Knative Pod Autoscaler (KPA) は、Knative が提供する使いやすい自動スケーリング機能です。これにより、ポッドの同時実行数と 1 秒あたりのリクエスト数 (RPS) に基づいてスケーリング条件を設定できます。デフォルトでは、Knative はアクティブなサービスリクエストがない場合、ポッド数をゼロに減らし、リソース使用量を最適化します。KPA を使用すると、ゼロにスケールダウンするまでの待機時間などのスケールダウンパラメータを設定し、ゼロへのスケールダウンを有効にするかどうかを指定できます。
前提条件
Knative が ACS クラスタにデプロイされていること。詳細については、Knative のデプロイを参照してください。
仕組み
Knative Serving は、queue-proxy という名前の Queue Proxy コンテナを各ポッドに挿入します。コンテナはアプリケーションポッドのリクエスト同時実行メトリクスを KPA に自動的に報告します。KPA はメトリクスを受信すると、同時実行リクエスト数と関連アルゴリズムに基づいて、デプロイメントにプロビジョニングされるポッド数を自動的に調整します。
展開して KPA アルゴリズムを表示する
KPA の設定
一部の設定は、アノテーションを使用してリビジョンレベルで有効にするか、ConfigMap を使用してグローバルに適用できます。両方の方法を同時に使用する場合、リビジョンレベルの設定が優先されます。
config-autoscaler
KPA を設定するには、config-autoscaler を設定する必要があります。デフォルトでは、config-autoscaler が設定されています。以下は主要なパラメータです。
次のコマンドを実行して、config-autoscaler をクエリします。
kubectl -n knative-serving describe cm config-autoscaler予想される出力(デフォルトの config-autoscaler ConfigMap):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# ポッドのデフォルトの最大同時実行数。デフォルト値は 100 です。
container-concurrency-target-default: "100"
