Spark 対話型リソースグループを指定することで、Spark SQL クエリを対話形式で実行できます。このリソースグループのリソースは、指定された範囲内で自動的にスケーリングされるため、対話型分析のニーズを満たし、コストを削減できます。このトピックでは、コンソール、Hive Java Database Connectivity (JDBC)、PyHive、Beeline、DBeaver などのクライアントツールを使用して、Spark SQL で対話型分析を実行する方法について説明します。
前提条件
AnalyticDB for MySQL Enterprise Edition、Basic Edition、または Data Lakehouse Edition クラスターが作成されていること。
AnalyticDB for MySQL クラスターと同じリージョンに Object Storage Service (OSS) バケットが作成されていること。
AnalyticDB for MySQL クラスターのデータベースアカウントが作成されていること。
Alibaba Cloud アカウントを使用する場合は、「特権アカウントを作成する」だけで済みます。
Resource Access Management (RAM) ユーザーを使用する場合は、「特権アカウントと標準アカウントを作成」し、「標準アカウントを RAM ユーザーに関連付ける」必要があります。
Java 8 および Python 3.9 の開発環境がインストールされていること。これらの環境では、Java アプリケーション、Python アプリケーション、Beeline などのクライアントを実行できます。
クライアントの IP アドレスを AnalyticDB for MySQL クラスターの ホワイトリスト に追加済みであること。
注意事項
Spark 対話型リソースグループが停止している場合、最初の Spark SQL クエリを実行すると、クラスターは自動的に再起動します。その結果、最初のクエリが長時間キューに入れられることがあります。
Spark は、INFORMATION_SCHEMA および MYSQL データベースからの読み取りや書き込みができません。これらのデータベースを初期接続に使用しないでください。
Spark SQL ジョブの送信に使用するデータベースアカウントに、ターゲットデータベースにアクセスするために必要な権限があることを確認してください。そうでない場合、クエリは失敗します。
準備
Spark 対話型リソースグループを作成済みであること。
Spark 対話型リソースグループのエンドポイントを取得します。
AnalyticDB for MySQL コンソールにログインします。コンソールの左上隅でリージョンを選択します。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。管理するクラスターを見つけて、クラスター ID をクリックします。
左側のナビゲーションウィンドウで、を選択し、リソースグループ管理 タブをクリックします。
目的のリソースグループを探し、 詳細 を 操作 列でクリックして、内部エンドポイントとパブリックエンドポイントを表示します。エンドポイントの横にある
 アイコンをクリックして、それをコピーできます。また、[ポート] の横にある括弧内の アイコンをクリックして、JDBC 接続文字列をコピーすることもできます。
アイコンをクリックして、それをコピーできます。また、[ポート] の横にある括弧内の アイコンをクリックして、JDBC 接続文字列をコピーすることもできます。次の場合は、[パブリックエンドポイント] の横にある [ネットワークをリクエスト] をクリックして、パブリックエンドポイントを手動でリクエストする必要があります。
Spark SQL ジョブの送信に使用するクライアントツールが、ローカルマシンまたは外部サーバーにデプロイされている。
Spark SQL ジョブの送信に使用するクライアントツールが ECS インスタンスにデプロイされており、その ECS インスタンスと AnalyticDB for MySQL クラスターが同じ VPC にない。

対話型分析
コンソール
セルフマネージドの HiveMetastore を使用する場合は、AnalyticDB for MySQL に default という名前のデータベースを作成する必要があります。その後、コンソールで Spark SQL ジョブを開発および実行するときに、このデータベースを選択します。
AnalyticDB for MySQL コンソールにログインします。コンソールの左上隅でリージョンを選択します。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。管理するクラスターを見つけて、クラスター ID をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
Spark エンジンと作成した Spark 対話型リソースグループを選択します。次に、次の Spark SQL 文を実行します。
SHOW DATABASES;
SDK 呼び出し
SDK メソッドを呼び出して Spark SQL クエリを実行すると、クエリ結果は指定された OSS の場所にファイルとして書き込まれます。その後、OSS コンソールでデータをクエリするか、「結果ファイルをローカルコンピューターにダウンロード」して表示できます。次のセクションでは、Python を使用して SDK を呼び出す例を示します。
次のコマンドを実行して SDK をインストールします。
pip install alibabacloud-adb20211201次のコマンドを実行して依存関係をインストールします。
pip install oss2 pip install loguruクラスターに接続し、Spark SQL クエリを実行します。
