このチュートリアルでは、パブリックデータセットを使用して PAI-Rec でカスタムレコメンデーションソリューションを構成する手順を説明します。最終的には、特徴量エンジニアリング、検索、詳細なランキングを網羅するエンドツーエンドのレコメンデーションパイプラインが動作し、そのワークフローが DataWorks にデプロイされます。
前提条件
開始する前に、以下を完了していることを確認してください。
PAI をアクティブ化済みであること。「PAI をアクティブ化し、デフォルトのワークスペースを作成する」をご参照ください。
VPC と vSwitch を作成済みであること。「IPv4 CIDR ブロックを持つ VPC を作成する」をご参照ください。
PAI-FeatureStore をアクティブ化し、オンラインストアとして FeatureDB を設定済みであること (Hologres はアクティブ化しないでください)。「データソースを作成する」の [前提条件] セクションと、「オンラインストアを作成する: FeatureDB」をご参照ください。
MaxCompute をアクティブ化し、project_mc という名前の MaxCompute プロジェクトを作成済みであること。「MaxCompute をアクティブ化する」と「MaxCompute プロジェクトを作成する」をご参照ください。
Object Storage Service (OSS) バケットを作成済みであること。「バケットを作成する」をご参照ください。
DataWorks をアクティブ化し、以下の設定を完了済みであること。
DataWorks ワークスペースを作成済みであること。「ワークスペースを作成する」をご参照ください。
DataWorks 用のサーバーレスリソースグループを購入済みであること (PAI-FeatureStore のデータ同期および eascmd コマンドの実行による PAI-EAS サービスの作成と更新に使用されます)。「サーバーレスリソースグループを使用する」をご参照ください。
DataWorks で OSS データソースと MaxCompute データソースを構成済みであること。「データソース管理」と「MaxCompute コンピューティングリソースをアタッチする」をご参照ください。
FeatureStore プロジェクトと特徴量エンティティを作成済みであること。サーバーレスリソースグループを使用する場合は、このステップをスキップしてください。専用リソースグループを使用する場合は、FeatureStore Python SDK をインストールしてください。「II. FeatureStore を作成して登録する」と「FeatureStore Python SDK をインストールする」をご参照ください。
Flink をアクティブ化し、[ストレージタイプ] を OSS バケットに設定済みであること (フルマネージドストレージではない)。Flink 用の OSS バケットは、PAI-Rec 用に構成されたものと一致している必要があります。Flink は、リアルタイムユーザー行動データを記録し、リアルタイムユーザー特徴量を計算するために使用されます。「Realtime Compute for Apache Flink をアクティブ化する」をご参照ください。
(条件付き) EasyRec (TensorFlow) を使用する場合: モデルはデフォルトで MaxCompute でトレーニングされます。
(条件付き) TorchEasyRec (PyTorch) を使用する場合: モデルはデフォルトで PAI-DLC でトレーニングされます。PAI-DLC で MaxCompute データをダウンロードするには、Data Transmission Service (DTS) をアクティブ化してください。「Data Transmission Service 用の専用リソースグループを購入して使用する」をご参照ください。