# 同時実行の目標使用率。デフォルト値は 70 で、0.7 を表します。
container-concurrency-target-percentage: "70"
# デフォルトの 1 秒あたりのリクエスト数 (RPS)。デフォルト値は 200 です。
requests-per-second-target-default: "200"
# ターゲットバースト容量パラメータは、トラフィックバーストを処理し、ポッドの過負荷を防ぐために使用されます。現在のデフォルト値は 211 です。これは、サービスに設定されたターゲットしきい値に準備完了ポッド数を掛けた値が 211 未満の場合、ルーティングは Activator サービスによって処理されることを意味します。
# Activator サービスは、ターゲットバースト容量を超えた場合にリクエストを受信してバッファリングするために使用されます。
# ターゲットバースト容量パラメータを 0 に設定すると、ポッド数がゼロにスケーリングされた場合にのみ、Activator サービスがリクエストパスに配置されます。
# ターゲットバースト容量パラメータを 0 より大きい値に設定し、container-concurrency-target-percentage を 100 に設定すると、Activator サービスは常にリクエストを受信してバッファリングするために使用されます。
# ターゲットバースト容量パラメータを -1 に設定すると、バースト容量は無制限になります。すべてのリクエストは Activator サービスによってバッファリングされます。ターゲットバースト容量パラメータを他の値に設定した場合、パラメータは有効になりません。
# 準備完了ポッドの現在の数 × 最大同時実行数 - ターゲットバースト容量 - パニックモードで計算された同時実行数の値が 0 より小さい場合、トラフィックバーストはターゲットバースト容量を超えています。このシナリオでは、Activator サービスが配置されてリクエストをバッファリングします。
target-burst-capacity: "211"
# 安定期間。デフォルトは 60 秒です。
stable-window: "60s"
# パニック期間の割合。デフォルトは 10 で、デフォルトのパニック期間が 6 秒 (60 × 0.1) であることを示します。
panic-window-percentage: "10.0"
# パニックしきい値の割合。デフォルトは 200 です。
panic-threshold-percentage: "200.0"
