AnalyticDB for PostgreSQL は、クエリパフォーマンスを向上させるために、複合ソートとインターリーブソートという 2 つのソートメソッドをサポートしています。ほとんどのワークロードでは、複合ソートを使用します。クエリがソートキーの先頭以外の列に対してほぼ等しい頻度でフィルターをかける場合にのみ、インターリーブソートに切り替えてください。
ソートの仕組み
テーブルを作成する際に、1 つ以上の列をソートキーとして指定します。データがロードされた後、ソートキーでテーブルをソートします。AnalyticDB for PostgreSQL は、すべてのディスクブロック内の各列の最小値と最大値を記録し、ラフ集合インデックスを形成します。テーブルスキャン中、クエリエンジンはフィルター値を最小/最大範囲と比較し、その範囲外にあるディスクブロックをスキップします。
例: あるテーブルに、日付でソートされた 7 年分のデータが格納されているとします。1 か月分のデータを検索するクエリでは、データの 1/(7 × 12) のみをスキャンする必要があります。つまり、ディスクブロックの 98.8% がスキップされます。ソートがない場合、クエリはすべてのディスクブロックをスキャンします。
ソートキーの選択
固定された列セットに対する等価フィルターと範囲フィルターの場合、複合ソートを使用します。複合ソートはソートキーを順序付けられたプレフィックスとして扱います。つまり、フィルター条件がソートキーの先頭列と一致する場合に、クエリエンジンは最も効果的です。これは、ほとんどのクエリにとって適切な選択肢です。
異なる先頭以外の列にまたがるフィルターの場合、インターリーブソートを使用します。インターリーブソートはソートキーの各列に等しい重みを割り当てるため、クエリエンジンはフィルターにどの列が現れるかに関係なくブロックをスキップできます。トレードオフとして、インターリーブソートはデータの追加分析が必要であり、一般的に複合ソートよりも低速です。
インターリーブソートキーには最大 8 列まで含めることができます。
JOIN 列の場合、JOIN 列を分散キーとソートキーの両方として設定します。これにより、クエリオプティマイザーはハッシュ結合の代わりにマージ結合を選択できます。データはすでに結合キーでソートされているため、オプティマイザーはマージ結合のソートフェーズを完全にスキップします。
複合ソートとインターリーブソートのパフォーマンス比較
以下のベンチマークでは、同一のデータを持つ 2 つの列指向追記専用テーブルを使用します。1 つは test (SORT でソート) で、もう 1 つは test_multi (MULTISORT でソート) です。両方のテーブルのソートキーは (id, num1, num2) です。
セットアップ
-
両方のテーブルを作成します:
CREATE TABLE test(id int, num1 int, num2 int, value varchar) WITH (APPENDONLY=TRUE, ORIENTATION=column) DISTRIBUTED BY (id) ORDER BY (id, num1, num2); CREATE TABLE test_multi(id int, num1 int, num2 int, value varchar) WITH (APPENDONLY=TRUE, ORIENTATION=column) DISTRIBUTED BY (id) ORDER BY (id, num1, num2); -
