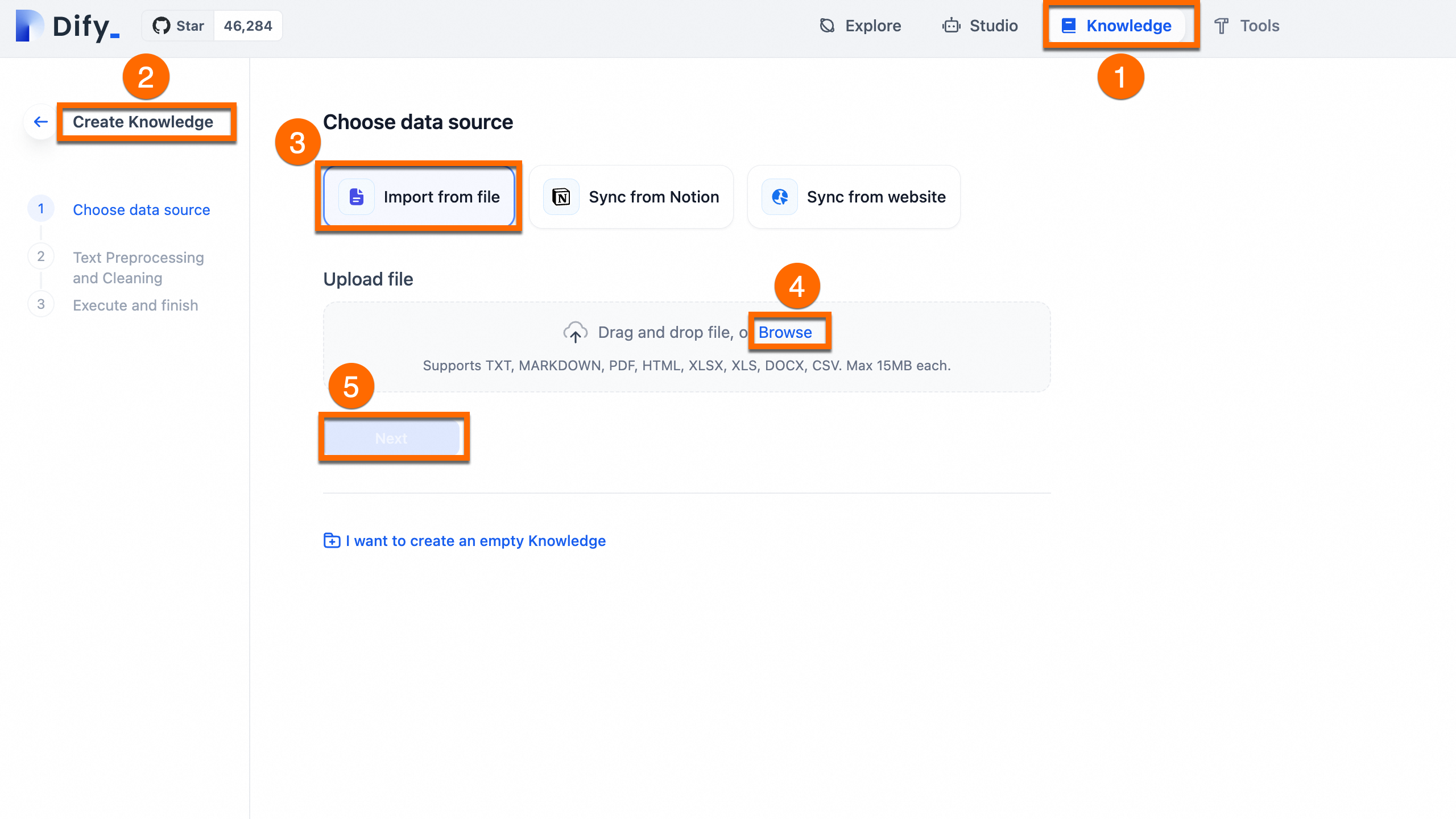
-
次へ をクリックします。テキストセグメンテーションとクリーニングを実行し、保存します。
デフォルト設定のままにします。ナレッジベースは、ドキュメントを自動的にクリーニング、セグメント化し、取得のためにインデックスを作成します。
上記のコーパスファイルが単一の .md ファイルにどのように整理されているかを確認するには、以下の折りたたみセクションを展開して詳細をご覧ください。
3.2 アシスタントのオーケストレーションと公開
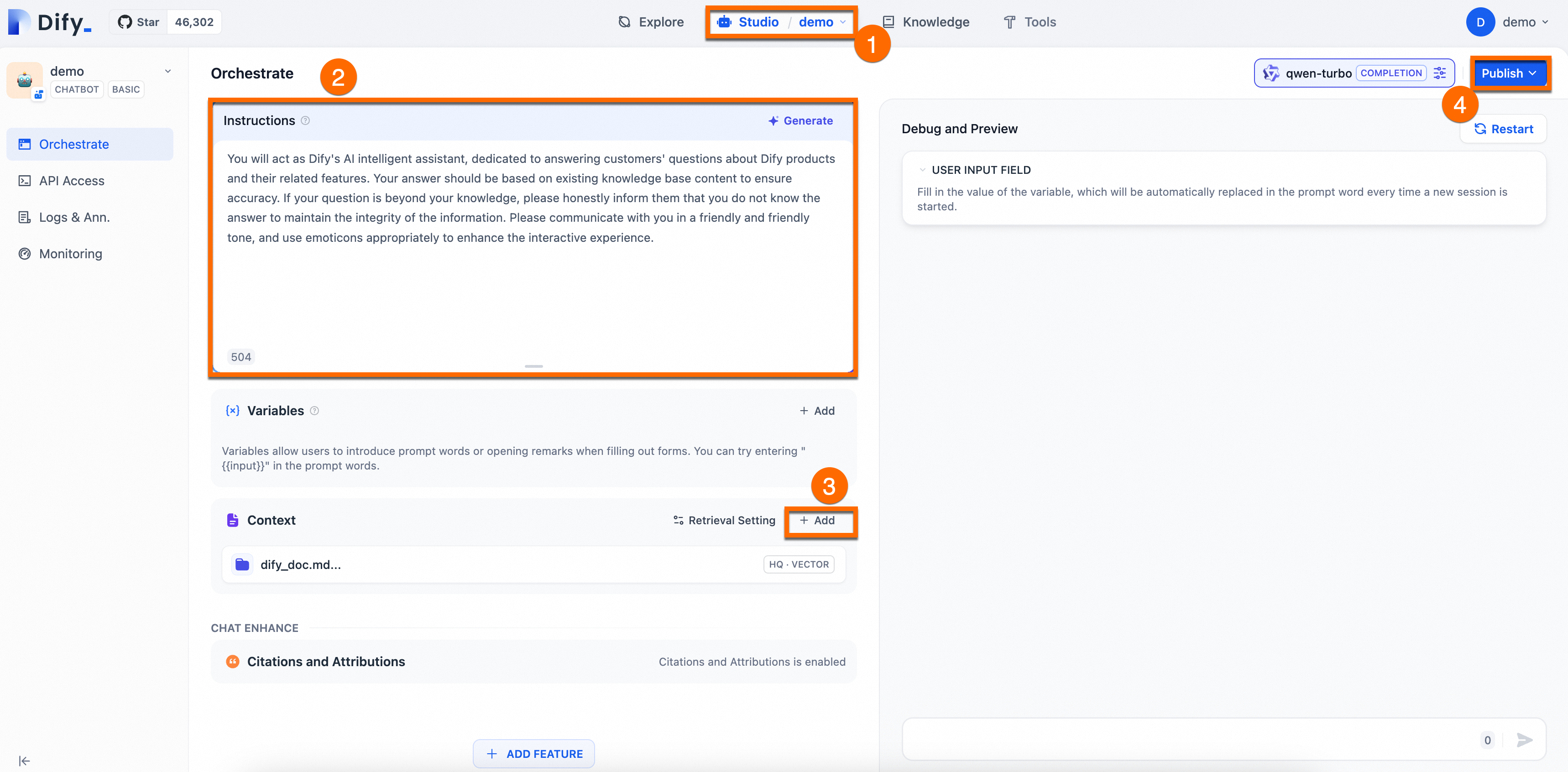
プロンプトを設定し、アシスタントのコンテキストにナレッジベースを追加します。
-