# 最大スケールアップ率。スケールアウトアクティビティあたりの目標ポッドの最大比率を示します。値は、math.Ceil(MaxScaleUpRate*readyPodsCount) の式に基づいて計算されます。
max-scale-up-rate: "1000.0"
# 最大スケールダウン率。デフォルトは 2 で、各スケールインアクティビティ中にポッドが現在の数の半分にスケーリングされることを示します。
max-scale-down-rate: "2.0"
# ポッド数をゼロにスケーリングするかどうかを指定します。デフォルトでは、この機能は有効になっています。
enable-scale-to-zero: "true"
# ポッド数がゼロにスケーリングされるまでの猶予期間。デフォルトは 30 秒です。
scale-to-zero-grace-period: "30s"
# ポッド数がゼロにスケーリングされる前の最後のポッドの保持期間。ポッドの起動コストが高い場合は、このパラメータを指定します。
scale-to-zero-pod-retention-period: "0s"
# オートスケーラーのタイプ。KPA、Horizontal Pod Autoscaler (HPA)、Advanced Horizontal Pod Autoscaler (AHPA) などのオートスケーラーがサポートされています。
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# Activator サービスのリクエスト容量。
activator-capacity: "100.0"
# リビジョン作成時に初期化するポッド数。デフォルトは 1 です。
initial-scale: "1"
# リビジョン作成時にポッドを初期化しないかどうかを指定します。デフォルトは false で、リビジョン作成時にポッドが初期化されることを示します。
allow-zero-initial-scale: "false"
# リビジョン用に保持されるポッドの最小数。デフォルトは 0 で、ポッドが保持されないことを意味します。
min-scale: "0"
# リビジョンをスケーリングできるポッドの最大数。デフォルトは 0 で、リビジョンをスケーリングできるポッド数に制限がないことを意味します。
max-scale: "0"
