このトピックでは、ApsaraMQ for Kafka と ApsaraDB RDS for MySQL の間でデータを同期するための JDBC コネクタを作成する方法について説明します。
前提条件
EventBridge がアクティブ化されており、必要な権限がResource Access Management (RAM) ユーザーに付与されていること。詳細については、「EventBridge をアクティブ化し、RAM ユーザーに権限を付与する」をご参照ください。
オブジェクトストレージサービス (OSS) がアクティブ化されており、バケットが作成されていること。詳細については、「OSSコンソールを使用して始める」をご参照ください。
Serverless App Engine (SAE) がアクティブ化されていること。詳細については、「SAEを使い始める」をご参照ください。
仮想プライベートクラウド (VPC) と vSwitch が作成されていること。詳細については、「IPv4 CIDRブロックを持つVPCを作成する」をご参照ください。
ApsaraMQ for Kafka インスタンスが購入され、デプロイされていること。詳細については、「手順 2: インスタンスを購入してデプロイする」をご参照ください。
手順 1: テーブルを作成する
ApsaraDB RDSコンソール にログインして、ApsaraDB RDS for MySQLインスタンスを作成します。詳細については、「ApsaraDB RDS for MySQLインスタンスを作成する」をご参照ください。
ApsaraDB RDS for MySQL インスタンスを作成する際は、このトピックの「前提条件」セクションで作成した ApsaraMQ for Kafka インスタンスがデプロイされている VPC を選択し、VPC の CIDR ブロックをホワイトリストに追加します。

[インスタンス] ページで、作成した ApsaraDB RDS for MySQL インスタンスをクリックします。次に、インスタンス詳細ページの左側のナビゲーションペインで、以下の操作を実行します。
[アカウント] をクリックします。表示されるページで、[アカウントの作成] をクリックしてアカウントを作成します。詳細については、「データベースとアカウントを作成する」をご参照ください。既存のアカウントを使用することもできます。
[データベース] をクリックします。表示されるページで、[データベースの作成] をクリックしてデータベースを作成します。詳細については、「データベースとアカウントを作成する」をご参照ください。既存のデータベースを使用することもできます。
[データベース接続] をクリックして、内部エンドポイントとポート番号を表示し、記録します。

インスタンス詳細ページで、[データベースにログオン] をクリックして、Data Management (DMS) コンソールに移動します。次に、管理するデータベースをクリックし、SQL ステートメントを使用してテーブルを作成します。次のサンプルコマンドは、列名が id と number であるテーブルを作成する方法の例を示しています。詳細については、「SQLコマンド」をご参照ください。
CREATE TABLE sql_table(id INT ,number INT);重要テーブルを作成する際は、いずれかの列をプライマリキーとして指定し、その列をインクリメンタルとして指定します。詳細については、「スキーマのクエリと変更」をご参照ください。
手順 2: コネクタを作成する
ソースコネクタ
JDBCコネクタ ファイルをダウンロードし、作成した OSS バケットにアップロードします。詳細については、「OSSコンソールを使用して始める」をご参照ください。
重要JDBC コネクタファイルをダウンロードする際は、Java 8 と互換性のあるバージョンを選択してください。
ApsaraMQ for Kafka コンソール にログインします。リソースの分布 セクションの 概要 ページで、管理する ApsaraMQ for Kafka インスタンスが存在するリージョンを選択します。
左側のナビゲーションペインで、 を選択します。
タスクリスト ページで、タスクリストの作成 をクリックします。
タスクの作成 ページで、[タスク名] パラメータを設定し、画面上の指示に従って他のパラメータを設定します。次のセクションでは、パラメータについて説明します。
タスクの作成
Source (ソース) 手順で、データプロバイダー パラメータを [apache Kafka Connect] に設定し、次へ をクリックします。
コネクタの設定 手順で、パラメータを設定し、次へ をクリックします。次の表にパラメータを示します。
サブセクション
パラメータ
説明
Kafka Connectプラグイン
バケット
JDBCコネクタファイルをアップロードした OSS バケットを選択します。
ファイル
OSS バケットにアップロードした JDBC コネクタファイルを選択します。
Message Queue for Apache Kafkaリソース
Message Queue for Apache Kafkaパラメータ
[ソースコネクト] を選択します。
Message Queue for Apache Kafkaインスタンス
このトピックの「前提条件」セクションで作成した ApsaraMQ for Kafka インスタンスを選択します。