# coding: utf-8 import csv import json import time from io import StringIO import oss2 from alibabacloud_adb20211201.client import Client from alibabacloud_adb20211201.models import ExecuteSparkWarehouseBatchSQLRequest, ExecuteSparkWarehouseBatchSQLResponse, \ GetSparkWarehouseBatchSQLRequest, GetSparkWarehouseBatchSQLResponse, \ ListSparkWarehouseBatchSQLRequest, CancelSparkWarehouseBatchSQLRequest, ListSparkWarehouseBatchSQLResponse from alibabacloud_tea_openapi.models import Config from loguru import logger def build_sql_config(oss_location, spark_sql_runtime_config: dict = None, file_format = "CSV", output_partitions = 1, sep = "|"): """ ADB SQL 実行の構成を構築します。 :param oss_location: SQL 実行結果が格納される OSS パス。 :param spark_sql_runtime_config: Spark SQL コミュニティのネイティブ構成。 :param file_format: SQL 実行結果のファイル形式。デフォルト値: CSV。 :param output_partitions: SQL 実行結果のパーティション数。大量の結果を出力する必要がある場合は、単一のファイルが大きくなりすぎないように、出力パーティションの数を増やす必要があります。 :param sep: CSV ファイルの区切り文字。このパラメーターは CSV 以外のファイルでは無視されます。 :return: SQL 実行の構成。 """ if oss_location is None: raise ValueError("oss_location is required") if not oss_location.startswith("oss://"): raise ValueError("oss_location must start with oss://") if file_format != "CSV" and file_format != "PARQUET" and file_format != "ORC" and file_format != "JSON": raise ValueError("file_format must be CSV, PARQUET, ORC or JSON") runtime_config = { # sql output config "spark.adb.sqlOutputFormat": file_format, "spark.adb.sqlOutputPartitions": output_partitions, "spark.adb.sqlOutputLocation": oss_location, # csv config "sep": sep } if spark_sql_runtime_config: runtime_config.update(spark_sql_runtime_config) return runtime_config def execute_sql(client: Client, dbcluster_id: str, resource_group_name: str, query: str, limit = 10000, runtime_config: dict = None, schema="default" ): """ Spark 対話型リソースグループで SQL 文を実行します。 :param client: Alibaba Cloud Client。 :param dbcluster_id: クラスターの ID。 :param resource_group_name: クラスターのリソースグループ。Spark 対話型リソースグループである必要があります。 :param schema: SQL 実行のデフォルトのデータベース名。指定しない場合、デフォルト値は `default` です。 :param limit: SQL 実行結果の最大行数。 :param query: 実行する SQL 文。セミコロン (;) を使用して複数の SQL 文を区切ります。 :return: """ # リクエストボディを組み立てます。 req = ExecuteSparkWarehouseBatchSQLRequest() # クラスター ID。 req.dbcluster_id = dbcluster_id # リソースグループ名。 req.resource_group_name = resource_group_name # SQL 実行のタイムアウト期間。 req.execute_time_limit_in_seconds = 3600 # SQL 文が実行されるデータベースの名前。 req.schema = schema # SQL ビジネスコード。 req.query = query # 返される結果の行数。 req.execute_result_limit = limit if runtime_config: # SQL 実行の構成。 req.runtime_config = json.dumps(runtime_config) # SQL 文を実行し、query_id を取得します。 