# スケールダウン遅延。デフォルトは 0 で、スケールインアクティビティがすぐに実行されることを示します。
scale-down-delay: "0s"メトリクス
autoscaling.knative.dev/metric アノテーションを使用して、リビジョンのメトリクスを設定できます。オートスケーラーごとにサポートされるメトリクスが異なります。
サポートされるメトリクス:
"concurrency"、"rps"、"cpu"、"memory"、およびカスタムメトリクス。デフォルトのメトリクス:
"concurrency"。
同時実行メトリクスの設定
RPS メトリクスの設定
CPU メトリクスの設定
メモリメトリクスの設定
目標しきい値の設定
autoscaling.knative.dev/target アノテーションを使用して、リビジョンの目標を設定できます。container-concurrency-target-default アノテーションを使用して、ConfigMap でグローバル目標を設定することもできます。
リビジョンの設定
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "50"グローバル設定
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"スケールツーゼロの設定
グローバルスケールツーゼロの設定
enable-scale-to-zero パラメータは、指定された Knative サービスがアイドル状態のときにポッド数をゼロにスケーリングするかどうかを指定します。有効な値は、"false" と "true" です。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # パラメータが "false" に設定されている場合、スケールツーゼロ機能は無効になります。この場合、指定された Knative サービスがアイドル状態のとき、ポッドはゼロにスケーリングされません。スケールツーゼロの猶予期間の設定
scale-to-zero-grace-period パラメータは、指定された Knative サービスのポッドがゼロにスケーリングされるまでの猶予期間を指定します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"スケールツーゼロの保持期間の設定
リビジョンの設定
