AnalyticDB for PostgreSQL は、外部データラッパー (FDW) を使用して、同じ Alibaba Cloud アカウント内のインスタンス間でデータをクエリします。これにより、データの重複や鮮度の低下を防ぎます。
組織が複数の AnalyticDB for PostgreSQL インスタンスを運用して個別の業務部門をサポートしている場合、それら全体で統合されたビューを取得することは困難です。インスタンス間でデータをコピーすると、不整合や冗長性が発生します。Object Storage Service (OSS) を介してデータを共有すると、鮮度が遅延します。Massively Parallel Processing (MPP) アーキテクチャ上に構築された FDW は、コンピューティングノード間の直接的な相互通信を使用してリモートデータに並行してアクセスすることで、この問題を解決し、ネイティブの postgres_fdw 拡張機能よりも数倍高いパフォーマンスを実現します。
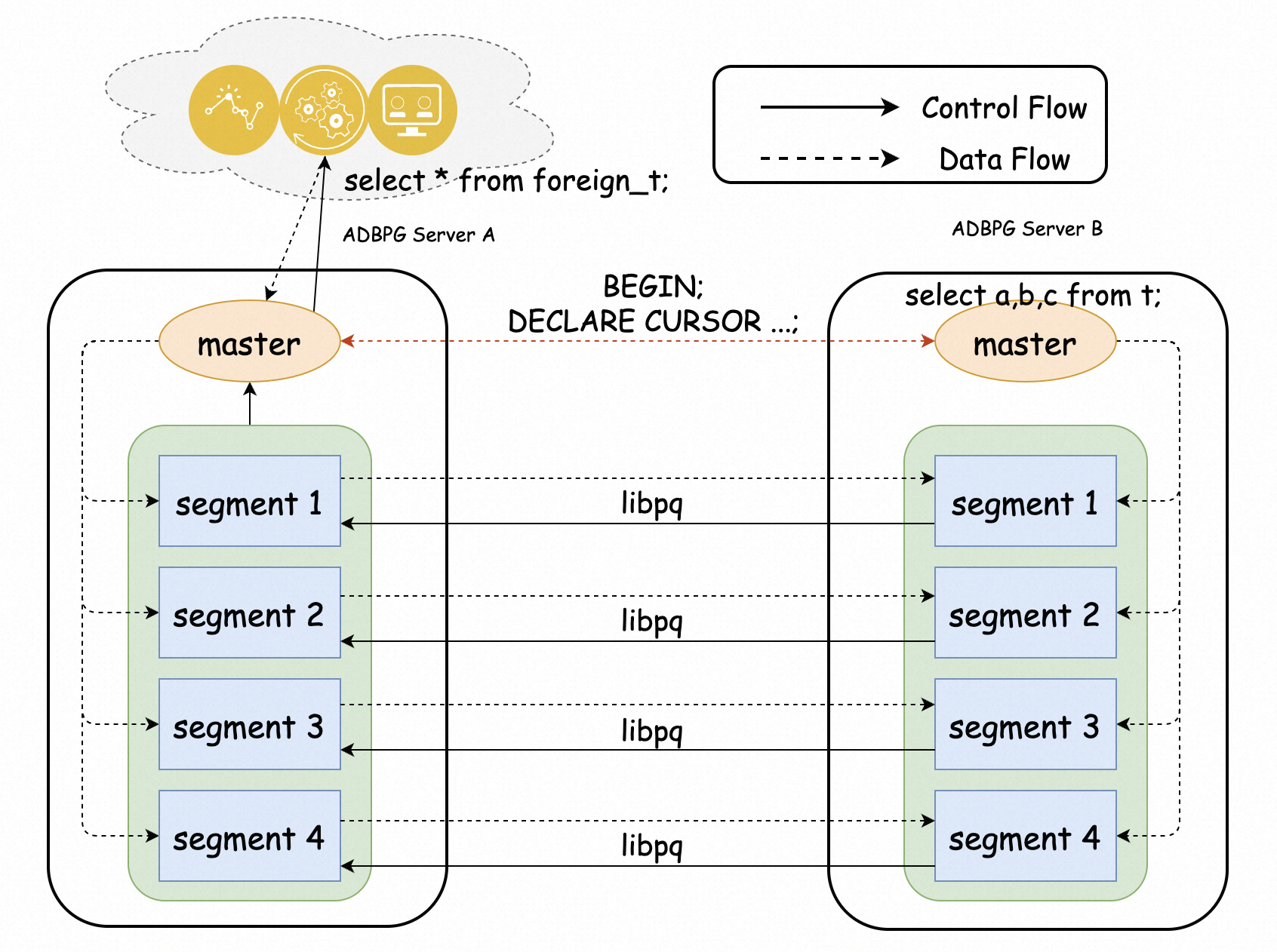
仕組み
FDW は、リモートインスタンス上のテーブルをローカルインスタンス上の外部テーブルとして公開します。クエリはローカルインスタンスで実行され、FDW は並列コンピューティングノード接続を使用して、リモートインスタンスから必要なデータのみをフェッチします。エラスティックストレージモードの AnalyticDB for PostgreSQL V7.0 では、Orca オプティマイザーが結合と集計をリモートインスタンスにプッシュダウンできるため、ネットワーク経由で転送されるデータ量を削減できます。
制限事項
| 制限 | 詳細 |
|---|---|
| アカウントとネットワーク | ソースインスタンスと宛先インスタンスは、同じ Alibaba Cloud アカウントに属し、同じリージョンおよび VPC に存在する必要があります。 |
| サポートされる DML | 外部テーブルは SELECT と INSERT のみをサポートします。UPDATE と DELETE はサポートされていません。 |
| Serverless スケーリング | Serverless モードのインスタンスがスケーリング状態の場合、そのデータにはアクセスできません。 |
| 結合と集計のプッシュダウン | エラスティックストレージモードの V7.0 でのみサポートされます。 |
| 実行計画オプティマイザー | V7.0 (エラスティックストレージモード) は Orca オプティマイザーを使用します。V6.0 (エラスティックストレージモード) と Serverless モードはネイティブオプティマイザーを使用します。 |
| クロスバージョンアクセス | V7.0 は異なるパスワード検証方法を使用します。V6.0 または Serverless モードのインスタンスから V7.0 インスタンスにアクセスするには、チケットを起票してください。 |
サポートされるバージョン
| デプロイメントモード | 最小バージョン |
|---|---|