プロンプトの設定:以下の内容を [指示] フィールドにコピーします。プロンプトは、指示と制約によって応答の精度を高めます。
You will act as Dify's AI assistant, dedicated to answering customers' questions about Dify products and their features. Your responses should be based on the existing knowledge base to ensure accuracy. If a question is beyond your knowledge, please honestly inform them that you do not know the answer, in order to maintain the integrity of the information. Please communicate in a friendly and warm tone, and feel free to use emoticons appropriately to enhance the interactive experience. -
コンテキストへのナレッジベースの追加: 追加 エリアで [追加] をクリックしてナレッジベースを追加すると、正確で専門的な回答が可能になります。
-
リリース > 更新 の順にクリックして、設定を保存して適用します。
設定は以下の図のとおりです。
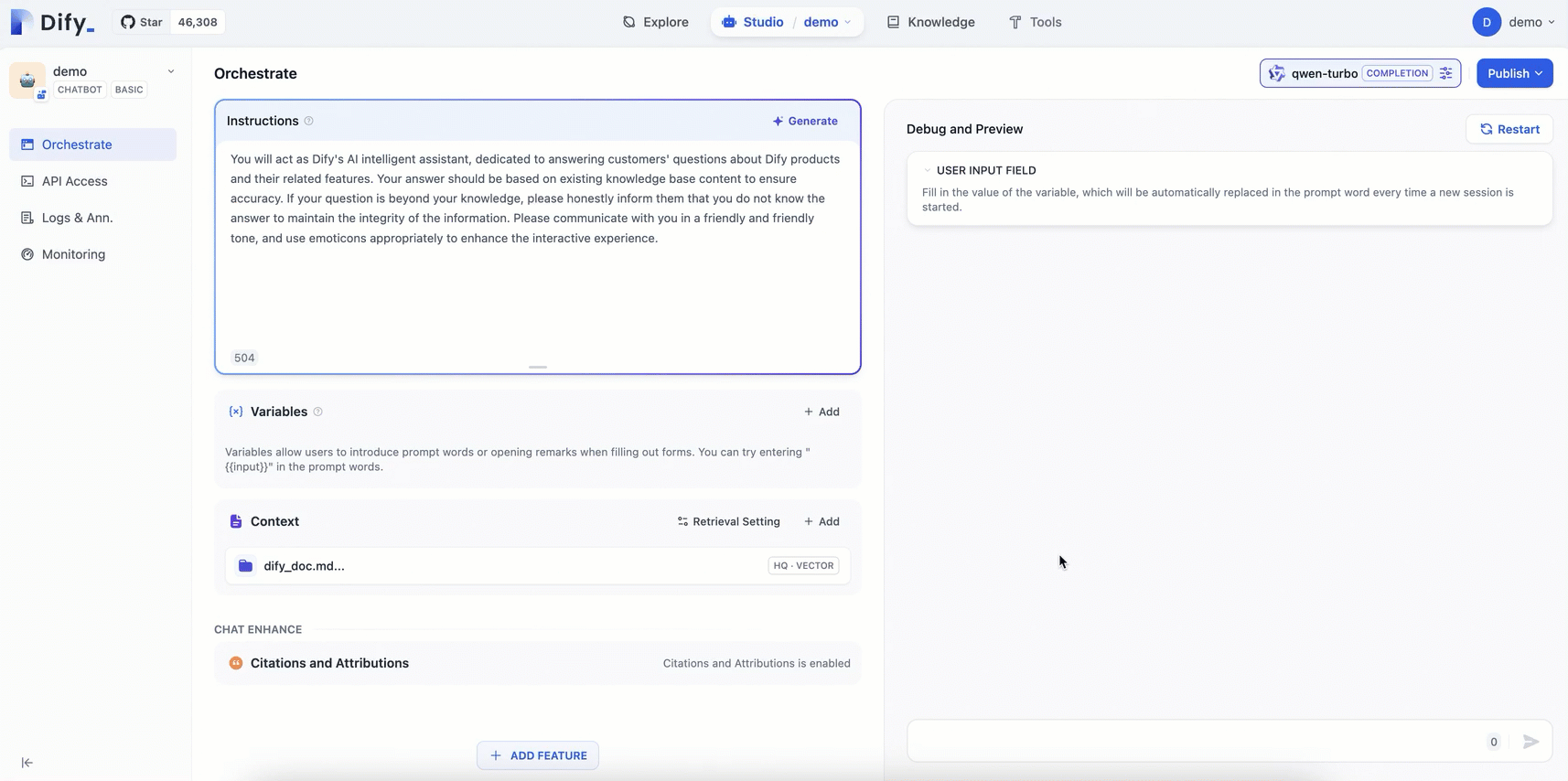