autoscaling.knative.dev/scale-to-zero-pod-retention-period アノテーションは、Knative サービスのポッドがゼロにスケーリングされる前の最後のポッドの保持期間を指定します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバル設定
scale-to-zero-pod-retention-period アノテーションは、Knative サービスのポッドがゼロにスケーリングされる前の最後のポッドのグローバル保持期間を指定します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-pod-retention-period: "42s"同時実行数の設定
同時実行数は、ポッドが同時に処理できるリクエストの最大数を示します。同時実行数は、ソフト同時実行制限、ハード同時実行制限、目標使用率、および RPS を設定することで設定できます。
ソフト同時実行制限の設定
ソフト同時実行制限は、厳密に適用される制限ではなく、目標とする制限です。一部のシナリオ、特にリクエストバーストが発生した場合、値を超える可能性があります。
リビジョンの設定
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "200"グローバル設定
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200" # Knative サービスの同時実行ターゲットを指定します。
リビジョンのハード同時実行制限の設定
アプリケーションに特定の同時実行数の上限がある場合にのみ、ハード同時実行制限を指定することをお勧めします。ハード同時実行制限を低く設定すると、アプリケーションのスループットと応答レイテンシに悪影響を及ぼします。
ハード同時実行制限は厳密に適用される制限です。ハード同時実行制限に達すると、リクエストを処理するために十分なリソースが使用できるようになるまで、超過リクエストは queue-proxy または Activator サービスによってバッファリングされます。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containerConcurrency: 50目標使用率
目標使用率は、オートスケーラーの目標の実際の割合を指定します。目標使用率を使用して、同時実行値を調整することもできます。目標使用率は、ポッドが実行されるホットネスとも呼ばれます。これにより、指定されたハード同時実行制限に達する前に、オートスケーラーがスケールアウトします。