VPC
作成した VPC を選択します。
vSwitch
作成した vSwitch を選択します。
セキュリティグループ
セキュリティグループを選択します。
Kafka Connect
ZIPパッケージ内の .properties ファイルを解析する
[.properties ファイルを作成] を選択します。次に、ソースコネクタの構成を含む .properties ファイルを ZIP パッケージから選択します。 .properties ファイルのパスは /etc/source-xxx.properties です。
JDBC ソースコネクタの作成に使用されるすべてのパラメーターについては、JDBC ソースコネクタ構成プロパティ をご参照ください。
インスタンス設定 ステップで、パラメーターを設定し、次へ をクリックします。次の表にパラメーターを示します。
サブセクション
パラメーター
説明
ワーカータイプ
ワーカータイプ
ワーカータイプを選択します。
ワーカーの最小数
このパラメーターを 1 に設定します。
ワーカーの最大数
このパラメーターを 1 に設定します。
ワーカー設定
Apache Kafka Connector ワーカーの依存関係を自動的に作成する
このオプションを選択することをお勧めします。このオプションを選択すると、システムは、選択した ApsaraMQ for Kafka インスタンスで Kafka Connect を実行するために必要な内部トピックとコンシューマーグループを作成し、コードエディターの対応するパラメーターに情報を同期します。次のセクションでは、設定項目について説明します。
オフセットトピック: オフセットデータを格納するために使用されるトピック。トピックの名前は
connect-eb-offset-<Task name>形式です。設定トピック: コネクタとタスクの設定データを格納するために使用されるトピック。トピックの名前は
connect-eb-config-<Task name>形式です。ステータストピック: コネクタとタスクのステータスデータを格納するために使用されるトピック。トピックの名前は
connect-eb-status-<Task name>形式です。Kafka Connect コンシューマーグループ: Kafka Connect ワーカーが内部トピックのメッセージを消費するために使用するコンシューマーグループ。コンシューマーグループの名前は
connect-eb-cluster-<Task name>形式です。Kafka ソースコネクタコンシューマーグループ: ソース トピックのデータを消費するために使用されるコンシューマーグループ。このコンシューマーグループは、シンクコネクタに対してのみ有効です。コンシューマーグループの名前は
connector-eb-cluster-<task name>-<connector name>形式です。
実行設定 セクションで、[ログ配信] パラメーターを [ログサービスにデータを送信] または [apsaramq For Kafka にデータを送信] に設定し、[ロールの承認] サブセクションの [ロール] ドロップダウンリストから Kafka Connect が依存するロールを選択し、[保存] をクリックします。
重要AliyunSAEFullAccess 権限ポリシーがアタッチされているロールを選択することをお勧めします。そうでない場合、タスクの実行に失敗する可能性があります。
タスクのプロパティ
タスクの再試行ポリシーとデッドレターキューを設定します。詳細については、「再試行ポリシーとデッドレターキュー」をご参照ください。
タスクの状態が [実行中] になると、コネクタは予期したとおりに動作を開始します。
シンク コネクタ
JDBCコネクタ ファイルをダウンロードし、作成したOSSバケットにアップロードします。詳細については、「OSSコンソールを使用して開始する」をご参照ください。
重要JDBCコネクタファイルをダウンロードする際は、Java 8と互換性のあるバージョンを選択してください。
ApsaraMQ for Kafka コンソール にログオンします。リソースの分布 セクションの 概要 ページで、管理するApsaraMQ for Kafkaインスタンスが存在するリージョンを選択します。
左側のナビゲーションペインで、 を選択します。
タスクリスト ページで、タスクリストの作成 をクリックします。
タスクの作成 ページで、[タスク名] パラメータを設定し、画面の指示に従って他のパラメータを設定します。次のセクションでは、パラメータについて説明します。
タスクの作成
Source (ソース) 手順で、データプロバイダー パラメータを [apache Kafka Connect] に設定し、次へ をクリックします。
コネクタの設定 手順で、パラメータを設定し、次へ をクリックします。次の表にパラメータを示します。
サブセクション
パラメータ
説明
Kafka Connectプラグイン
バケット
JDBCコネクタファイルをアップロードしたOSSバケットを選択します。
ファイル
OSSバケットにアップロードしたJDBCコネクタファイルを選択します。
Message Queue for Apache Kafkaリソース
Message Queue for Apache Kafkaパラメータ
Sink Connectを選択します。
Message Queue for Apache Kafkaインスタンス
