背景情報
レコメンデーションシステムは、ユーザーに表示されるアイテムを選択し、クリックや購入などの肯定的なユーザー行動を期待します。ただし、レコメンデーションシステムは、システムがユーザーにアイテムをレコメンドしたときにユーザーの行動を予測することはできません。これは、システムがレコメンデーションの報酬を事前に学習できないことを示しています。レコメンデーションシステムは、レコメンデーションポリシーを更新するために、リアルタイムで試し続け、ユーザーの行動データを収集する必要があります。これにより、リグレットが最小限に抑えられます。このプロセスは、ギャンブラーがスロットマシンで遊ぶのと似ています。カジノでは、ギャンブラーはスロットマシンの列の前に立っています。各マシンは、そのマシンに固有の確率分布からランダムな報酬を提供します。ギャンブラーは、報酬の合計を最大化するために、どのマシンでプレイするか、どの順番でプレイするかを決定する必要があります。これは、多腕バンディット(MAB)問題です。
MAB問題は、探索と活用のトレードオフのジレンマの良い例です。活用とは、ギャンブラーがより多くの報酬を得るために、高いペイオフがあるとわかっているマシンでプレイする必要があることを示しています。探索とは、ギャンブラーはより良いペイオフを見逃さないように、他のマシンでもプレイする必要があることを示しています。ただし、この場合、ギャンブラーはより高いリスクにも直面し、機会費用が増加します。
コールドスタート問題
新しいアイテムには履歴行動データがありません。ユーザー満足度を最大化するためにトラフィックをどのように割り当てればよいでしょうか?
レコメンデーションシステムのフィードバックループ
レコメンデーションアルゴリズムは表示するコンテンツを決定し、表示されたコンテンツはユーザーの行動に影響を与え、ユーザーの行動データはアルゴリズムモデルのトレーニングのために収集されます。この場合、フィードバックループが発生します。フィードバックループでは、トレーニングデータセットとテストデータセットのデータは独立して同一に分布していません。また、システムには効果的な探索メカニズムがありません。アルゴリズムモデルは、ローカル最適化に重点を置いています。

ユーザーの行動データがまばらな場合、負のフィードバックループはより深刻になります。重要な問題は、限られたデータを使用してレコメンデーションのパフォーマンスを絶対的な確信を持って予測することはできないということです。負のフィードバックループを閉じるには、探索と活用が不可欠です。
概要
バンディットアルゴリズムは、探索と活用のバランスをより適切に取ることができます。コールドスタート問題を解決するために、事前に大量のデータを収集する必要はありません。これにより、表示回数で割った直接的な利益に基づく重み計算によってマタイ効果が発生するのを防ぎます。さらに、レコメンデーションシステムは、ほとんどのロングテールアイテムと新しいアイテムを公開する機会を得ることができます。バンディットアルゴリズムに基づいて設計されたレコメンデーションアルゴリズムは、前述の問題をより適切に解決できます。
バンディットアルゴリズムは、コンテキスト特性が考慮されるかどうかによって、コンテキストフリーバンディットアルゴリズムとコンテキストバンディットアルゴリズムに分類されます。
シングルプレイバンディットアルゴリズムの擬似コード:
バンディットアルゴリズムと従来のアルゴリズムの違い:
各候補アイテムは独立したモデルに対応しています。これにより、すべてのアイテムが1つのモデルに対応する従来のモデルにおけるサンプル分布の不均衡が回避されます。
従来のアルゴリズムは貪欲なポリシーを採用し、既存の知識を最大限に活用するために活用に重点を置いています。これは、マタイ効果のために情報の繭を引き起こす可能性があります。ただし、バンディットアルゴリズムには明示的な探索メカニズムが備わっています。露出の少ないアイテムは、より多くの露出の機会を得ます。
バンディットアルゴリズムはオンライン学習に基づいており、リアルタイムでモデルを更新します。バンディットアルゴリズムは、A/Bテストよりも早く最適なポリシーを取得できます。
リクエストで複数の候補アイテムをレコメンドするには、次のマルチプレイバンディットアルゴリズムを使用します。

詳細な説明
バンディットアルゴリズムは、活用と探索のジレンマを解決するために使用されるポリシーです。バンディットアルゴリズムは、コンテキスト機能が考慮されるかどうかによって、コンテキストフリーバンディットアルゴリズムとコンテキストバンディットアルゴリズムに分類されます。
1. UCB
コンテキストフリーバンディットアルゴリズムには、εグリーディー、ソフトマックス、トンプソンサンプリング、および上限信頼限界(UCB)が含まれます。
UCBは、平均報酬の信頼区間の上限を指し、特定のアームの将来の報酬の推定値を示します。
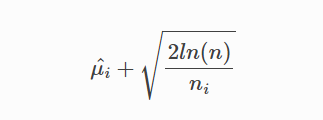
UCBが最も高いアームが選択されます。 UCBアルゴリズムの利点は、未知のアームにより多くの機会を提供することです。

未知でプル回数の少ないアームの平均報酬は低くなる可能性があります。ただし、これらのアームのUCBは、不確実性のために高くなる可能性があります。したがって、探索メカニズムは高い確率でトリガーされる可能性があります。
既知のアームでは、活用メカニズムがトリガーされる可能性が高くなります。アームの平均報酬が大きい場合、アームをプルする機会が増えます。そうでない場合は、機会が少なくなります。
2. LinUCB
レコメンデーションシステムでは、レコメンドされるアイテムは通常、MAB問題のアームと見なされます。 UCBアルゴリズムなどのコンテキストフリーバンディットアルゴリズムは、レコメンデーションシーンのコンテキスト情報を考慮せず、同じポリシーを使用してすべてのユーザーにアイテムをレコメンドします。このように、興味、好み、購買力などのユーザーの特徴は無視されます。同じアイテムは、異なるユーザーによって異なるシーンで異なる方法で受け入れられます。したがって、レコメンデーションシステムはコンテキストフリーバンディットアルゴリズムを採用していません。
コンテキストバンディットアルゴリズムは、活用と探索のジレンマを解決するために使用される場合、コンテキスト情報を考慮に入れます。したがって、コンテキストバンディットアルゴリズムはパーソナライズされたレコメンデーションシーンに適用できます。
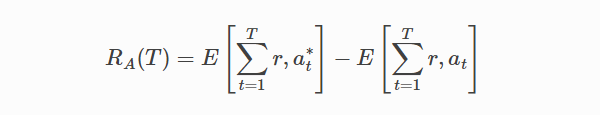
Tは、試行におけるすべての「t」を示します。 at* は、試行tで期待されるペイオフが最大のアームですが、事前に知ることはできません。
LinUCBアルゴリズムの利点:
計算の複雑さは、アームの数に比例します。
動的候補アームがサポートされています。
参照
レコメンデーションシステムでのコンテキストバンディットアルゴリズムの実装
本番環境でのレコメンデーションシステムへのコンテキストバンディット(LinUCB)アルゴリズムのデプロイの経験と落とし穴
Telcoのレコメンダーシステムでコールドスタート問題を解決するための多腕バンディットの使用
レコメンダーシステムに適用されるマルチプレイバンディットアルゴリズム
多腕バンディットポリシーをコンテキストバンディットシナリオに適応させる