たとえば、containerConcurrency が 10 に設定され、目標使用率が 70(パーセント)に設定されている場合、オートスケーラーは、すべての既存のポッドの平均同時実行リクエスト数が 7 に達するとポッドを作成します。ポッドが作成されてから準備完了状態になるまでには、ある程度の時間がかかります。目標使用率の値を小さくすると、ハード同時実行制限に達する前に新しいポッドを作成できます。これは、コールドスタートによる応答レイテンシの短縮に役立ちます。
リビジョンの設定
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70" # 目標使用率の割合を設定します。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバル設定
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-percentage: "70" # KPA は、各ポッドの同時実行数が現在のリソースの 70% を超えないようにしようとします。RPS の設定
RPS は、ポッドが 1 秒あたりに処理できるリクエスト数を指定します。
リビジョンの設定
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "150"
autoscaling.knative.dev/metric: "rps" # ポッド数は RPS 値に基づいて調整されます。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバル設定
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
requests-per-second-target-default: "150"シナリオ 1:同時実行ターゲットを設定して自動スケーリングを設定する
この例では、同時実行ターゲットを設定して KPA が自動スケーリングを実行できるようにする方法を示します。
次の YAML テンプレートを使用して autoscale-go.yaml という名前のファイルを作成し、クラスタにデプロイします。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # 同時実行ターゲットを 10 に設定します。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yamlイングレスゲートウェイを取得します。