各テーブルに 1,000 万行を挿入します:
INSERT INTO test(id, num1, num2, value) SELECT g, (random() * 10000000)::int, (random() * 10000000)::int, (ARRAY['foo', 'bar', 'baz', 'quux', 'boy', 'girl', 'mouse', 'child', 'phone'])[floor(random() * 10 + 1)] FROM generate_series(1, 10000000) AS g; INSERT INTO test_multi SELECT * FROM test; -
対応するメソッドを使用して各テーブルをソートします:
SORT test; -- 複合ソート MULTISORT test_multi; -- インターリーブソート
等価クエリの結果
3 つのクエリが、ソートキー列の異なる組み合わせでフィルターをかけます:
-
Q1 — 先頭列のみ:
WHERE id = 100000 -
Q2 — 2 番目の列のみ:
WHERE num1 = 8766963 -
Q3 — 2 番目と 3 番目の列:
WHERE num1 = 100000 AND num2 = 2904114
| ソートメソッド | Q1 | Q2 | Q3 |
|---|---|---|---|
| 複合ソート | 0.026 s | 3.95 s | 4.21 s |
| インターリーブソート | 0.55 s | 0.42 s | 0.071 s |
範囲クエリの結果
同じ列の組み合わせで、範囲述語を使用します:
-
Q1 — 先頭列:
WHERE id > 5000 AND id < 100000 -
Q2 — 2 番目の列:
WHERE num1 > 5000 AND num1 < 100000 -
Q3 — 2 番目と 3 番目の列:
WHERE num1 > 5000 AND num1 < 100000 AND num2 < 100000
| ソートメソッド | Q1 | Q2 | Q3 |
|---|---|---|---|
| 複合ソート | 0.07 s | 3.35 s | 3.64 s |
| インターリーブソート | 0.44 s | 0.28 s | 0.047 s |
結論
-
Q1 (先頭列フィルター): 複合ソートの方が高速です。フィルターがソートキーの先頭列と一致する場合、クエリエンジンはインターリーブソートが必要とする追加の分析なしで効率的にブロックをスキップします。
-
Q2 (先頭以外の列フィルター): インターリーブソートは、プレフィックスだけでなく各列に独立した最小/最大範囲を割り当てるため、複合ソートよりもパフォーマンスが優れています。
-