| エラスティックストレージモードの V7.0 | V7.0.1.x |
| エラスティックストレージモードの V6.0 | V6.3.11.2 |
| Serverless モード | V1.0.6.x |
前提条件
開始する前に、以下があることを確認してください。
同じ Alibaba Cloud アカウント、リージョン、および VPC 内にある 2 つの AnalyticDB for PostgreSQL インスタンス
psqlクライアントがインストールされ、構成されていることソースインスタンスに対する読み取り権限を持つデータベースアカウント (INSERT 操作には書き込み権限も必要です)
インスタンス間クエリのセットアップ
次の手順では、インスタンス A (クエリインスタンス) とインスタンス B (データソース) の間でインスタンス間クエリを構成します。セットアップ後、インスタンス A の db01 データベースで実行されるクエリは、インスタンス B の db02 データベースからテーブルを読み取ることができます。
ステップ 1: 両方のインスタンスに接続する
psql を使用してインスタンス A とインスタンス B に接続します。詳細については、「クライアント接続」をご参照ください。
ステップ 2: データベースを作成する
各インスタンスにデータベースを作成し、それに切り替えます。
インスタンス A で:
CREATE DATABASE db01;
\c db01インスタンス B で:
CREATE DATABASE db02;
\c db02ステップ 3: 必要な拡張機能をインストールする
インスタンス A の db01 データベースとインスタンス B の db02 データベースの両方のインスタンスに、greenplum_fdw および gp_parallel_retrieve_cursor 拡張機能をインストールします。インスタンス間クエリが機能するには、両方のインスタンスに同じ拡張機能がインストールされている必要があります。詳細については、「拡張機能のインストール、更新、アンインストール」をご参照ください。
ステップ 4: インスタンス A の IP アドレスをインスタンス B のホワイトリストに追加する
インスタンス A で次のステートメントを実行して、その内部 IP アドレスを取得します。
SELECT dbid, address FROM gp_segment_configuration;返された IP アドレスをインスタンス B のホワイトリストに追加します。詳細については、「IP アドレスホワイトリストの構成」をご参照ください。
ステップ 5: インスタンス B でテストデータを準備する
インスタンス B の db02 データベースで次のステートメントを実行します。
CREATE SCHEMA s01;
CREATE TABLE s01.t1(a int, b int, c text);
CREATE TABLE s01.t2(a int, b int, c text);
CREATE TABLE s01.t3(a int, b int, c text);