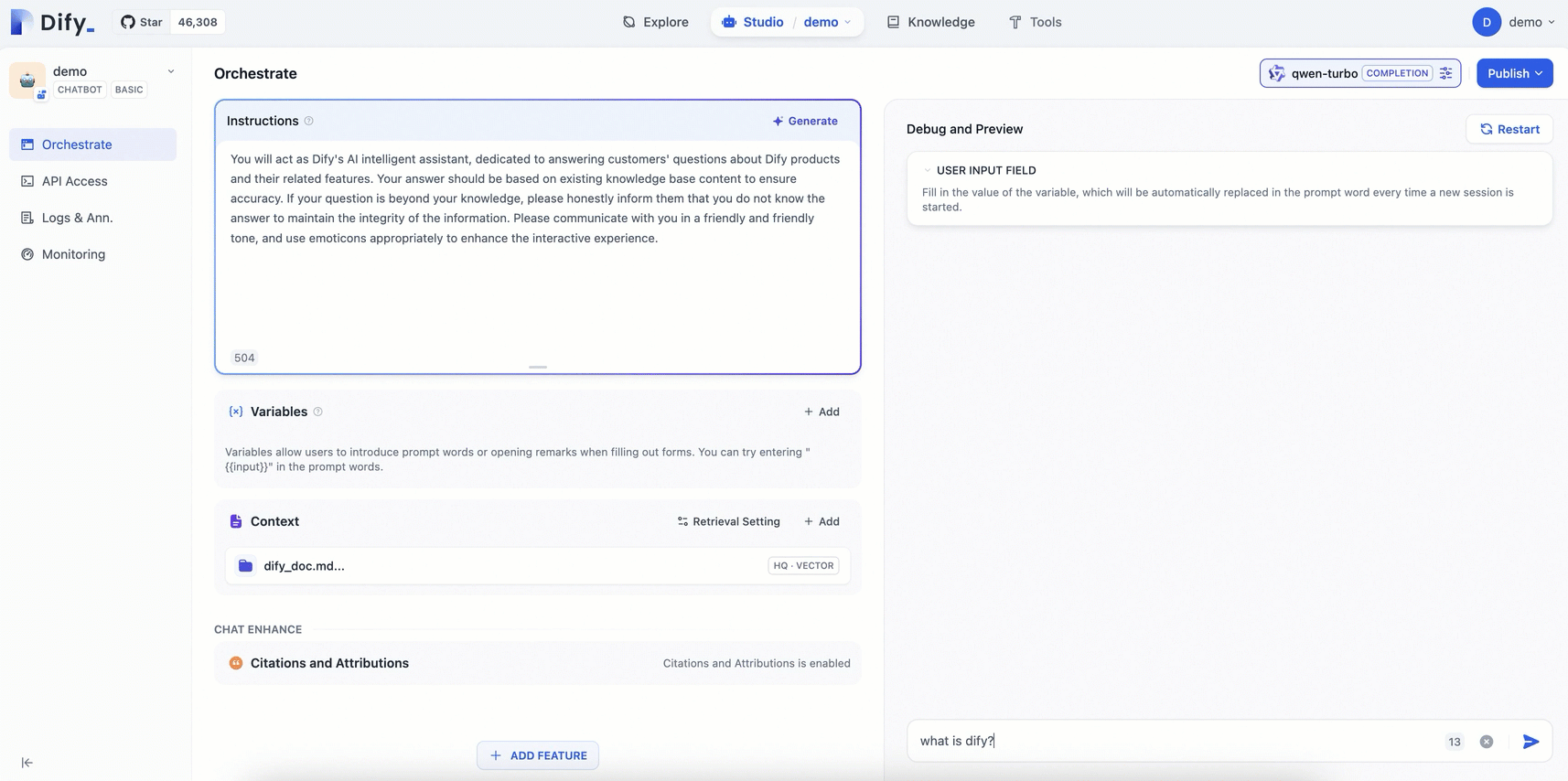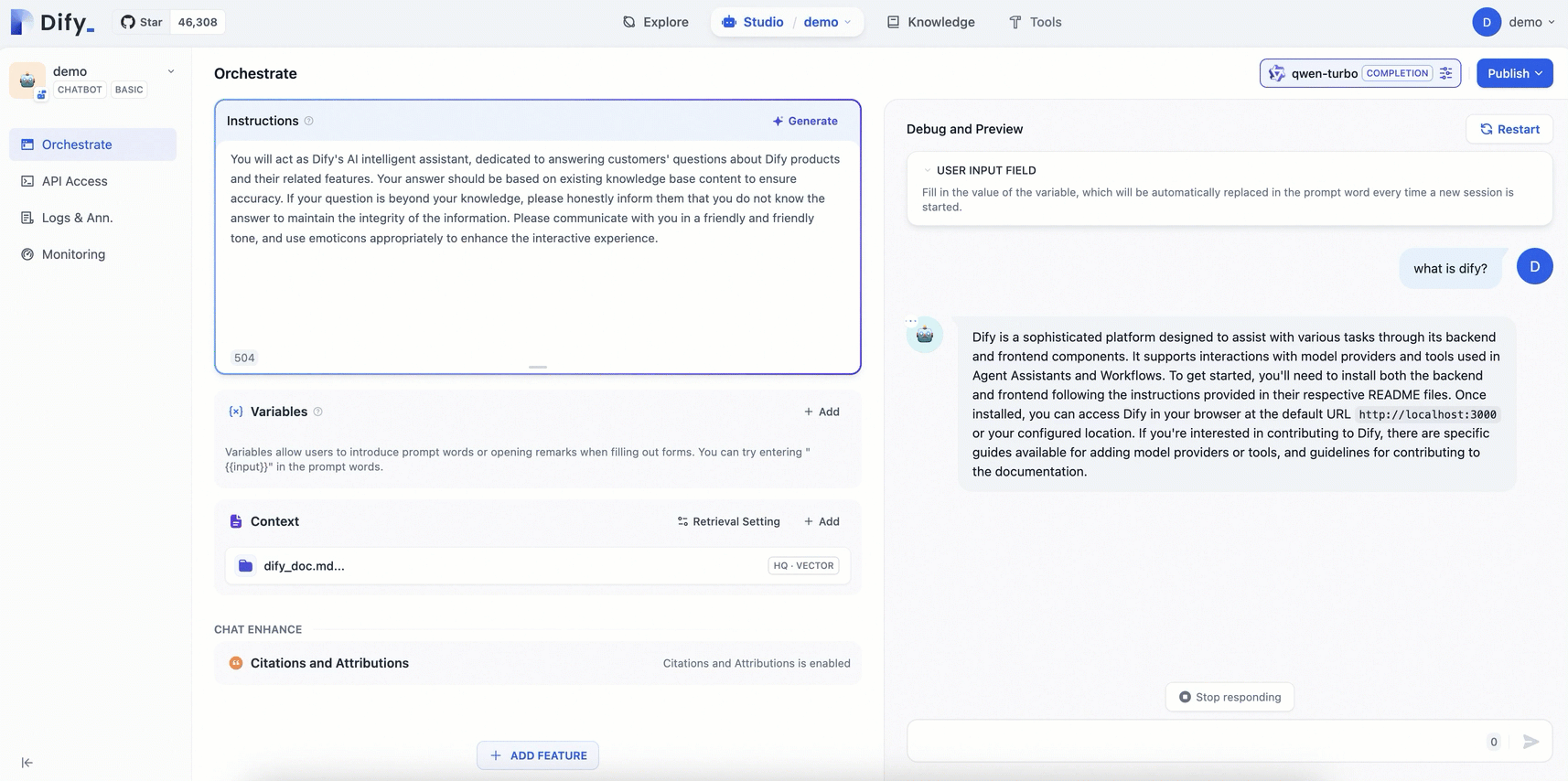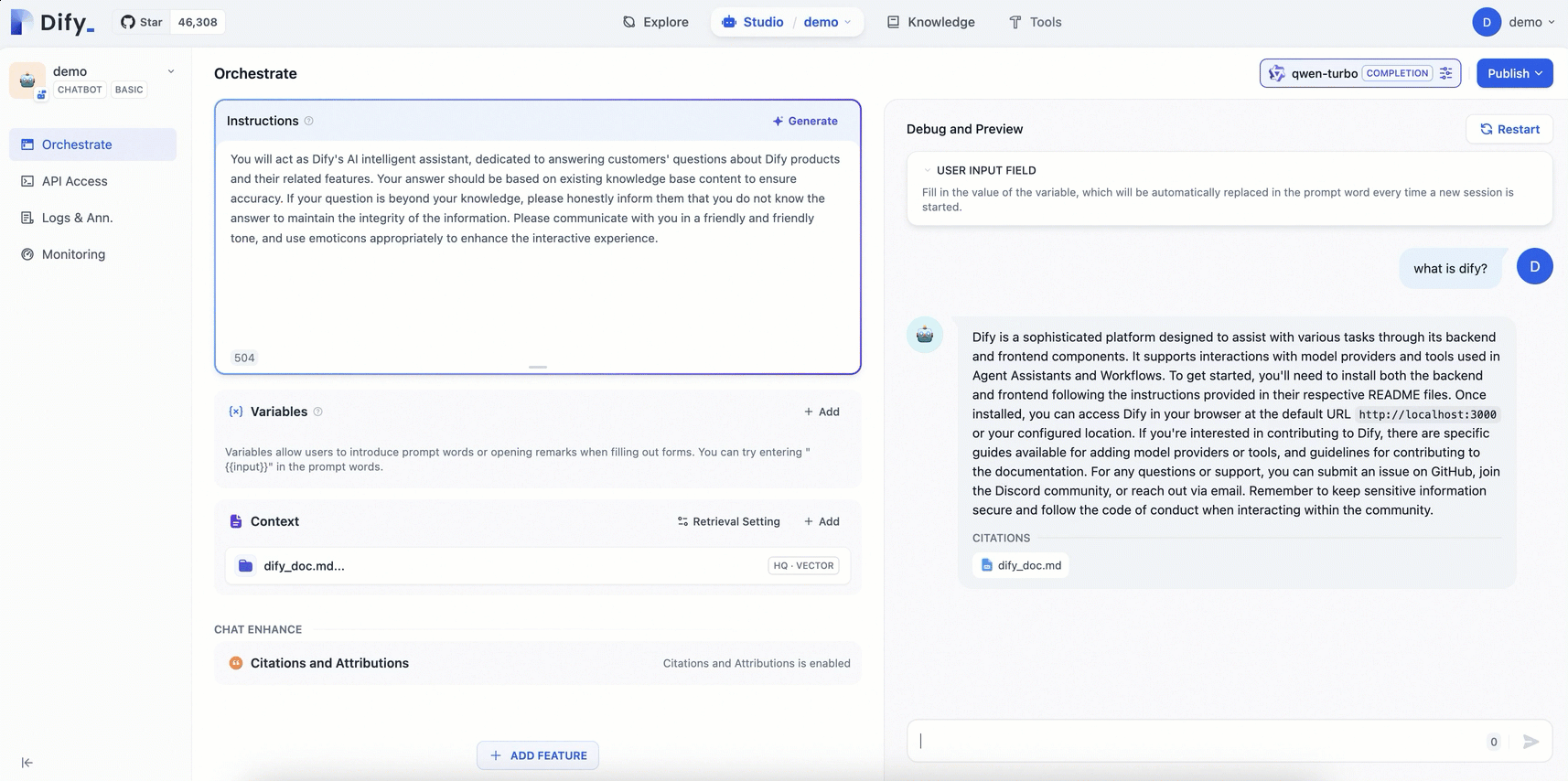
3.3 結果の検証
専用のナレッジベースにより、AI アシスタントは汎用チャットボットよりも正確でドメイン固有の回答を提供します。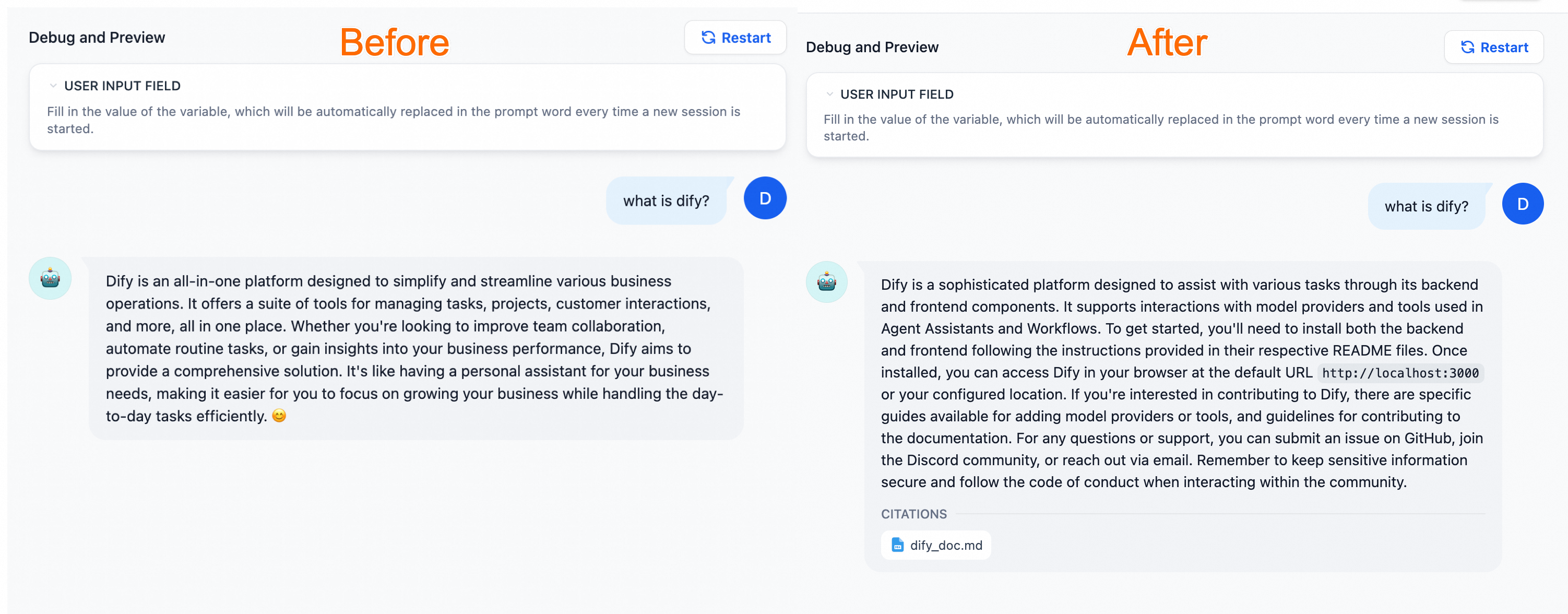
まとめ
Dify のコア機能:
|
機能 |
説明 |
|
包括的な LLMOps |
アプリケーションのログとメトリクスをリアルタイムでモニタリングし、本番データに基づいてプロンプト、データセット、モデルを継続的に最適化します。 |
|
RAG エンジン |