ステップ 1: PAI-Rec インスタンスを作成し、サービスを初期化する
このステップでは、PAI-Rec Premium Edition インスタンスをプロビジョニングし、前提条件で設定したクラウドリソースに接続します。Premium Edition は必須です。これには、このチュートリアルで使用されるデータ診断とカスタムレコメンデーションソリューション機能が含まれています。
パーソナライズドレコメンデーションプラットフォームのホームページにログインして、[今すぐ購入] をクリックします。
購入ページで、以下のパラメーターを設定し、[今すぐ購入] をクリックします。
パラメーター 説明 リージョンとゾーン ご利用のクラウドサービスがデプロイされるリージョン。 サービスタイプ [Premium Edition] を選択します。Premium Edition は、Standard Edition と比較して、データ診断とカスタムレコメンデーションソリューション機能を追加します。 PAI-Rec コンソール にログインし、トップメニューバーからリージョンを選択します。
左のナビゲーションウィンドウで、[インスタンスリスト] をクリックします。 インスタンス名をクリックしてインスタンス詳細ページを開きます。
「操作ガイド」セクションで、[初期化] をクリックします。[システム構成] > [エンドツーエンドサービス] にリダイレクトされます。[編集] をクリックし、次の表のリソースを構成してから、[完了] をクリックします。
左側のナビゲーションウィンドウで、[システム構成] > [権限管理] を選択します。[アクセスサービス] タブで、各クラウドプロダクトへのアクセスが許可されていることを確認します。
ステップ 2: パブリックデータセットをクローンする
このステップでは、サンプルデータを MaxCompute プロジェクトにロードします。PAI-Rec は、公開アクセス可能な pai_online_project プロジェクトで 3 つの共有テーブルを提供します。
ユーザーテーブル:
pai_online_project.rec_sln_demo_user_tableアイテムテーブル:
pai_online_project.rec_sln_demo_item_table行動テーブル:
pai_online_project.rec_sln_demo_behavior_table
これらのテーブルのデータはランダムに生成されており、実際のビジネス上の意味はありません。そのため、AUC (曲線下面積) などのトレーニングメトリクスは低くなります。これはデモ設定では想定内の動作です。
2 つの方法が利用可能です。
| 方法 | スケジューリングサポート | 使用時期 |
|---|---|---|
| SQL を使用して固定時間ウィンドウを同期 | なし | チュートリアルを探索するための 1 回限りの設定 |
| Python スクリプトを使用してデータを生成 | あり (日次) | スケジュールされたタスクによる定期的なモデルトレーニング |
日次データ生成とモデルトレーニングには、Python スクリプト方式を使用してください。
固定時間ウィンドウを同期
DataWorks で SQL コマンドを実行して、pai_online_project から 3 つのテーブルを MaxCompute プロジェクト (例: project_mc) にコピーします。
DataWorks コンソール にログインし、リージョンを選択します。
