ベクトルインデックスを作成して、ベクトル検索を高速化できます。これは、大規模なデータセットや、高速なデータアクセスと取得を必要とするシナリオで役立ちます。一般的なユースケースには、データベースクエリの最適化、機械学習、データマイニング、画像およびビデオの取得、空間データクエリなどがあります。ベクトルインデックスは、クエリのパフォーマンスを向上させ、データ分析を高速化し、検索タスクを最適化します。これにより、システムの効率と応答速度が向上します。
背景情報
クラウドネイティブのデータウェアハウス AnalyticDB for PostgreSQL の FastANN ベクトル検索エンジンは、一般的な階層的航行可能小世界 (HNSW) アルゴリズムを実装しています。このエンジンは、PostgreSQL のセグメント化されたページストレージ上に構築されています。インデックスにはベクトル列へのポインターのみを格納するため、ストレージスペースが大幅に削減されます。FastANN ベクトル検索エンジンは、高次元ベクトルの次元を削減するためのプロダクト量子化 (PQ) もサポートしています。これらの削減された次元のベクトルをインデックスに格納することで、ベクトルの挿入およびクエリ中のテーブルルックアップが最小限に抑えられます。これにより、ベクトル検索のパフォーマンスが向上します。
構文
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
DISTANCEMEASURE=<MEASURE>,
HNSW_M=<M>,
HNSW_EF_CONSTRUCTION=<EF_CONSTURCTION>,
PQ_ENABLE=<PQ_ENABLE>,
PQ_SEGMENTS=<PQ_SEGMENTS>,
PQ_CENTERS=<PQ_CENTERS>,
EXTERNAL_STORAGE=<EXTERNAL_STORAGE>);次の表に、フィールドの説明を示します。
INDEX_NAME: インデックス名。
SCHEMA_NAME: スキーマ (名前空間) 名。
TABLE_NAME: テーブル名。
COLUMN_NAME: ベクトルインデックス列名。
その他のベクトルインデックスパラメーター:
ベクトルインデックスパラメーター
必須
説明
デフォルト値
有効値
DIM
はい
ベクトルのディメンション。このパラメーターは、ベクトル挿入時のチェックに使用されます。ディメンションが一致しない場合、システムはエラーメッセージを返します。
0
[1, 8192]
DISTANCEMEASURE
いいえ
サポートされている類似性距離メジャー:
L2: ユークリッド距離の二乗関数を使用してインデックスを構築します。これは通常、画像の類似検索シナリオで使用されます。
式:
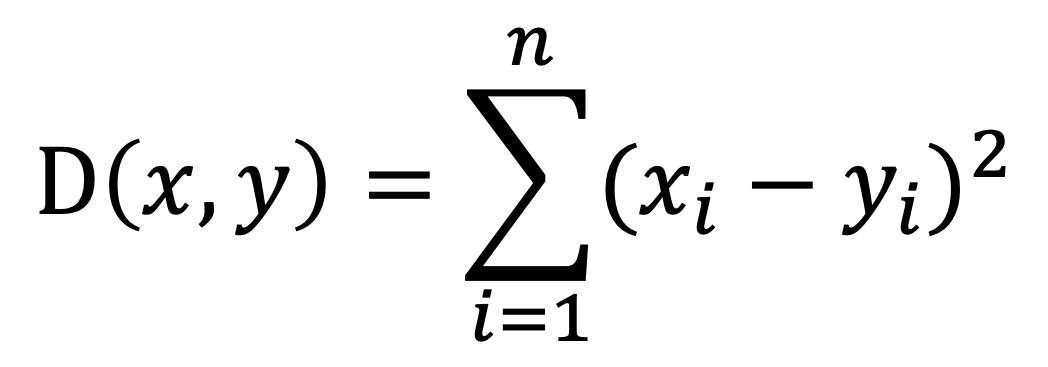
IP: 負の内積距離関数を使用してインデックスを構築します。これは通常、ベクトル正規化後のコサイン類似性の代替として使用されます。
式:
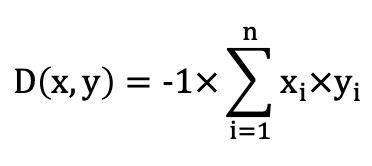
COSINE: コサイン距離関数を使用してインデックスを構築します。これは通常、テキストの類似検索シナリオで使用されます。
式:

説明IP と COSINE には、6.3.10.18 以降のエンジンバージョンが必要です。これらを使用する前に、エンジンバージョンがこの要件を満たしていることを確認してください。エンジンバージョンを表示およびアップグレードするには、詳細については、「バージョンをアップグレードする」をご参照ください。
インポートする前にベクトルデータを正規化します。次に、インデックスの類似性メジャーとして IP 距離を使用して、最適なパフォーマンスを実現します。
インデックスの類似性メジャーとして IP 距離を使用する場合、クエリ中にユークリッド距離とコサイン類似性を直接取得することもできます。この機能の使用方法の詳細については、「ベクトル検索」をご参照ください。
ベクトル検索のユーザー定義関数 (UDF) の詳細については、「関連リファレンス」をご参照ください。
L2
(L2, IP, COSINE)
HNSW_M
いいえ
HNSW アルゴリズムの近傍の最大数。
32
[10, 1000]
HNSW_EF_CONSTRUCTION
いいえ
HNSW アルゴリズムのインデックス構築中の候補セットのサイズ。
600
[40, 4000]
PQ_ENABLE
いいえ
PQ ベクトル次元削減機能を有効にするかどうかを指定します。PQ ベクトル次元削減は、既存のベクトルサンプルデータでのトレーニングに依存します。データ量が 500,000 未満の場合は、このパラメーターを設定しないでください。
