AnalyticDB for PostgreSQLを使用すると、ペタバイト単位のデータに対してリアルタイムでインタラクティブな分析、抽出、変換、ロード (ETL) 、抽出、ロード、変換 (ELT) 操作、ビジネスインテリジェンス (BI) レポートの視覚化を実行できます。 また、AnalyticDB for PostgreSQLを使用すると、リアルタイムでデータを書き込み、高いスループットでデータをバッチでインポートでき、原子性、一貫性、分離、耐久性 (ACID) 保証、および標準的なトランザクション分離を提供します。 AnalyticDB for PostgreSQLは、コスト効率の高いクラウドネイティブデータベースウェアハウスであり、MPP (大規模並列処理) アーキテクチャを使用して、Alibaba cloudエコシステムに基づくパブリッククラウドおよびハイブリッドクラウドサービスを提供します。
概要
AnalyticDB for PostgreSQLはJDBCおよびODBC接続をサポートし、SQL:2003構文標準、PostgreSQL、およびGreenplumと完全に互換性があり、Oracle構文と部分的に互換性があります。 AnalyticDB for PostgreSQLは、PL/pgSQLストアドプロシージャを提供します。 AnalyticDB for PostgreSQLは、機械学習用のApache MADLibとSQL標準のジオメトリ分析用のPostGISをサポートしています。 標準SQLを使用して、JSON形式またはJSON-B形式の半構造化データ、画像やオーディオなどの非構造化データ、および構造化データに対してハイブリッド分析を実行できます。
AnalyticDB for PostgreSQLは、さまざまな展開モードをサポートしています。 AnalyticDB for PostgreSQLは、Alibaba Cloudパブリッククラウドサービスを従量課金制で提供し、垂直および水平スケーリングをサポートし、オンラインでストレージ容量を個別にスケールアップできます。 AnalyticDB for PostgreSQLは、DBStackを使用したハイブリッドクラウド展開のためのApsara Stack EnterpriseおよびApsara Stack Agilityも提供します。 AnalyticDB for PostgreSQLは、x86プラットフォームとARMプラットフォームをサポートしています。
AnalyticDB for PostgreSQLは、TPC Benchmark-H (TPC-H) 30テラバイトの費用対効果リストで1位にランクされています。 AnalyticDB for PostgreSQLは、中国情報通信技術アカデミー (CAICT) が主催するTPCベンチマーク-C (TPC-C) トランザクションパフォーマンステストおよびTPCベンチマーク-DS (TPC-DS) 100テラバイト640ノード分析パフォーマンステストに合格します。
アーキテクチャ
AnalyticDB for PostgreSQLのアーキテクチャは、コーディネーターノードとコンピュートノードで構成されています。 ノードは、データ伝送のために相互接続される。 次の図はアーキテクチャを示しています。
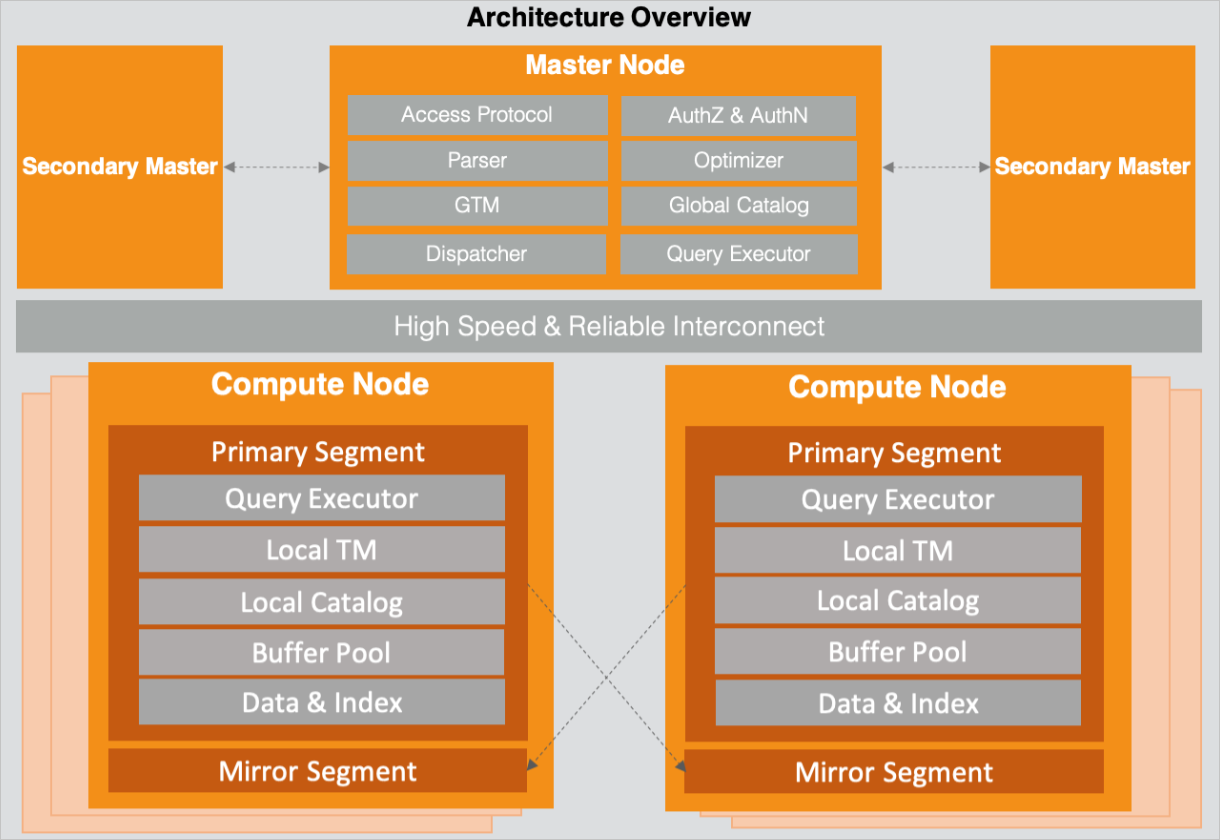
コーディネーターノードとコンピュートノードは複数のレプリカを提供し、サービスの高可用性とデータの高信頼性を保証します。 インスタンスのコーディネーターノードまたは計算ノードをスケールアウトして、読み取りおよび書き込みクエリの同時実行性とスループットを向上させることができます。
モジュール部品
コーディネーターノード
コーディネータノードは、アクセスプロトコルを介してクライアントとの接続を確立し、認証および許可を実行し、パーサ、リライタ、オプティマイザ、およびディスパッチャの役割を引き受ける。