ALB
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl get albconfig knative-internet予想される出力:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl -n knative-serving get ing stats-ingress予想される出力:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"予想される出力:
121.XX.XX.XXKourier
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl -n knative-serving get svc kourier予想される出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m負荷テストツール hey を使用して、30 秒以内に 50 の同時実行リクエストをアプリケーションに送信します。
説明hey の詳細については、hey を参照してください。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX はイングレスゲートウェイの IP アドレスです。予想される出力:
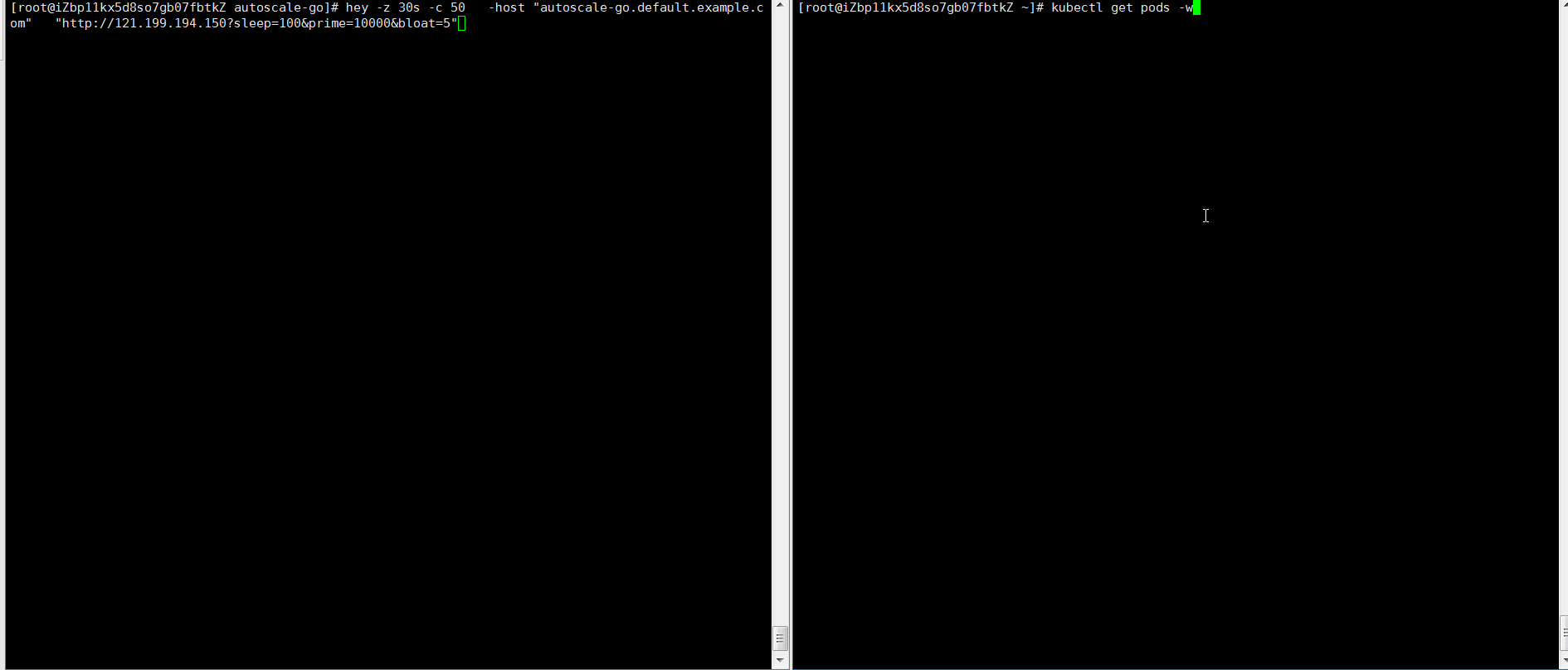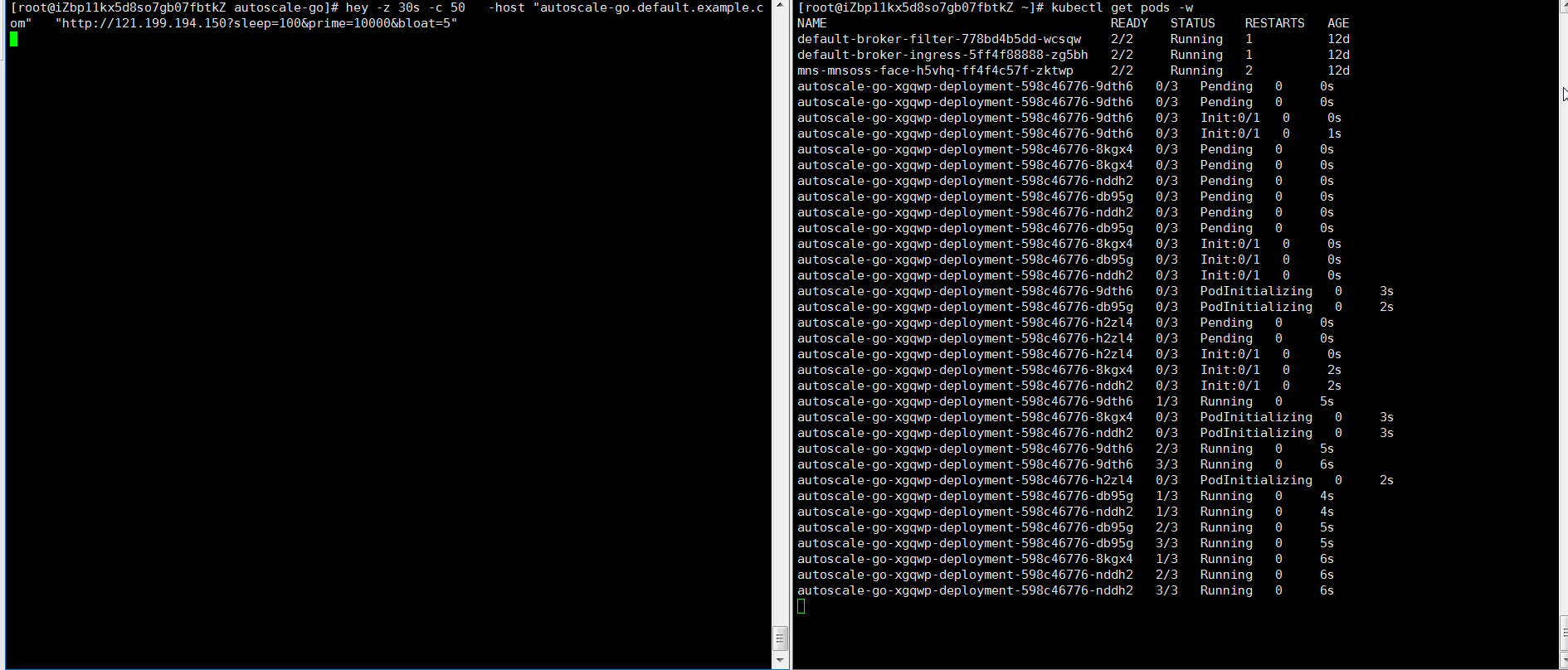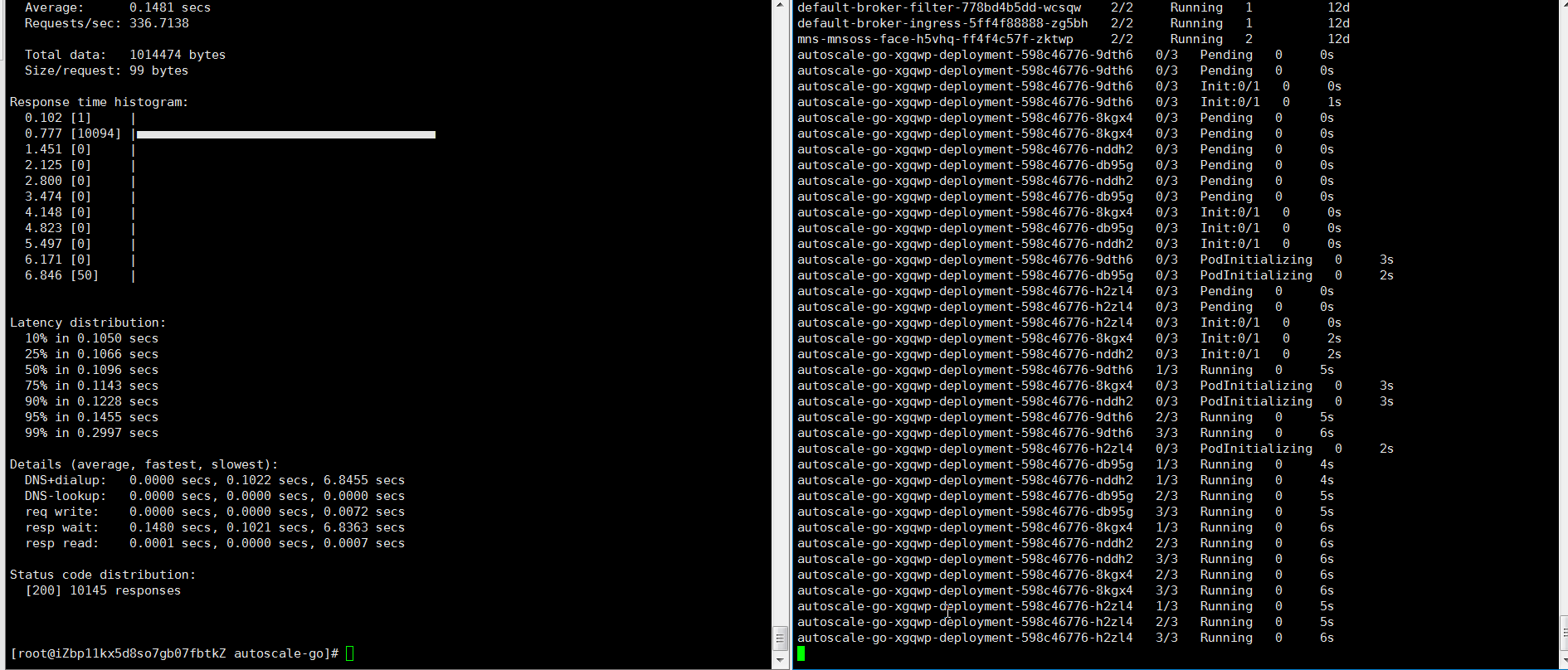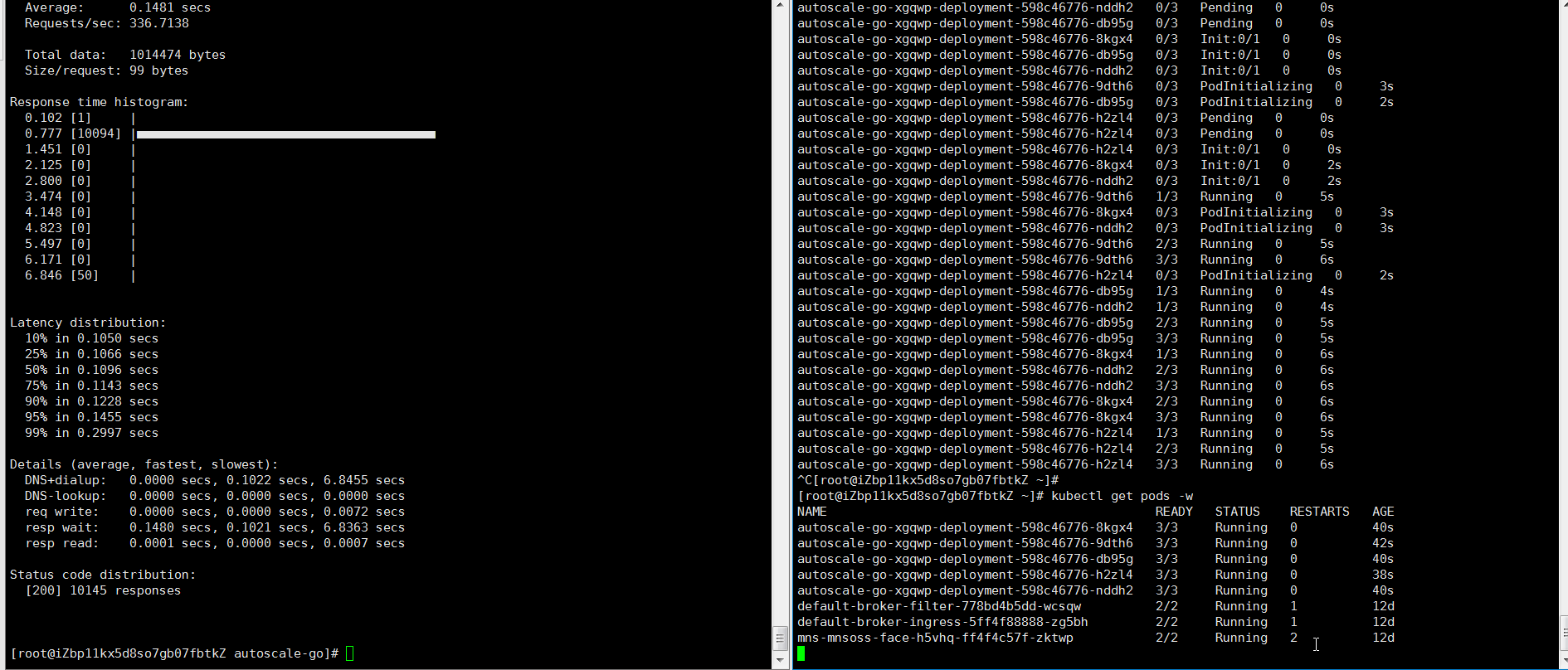
出力は、予想どおり 5 つのポッドが追加されたことを示しています。
シナリオ 2:スケール境界を設定して自動スケーリングを有効にする
スケール境界は、アプリケーションにプロビジョニングできるポッドの最小数と最大数を制御します。この例では、スケール境界を設定して自動スケーリングを有効にする方法を示します。
次の YAML テンプレートを使用して autoscale-go.yaml という名前のファイルを作成し、クラスタにデプロイします。