このトピックの「前提条件」セクションで作成したApsaraMQ for Kafkaインスタンスを選択します。
VPC
作成したVPCを選択します。
vSwitch
作成したvSwitchを選択します。
セキュリティグループ
セキュリティグループを選択します。
Kafka Connect
ZIPパッケージ内の.propertiesファイルを解析する
[.propertiesファイルの作成] を選択します。次に、シンクコネクタの構成を含む.propertiesファイルをZIPパッケージから選択します。 .propertiesファイルのパスは /etc/sink-xxx.properties です。
JDBCシンクコネクタの作成に使用されるすべてのパラメータについては、「JDBC Sink Connector Configuration Properties」をご参照ください。
インスタンス設定 手順で、パラメータを設定し、次へ をクリックします。次の表にパラメータを示します。
サブセクション
パラメータ
説明
ワーカータイプ
ワーカータイプ
ワーカータイプを選択します。
ワーカーの最小数
このパラメータを 1 に設定します。
ワーカーの最大数
このパラメータを 1 に設定します。このフィールドの値は、tasks.max フィールドの値より大きくすることはできません。
ワーカー構成
Apache Kafka Connector Workerの依存関係を自動的に作成する
このオプションを選択することをお勧めします。このオプションを選択すると、選択したApsaraMQ for KafkaインスタンスでKafka Connectを実行するために必要な内部トピックとコンシューマーグループが作成され、情報がコードエディタの対応するパラメータに同期されます。次のセクションでは、構成項目について説明します。
オフセットトピック: オフセットデータを格納するために使用されるトピック。トピックの名前は
connect-eb-offset-<タスク名>形式です。構成トピック: コネクタとタスクの構成データを格納するために使用されるトピック。トピックの名前は
connect-eb-config-<タスク名>形式です。ステータストピック: コネクタとタスクのステータスデータを格納するために使用されるトピック。トピックの名前は
connect-eb-status-<タスク名>形式です。Kafka Connectコンシューマーグループ: Kafka Connectワーカーが内部トピックのメッセージを消費するために使用するコンシューマーグループ。コンシューマーグループの名前は
connect-eb-cluster-<タスク名>形式です。Kafkaソースコネクタコンシューマーグループ: ソーストピックのデータを消費するために使用されるコンシューマーグループ。このコンシューマーグループは、シンクコネクタに対してのみ有効です。コンシューマーグループの名前は
connector-eb-cluster-<タスク名>-<コネクタ名>形式です。
[実行構成] セクションで、[ログ配信] パラメータを [log Serviceにデータを送信] または [apsaramq For Kafkaにデータを送信] に設定し、[ロール] ドロップダウンリストからKafka Connectが依存するロールを選択し、[ロール認証] サブセクションで [保存] をクリックします。
重要AliyunSAEFullAccess権限ポリシーがアタッチされているロールを選択することをお勧めします。そうでない場合、タスクが実行に失敗する可能性があります。
タスクプロパティ
タスクの再試行ポリシーとデッドレターキューを設定します。詳細については、「再試行ポリシーとデッドレターキュー」をご参照ください。
タスクのステータスが [実行中] になると、コネクタは想定どおりに動作を開始します。
ステップ 3: コネクターをテストする
ソースコネクター
DMS コンソールで、ステップ 1: テーブルを作成するで作成したデータテーブルにデータレコードを挿入します。id が 12、number が 20 のデータレコードを挿入する方法の例を、次のサンプルコマンドに示します。
INSERT INTO sql_table(id, number) VALUES(12,20);ApsaraMQ for Kafka コンソール にログオンします。[インスタンス] ページで、管理するインスタンスをクリックします。
[インスタンスの詳細] ページの左側のナビゲーションペインで、[トピック] をクリックします。表示されるページで、管理するトピックをクリックします。次に、[メッセージクエリ] タブをクリックして、挿入されたメッセージデータを表示します。メッセージ値の例を、次のサンプルコードに示します。
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"number"}],"optional":false,"name":"sql_table"},"payload":{"id":12,"number":20}}
シンクコネクター
ApsaraMQ for Kafka コンソール にログオンします。[インスタンス] ページで、管理するインスタンスをクリックします。
[インスタンスの詳細] ページの左側のナビゲーションペインで、[トピック] をクリックします。表示されるページで、管理するトピックの名前をクリックします。