0
[0, 1]
PQ_SEGMENTS
いいえ
このパラメーターは、PQ_ENABLE が 1 に設定されている場合に有効になります。PQ ベクトル次元削減に使用される k-means クラスタリングアルゴリズムのセグメント数を指定します。
DIM が 8 で割り切れる場合は、このパラメーターを指定する必要はありません。それ以外の場合は、手動で設定する必要があります。
PQ_SEGMENTS は 0 より大きく、DIM は PQ_SEGMENTS で割り切れる必要があります。
0
[1, 256]
PQ_CENTERS
いいえ
このパラメーターは、PQ_ENABLE が 1 に設定されている場合に有効になります。PQ ベクトル次元削減に使用される k-means クラスタリングアルゴリズムの重心の数を指定します。
2048
[256, 8192]
EXTERNAL_STORAGE
いいえ
mmap を使用して HNSW インデックスを構築するかどうかを指定します。
0 に設定すると、インデックスはデフォルトでセグメント化されたページストレージを使用して構築されます。このモードでは、PostgreSQL の shared_buffer をキャッシュに使用でき、delete や update などの操作をサポートします。
1 に設定すると、インデックスは mmap を使用して構築されます。バージョン v6.6.2.3 以降、インデックスは mark-for-delete をサポートし、データテーブルに対する少数の delete および update 操作を許可します。
重要external_storage パラメーターはバージョン 6.0 でのみサポートされています。バージョン 7.0 ではサポートされていません。
0
[0, 1]
例
テキストナレッジベースがあるとします。記事をチャンクに分割し、埋め込みベクトルに変換して、データベースに格納できます。生成された `chunks` テーブルには、次のフィールドが含まれています。
フィールド | タイプ | 説明 |
id | serial | ID。 |
chunk | varchar(1024) | 記事が分割された後のテキストチャンク。 |
intime | timestamp | 記事がデータベースにインポートされた時間。 |
url | varchar(1024) | テキストチャンクが属する記事へのリンク。 |
feature | real[] | テキストチャンクの埋め込みベクトル。 |
ベクトルを格納するデータベーステーブルを作成します。
CREATE TABLE chunks ( id SERIAL PRIMARY KEY, chunk VARCHAR(1024), intime TIMESTAMP, url VARCHAR(1024), feature REAL[] ) DISTRIBUTED BY (id);ベクトル列のストレージモードを PLAIN に設定して、行スキャンコストを削減し、パフォーマンスを向上させます。
ALTER TABLE chunks ALTER COLUMN feature SET STORAGE PLAIN;ベクトル列にベクトルインデックスを作成します。
-- ユークリッド距離メジャーを使用するベクトルインデックスを作成します。 CREATE INDEX idx_chunks_feature_l2 ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=l2, hnsw_m=64, pq_enable=1); -- 内積距離メジャーを使用するベクトルインデックスを作成します。 CREATE INDEX idx_chunks_feature_ip ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=ip, hnsw_m=64, pq_enable=1); -- コサイン類似性メジャーを使用するベクトルインデックスを作成します。 CREATE INDEX idx_chunks_feature_cosine ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);説明現在、ベクトルテーブルに複数のベクトル列を作成し、各ベクトル列に複数のベクトルインデックスを作成できます。無効なインデックスを作成しないように、必要に応じてのみベクトルインデックスを作成してください。
ベクトルクエリメソッドは、ベクトルインデックスの距離メジャーに対応している必要があります。たとえば、ベクトルクエリの
