分散システムは複雑であり、インフラストラクチャ、アプリケーションロジック、および O&M の安定性にリスクをもたらします。これは、ビジネスシステムの障害につながる可能性があります。したがって、フォールトトレランス機能を備えた分散システムを構築することが重要です。このトピックでは、Service Mesh(ASM)を使用してタイムアウト処理、再試行、バルクヘッド、およびサーキットブレーカーメカニズムを構成し、フォールトトレランス機能を備えた分散システムを構築する方法について説明します。
背景情報
フォールトトレランスとは、部分的な障害発生時にもシステムが動作し続ける機能のことです。信頼性と回復力のあるシステムを作成するには、システム内のすべてのサービスにフォールトトレランスがあることを確認する必要があります。クラウド環境の動的な性質上、サービスは障害を積極的に予測し、予期しないインシデントに適切に対応する必要があります。
各サービスで、サービスリクエストが失敗する可能性があります。失敗したサービスリクエストを処理するための適切な対策を用意する必要があります。特定のサービスの中断は、連鎖的な影響を引き起こし、ビジネスに深刻な影響を与える可能性があります。したがって、システムの回復力を構築、テスト、および活用する必要があります。ASM は、タイムアウト処理、再試行、バルクヘッド、およびサーキットブレーカーメカニズムをサポートするフォールトトレランソリューションを提供します。このソリューションは、アプリケーションのコードを変更することなく、アプリケーションにフォールトトレランスをもたらします。
タイムアウト処理
仕組み
クライアントがアップストリームサービスにリクエストを送信すると、アップストリームサービスが応答しない場合があります。タイムアウト期間を設定できます。アップストリームサービスがタイムアウト期間内にリクエストに応答しない場合、クライアントはリクエストを失敗とみなし、アップストリームサービスからの応答を待機しなくなります。
タイムアウト期間が設定されると、バックエンドサービスがタイムアウト期間内に応答しない場合、アプリケーションはリターンエラーを受け取ります。その後、アプリケーションは適切なフォールバックアクションを実行できます。タイムアウト設定は、リクエスト元のクライアントがサービスのリクエストへの応答を待機する時間を指定します。タイムアウト設定は、サービスの処理動作には影響しません。したがって、タイムアウトは、リクエストされた操作が失敗することを意味するものではありません。
ソリューション
ASM を使用すると、仮想サービス内のルートにタイムアウトポリシーを構成して、タイムアウト期間を設定できます。サイドカープロキシがタイムアウト期間内に応答を受信しない場合、リクエストは失敗します。ルートのタイムアウト期間を設定すると、タイムアウト設定は、そのルートを使用するすべてのリクエストに適用されます。
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
timeout: 5stimeout: タイムアウト期間を指定します。リクエストされたサービスが指定されたタイムアウト期間内に応答しない場合、エラーが返され、リクエスト元のクライアントは応答を待機しなくなります。
再試行メカニズム
仕組み
サービスでリクエストのタイムアウト、接続のタイムアウト、サービスの停止などのリクエスト障害が発生した場合、再試行メカニズムを構成してサービスを再度リクエストできます。
頻繁に、または長時間再試行しないでください。そうしないと、カスケード障害が発生する可能性があります。
ソリューション
ASM を使用すると、仮想サービスを作成して HTTP リクエストの再試行ポリシーを定義できます。この例では、次の再試行ポリシーを定義するために仮想サービスが作成されます。ASM インスタンス内のサービスが httpbin アプリケーションをリクエストする場合、httpbin アプリケーションが応答しない、またはサービスが httpbin アプリケーションへの接続の確立に失敗した場合、サービスは httpbin アプリケーションを最大 3 回再度リクエストします。各リクエストのタイムアウト期間は 5 秒です。
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 5s
retryOn: connect-failure,resetretries 構造体に次のフィールドを構成して、リクエストに対するサイドカープロキシの再試行動作をカスタマイズできます。
フィールド | 説明 |
attempts | リクエストの最大再試行回数を指定します。サービスルートの再試行メカニズムとタイムアウト期間の両方が構成されている場合、実際の再試行回数はタイムアウト期間によって異なります。たとえば、リクエストが最大再試行回数に達していないが、すべての再試行に費やされた合計時間がタイムアウト期間を超えた場合、サイドカープロキシはリクエストの再試行を停止し、タイムアウト応答を返します。 |