resp: ExecuteSparkWarehouseBatchSQLResponse = client.execute_spark_warehouse_batch_sql(req) logger.info("Query execute submitted: {}", resp.body.data.query_id) return resp.body.data.query_id def get_query_state(client, query_id): """ SQL 文の実行ステータスをクエリします。 :param client: Alibaba Cloud Client。 :param query_id: SQL 実行の ID。 :return: SQL 文の実行ステータスと結果。 """ req = GetSparkWarehouseBatchSQLRequest(query_id=query_id) resp: GetSparkWarehouseBatchSQLResponse = client.get_spark_warehouse_batch_sql(req) logger.info("Query state: {}", resp.body.data.query_state) return resp.body.data.query_state, resp def list_history_query(client, db_cluster, resource_group_name, page_num): """ Spark 対話型リソースグループで実行された SQL 文の履歴をクエリします。 :param client: Alibaba Cloud Client。 :param db_cluster: クラスターの ID。 :param resource_group_name: リソースグループ名。 :param page_num: ページングクエリのページ番号。 :return: SQL 文が存在するかどうか。存在する場合、次のページに進むことができます。 """ req = ListSparkWarehouseBatchSQLRequest(dbcluster_id=db_cluster, resource_group_name=resource_group_name, page_number = page_num) resp: ListSparkWarehouseBatchSQLResponse = client.list_spark_warehouse_batch_sql(req) # SQL 文が見つからない場合は true を返します。それ以外の場合は false を返します。デフォルトのページサイズは 10 です。 if resp.body.data.queries is None: return True # クエリされた SQL 文を出力します。 for query in resp.body.data.queries: logger.info("Query ID: {}, State: {}", query.query_id, query.query_state) logger.info("Total queries: {}", len(resp.body.data.queries)) return len(resp.body.data.queries) < 10 def list_csv_files(oss_client, dir): for obj in oss_client.list_objects_v2(dir).object_list: if obj.key.endswith(".csv"): logger.info(f"reading {obj.key}") # oss ファイルの内容を読み取ります csv_content = oss_client.get_object(obj.key).read().decode('utf-8') csv_reader = csv.DictReader(StringIO(csv_content)) # CSV の内容を出力します for row in csv_reader: print(row) if __name__ == '__main__': logger.info("ADB Spark Batch SQL Demo") # AccessKey ID。 ご自身の AccessKey ID に置き換えてください。 _ak = "LTAI****************" # AccessKey Secret。 ご自身の AccessKey Secret に置き換えてください。 _sk = "yourAccessKeySecret" # リージョン ID。 ご自身のリージョン ID に置き換えてください。 _region= "cn-shanghai" # クラスター ID。 ご自身のクラスター ID に置き換えてください。 _db = "amv-uf6485635f****" # リソースグループ名。 ご自身のリソースグループ名に置き換えてください。 _rg_name = "testjob" # クライアント構成 client_config = Config( # Alibaba Cloud AccessKey ID access_key_id=_ak, # Alibaba Cloud AccessKey Secret access_key_secret=_sk, # ADB サービスのエンドポイント # adb.ap-southeast-1.aliyuncs.com はシンガポールリージョンの ADB サービスのエンドポイントです # adb-vpc.ap-southeast-1.aliyuncs.com は VPC シナリオで使用されます endpoint=f"adb.{_region}.aliyuncs.com" ) # Alibaba Cloud Client を作成します。 _client = Client(client_config) # SQL 実行の構成。 _spark_sql_runtime_config = { "spark.sql.shuffle.partitions": 1000, "spark.sql.autoBroadcastJoinThreshold": 104857600, "spark.sql.sources.partitionOverwriteMode": "dynamic", "spark.sql.sources.partitionOverwriteMode.dynamic": "dynamic" } _config = build_sql_config(oss_location="oss://testBucketName/sql_result", spark_sql_runtime_config = _spark_sql_runtime_config) # 実行する SQL 文。 _query = """ SHOW DATABASES; SELECT 100; """ _query_id = execute_sql(client = _client, dbcluster_id=_db, resource_group_name=_rg_name, query=_query, runtime_config=_config) logger.info(f"Run query_id: {_query_id} for SQL {_query}.\n Waiting for result...") # SQL 実行が完了するのを待ちます。 current_ts = time.time() while True: query_state, resp = get_query_state(_client, _query_id) """ query_state は次のいずれかの状態になります: - PENDING: ジョブはサービスキューで保留中です。Spark 対話型リソースグループが起動しています。 - SUBMITTED: ジョブは Spark 対話型リソースグループに送信されました。 - RUNNING: SQL 文が実行中です。 - FINISHED: SQL 文はエラーなしで正常に実行されました。 - FAILED: SQL 実行が失敗しました。 - CANCELED: SQL 実行がキャンセルされました。 """ if query_state == "FINISHED": logger.info("query finished success") break elif query_state == "FAILED": # 失敗情報を出力します。 logger.error("Error Info: {}", resp.body.data) exit(1) elif query_state == "CANCELED": # キャンセル情報を出力します。 logger.error("query canceled") exit(1) else: time.sleep(2) if time.time() - current_ts > 600: logger.error("query timeout") # 実行時間が 10 分を超えた場合、SQL 実行をキャンセルします。 _client.cancel_spark_warehouse_batch_sql(CancelSparkWarehouseBatchSQLRequest(query_id=_query_id)) exit(1) # 1 つのクエリに複数の文を含めることができます。すべての文をリストします。 for stmt in resp.body.data.statements: logger.info( f"statement_id: {stmt.statement_id}, result location: {stmt.result_uri}") # 結果を表示するためのサンプルコード。 _bucket = stmt.result_uri.split("oss://")[1].split("/")[0] _dir = stmt.result_uri.replace(f"oss://{_bucket}/", "").replace("//", "/") oss_client = oss2.Bucket(oss2.Auth(client_config.access_key_id, client_config.access_key_secret), f"oss-{_region}.aliyuncs.com", _bucket) list_csv_files(oss_client, _dir) # Spark 対話型リソースグループで実行されたすべての SQL 文をクエリします。ページングクエリがサポートされています。 logger.info("List all history query") page_num = 1 no_more_page = list_history_query(_client, _db, _rg_name, page_num) while no_more_page: logger.info(f"List page {page_num}") page_num += 1 no_more_page = list_history_query(_client, _db, _rg_name, page_num)パラメーター:
_ak: AnalyticDB for MySQL の アクセス権限 を持つ Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID。AccessKey ID と AccessKey Secret の取得方法の詳細については、「アカウントと権限」をご参照ください。
_sk: AnalyticDB for MySQL の アクセス権限 を持つ Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey Secret。AccessKey ID と AccessKey Secret の取得方法の詳細については、「アカウントと権限」をご参照ください。
region: AnalyticDB for MySQL クラスターのリージョン ID。
_db: AnalyticDB for MySQL クラスターの ID。
_rg_name: Spark 対話型リソースグループの名前。