<->オペレーターは、ユークリッド距離メジャーを使用するベクトルインデックスに対応します。<#>オペレーターは内積距離インデックスに対応し、<=>オペレーターはコサイン類似性インデックスに対応します。対応するベクトルインデックスが存在しない場合、ベクトルクエリは正確な検索 (力まかせ探索) にダウングレードされます。FastANN ベクトル検索プラグインによって提供される
ANNアクセスメソッドを使用します。インスタンスの [ベクトル検索エンジンの最適化] 機能を有効にすると、そのインスタンスに FastANN ベクトル検索プラグインが自動的に作成されます。エラーメッセージ
You must specify an operator class or define a default operator class for the data typeが返された場合、インスタンスの [ベクトル検索エンジンの最適化] 機能が有効になっていません。この問題を解決するには、この機能を有効にしてから操作をリトライしてください。詳細については、「ベクトル検索エンジンの最適化を有効または無効にする」をご参照ください。
頻繁に使用される構造化列にインデックスを作成して、ハイブリッドクエリのパフォーマンスを向上させます。
CREATE INDEX ON chunks(intime);
ベクトルインデックスの構築メソッド
ベクトルインデックスは、主に 2 つの方法で構築できます。
ストリーム構築
まず、空のテーブルを作成し、その上にベクトルインデックスを構築します。ベクトルデータをインポートすると、インデックスはストリームとしてリアルタイムに構築されます。このメソッドは、リアルタイムのベクトル検索シナリオに適していますが、データインポートプロセスが遅くなる可能性があります。
非同期構築
まず、空のテーブルを作成し、ベクトルインデックスなしでデータをインポートします。次に、既存のベクトルデータ上にベクトルインデックスを構築できます。このメソッドは、大規模なベクトルデータのインポートシナリオに適しています。
AnalyticDB for PostgreSQL は、非同期ベクトルインデックス構築メソッドの同時構築機能を提供します。`fastann.build_parallel_processes` Grand Unified Configuration (GUC) パラメーターを使用して、インデックス構築の並列処理の次数を設定できます。
たとえば、次のように DMS 上で非同期にインデックスを構築できます。
-- この操作は 8 コア 32 GB のインスタンスタイプで実行されると仮定します。
-- タイムアウトによる中断を防ぐために、statement_timeout と idle_in_transaction_session_timeout を 0 に設定します。
-- 計算ノードの CPU 使用率を最大限に高めるために、fastann.build_parallel_processes を 8 に設定します。この値はセグメントの仕様に基づいて設定する必要があります。たとえば、4 コア 16 GB のインスタンスタイプでは 4、8 コア 32 GB のインスタンスタイプでは 8、16 コア 64 GB のインスタンスタイプでは 16 に設定します。
-- DMS では、パラメーター設定が有効になるには、CREATE INDEX SQL 文と同じ行にある必要があります。
SET statement_timeout = 0;SET idle_in_transaction_session_timeout = 0;SET fastann.build_parallel_processes = 8;CREATE INDEX ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);psql を使用して非同期にインデックスを構築するには、次のステップを実行します。
-- 上記の DMS 操作と同じく、8 コア 32 GB のインスタンスで操作が実行されると仮定します。
-- ステップ 1: 次の内容を create_index.sql という名前のファイルに保存します。
SET statement_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET fastann.build_parallel_processes = 8;
CREATE INDEX ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);