左側のナビゲーションウィンドウで、[データ開発と O&M] > [データ開発] をクリックします。
作成した DataWorks ワークスペースを選択し、[データ開発へ移動] をクリックします。
「作成」にマウスを合わせ、[ノードの作成] > [MaxCompute] > [ODPS SQL] を選択します。次のパラメーターを設定し、[確認] をクリックします。
ノードエディターで、以下の SQL を貼り付けて実行します。実行する前に、スケジューリング変数を構成して、
${bizdate}が前日の日付に、${bizdate_100}が${bizdate}の 100 日前に設定されるようにします。スケジューリングパラメーターは次のように構成します: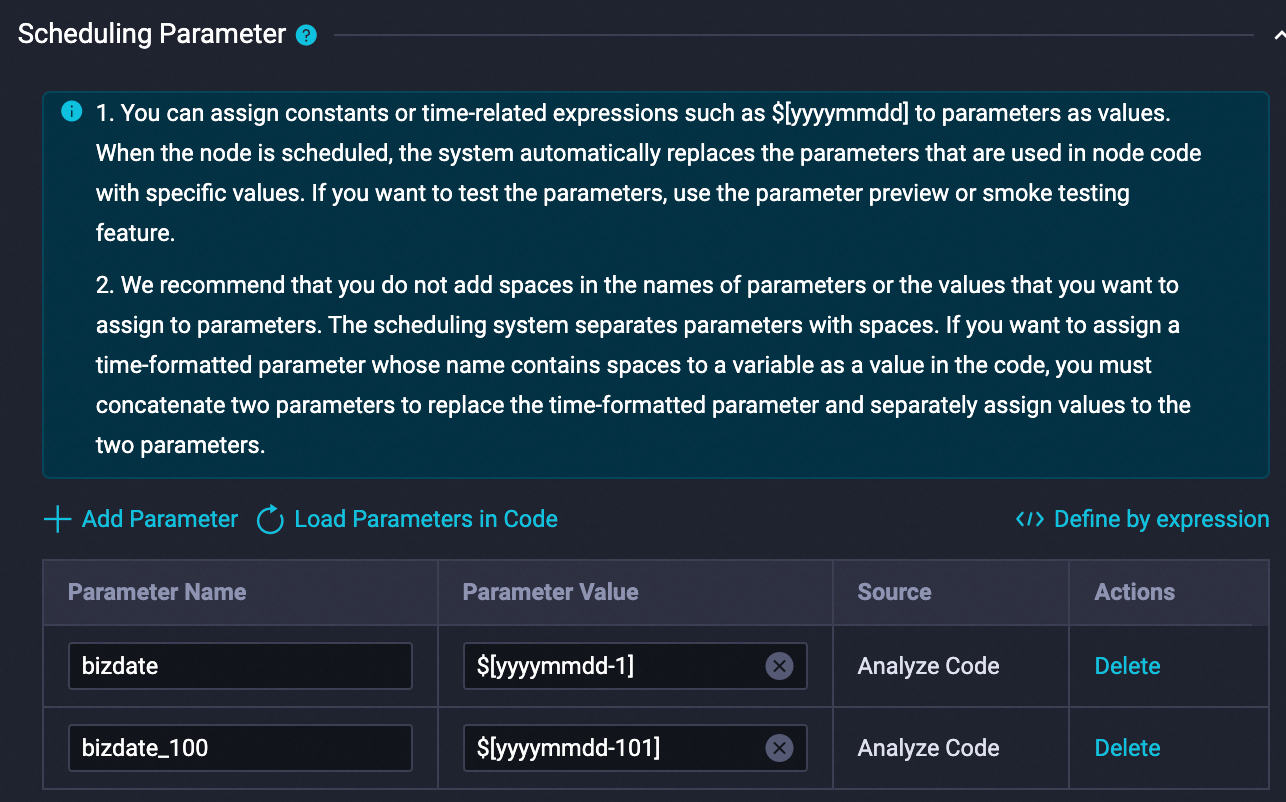 パブリックプロジェクトからご利用のプロジェクトにデータをコピーするには、以下の SQL を 1 回実行します。
パブリックプロジェクトからご利用のプロジェクトにデータをコピーするには、以下の SQL を 1 回実行します。CREATE TABLE IF NOT EXISTS rec_sln_demo_user_table_v1( user_id BIGINT COMMENT '一意のユーザーID', gender STRING COMMENT '性別', age BIGINT COMMENT '年齢', city STRING COMMENT '都市', item_cnt BIGINT COMMENT '作成されたアイテムの数', follow_cnt BIGINT COMMENT 'フォロー数', follower_cnt BIGINT COMMENT 'フォロワー数', register_time BIGINT COMMENT '登録時間', tags STRING COMMENT 'ユーザータグ' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_user_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_user_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}"; CREATE TABLE IF NOT EXISTS rec_sln_demo_item_table_v1( item_id BIGINT COMMENT 'アイテムID', duration DOUBLE COMMENT '動画の長さ', title STRING COMMENT 'タイトル', category STRING COMMENT 'プライマリタグ', author BIGINT COMMENT '作成者', click_count BIGINT COMMENT '合計クリック数', praise_count BIGINT COMMENT '合計いいね数', pub_time BIGINT COMMENT '公開時間' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_item_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_item_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}"; CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table_v1( request_id STRING COMMENT 'インストルメンテーションID/リクエストID', user_id STRING COMMENT '一意のユーザーID', exp_id STRING COMMENT '実験ID', page STRING COMMENT 'ページ', net_type STRING COMMENT 'ネットワークタイプ', event_time BIGINT COMMENT '行動時間', item_id STRING COMMENT 'アイテムID', event STRING COMMENT '行動タイプ', playtime DOUBLE COMMENT '再生/読み取り時間' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_behavior_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_behavior_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}";
Python スクリプトを使用してデータを生成
この方法を使用して、日次データ生成をスケジュールします。スクリプトは、指定された時間範囲の合成データを生成します。
DataWorks コンソールで、PyODPS 3 ノードを作成します。「MaxCompute ノードを作成および管理する」をご参照ください。
create_data.py をダウンロードし、その内容を PyODPS 3 ノードに貼り付けます。
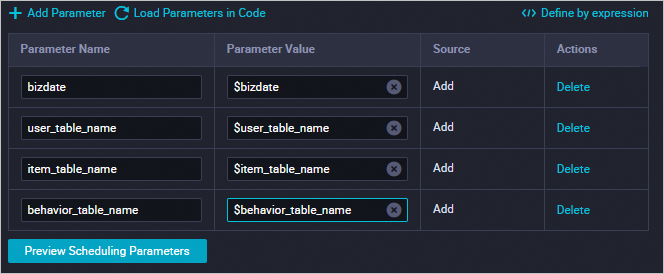
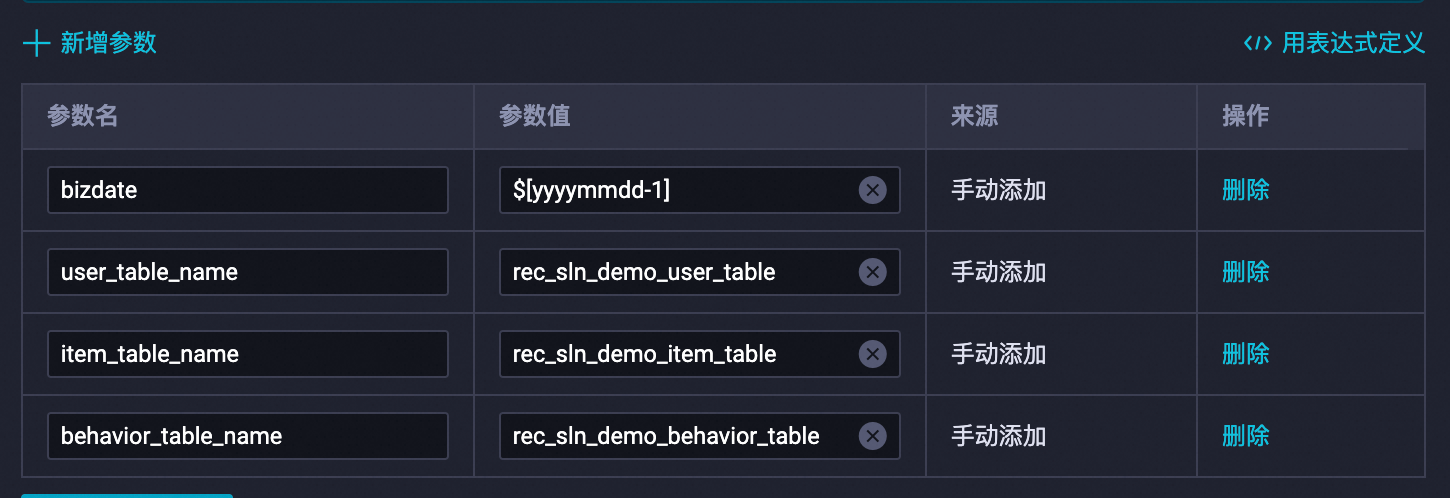
右側のペインで、[スケジューリング構成] をクリックし、スケジューリングパラメーターを設定します。次の変数を置き換えます。置き換え後、スケジューリングの依存関係を設定し、次に保存
 アイコンと送信
アイコンと送信  アイコンをクリックします。
アイコンをクリックします。$user_table_name→rec_sln_demo_user_table$item_table_name→rec_sln_demo_item_table$behavior_table_name→rec_sln_demo_behavior_table
「運用センター」に移動し、[定期タスクの運用・保守] > [定期タスク] を選択します。
ターゲットタスクの[操作]列で、[データ埋め戻し] > [現在のノードと子孫ノード]を選択します。
[データのバックフィル]パネルで、データタイムスタンプを設定し、[送信して移動]をクリックします。データ整合性を確保するために、データタイムスタンプを
Scheduled task date - 60に設定して、60 日分のデータをバックフィルします。
依存ノードを構成する
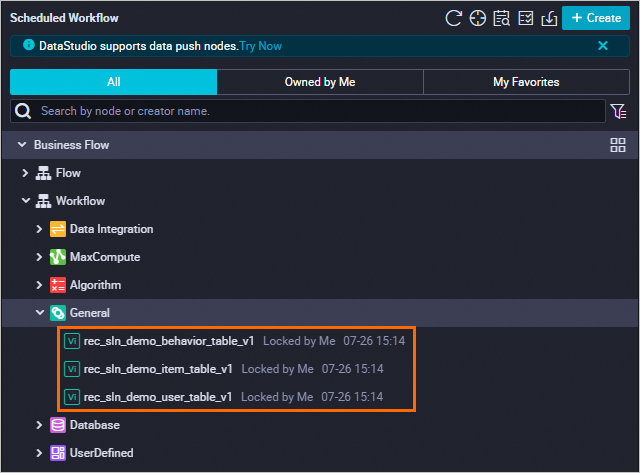
DataWorks プロジェクトに 3 つの仮想ノードを追加します。これらのノードは、データテーブルの依存アンカーとして機能し、ダウンストリームタスクが実行される前にデータが利用可能になるのを待ちます。
[作成] にカーソルを合わせ、[ノードの作成] > [一般] > [仮想ノード] を選択します。 以下の設定を使用して 3 つの仮想ノードを作成し、[確認] をクリックします。
各仮想ノードについて、ノードコンテンツを
select 1;に設定します。次に、右側のペインで[スケジューリング構成]をクリックし、次の設定を完了します。3つのノードすべてを構成します。「[時間プロパティ]」で、「再実行プロパティ」を「[成功時または失敗時に再実行]」に設定します。
[スケジューリング依存関係] > [上流依存関係] で、DataWorks ワークスペース名を入力し、_root サフィックスが付いたノードを選択して、[追加] をクリックします。