perTryTimeout | 再試行ごとのタイムアウト期間を指定します。単位:ミリ秒、秒、分、または時間。 |
retryOn | 再試行が実行される条件を指定します。複数の再試行条件はコンマ(,)で区切ります。詳細については、「HTTP リクエストの一般的な再試行条件」および「gRPC リクエストの一般的な再試行条件」をご参照ください。 |
次の表に、HTTP リクエストの一般的な再試行条件を示します。
再試行条件 | 説明 |
connect-failure | アップストリームサービスへの接続に失敗した(接続タイムアウトなど)ためにリクエストが失敗した場合、再試行が実行されます。 |
refused-stream | アップストリームサービスが REFUSED_STREAM フレームを返してストリームをリセットした場合、再試行が実行されます。 |
reset | アップストリームサービスが応答する前に、切断、リセット、または読み取りタイムアウトイベントが発生した場合、再試行が実行されます。 |
5xx | アップストリームサービスが 500 や 503 などの 5XX 応答コードを返すか、アップストリームサービスが応答しない場合、再試行が実行されます。 説明 5xx 再試行条件には、connect-failure および refused-stream の再試行条件が含まれます。 |
gateway-error | アップストリームサービスが 502、503、または 504 ステータスコードを返す場合、再試行が実行されます。 |
envoy-ratelimited | リクエストに x-envoy-ratelimited ヘッダーが存在する場合、再試行が実行されます。 |
retriable-4xx | アップストリームサービスが 409 ステータスコードを返す場合、再試行が実行されます。 |
retriable-status-codes | アップストリームサービスから返されたステータスコードが再試行を許可していることを示している場合、再試行が実行されます。 説明 retryOn フィールドに有効なステータスコードを追加して、 |
retriable-headers | アップストリームサービスから返されたレスポンスヘッダーに、再試行が許可されていることを示すヘッダーが含まれている場合、再試行が実行されます。 説明 リクエストヘッダーに |
gRPC は転送プロトコルとして HTTP/2 を使用します。したがって、HTTP リクエストの再試行ポリシーの retryOn フィールドで gRPC リクエストの再試行条件を設定できます。次の表に、gRPC リクエストの一般的な再試行条件を示します。
再試行条件 | 説明 |
cancelled | アップストリーム gRPC サービスのレスポンスヘッダーの gRPC ステータスコードが cancelled(1)の場合、再試行が実行されます。 |
unavailable | アップストリーム gRPC サービスのレスポンスヘッダーの gRPC ステータスコードが unavailable(14)の場合、再試行が実行されます。 |
deadline-exceeded | アップストリーム gRPC サービスのレスポンスヘッダーの gRPC ステータスコードが deadline-exceeded(4)の場合、再試行が実行されます。 |
internal | アップストリーム gRPC サービスのレスポンスヘッダーの gRPC ステータスコードが internal(13)の場合、再試行が実行されます。 |
resource-exhausted | アップストリーム gRPC サービスのレスポンスヘッダーの gRPC ステータスコードが resource-exhausted(8)の場合、再試行が実行されます。 |
HTTP リクエストのデフォルトの再試行ポリシーを構成する
デフォルトでは、ASM 内のサービスは、仮想サービスを使用して HTTP リクエストの再試行ポリシーが定義されていない場合でも、他の HTTP サービスにアクセスするときに HTTP リクエストのデフォルトの再試行ポリシーを採用します。このデフォルトの再試行ポリシーの再試行回数は 2 で、再試行のタイムアウト期間は設定されていません。デフォルトの再試行条件は、connect-failure、refused-stream、unavailable、cancelled、および retriable-status-codes です。ASM コンソールの [基本情報] ページで、HTTP リクエストのデフォルトの再試行ポリシーを構成できます。構成後、新しいデフォルトの再試行ポリシーは元のデフォルトの再試行ポリシーをオーバーライドします。
この機能は、バージョンが 1.15.3.120 以降の ASM インスタンスでのみ使用できます。ASM インスタンスの更新方法の詳細については、「ASM インスタンスを更新する」をご参照ください。
ASM コンソール にログインします。左側のナビゲーションペインで、 を選択します。
[メッシュ管理] ページで、ASM インスタンスの名前をクリックします。左側のナビゲーションペインで、 を選択します。