-- ステップ 2: 次のコマンドを実行して、インデックスの並列構築を開始します。
psql -h gp-xxxx-master.gpdb.rds.aliyuncs.com -p 5432 -d dbname -U username -f create_index.sql現在のインスタンスがビジネスワークロードを処理している場合は、インデックス構築の並列プロセス数をインスタンスの仕様に合わせて設定しないでください。そうしないと、実行中のビジネスワークロードのパフォーマンスに影響が及ぶ可能性があります。
関連リファレンス
関数の目的 | ベクトル関数 | 戻り値の型 | 意味 | サポートされているデータの型 |
計算 | l2_distance | double precision | ユークリッド距離 (平方根値)。2 つのベクトルの大きさを測定し、それらの間の距離を表します。一般的に画像の類似検索に使用されます。 重要 バージョン V6.3.10.17 以前では、`l2_distance` はユークリッド距離の二乗を返します。バージョン V6.3.10.18 以降では、ユークリッド距離 (平方根値) を返します。 | smallint[], float2[], float4[], real[] |
inner_product_distance | double precision | 内積距離。ベクトル正規化後、コサイン類似性と等しくなります。正規化後のコサイン類似性の代替としてよく使用されます。 式: | smallint[], float2[], float4[], real[] | |
cosine_similarity | double precision | コサイン類似性。値の範囲は [-1, 1] です。通常、実際の長さに関係なく、2 つのベクトル間の方向の類似性を測定するために使用されます。 式: | smallint[], float2[], float4[], real[] | |
dp_distance | double precision | ドット積距離。内積距離と同じです。 式: | smallint[], float2[], float4[], real[] | |
hm_distance | integer | ハミング距離。 式: ビットごとの演算 | int[] | |
vector_add | smallint[], float2[], or float4[] | 2 つのベクトル配列の合計を計算します。 | smallint[], float2[], float4[], real[] | |
vector_sub | smallint[], float2[], or float4[] | 2 つのベクトル配列の差を計算します。 | smallint[], float2[], float4[], real[] | |
vector_mul | smallint[], float2[], or float4[] | 2 つのベクトル配列の積を計算します。 | smallint[], float2[], float4[], real[] | |
vector_div | smallint[], float2[], or float4[] | 2 つのベクトル配列の商を計算します。 | smallint[], float2[], float4[], real[] | |
vector_sum | int or double precision | ベクトル配列のすべての要素の合計を計算します。 | smallint[], int[], float2[], float4[], real[], float8[] | |
vector_min | int or double precision | ベクトル配列内のすべての要素の中から最小値を見つけます。 | smallint[], int[], float2[], float4[], real[], float8[] | |
vector_max | int or double precision | ベクトル配列内のすべての要素の中から最大値を見つけます。 | smallint[], int[], float2[], float4[], real[], float8[] | |
vector_avg | int or double precision | ベクトル配列のすべての要素の平均値を計算します。 | smallint[], int[], float2[], float4[], real[], float8[] | |