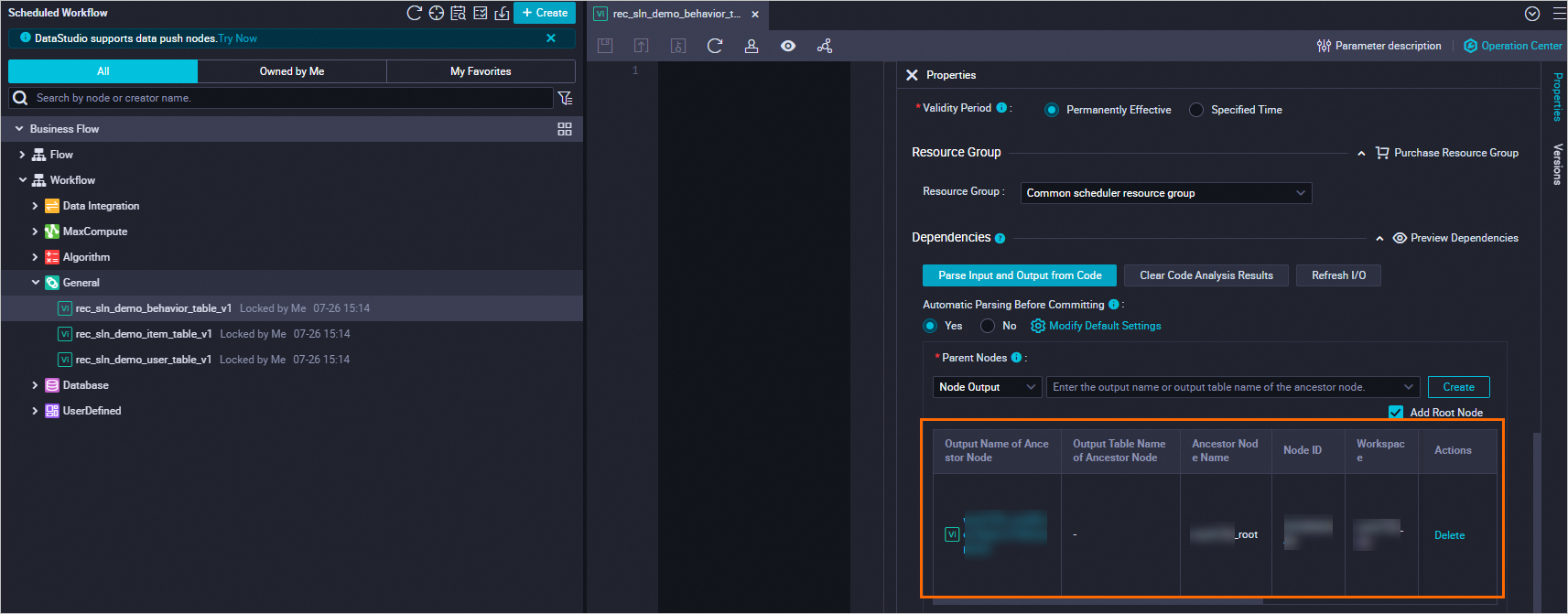
各仮想ノードの前の
 アイコンをクリックして送信します。
アイコンをクリックして送信します。
ステップ 3: データを登録する
後続のステップで特徴量エンジニアリング、検索、ランキング構成で利用できるように、3 つの同期されたテーブルを PAI-Rec に登録します。
PAI-Rec コンソール にログインし、リージョンを選択します。
左側のナビゲーションウィンドウで、[インスタンスリスト] をクリックします。インスタンス名をクリックして、インスタンス詳細ページを開きます。
左側のナビゲーションウィンドウで、[カスタムレコメンデーションソリューション] > [データ登録] を選択します。「MaxCompute テーブル」タブで、[データテーブルの追加] をクリックします。次の設定を使用して、ユーザー テーブル、アイテム テーブル、および動作 テーブルをそれぞれ 1 つずつ追加し、[インポートの開始] をクリックします。
パラメーター 説明 例 MaxCompute プロジェクト 作成した MaxCompute プロジェクト。 project_mcMaxCompute テーブル 同期されたデータテーブル。 ユーザー: rec_sln_demo_user_table_v1; アイテム:rec_sln_demo_item_table_v1; 行動:rec_sln_demo_behavior_table_v1データテーブル名 テーブルのカスタム表示名。 User Table、Item Table、Behavior Table
ステップ 4: レコメンデーションシナリオを作成する
レコメンデーションが提供されるコンテキスト (例: ホームページフィード) を定義するレコメンデーションシナリオを作成します。レコメンデーションシナリオとトラフィック ID の背景情報については、「用語」をご参照ください。
左側のナビゲーションウィンドウで、[推奨シナリオ] を選択します。 [シナリオの作成] をクリックし、以下のパラメーターを設定して、[OK] をクリックします。
ステップ 5: アルゴリズムソリューションを作成および構成する
このステップでは、レコメンデーションシナリオの検索アルゴリズムとランキングアルゴリズムを構成します。完全な本番環境設定では、以下のアルゴリズムが利用可能です。
グローバルホット検索: ログデータからのクリック統計に基づいて、上位 k 個のアイテムをランク付けします。
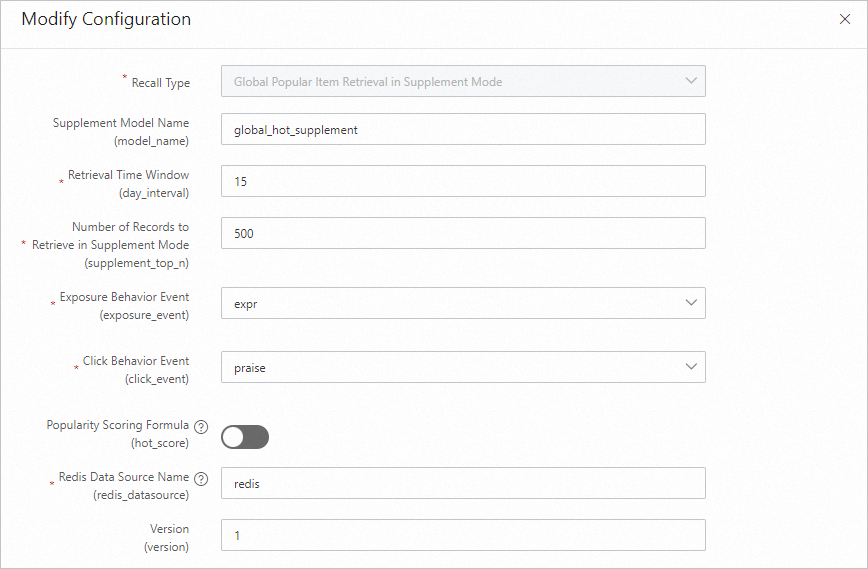
グローバルホットフォールバック検索: プライマリ検索エンジンが失敗した場合に空の結果を防ぐために、Redis にフォールバック候補セットを保存します。
グループ化されたホット検索: 属性グループ (例: 都市や性別) 別にアイテムを検索し、人気アイテムのパーソナライゼーションを改善します。
etrec U2I 検索: etrec 協調フィルタリングアルゴリズムに基づくユーザーからアイテムへの検索。
Swing u2i 再現率 (オプション): Swing アルゴリズムに基づくユーザー対アイテムの再現率。
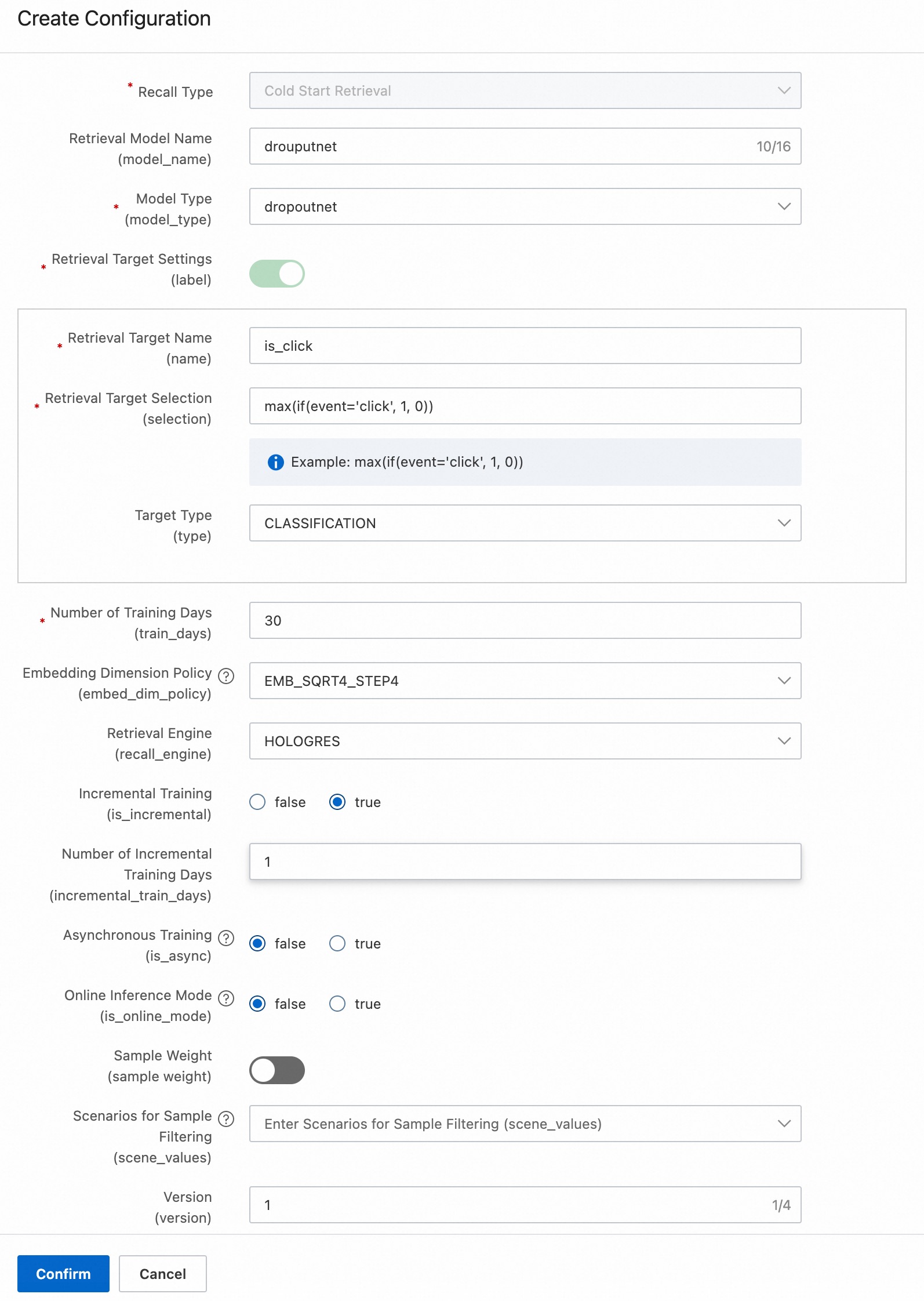
コールドスタート検索 (オプション): DropoutNet アルゴリズムを使用した新規ユーザーおよびアイテムの検索。
詳細なランキング: 単一目的ランキングには MultiTower を、多目的ランキングには DBMTL を選択します。