Q3 (複数の先頭以外の列): インターリーブソートが大幅に高速です。フィルターに含まれる先頭以外の列が多いほど、その利点は大きくなります。各追加列がブロックスキャンの範囲を狭めるのに貢献するためです。
ソートアクセラレーション
SORT <tablename> を実行すると、AnalyticDB for PostgreSQL はソートを意識したオペレーター (SORT、AGG、JOIN) をストレージレイヤーにプッシュダウンします。データの物理的なソート順と一致するクエリは、すでに順序付けられたブロックに対して実行されるため、オンザフライのソートが不要になります。
-
ソートアクセラレーションは、テーブル内のすべてのデータが順序付けられている必要があります。新しいデータを書き込んだ後、再度
SORT <tablename>を実行してください。 -
ソートアクセラレーションはデフォルトで有効になっています。
以下の例では、far という名前のテストテーブルで、ソートアクセラレーションの適用前後のクエリ時間を比較します。
セットアップ
-
farテーブルを作成します:CREATE TABLE far(a int, b int) WITH (APPENDONLY=TRUE, COMPRESSTYPE=ZSTD, COMPRESSLEVEL=5) DISTRIBUTED BY (a) -- 分散キー ORDER BY (a); -- ソートキー -
100 万行を挿入します:
INSERT INTO far VALUES (generate_series(0, 1000000), 1); -
テーブルをソートします:
SORT far;
クエリパフォーマンスの比較
以下のクエリ時間は参考用です。実際の時間は、データ量、コンピューティングリソース、ネットワーク状態によって異なります。
ORDER BY
-
ソートアクセラレーション適用前:
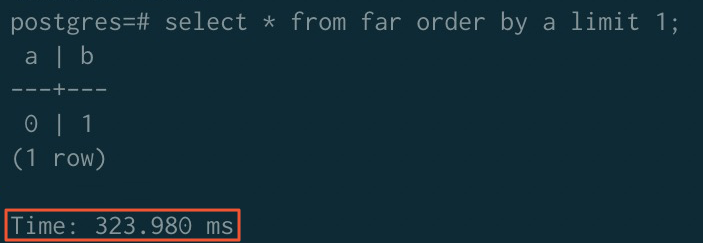
-
ソートアクセラレーション適用後:
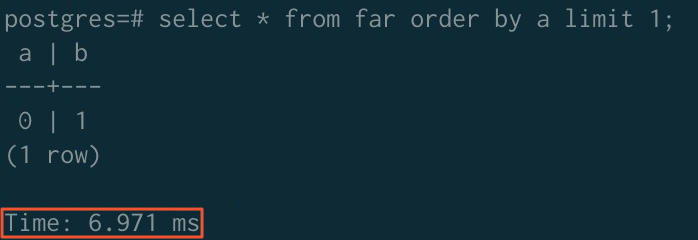
GROUP BY
-
ソートアクセラレーション適用前:
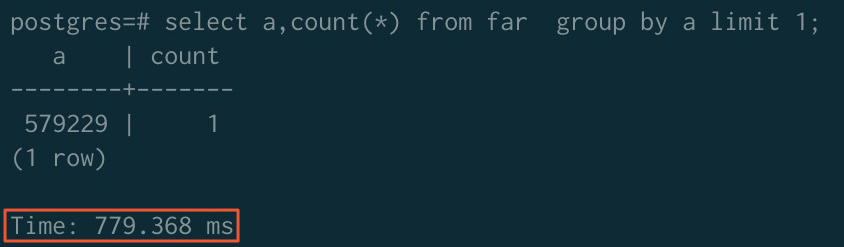
-
ソートアクセラレーション適用後:
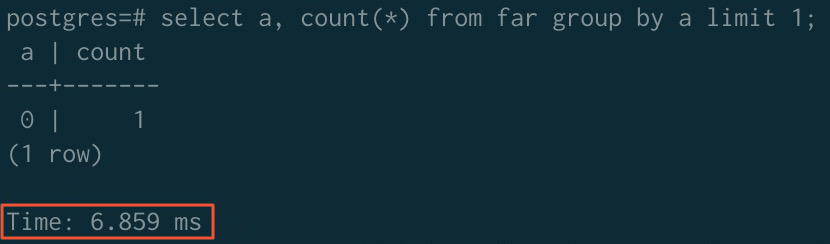
JOIN
-
ソートアクセラレーション適用前:
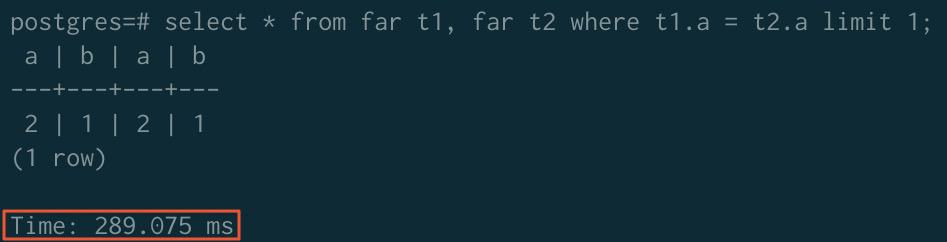
-
ソートアクセラレーション適用後:
説明JOIN オペレーターでソートアクセラレーションを使用するには、ORCA オプティマイザーを無効にし、マージ結合アルゴリズムを有効にします:
SET enable_mergejoin TO on; SET optimizer TO off;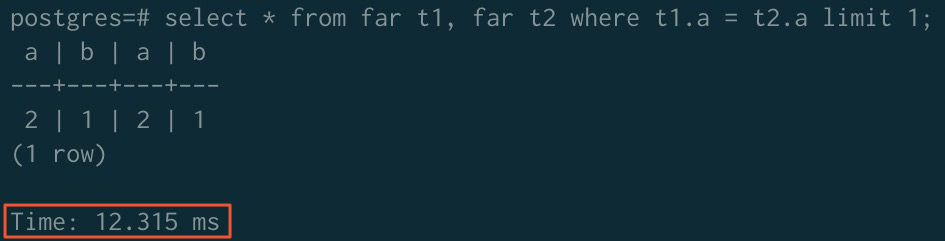
まとめ
| ORDER BY | GROUP BY | JOIN | |
|---|---|---|---|
| アクセラレーション適用前 | 323.980 ms | 779.368 ms | 289.075 ms |
| アクセラレーション適用後 | 6.971 ms | 6.859 ms | 12.315 ms |