構成情報[基本情報] ページの 編集既定の HTTP 再試行ポリシー セクションで、 の横にある をクリックします。
[デフォルトの HTTP 再試行ポリシー] ダイアログボックスで、関連パラメーターを構成し、[OK] をクリックします。
パラメーター
説明
再試行回数
前述の attempts フィールドに対応します。HTTP リクエストのデフォルトの再試行ポリシーでは、このフィールドを 0 に設定できます。これは、デフォルトで HTTP リクエストの再試行が無効になっていることを示します。
タイムアウト
前述の perTryTimeout フィールドに対応します。
再試行条件
前述の retryOn フィールドに対応します。
バルクヘッドパターン
仕組み
バルクヘッドパターンは、クライアントがサービスに対して開始できる接続の最大数とアクセスリクエストの最大数を制限して、サービスへの過剰なアクセスを回避します。指定されたしきい値を超えると、新しいリクエストは切断されます。バルクヘッドパターンは、サービスで使用されるリソースを分離し、カスケードシステム障害を防ぐのに役立ちます。同時接続の最大数と各接続のタイムアウト期間は、TCP と HTTP の両方で有効な一般的な接続設定です。接続あたりのリクエストの最大数とリクエストの再試行の最大数は、HTTP1.1、HTTP2、および Google Remote Procedure Call(gRPC)接続に対してのみ有効です。
ソリューション
ASM を使用すると、宛先ルールを作成してバルクヘッドパターンを構成できます。この例では、次のバルクヘッドパターンを定義するために宛先ルールが作成されます。サービスが httpbin アプリケーションをリクエストする場合、同時接続の最大数は 1、接続あたりのリクエストの最大数は 1、リクエストの再試行の最大数は 1 です。さらに、10 秒以内に httpbin アプリケーションへの接続が確立されない場合、サービスは 503 エラーを受け取ります。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
connectTimeout: 10s
maxConnections: 1http1MaxPendingRequests: リクエストの再試行の最大数を指定します。
maxRequestsPerConnection: 接続あたりのリクエストの最大数を指定します。
connectTimeout: 各接続のタイムアウト期間を指定します。
maxConnections: 同時接続の最大数を指定します。
サーキットブレーカー
仕組み
サーキットブレーカーメカニズムは、次のように動作します。サービス B がサービス A からの要求に応答しない場合、サービス A は新しい要求の送信を停止しますが、指定された期間内に発生する連続エラーの数をチェックします。連続エラーの数が指定されたしきい値を超えると、サーキットブレーカーは現在の要求を切断します。サーキットブレーカーが閉じるまで、後続のすべての要求は失敗します。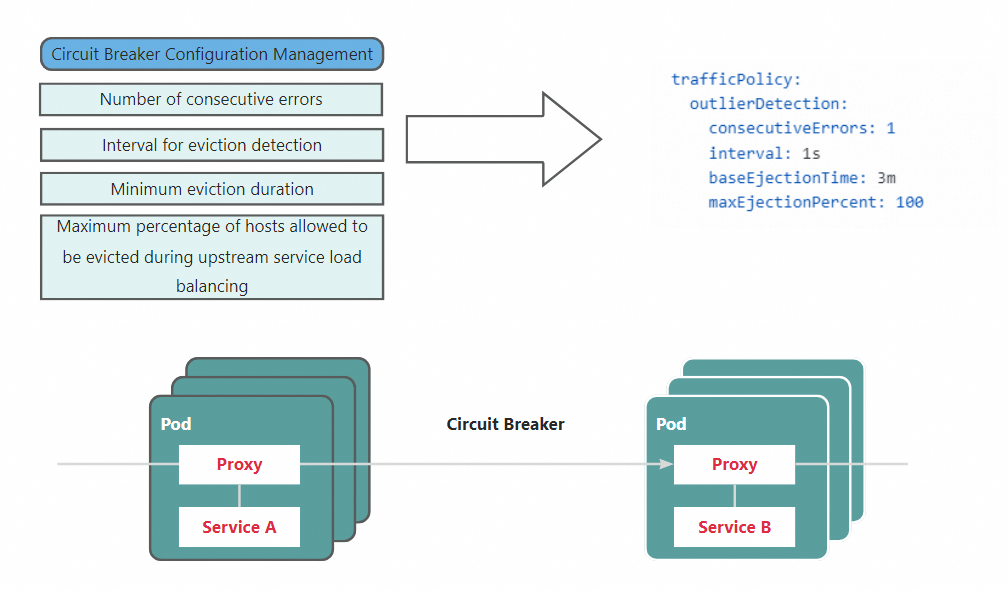
解決策
ASM を使用すると、ホストレベルのサーキットブレーカーメカニズムを設定する宛先ルールを作成できます。この例では、次のサーキットブレーカーメカニズムを定義する宛先ルールが作成されます。サービスが 5 秒以内に 3 回連続して httpbin アプリケーションへのリクエストに失敗した場合、このサービスから httpbin アプリケーションの同じホストへのリクエストは 5 分間許可されません。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
outlierDetection:
consecutiveErrors: 3 # 連続エラーの数を指定します。
interval: 5s # 排除検出の時間間隔を指定します。
baseEjectionTime: 5m # 最小排除期間を指定します。
maxEjectionPercent: 100 # ロードバランシングプールから排除できるホストの最大割合を指定します。
consecutiveErrors: 連続エラーの数を指定します。
interval: 排除検出の時間間隔を指定します。
baseEjectionTime: 最小排除期間を指定します。
maxEjectionPercent: ロードバランシングプールから排除できるホストの最大割合を指定します。
ホストレベルのサーキットブレーキング関連のメトリクスを表示する
ホストレベルのサーキットブレーキングシナリオでは、クライアントのサイドカープロキシが、アップストリームサービスの各ホストのエラー率を個別に検出し、ホストで連続したエラーが発生した場合に、サービスのロードバランシングプールからホストを除外します。このホストレベルのサーキットブレーキングメカニズムは、ASMCircuitBreakerフィールドを使用して定義されたサーキットブレーキングメカニズムとは異なります。