oss_location: (オプション) クエリ結果ファイルが格納される OSS パス。
このパラメーターを指定しない場合、 ページの SQL クエリ文の [ログ] で、データの最初の 5 行のみを表示できます。
アプリケーション
Hive JDBC
pom.xml ファイルで Maven の依存関係を構成します。
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.3.9</version> </dependency>接続を確立し、Spark SQL クエリを実行します。
public class java { public static void main(String[] args) throws Exception { Class.forName("org.apache.hive.jdbc.HiveDriver"); String url = "<endpoint>"; Connection con = DriverManager.getConnection(url, "<username>", "<password>"); Statement stmt = con.createStatement(); ResultSet tables = stmt.executeQuery("show tables"); List<String> tbls = new ArrayList<>(); while (tables.next()) { System.out.println(tables.getString("tableName")); tbls.add(tables.getString("tableName")); } } }パラメーター:
接続アドレス: Spark 対話型リソースグループの JDBC 接続文字列。詳細については、「準備」をご参照ください。接続文字列では、
defaultをご自身のデータベースの名前に置き換える必要があります。username: AnalyticDB for MySQL のデータベースアカウント。
password: AnalyticDB for MySQL データベースアカウントのパスワード。
PyHive
Python Hive クライアントをインストールします。
pip install pyhive接続を確立し、Spark SQL クエリを実行します。
from pyhive import hive from TCLIService.ttypes import TOperationState cursor = hive.connect( host='<endpoint>', port=<port>, username='<resource_group_name>/<username>', password='<password>', auth='CUSTOM' ).cursor() cursor.execute('show tables') status = cursor.poll().operationState while status in (TOperationState.INITIALIZED_STATE, TOperationState.RUNNING_STATE): logs = cursor.fetch_logs() for message in logs: print(message) # If needed, an asynchronous query can be cancelled at any time with: # cursor.cancel() status = cursor.poll().operationState print(cursor.fetchall())パラメーター:
エンドポイント: 準備 で、Spark 対話型リソースグループのエンドポイントが提供されます。
port: Spark 対話型リソースグループのポート番号。値は 10000 に固定されています。
resource_group_name: Spark 対話型リソースグループの名前。
username: AnalyticDB for MySQL のデータベースアカウント。
password: AnalyticDB for MySQL データベースアカウントのパスワード。
クライアント
このトピックで説明する Beeline、DBeaver、DBVisualizer、Datagrip クライアントに加えて、「Airflow」、「Azkaban」、「DolphinScheduler」などのワークフロースケジューリングツールでも対話型分析を実行できます。
Beeline
Spark 対話型リソースグループに接続します。
コマンドのフォーマットは次のとおりです。
!connect <endpoint> <username> <password>接続アドレス: Spark 対話型リソースグループの JDBC 接続文字列。詳細については、「準備」をご参照ください。接続文字列では、
defaultをご自身のデータベースの名前に置き換える必要があります。username: AnalyticDB for MySQL のデータベースアカウント。
password: AnalyticDB for MySQL データベースアカウントのパスワード。
例:
!connect jdbc:hive2://amv-bp1c3em7b2e****-spark.ads.aliyuncs.com:10000/adb_test spark_resourcegroup/AdbSpark14**** Spark23****次の結果が返されます。
Connected to: Spark SQL (version 3.2.0) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READSpark SQL クエリを実行します。
SHOW TABLES;
DBeaver
DBeaver クライアントを開き、 を選択します。
[データベースに接続] ページで、[Apache Spark] を選択し、[次へ] をクリックします。