[トピックの詳細] ページの右上隅にある [メッセージの送信] をクリックします。
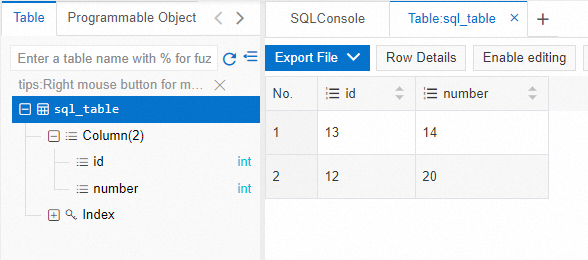
[メッセージの送受信を開始] パネルで、メッセージの内容を指定します。たとえば、id が 13、number が 14 のデータレコードを追加する場合、次のメッセージの内容を入力します。
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"number"}],"optional":false,"name":"sql_table"},"payload":{"id":13,"number":14}}DMS コンソールで、データがデスティネーションテーブルに書き込まれているかどうかを確認します。
一般的なエラーとトラブルシューティング
エラー 1:すべてのタスクが実行に失敗する
エラーメッセージ:
All tasks under connector mongo-source failed, please check the error trace of the task.解決策:メッセージ入力タスクの詳細ページで、[基本情報] セクションの [診断] をクリックして、コネクタ監視ページに移動します。 コネクタ監視ページで、タスクの失敗の詳細を確認できます。
エラー 2:Kafka Connect が予期せず終了する
エラーメッセージ:
Kafka connect exited! Please check the error log /opt/kafka/logs/connect.log on sae application to find out the reason why kafka connect exited and update the event streaming with valid arguments to solve it.解決策:Kafka Connect のステータス更新が遅延している可能性があります。 ページを更新することをお勧めします。 Kafka Connect がまだ失敗する場合は、次の操作を実行して問題をトラブルシューティングできます。
メッセージ入力タスクの詳細ページの [ワーカー情報] セクションで、[SAE アプリケーション] の右側のインスタンス名をクリックして、アプリケーション詳細ページに移動します。
[基本情報] ページで、[インスタンスデプロイ情報] タブをクリックします。
[アクション] 列の [webshell] をクリックして、Kafka Connect の実行環境にログオンします。

vi /home/admin/connector-bootstrap.logコマンドを実行して、コネクタの起動ログを表示し、ログにエラーメッセージが存在するかどうかを確認します。vi /opt/kafka/logs/connect.logコマンドを実行して、コネクタの実行ログを表示し、ERROR または WARN フィールドにエラーメッセージが存在するかどうかを確認します。
エラーメッセージに基づいて問題をトラブルシューティングした後、対応するタスクを再起動できます。
エラー 3:コネクタパラメータの検証が失敗する
エラーメッセージ:
Start or update connector xxx failed. Error code=400. Error message=Connector configuration is invalid and contains the following 1 error(s):
Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery
You can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`解決策:エラーメッセージに基づいて値が無効なパラメータを見つけ、パラメータを更新します。 エラーメッセージに基づいてパラメータが見つからない場合は、Kafka Connect の実行環境にログオンし、次のコマンドを実行できます。 Kafka Connect の実行環境へのログオン方法については、このトピックのエラー 2 を参照してください。
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" -d @$CONNECTOR_PROPERTIES_MAPPING http://localhost:8083/connector-plugins/io.confluent.connect.jdbc.JdbcSinkConnector/config/validate各コネクタパラメータの検証結果は、レスポンスで返されます。 パラメータの値が無効な場合、パラメータの errors フィールドは空ではありません。
"value":{
"name":"snapshot.mode",
"value":null,
"recommended_values":[
"never",
"initial_only",
"when_needed",
"initial",
"schema_only",
"schema_only_recovery"
],
"errors":[
"Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery"
],
"visible":true
}