コーディネータ・ノードはまた、グローバル・トランザクション・マネージャ (GTM) の役割を引き受けて、スナップショットおよびグローバル・トランザクションIDを生成し、分散トランザクションを管理する。 コーディネーターノードは、ユーザー、データベース、テーブル、ビュー、インデックス、分散パーティションなどのデータベースオブジェクトのメタデータを記録するグローバルカタログを提供します。
計算ノード
計算ノードは、セグメントのセットからなる。 計算ノードは、物理マシン、仮想マシン (VM) 、またはコンテナとすることができる。
セグメント
セグメントは、特定のSQL実行とデータストレージを担当します。 セグメントのローカルカタログは、ステートメントの実行を高速化するためにコーディネーターノードのグローバルカタログと同期されます。 このように、セグメントは、メタデータを取得するためにコーディネータノードに頻繁にアクセスする必要がない。 セグメントのローカルトランザクションマネージャは、トランザクションを調整するために使用される。 セグメントのバッファプールは、読み書きのパフォーマンスを向上させるために読み書きをキャッシュします。
クエリエグゼキュータは、ベクトル化された実行エンジンとジャストインタイム (JIT) コンパイルを活用して、行ごとに計算を実行する火山モデルと比較して、計算パフォーマンスを複数回改善します。
AnalyticDB for PostgreSQLは、行ストアテーブル、列ストアテーブル、外部テーブル、および対応するインデックスをサポートしています。
行ストアテーブル: データは行単位で格納されます。 行は、主キーによって順序付けすることができる。 Bツリー、ビットマップ、およびGINインデックスがサポートされています。 行ストアテーブルは、ライブデータの書き込み、更新、および削除操作に適しています。 ポイントクエリや範囲クエリにも適しています。 AnalyticDB for PostgreSQLは、マルチバージョン同時実行制御 (MVCC) モデルを使用して、行ストア形式のトランザクションを管理します。
列格納テーブル: データは高圧縮率で列ごとに格納されます。 列ストアは、少量のデータを更新または削除する必要があるシナリオに適しています。 列ストアは、効率的なポイントクエリのためのBツリーインデックスをサポートし、最小値と最大値を使用して軽量ブロック範囲インデックスを提供します。 データは、複数の次元で複数の列にソートできます。 ソートされた列は、効率的な分析のために複合条件に基づいてフィルタできます。
外部テーブル: 外部テーブルを使用して、ローカルシステムテーブルに保存されているメタデータと、OSS (Object Storage Service) に保存されているデータを照会できます。 外部テーブルはパーティション分割でき、ORC、Parquet、CSV、JSONなどのさまざまなデータ形式をサポートできます。 ORCおよびParquetsデータファイルは、列フィルタリングと述語プッシュダウンをサポートし、分析パフォーマンスを向上させます。 外部テーブルは、Hadoop分散ファイルシステム (HDFS) およびApache Hiveからのデータをクエリすることもできます。

データモデル
理想的には、表データはノード間に均等に分散されます。 データ分散でも、インスタンスのI/Oパフォーマンスを最大限に活用し、ストレージ容量を向上させ、コンピューティングとネットワーク伝送の効率を最適化します。 ハッシュ配布は、デフォルトのテーブル配布オプションです。 AnalyticDB for PostgreSQLは、レプリケーション分散とランダム分散もサポートしています。 レプリケーション分散は、各計算ノードでアクセス可能なテーブルの完全なコピーを生成します。 通常、レプリケーション分散は、関連するクエリが頻繁に実行される小さなテーブルに使用されます。 レプリケートされたテーブルでクエリを実行する場合、データをブロードキャストまたは再配布する必要はありません。 これにより、クエリのパフォーマンスが向上します。 ランダム分布は、大きなテーブルのフィールドがハッシュ列になるのに不適切なシナリオに適しています。 たとえば、ハッシュ分散はノード間でデータスキューを引き起こす可能性があり、レプリケーション分散は大きなテーブルには適していません。 この場合、ランダム分散は計算ノード間でデータを均等に分散します。