INSERT INTO s01.t1 VALUES(generate_series(1,10),generate_series(11,20),'t1');
INSERT INTO s01.t2 VALUES(generate_series(11,20),generate_series(11,20),'t2');
INSERT INTO s01.t3 VALUES(generate_series(21,30),generate_series(11,20),'t3');ステップ 6: インスタンス A でサーバーとユーザーマッピングを作成する
インスタンス A の db01 データベースで次のステートメントを実行します。
サーバーを作成する — インスタンス B への接続を定義します。
CREATE SERVER remote_adbpg FOREIGN DATA WRAPPER greenplum_fdw
OPTIONS (host 'gp-xxxxxxxx-master.gpdb.zhangbei.rds.aliyuncs.com',
port '5432',
dbname 'db02');| パラメーター | 説明 |
|---|---|
host | インスタンス B の内部エンドポイントです。AnalyticDB for PostgreSQL コンソールのインスタンス B の 基本情報 ページで、データベース接続情報 > 内部エンドポイント に表示されます。AnalyticDB for PostgreSQL コンソール |
port | インスタンス B の内部ポートです。デフォルト値: 5432。 |
dbname | ソースデータベースの名前です。本例では:db02。 |
ユーザーマッピングを作成する — インスタンス B へのアクセスに使用される認証情報を設定します。完全な構文については、「CREATE USER MAPPING」をご参照ください。
CREATE USER MAPPING FOR PUBLIC SERVER remote_adbpg
OPTIONS (user 'report', password '******');| パラメーター | 説明 |
|---|---|
user | インスタンス B のデータベースアカウントです。このアカウントは db02 への読み取りアクセス権を持っている必要があります。INSERT 操作には書き込みアクセス権も必要です。詳細については、「データベースアカウントの作成」をご参照ください。 |
password | データベースアカウントのパスワードです。 |
ステップ 7: 外部テーブルをインポートする
インスタンス B のテーブルをインスタンス A で公開するには、次のいずれかのメソッドを選択します。
| メソッド | 使用するタイミング |
|---|---|
| CREATE FOREIGN TABLE | 特定のテーブルをインポートします。公開する列をカスタマイズします。 |
| IMPORT FOREIGN SCHEMA | スキーマからすべてのテーブルを迅速にインポートします。列名と型はソースと完全に一致する必要があります。 |