この YAML テンプレートは、同時実行ターゲットを 10、
min-scaleを 1、max-scaleを 3 に設定します。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yamlイングレスゲートウェイを取得します。
ALB
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl get albconfig knative-internet予想される出力:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl -n knative-serving get ing stats-ingress予想される出力:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"予想される出力:
121.XX.XX.XXKourier
次のコマンドを実行して、イングレスゲートウェイを取得します。
kubectl -n knative-serving get svc kourier予想される出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m負荷テストツール hey を使用して、30 秒以内に 50 の同時実行リクエストをアプリケーションに送信します。
説明hey の詳細については、hey を参照してください。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX はイングレスゲートウェイの IP アドレスです。予想される出力:
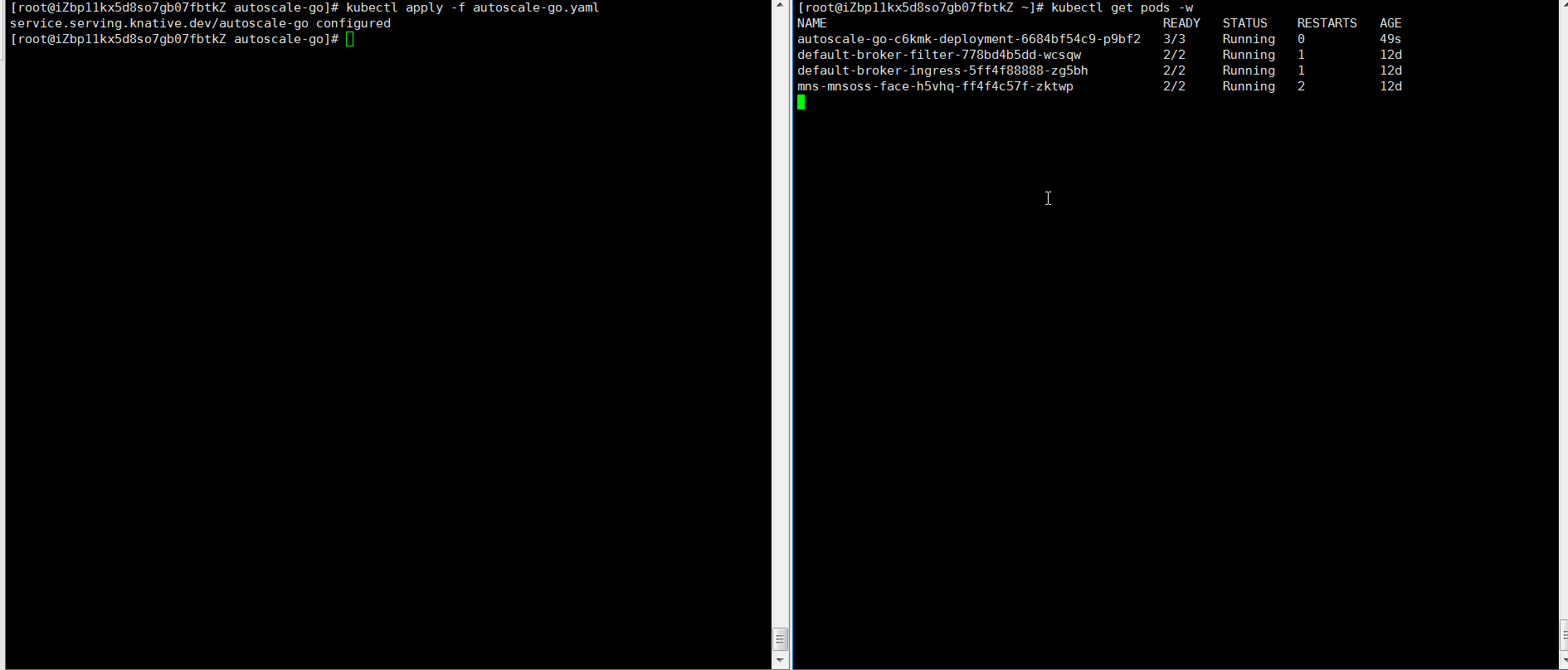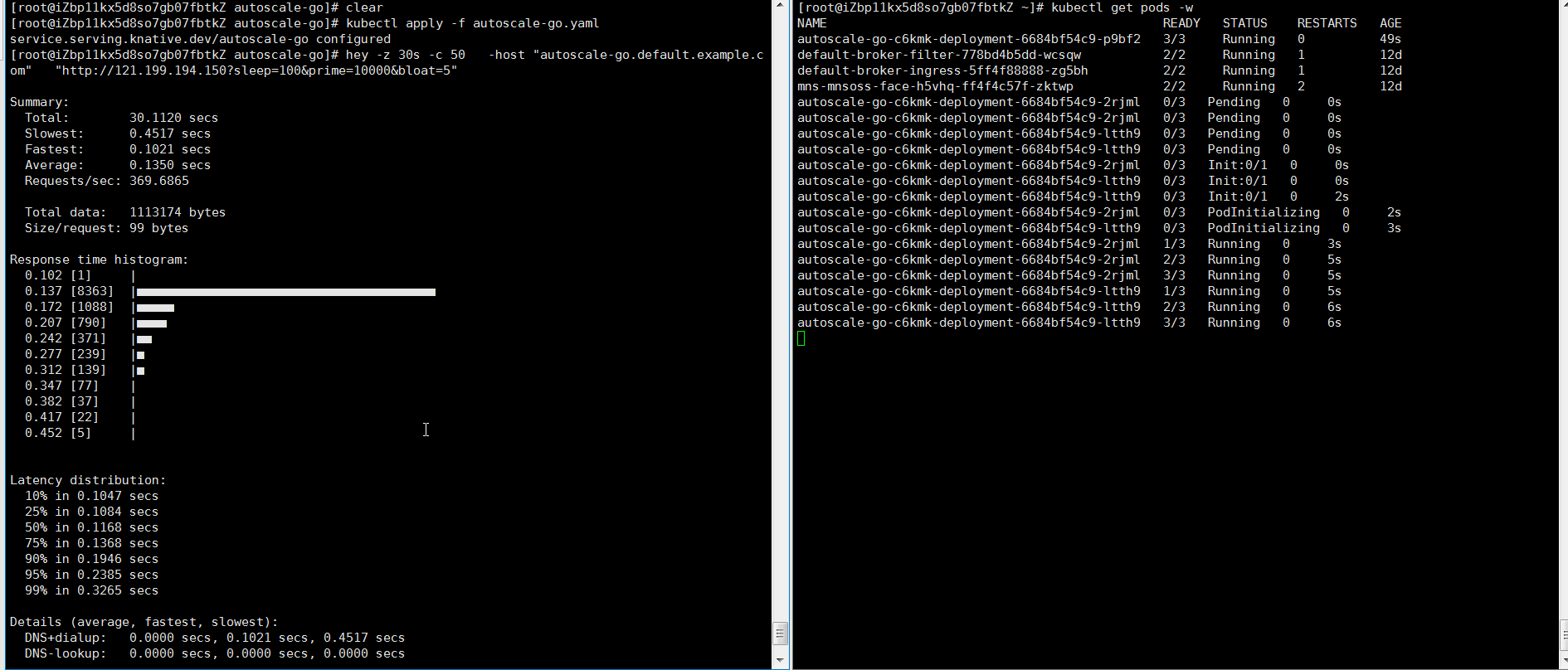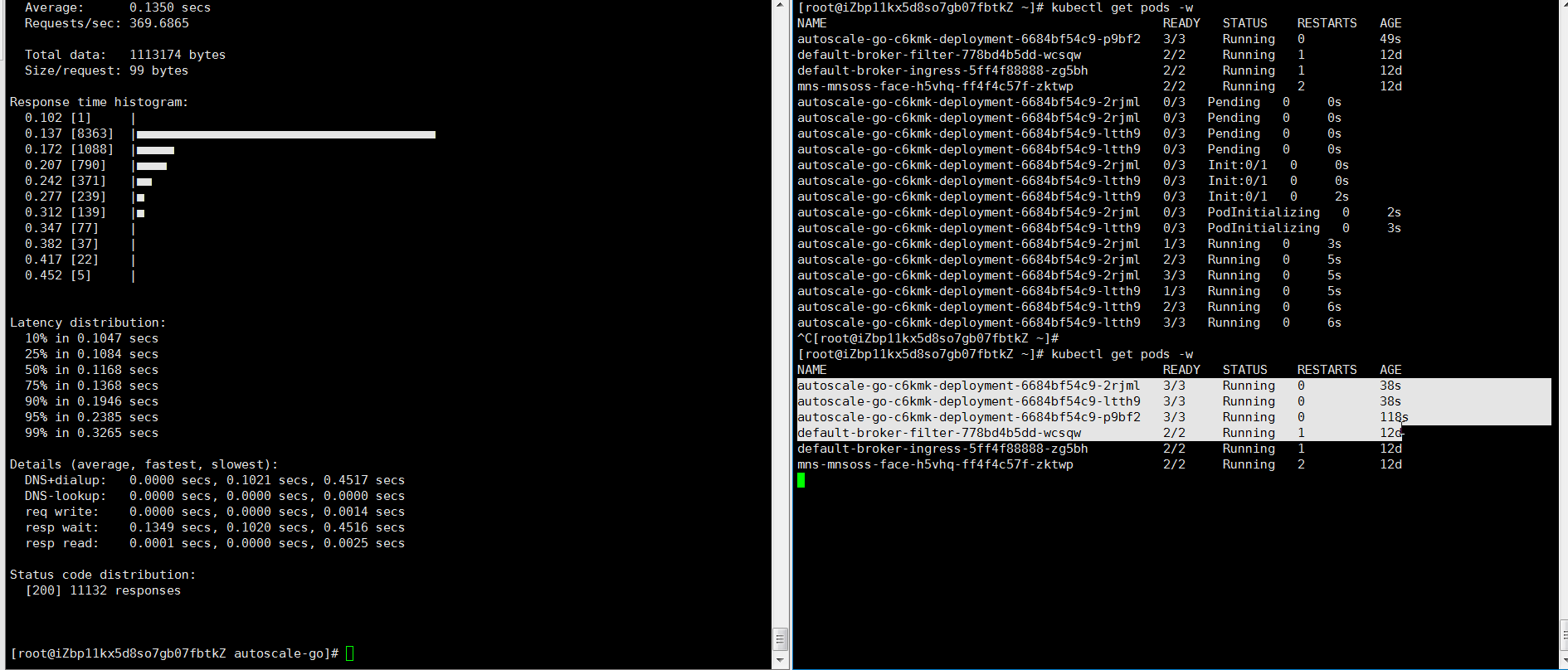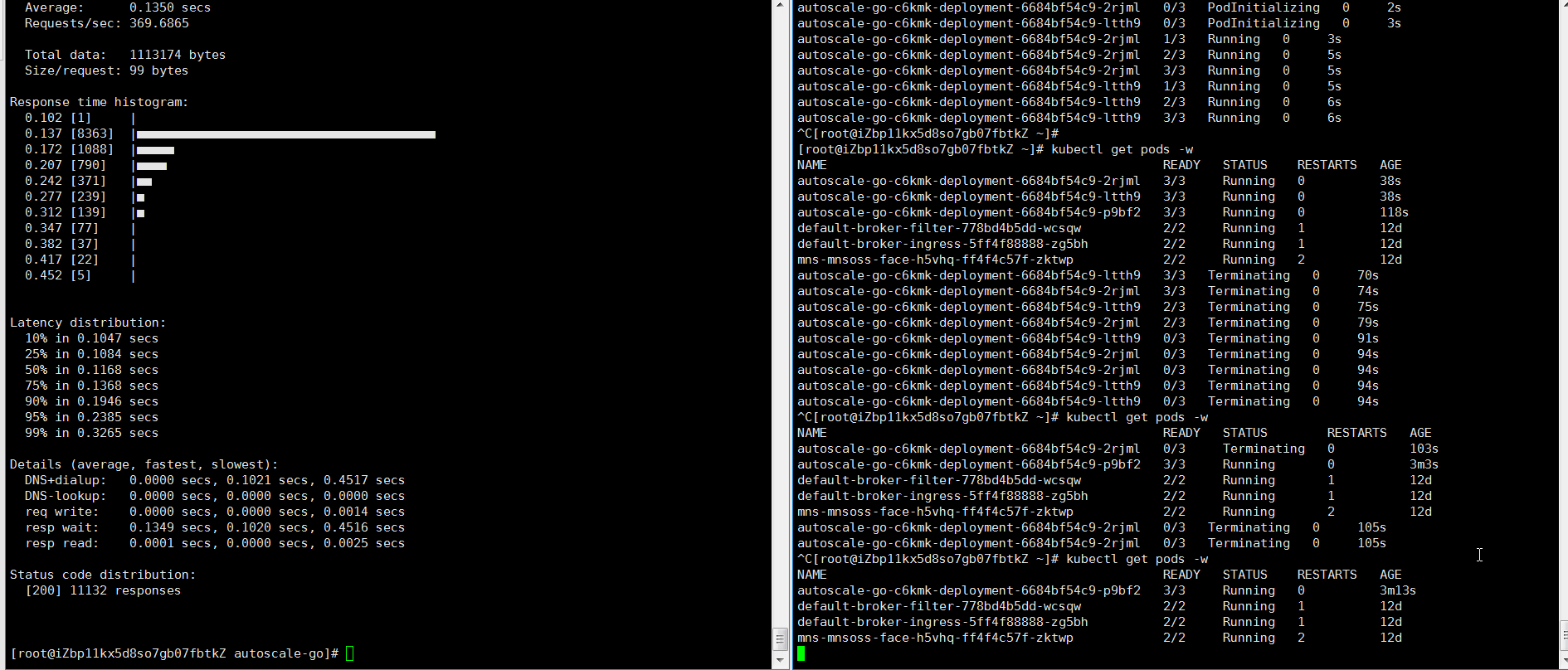
最大 3 つのポッドが追加されます。アプリケーションにトラフィックが流れていない場合は、1 つのポッドが予約されます。
参考文献
Knative で AHPA を使用して、過去のメトリクス値に基づいてリソースを事前にスケーリングできます。詳細については、AHPA を使用してスケジュールされた自動スケーリングを実装する を参照してください。