表形式データがコンピュートノードに分散された後、特定のクエリ用に表形式データを単一のコンピュートノードに分割して、クエリとデータ処理の範囲を絞り込むことができます。 AnalyticDB for PostgreSQLは、範囲とリストのパーティショニングタイプをサポートしており、マルチレベルパーティションを作成できます。 次の図では、ハッシュテーブルのデータはid列に基づいて3つのノードに分散されています。 各ノードでは、日付列に基づいて範囲分割が実行され、次に都市列に基づいてリスト分割が実行されます。 次の図の右端に示すように、各パーティションにはテーブルのデータとインデックスが格納されます。 パーティション化されたテーブルは、行ストアテーブル、列ストアテーブル、または外部テーブルです。 たとえば、データの書き込みが必要なMarパーティションには行ストアテーブルを、データがアーカイブされるFebパーティションには列ストアテーブルを、クエリがほとんど実行されないJanパーティションにはOSS外部テーブルを使用できます。

データベースオブジェクト
AnalyticDB for PostgreSQLは、オブジェクトとオブジェクトのプロパティ (データ型、関数、演算子、ドメイン、インデックスなど) をカスタマイズするために使用できるオブジェクトリレーショナルデータベースサービスです。 複雑なデータ構造を作成し、格納し、取り出すことができる。 データベースオブジェクトには、通常、テーブル、ビュー、関数、シーケンス、インデックス、パーティション分割された子テーブル、および外部テーブルが含まれます。 オブジェクトは、ロジックによって異なるスキーマに分割されます。 データベースが作成されると、パブリックスキーマがデフォルトスキーマとして作成されます。 すべてのユーザーまたはロールがパブリックスキーマにアクセスできます。 既定では、このデータベース用に作成されたオブジェクトはパブリックスキーマに含まれます。
データベースは、データベースオブジェクトの物理的な集合である。 スキーマは、データベース内のデータベースオブジェクトを整理および管理するために使用される論理コレクションです。 スキーマには、テーブル、インデックス、データ型、関数、演算子など、アプリケーションがアクセスできるオブジェクトが含まれます。 スキーマを使用してデータベースオブジェクトを論理グループに整理し、管理を容易にすることができます。 これにより、複数のユーザーまたはロールが互いに干渉することなく同じデータベースを使用できます。
ユーザーまたはロールは、インスタンスのグローバル権限を制御し、インスタンスのすべてのオブジェクトの権限を管理します。 ユーザーは個々のデータベースに固有ではありません。 データ管理 (DMS) コンソールにログインするには、ユーザーがデータベースに接続する必要があります。 ユーザは、様々なデータベースオブジェクトを所有することができる。
デフォルトでは、ユーザーが所有していないオブジェクトは表示できません。 オブジェクトを表示するには、必要な権限をユーザーに付与する必要があります。 必要な権限が付与されている場合、ユーザーは他のスキーマでオブジェクトを作成できます。 既定では、各ユーザーには、テーブルを作成し、テーブルからデータを読み取り、テーブルにデータを書き込む権限など、パブリックスキーマでオブジェクトを作成する権限があります。
AnalyticDB for PostgreSQLは、オブジェクトをシステムメタデータとしてコーディネーターノードとコンピュートノードの両方のサーバーに保存します。