ドキュメントの取り込みから検索までのエンドツーエンドの RAG パイプライン。PDF や PPT などの一般的なフォーマットを直接処理します。 |
|
エージェント |
LLM の関数呼び出しまたは ReAct パラダイムを使用してエージェントを定義し、50 以上の組み込みツールとカスタムツールをサポートします。 |
|
ワークフローオーケストレーション |
コンポーネントをドラッグアンドドロップで接続して AI ワークフローを構築するためのビジュアルキャンバスで、コーディングは最小限で済みます。 |
|
可観測性 |
監視ダッシュボードを通じて LLM アプリケーションの品質とコストを追跡および評価します。 |
|
エンタープライズ機能 (SSO/アクセス制御) |
組織は、情報漏洩やデータ破損のリスクを軽減し、情報セキュリティとビジネスの継続性を確保できます。 |
本番環境に適用
AI Q&A アシスタントを本番環境にデプロイするための 4 つのオプション:
-
公開共有 Web サイト。
Dify で作成した AI アプリケーションは、インターネット上でアクセス可能な Web アプリケーションとして公開でき、プロンプトとオーケストレーションの設定に基づいて動作します。詳細については、「公開 Web アプリとして公開する」をご参照ください。
-
API ベースの呼び出し。
Dify は、「Backend-as-a-Service」の概念に基づき、すべてのアプリケーションに API を提供します。これにより、開発者は複雑なバックエンドアーキテクチャやデプロイを気にすることなく、フロントエンドアプリケーションで大規模言語モデルの能力を活用できます。詳細については、「API を使用した開発」をご参照ください。
-
フロントエンドコンポーネントをベースにした再開発。
ゼロから新しい製品を開発している場合や、プロトタイプの設計段階にある場合は、Dify を使用して AI サイトを迅速に公開できます。詳細については、「フロントエンドコンポーネントをベースにした再開発」をご参照ください。
-
エンタープライズまたは個人の Web サイトへの埋め込み。
Dify は、AI アプリケーションをビジネス Web サイトに埋め込むことをサポートしています。この機能を使用して、公式 AI カスタマーサービス、ビジネス Q&A、その他のアプリケーションをビジネスデータを使用して数分で作成できます。詳細については、「Web サイトへの埋め込み」をご参照ください。