ホストレベルのサーキットブレーキングでは、一連の関連メトリクスが生成されます。これは、サーキットブレーキングが発生したかどうかを判断するのに役立ちます。次の表に、関連するメトリクスを示します。
メトリクス | タイプ | 説明 |
envoy_cluster_outlier_detection_ejections_active | Gauge | 除外されたホストの数 |
envoy_cluster_outlier_detection_ejections_enforced_total | Counter | ホストの除外が発生した回数 |
envoy_cluster_outlier_detection_ejections_overflow | Counter | 最大除外率に達したため、ホストの除外が中止された回数 |
ejections_detected_consecutive_5xx | Counter | ホストで検出された連続した 5xx エラーの数 |
サイドカープロキシの proxyStatsMatcher を設定して、サイドカープロキシがサーキットブレーキング関連のメトリクスを報告できるようにすることができます。設定後、Prometheus を使用して、サーキットブレーキング関連のメトリクスを収集および表示できます。
proxyStatsMatcher を使用して、サーキットブレーキング関連のメトリクスを報告するようにサイドカープロキシを設定できます。 proxyStatsMatcher を選択した後、正規表現の一致
.*outlier_detection.*サイドカープロキシを構成する を選択し、値を に設定します。詳細については、「」の proxyStatsMatcher セクションをご参照ください。httpbin アプリケーションのデプロイメントを再デプロイします。詳細については、「サイドカープロキシの設定」の「(オプション)ワークロードの再デプロイ」セクションをご参照ください。
ホストレベルのサーキットブレーカーのメトリック収集とアラートを構成する
ホストレベルのサーキットブレーキングに関連するメトリクスを構成した後、Prometheus インスタンスを構成してメトリクスを収集できます。また、主要なメトリクスに基づいてアラートルールを構成することもできます。このようにして、サーキットブレーキングが発生したときにアラートが生成されます。次のセクションでは、ホストレベルのサーキットブレーキングのメトリック収集とアラートを構成する方法について説明します。この例では、Managed Service for Prometheus を使用します。
Managed Service for Prometheus で、データプレーン上の ACK クラスタを [alibaba Cloud ASM] コンポーネントに接続するか、Alibaba Cloud ASM コンポーネントを最新バージョンにアップグレードします。これにより、サーキットブレーキングメトリクスが Managed Service for Prometheus によって収集されるようになります。コンポーネントを ARMS に統合する方法の詳細については、「コンポーネントの管理」をご参照ください。(「自己管理型 Prometheus インスタンスを使用して ASM インスタンスを監視する」を参照して、自己管理型 Prometheus インスタンスを統合して ASM インスタンスのメトリクスを収集している場合は、この手順を実行する必要はありません。)
ホストレベルのサーキットブレーキングのアラートルールを作成します。詳細については、「カスタム PromQL ステートメントを使用してアラートルールを作成する」をご参照ください。次の表は、アラートルールを設定するための主要なパラメーターを指定する方法について説明しています。その他のパラメーターの詳細については、前述のドキュメントをご参照ください。
パラメーター
例
説明
カスタム PromQL ステートメント
(sum (envoy_cluster_outlier_detection_ejections_active) by (cluster_name, namespace)) > 0
この例では、envoy_cluster_outlier_detection_ejections_active メトリクスをクエリして、現在のクラスタでホストが排出されているかどうかを判断します。クエリ結果は、サービスが存在する名前空間とサービス名でグループ化されます。
アラートメッセージ
ホストレベルのサーキットブレーキングがトリガーされました。一部のワークロードでエラーが繰り返し発生し、ホストがロードバランシングプールから排出されました。名前空間: {$labels.namespace}}、ホストの排出が発生したサービス: {{$labels.cluster_name}}。排出されたホストの数: {{ $value }}
この例の警告情報は、サーキットブレーキングをトリガーしたサービスの名前空間、サービス名、および排出されたホストの数を示しています。