オプション 1: CREATE FOREIGN TABLE — カスタム列選択で個々のテーブルをインポートする
CREATE SCHEMA s01;
CREATE FOREIGN TABLE s01.t1(a int, b int)
server remote_adbpg options(schema_name 's01', table_name 't1');これにより、列のサブセットのみを公開できます。上記の例では、インスタンス B の t1 には 3 つの列 (a、b、c) がありますが、a と b のみがインポートされます。各テーブルには個別の DDL ステートメントが必要です。
オプション 2: IMPORT FOREIGN SCHEMA — スキーマからすべてのテーブルを一度にインポートする
CREATE SCHEMA s01;
IMPORT FOREIGN SCHEMA s01 LIMIT TO (t1, t2, t3)
FROM SERVER remote_adbpg INTO s01;これにより、各テーブルの DDL を記述することなく、複数のテーブルを 1 つのステートメントでインポートできます。外部テーブルの列はソーステーブルと完全に一致する必要があります。完全な構文については、「IMPORT FOREIGN SCHEMA」をご参照ください。
ステップ 8: リモートデータをクエリする
インスタンス A でクエリを実行して、インスタンス B からデータを読み取ります。
SELECT * FROM s01.t1;期待される出力:
a | b | c
----+----+----
2 | 12 | t1
3 | 13 | t1
4 | 14 | t1
7 | 17 | t1
8 | 18 | t1
1 | 11 | t1
5 | 15 | t1
6 | 16 | t1
9 | 19 | t1
10 | 20 | t1
(10 rows)パフォーマンスに関する考慮事項
次の図は、1 TB のデータセットにおけるローカルクエリとインスタンス間クエリを比較した TPC-H ベンチマーク結果を示しています。
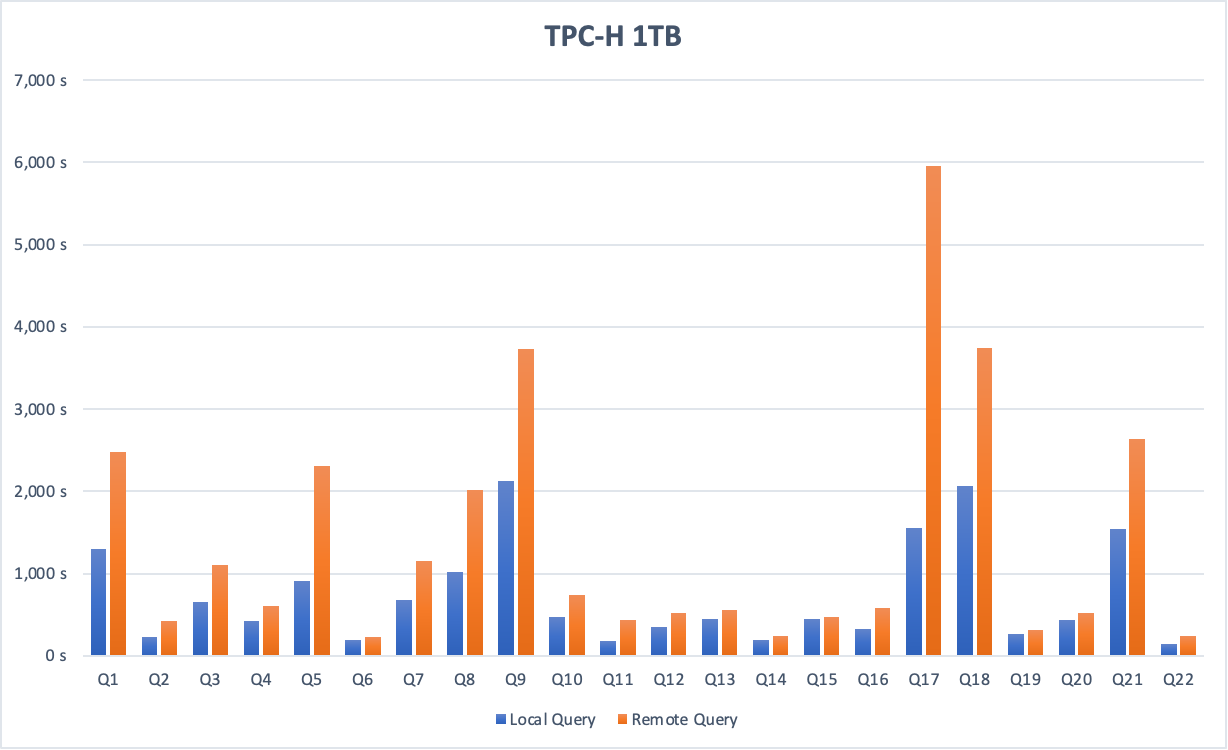
1 TB のデータセットでは、データがネットワーク経由で転送される必要があるため、インスタンス間クエリのパフォーマンスは同等のローカルクエリの約半分になります。
ネットワーク I/O を削減するには:
外部テーブルに WHERE 句フィルターを追加します。FDW はデータが転送される前にフィルター条件をリモートインスタンスにプッシュするため、一致する行のみがネットワーク経由で転送されます。
結合と集計のプッシュダウンには、エラスティックストレージモードの V7.0 を使用します。Orca オプティマイザーは結合と集計全体をリモートインスタンスにプッシュできるため、転送されるデータ量を大幅に削減できます。
次のステップ
AnalyticDB for PostgreSQL は、同じインスタンス内のクロスデータベースクエリもサポートしています。詳細については、「データベース間クエリ」をご参照ください。