[Hadoop/Apache Spark 接続設定] を構成します。パラメーターは次のとおりです。
パラメーター
説明
接続方法
[接続方法] を [URL] に設定します。
JDBC URL
「準備」で取得した JDBC 接続文字列を入力します。
重要接続文字列の
defaultをご自身のデータベースの名前に置き換えてください。ユーザー名
AnalyticDB for MySQL のデータベースアカウント。
パスワード
AnalyticDB for MySQL データベースアカウントのパスワード。
パラメーターを構成したら、[接続のテスト] をクリックします。
重要初めて接続をテストすると、DBeaver は必要なドライバーに関する情報を自動的に取得します。情報が取得されたら、[ダウンロード] をクリックしてドライバーをダウンロードします。
接続に成功したら、[終了] をクリックします。
[データベースナビゲーター] タブで、データソースのサブディレクトリを展開し、データベースをクリックします。
右側のコードエディタに SQL 文を入力し、
 アイコンをクリックして文を実行します。
アイコンをクリックして文を実行します。SHOW TABLES;次の結果が返されます。
+-----------+-----------+-------------+ | namespace | tableName | isTemporary | +-----------+-----------+-------------+ | db | test | [] | +-----------+-----------+-------------+
DBVisualizer
DBVisualizer クライアントを開き、 を選択します。
[ドライバーマネージャー] ページで、[Hive] を選択し、
 アイコンをクリックします。
アイコンをクリックします。[ドライバー設定] タブで、次のパラメーターを構成します。
パラメーター
説明
名前
Hive データソースの名前。名前はカスタマイズできます。
URL フォーマット
「準備」で取得した JDBC 接続文字列を入力します。
重要接続文字列の
defaultをご自身のデータベースの名前に置き換えてください。ドライバークラス
Hive ドライバー。これを [org.apache.hive.jdbc.HiveDriver] に設定します。
重要パラメーターを構成したら、[ダウンロードを開始] をクリックしてドライバーをダウンロードします。
ドライバーがダウンロードされたら、 を選択します。
[データベース URL からデータベース接続を作成] ダイアログボックスで、次の表に示すパラメーターを構成します。
パラメーター
説明
データベース URL
「準備」で取得した JDBC 接続文字列を入力します。
重要接続文字列の
defaultをご自身のデータベースの名前に置き換えてください。ドライバークラス
ステップ 3 で作成した Hive データソースを選択します。
[接続] ページで、次の接続パラメーターを構成し、[接続] をクリックします。
パラメーター
説明
名前
デフォルトでは、このパラメーターはステップ 3 で作成した Hive データソースと同じ値を持ちます。名前はカスタマイズできます。
メモ
備考。
ドライバーの種類
[Hive] を選択します。
データベース URL
「準備」で取得した JDBC 接続文字列を入力します。
重要接続文字列の
defaultをご自身のデータベースの名前に置き換えてください。データベースユーザー ID
AnalyticDB for MySQL のデータベースアカウント。
データベースパスワード
AnalyticDB for MySQL データベースアカウントのパスワード。
説明他のパラメーターを構成する必要はありません。デフォルト値を使用できます。
接続に成功したら、[データベース] タブで、データソースのサブディレクトリを展開し、データベースをクリックします。
右側のコードエディタに SQL 文を入力し、
 アイコンをクリックして文を実行します。
アイコンをクリックして文を実行します。SHOW TABLES;次の結果が返されます。
+-----------+-----------+-------------+ | namespace | tableName | isTemporary | +-----------+-----------+-------------+ | db | test | false | +-----------+-----------+-------------+
Datagrip
Datagrip クライアントを開き、 を選択してプロジェクトを作成します。
データソースを追加します。
 アイコンをクリックし、 を選択します。
アイコンをクリックし、 を選択します。表示される [データソースとドライバー] ダイアログボックスで、次のパラメーターを構成し、[OK] をクリックします。
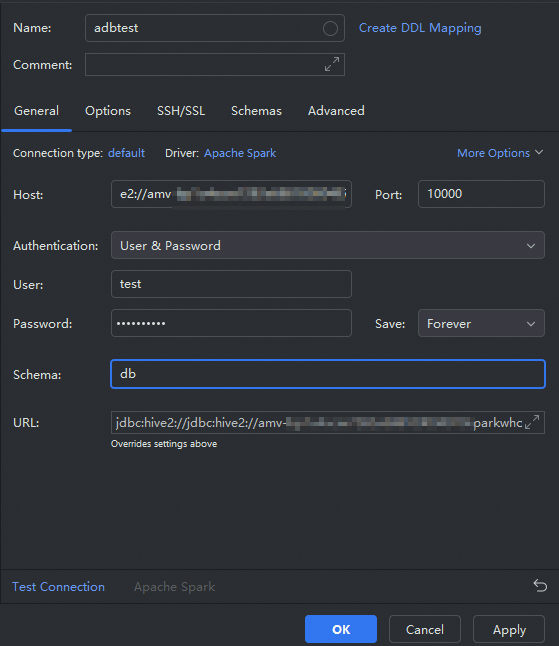
パラメーター
説明
名前
データソースの名前。名前はカスタマイズできます。この例では、
adbtestが使用されます。ホスト
「準備」で取得した JDBC 接続文字列を入力します。
重要接続文字列の
defaultをご自身のデータベースの名前に置き換えてください。ポート
Spark 対話型リソースグループのポート番号。値は 10000 に固定されています。
ユーザー
AnalyticDB for MySQL のデータベースアカウント。
パスワード
AnalyticDB for MySQL データベースアカウントのパスワード。
スキーマ
AnalyticDB for MySQL クラスター内のデータベースの名前。
Spark SQL クエリを実行します。
データソースリストで、ステップ 2 で作成したデータソースを右クリックし、 を選択します。
右側の [コンソール] パネルで、Spark SQL クエリを実行します。
SHOW TABLES;