vector_norm | double precision | ベクトル配列のノルム (長さ) を計算します。 | smallint[], int[], float2[], float4[], real[], float8[] | |
vector_angle | double precision | 2 つのベクトル配列の間の角度を計算します。 | smallint[], float2[], float4[], real[] | |
並べ替え | l2_squared_distance | double precision | ユークリッド距離の二乗。ユークリッド距離の平方根計算を回避するため、主にユークリッド距離によるソートに使用され、計算負荷を軽減します。 式: | smallint[], float2[], float4[], real[] |
negative_inner_product_distance | double precision | 負の内積距離。これは内積距離の結果を否定したものです。主に内積距離でソートするために使用され、結果が内積距離の降順でソートされることを保証します。 式: | smallint[], float2[], float4[], real[] | |
cosine_distance | double precision | コサイン距離。値の範囲は [0, 2] です。主にコサイン類似性でソートするために使用され、結果がコサイン類似性の降順でソートされることを保証します。 式: | smallint[], float2[], float4[], real[] |
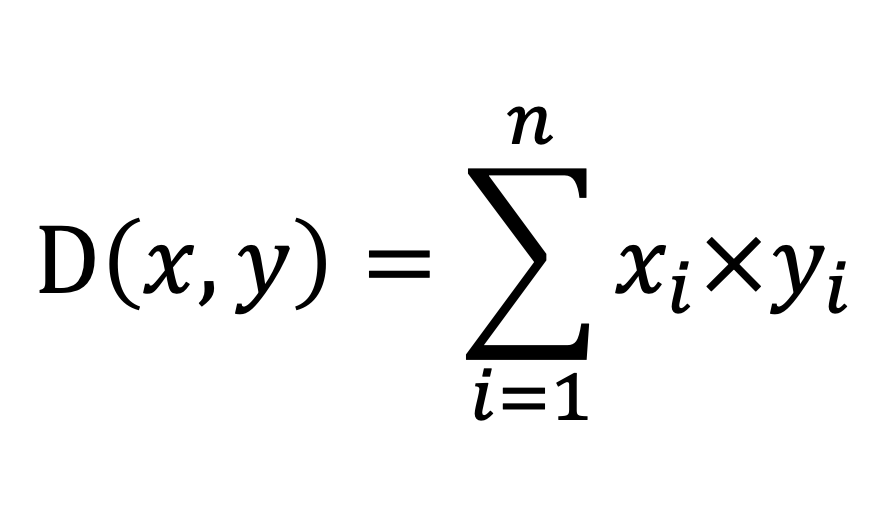

`vector_add`、`vector_sub`、`vector_mul`、`vector_div`、`vector_sum`、`vector_min`、`vector_max`、`vector_avg`、`vector_norm`、および `vector_angle` 関数は、v6.6.1.0 以降のバージョンでのみサポートされています。インスタンスのバージョンを表示するには、詳細については、「マイナーエンジンバージョンを表示する」をご参照ください。
ベクトル関数の例:
-- ユークリッド距離
SELECT l2_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 内積距離
SELECT inner_product_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- コサイン類似性
SELECT cosine_similarity(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ドット積距離
SELECT dp_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ハミング距離
SELECT hm_distance(array[1,0,1,0]::int[], array[0,1,0,1]::int[]);
-- ベクトル配列の加算
SELECT vector_add(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ベクトル配列の減算
SELECT vector_sub(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ベクトル配列の乗算
SELECT vector_mul(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ベクトル配列の除算
SELECT vector_div(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- ベクトル配列要素の合計
SELECT vector_sum(array[1,1,1,1]::real[]);
-- ベクトル配列の最小値
SELECT vector_min(array[1,1,1,1]::real[]);
-- ベクトル配列の最大値
SELECT vector_max(array[1,1,1,1]::real[]);
-- ベクトル配列の平均値
SELECT vector_avg(array[1,1,1,1]::real[]);
-- ベクトル配列のノルム
SELECT vector_norm(array[1,1,1,1]::real[]);
-- 2 つのベクトル間の角度
SELECT vector_angle(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);