ベクター検索と PDN 検索は、通常、基本的な検索ステージが完了した後に追加されます。ベクター検索にはベクター検索エンジンが必要ですが、FeatureDB はこれをサポートしていないため、このチュートリアルでは扱いません。
デプロイを迅速に完了するために、このチュートリアルでは、検索ステージには [グローバルホット検索] と [etrec U2I 検索] のみを、ランキングステージには [詳細なランキング] のみを構成します。
左側のナビゲーションウィンドウで、[カスタム推奨ソリューション] > [ソリューション構成] を選択します。 作成したシナリオを選択し、[推奨ソリューションの作成] をクリックし、次のパラメーターを入力してから、[アルゴリズムソリューションを保存して構成] をクリックします。 ここに記載されていないパラメーターについては、デフォルト値のままにします。 詳細については、「データテーブル構成」をご参照ください。
[データテーブル設定] ノードで、各データテーブルの横にある [追加] をクリックします。以下のように動作ログテーブル、ユーザーテーブル、およびアイテムテーブルを設定し、[次へ] をクリックします。ここに記載されていないパラメーターについては、デフォルト値のままにします。詳細については、「データテーブル設定」をご参照ください。動作ログテーブル 動作ログテーブルを設定する際、実際のデータに合わせてフィールドを調整します。デモ動作ログには、リクエスト ID、ユーザー ID、ページ、動作タイムスタンプ、および動作タイプが含まれます。データに追加のディメンションがある場合は、特徴量エンジニアリング用にそれらをユーザー情報またはアイテム情報として分類します。
ユーザーテーブル
アイテムテーブル
[特徴量構成] ノードで、次のパラメーターを設定し、[特徴量生成] をクリックし、特徴量バージョンを設定して、[次へ] をクリックします。[特徴量生成] をクリックすると、システムがユーザーとアイテムの統計的特徴量を導出します。このチュートリアルでは、デフォルト設定で問題ありません。導出された特徴量をカスタマイズするには、特徴量構成をご参照ください。
[再現率の構成] ノードで、対象の再現率カテゴリの横にある [追加] をクリックし、パラメーターを設定し、[確認] をクリックし、次に [次へ] をクリックします。
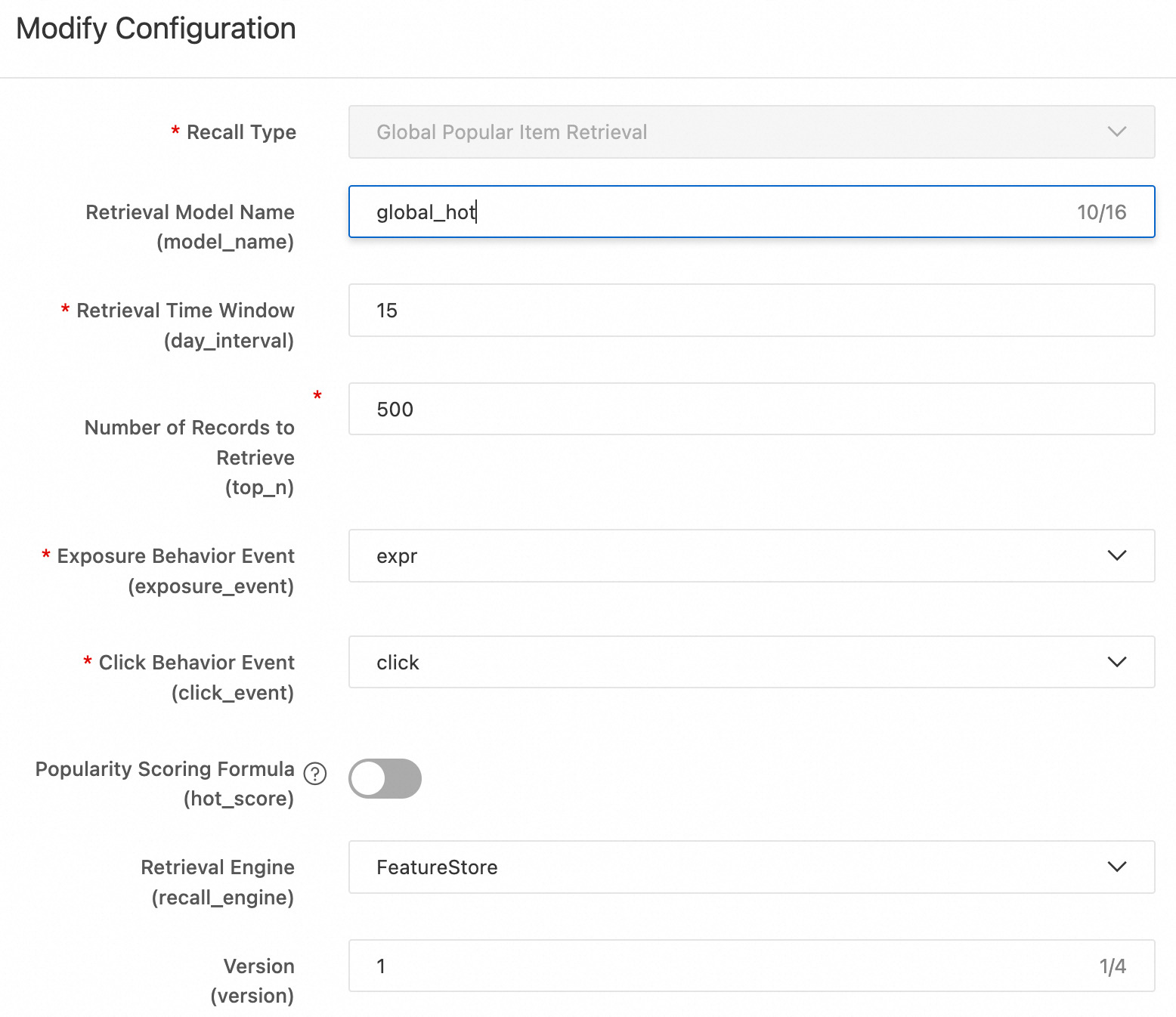
以下のセクションでは、各リコール手法について説明します。迅速なデプロイメントを行うには、[グローバルホットリコール] および etrec u2i リコール のみを設定してください。残りの手法は参考用です。#### グローバルホットリコール グローバルホットリコールは、クリックイベントの統計に基づいて、人気のあるアイテム(
top_nアイテム)のランキング付きリストを生成します。DataWorks にコードをデプロイした後、スコアリング数式または対象イベントを変更できます。スコアリング数式は次のとおりです:グローバルホットリコール
グローバルホットリコールは、クリックイベントの統計に基づいて、人気アイテムのランキングリスト (
top_nアイテム) を生成します。コードを DataWorks にデプロイした後、スコアリング数式やターゲットイベントを変更できます。スコアリング数式は以下の通りです:
click_uv * click_uv / (expr + adj_factor) * exp(-item_publish_days / fresh_decay_denom)次に示すとおり:
click_uv:同じクリック率 (CTR) の場合、クリック数が多いほど人気度が高いことを示します。click_uv / (expr + adj_factor):平滑化された CTR です。click_uvはクリックしたユニークユーザー数、exprはインプレッション数です。調整係数adj_factorは、分母がゼロになるのを防ぎ、インプレッション数が少ない場合に CTR を補正します。exp(-item_publish_days / fresh_decay_denom):古いアイテムのスコアを減らすための新鮮さのペナルティです。item_publish_daysは公開からの経過日数です。
etrec u2i リコール
etrec はアイテムベースの協調フィルタリングアルゴリズムです。詳細については、「協調フィルタリング etrec」をご参照ください。
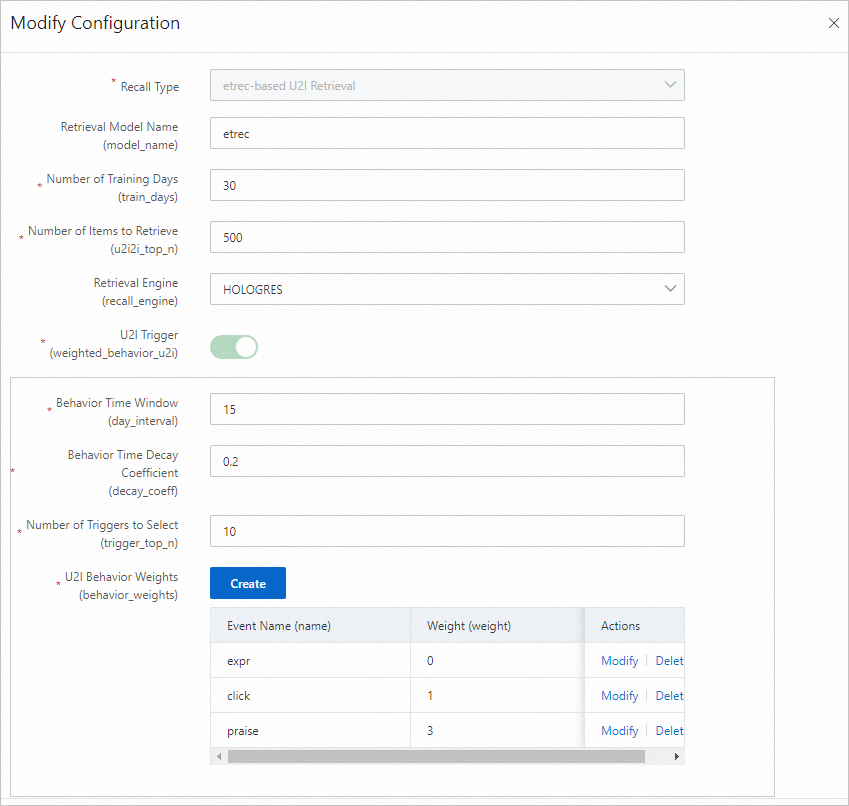
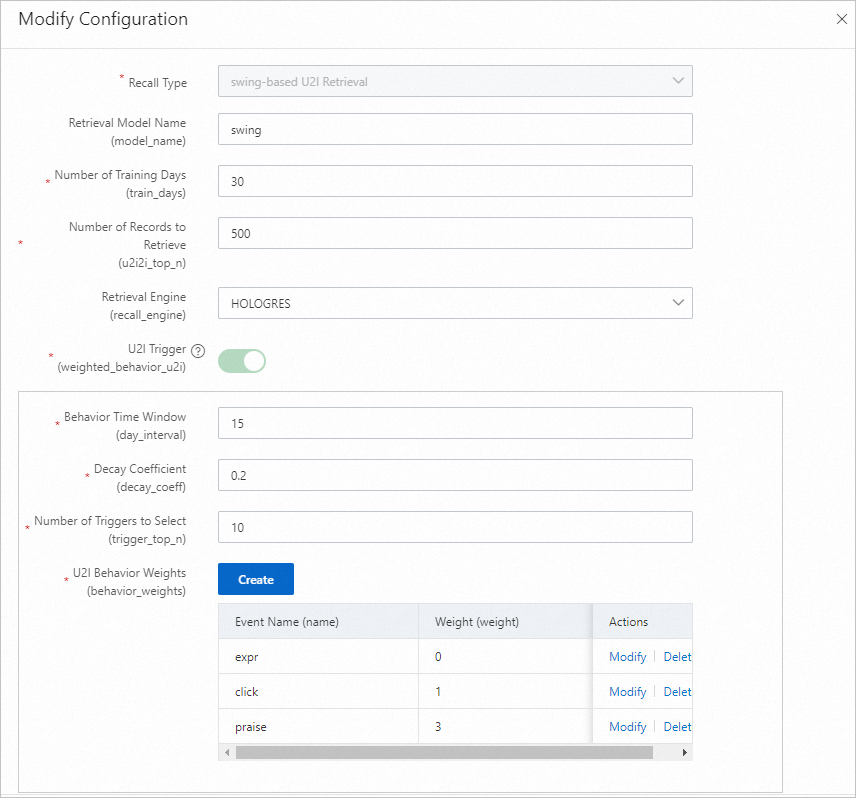
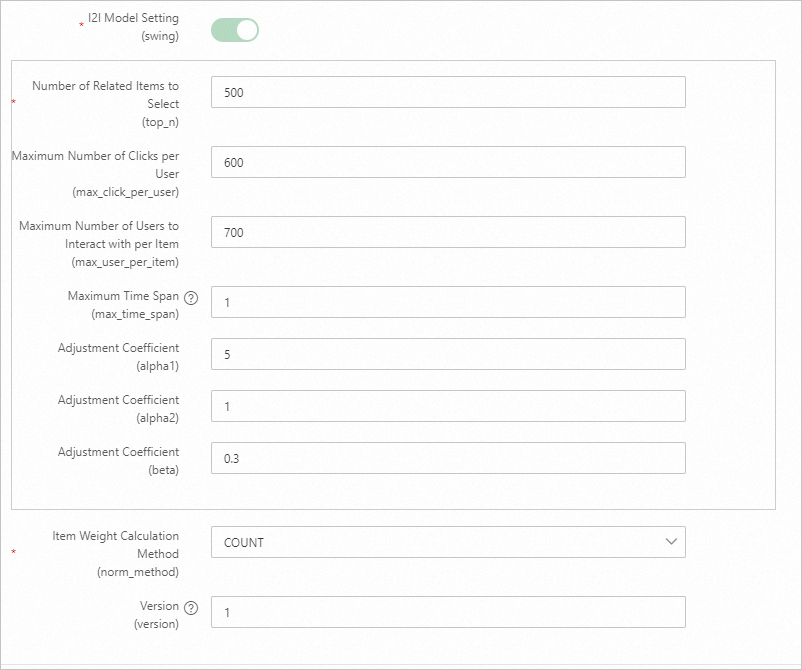
パラメーター 説明 トレーニング日数 トレーニングに使用される動作ログの日数です。デフォルト:30。ログのボリュームに応じて調整してください。 リコール数 オフラインで生成されるユーザーとアイテムのペアの最終的な数です。 U2Iトリガー ユーザーが操作 (クリック、お気に入り登録、購入など) したアイテムです。インプレッションのみのアイテムは含めないでください。 動作タイムウィンドウ 収集する動作データの日数です。デフォルト:15。 動作時間減衰係数 0 から 1 の間の値です。値が大きいほど、過去の動作の減衰が速くなり、トリガーアイテムを構築する際の重みが減少します。 トリガー選択数 etrec からの i2i データとデカルト積を実行するために使用される、ユーザーあたりのアイテム ID の数です。通常は 10 から 50 の間の値が使用されます。トリガーが多すぎると、候補セットが大きくなりすぎます。 U2i 動作の重み インプレッションイベントの重みを 0 に設定するか、未設定のままにします。 I2I モデル設定 etrec モデルのパラメーターです。詳細については、「協調フィルタリング etrec」をご参照ください。関連アイテムの選択数を高く設定しすぎないようにしてください。 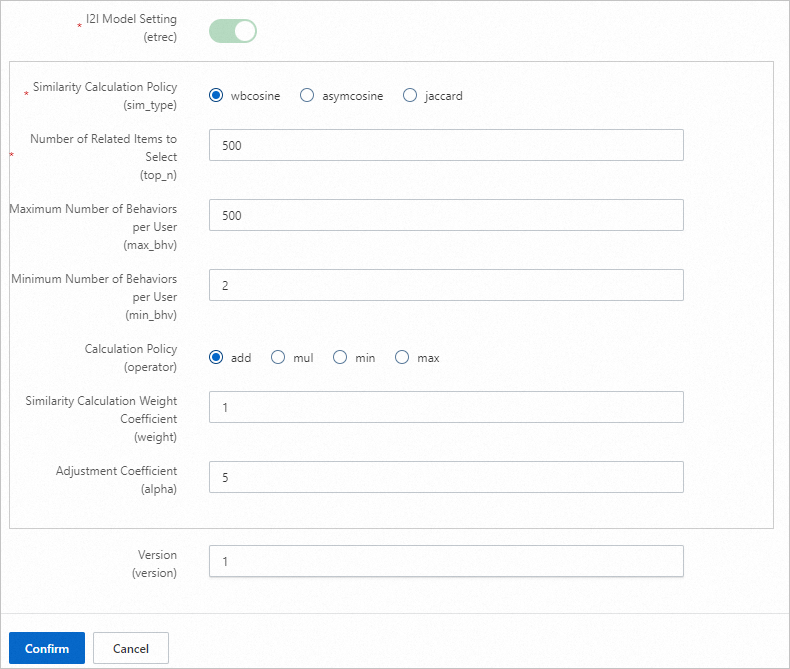
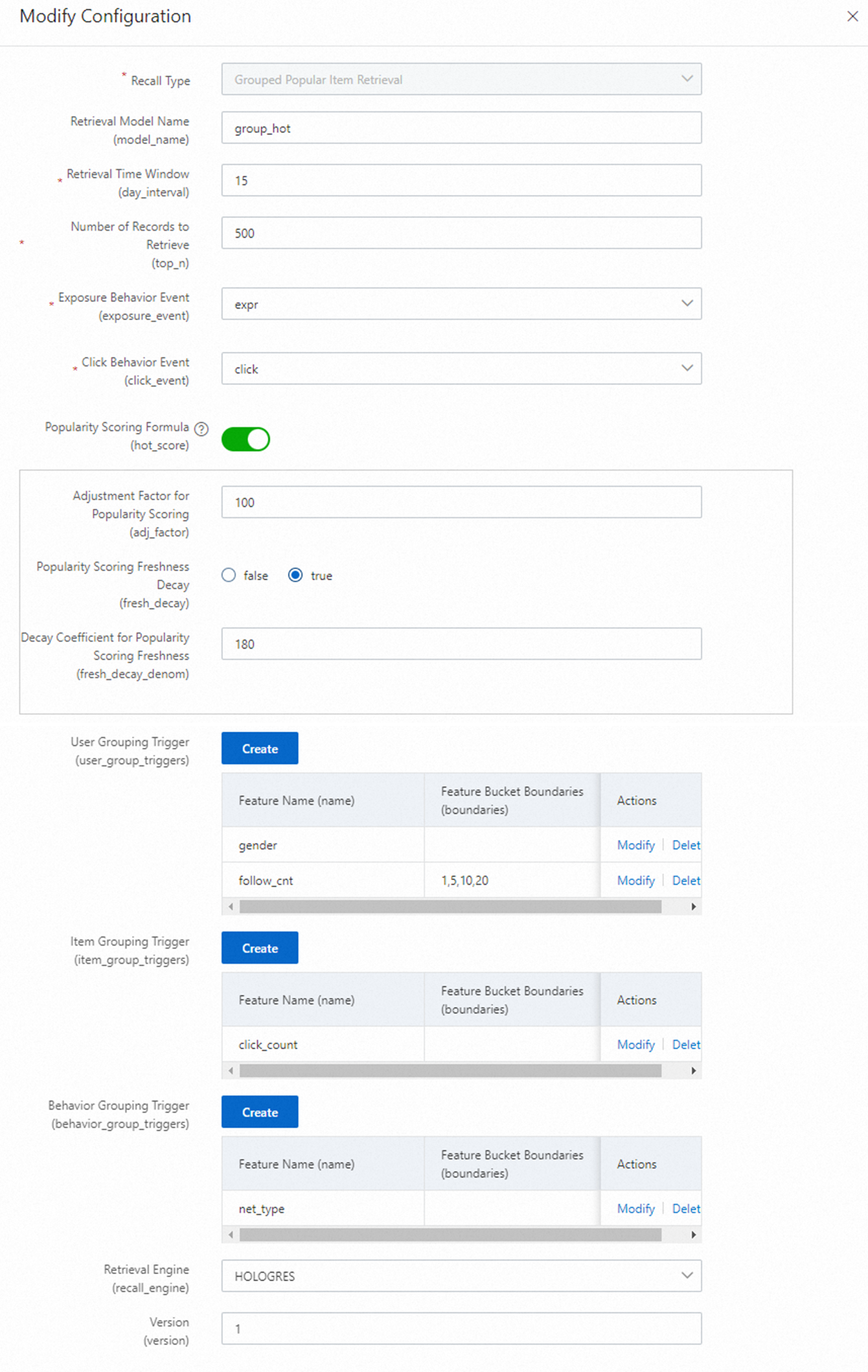
グループ化ホットリコール
属性グループ (都市や性別など) ごとにランキングを設定し、初期のパーソナライゼーションを提供します。以下の例では、性別と数値属性のバケット化された値の組み合わせをグループとして使用しています。
Swing u2i リコール
Swing は、User-Item-User の原則に基づいてアイテムの類似度を測定します。
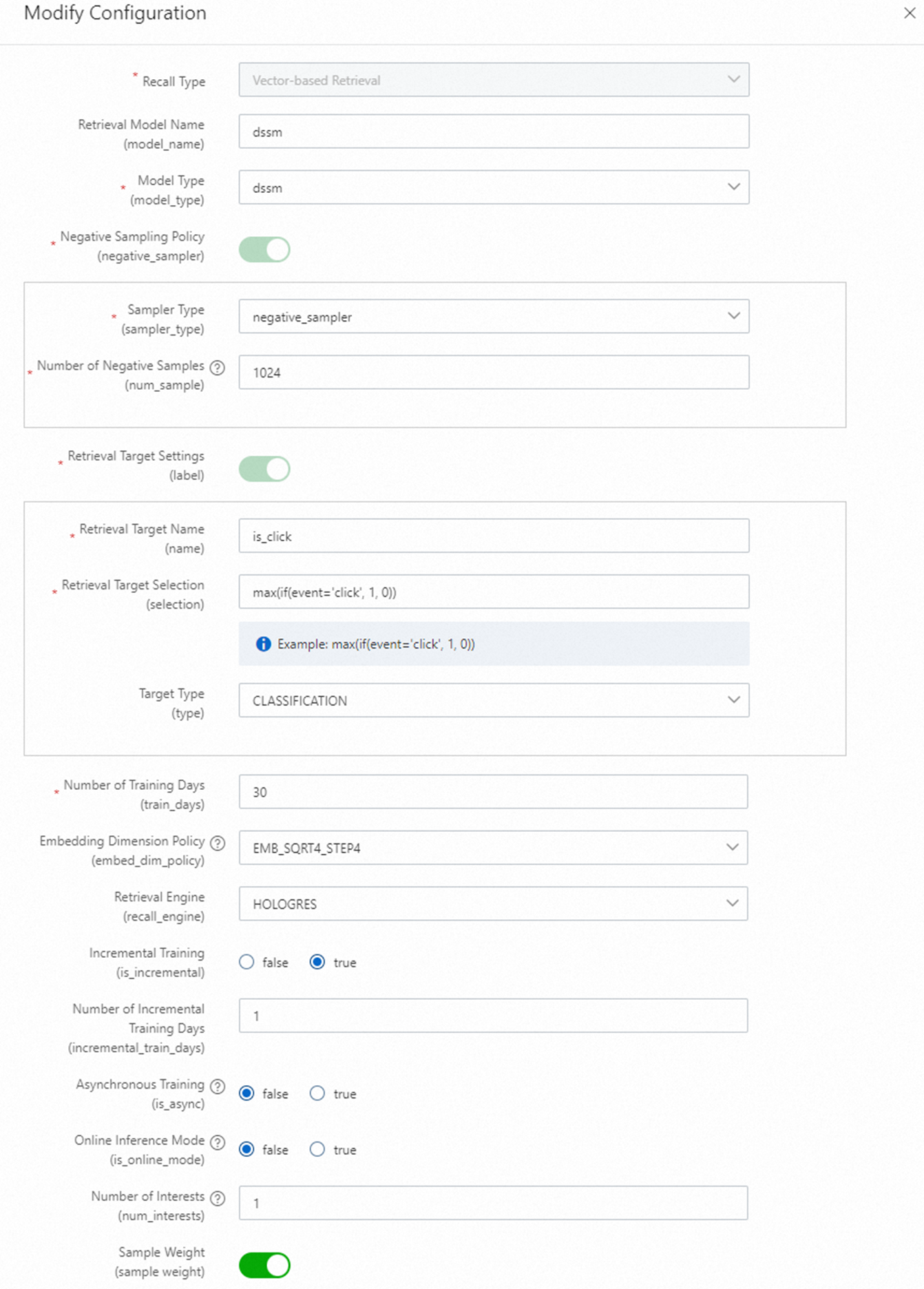
ベクターリコール
利用可能なベクターリコールのメソッドは、DSSM と MIND の 2 種類です。
リコールターゲットを以下のように設定します:
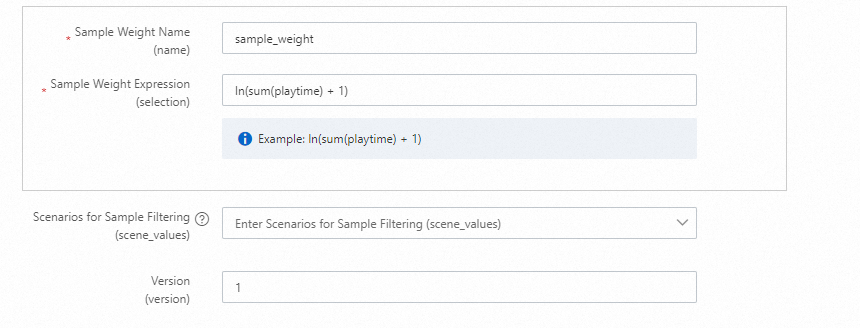
リコールターゲット名:
is_clickリコールターゲットの選択:
max(if(event='click', 1, 0))
以下の SQL はリコールターゲットを生成します:
select max(if(event='click',1,0)) is_click, ... from ${behavior_table} where dt between ${bizdate_start} and ${bizdate_end} group by req_id, user_id, item以下に示すとおり:
${behavior_table}:動作テーブルです。${bizdate_start}:動作タイムウィンドウの開始日です。event:動作テーブルのイベントフィールドです。ご利用の特定のフィールドに基づいて値を選択してください。is_click:ターゲット名です。
埋め込みディメンションの数式:
EMB_SQRT4_STEP8: (8 + Pow(count, 0.25)) / 8) * 8 EMB_SQRT4_STEP4: (4 + Pow(count, 0.25)) / 4) * 4 EMB_LN_STEP8: (8 + Log(count + 1)) / 8) * 8 EMB_LN_STEP4: (4 + Log(count + 1)) / 4) * 4特徴量の値の数が多い場合は、Log 関数を使用します。
コールドスタートリコール
DropoutNet は、ヘッドユーザーやアイテム、ロングテールや新規のユーザーやアイテムに適したデュアルタワーリコールモデル (ユーザータワー + アイテムタワー) です。詳細については、「DropoutNet」をご参照ください。
グローバルホットフォールバックリコール
グローバルホットフォールバックリコールはセーフティネットとして機能します。プライマリリコールエンジンに障害が発生した場合、Redis に保存されている事前計算された候補セットを返します。その出力は単一行のデータです。
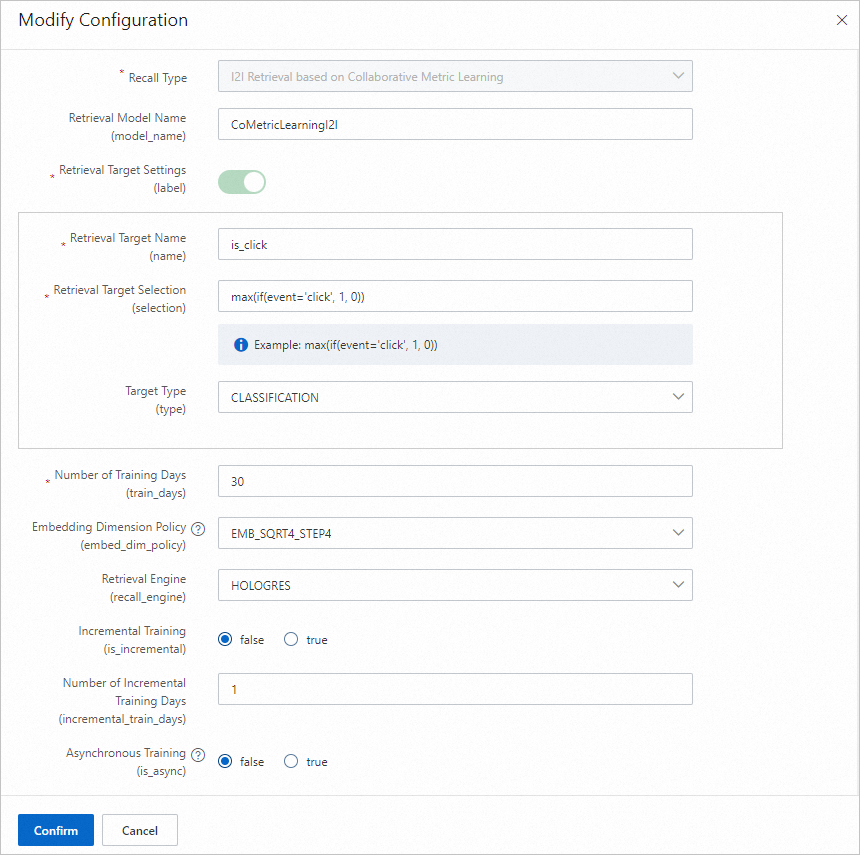
協調メトリック学習 i2i リコール
協調メトリック学習 I2I リコールモデルは、セッションクリックデータに基づいてアイテムの類似度を計算します。
「検索順位の構成」ノードで、「細かい検索順位」の横にある[追加]をクリックし、パラメーターを設定して[確認]をクリックした後、[次へ]をクリックします。
PAI-Rec は複数のランキングモデルをサポートしています。全リストについては、「ランキングモデル」をご参照ください。以下に、多目的ランキングモデルである DBMTL の構成方法を示します。
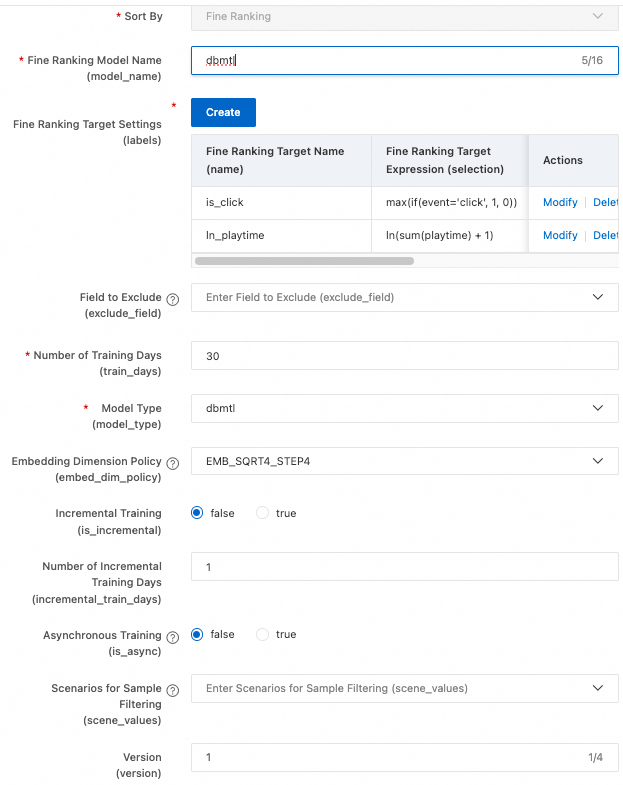
[精選ランキングのターゲット設定 (ラベル)] の横にある [追加] をクリックし、2 つのラベルを追加します:
ターゲット 1
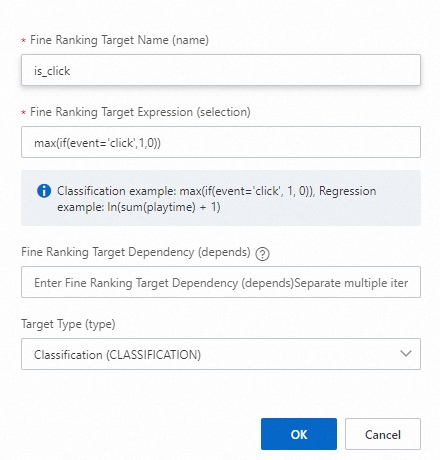
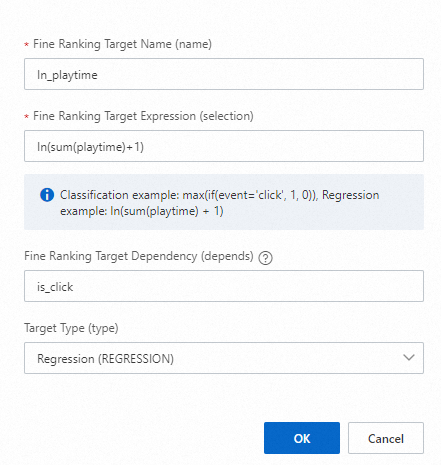
ターゲット 2 (「ln」の「l」は小文字の L です)
[Generate script]ノードで、[Generate Deployment Script]をクリックします。
重要スクリプトが生成されると、システムはすべてのデプロイファイルが保存される OSS アドレスを生成します。このアドレスはローカルに保存してください。Migration Assistant を介して手動でデプロイする場合に必要になります。
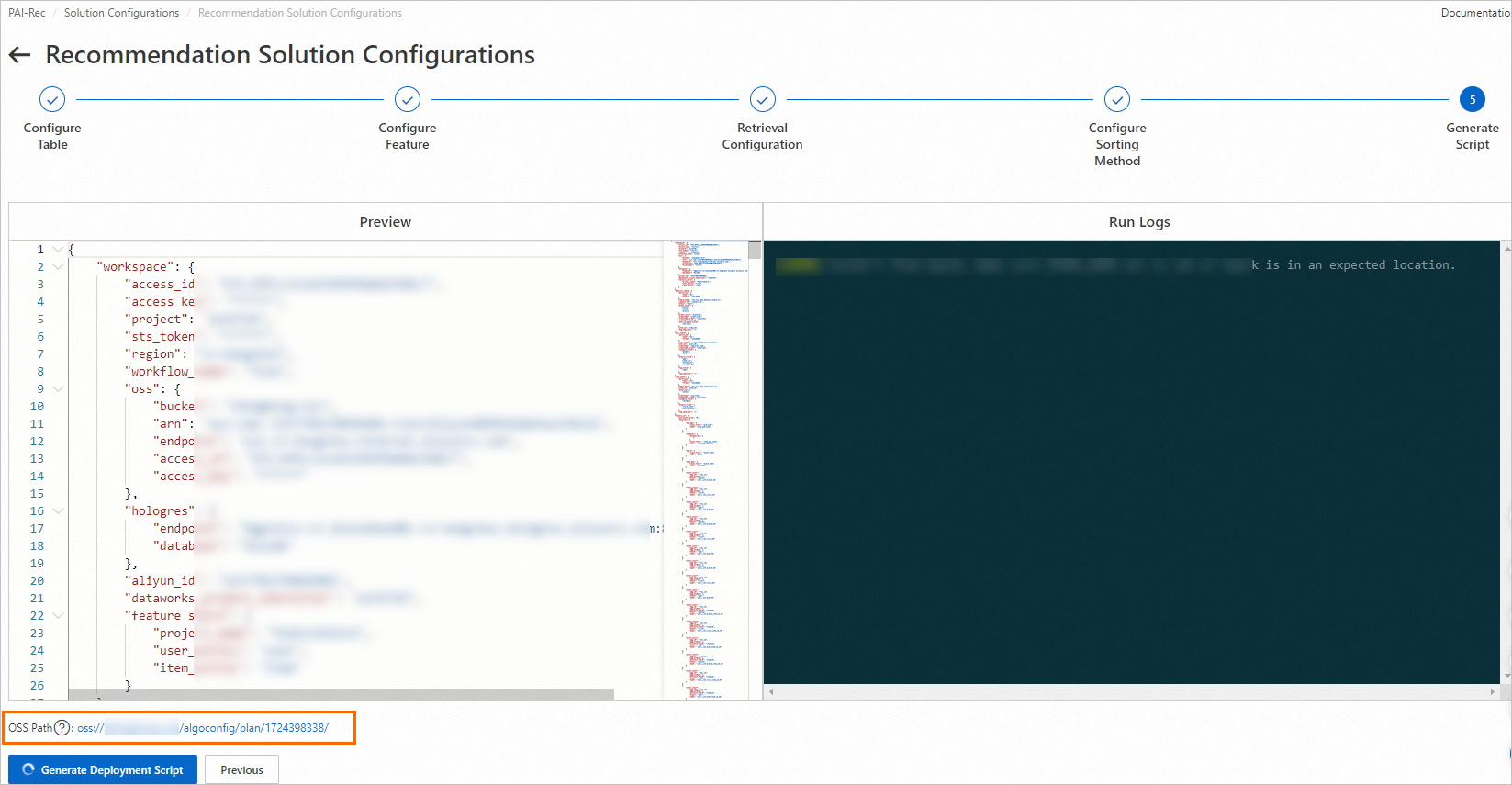
スクリプトの生成が完了したら、ダイアログボックスで[OK]をクリックします。[カスタムレコメンデーションソリューション] > [デプロイメントレコード]にリダイレクトされます。生成が失敗した場合は、実行ログを確認し、エラーを解決して、スクリプトを再生成します。
ステップ 6: レコメンデーションソリューションをデプロイする
スクリプトが生成されたら、2 つの方法のいずれかを使用して DataWorks にデプロイします。
方法 1: Personalized Recommendation Platform を介してデプロイする
対象のソリューションの横にある [デプロイに進む] をクリックします。
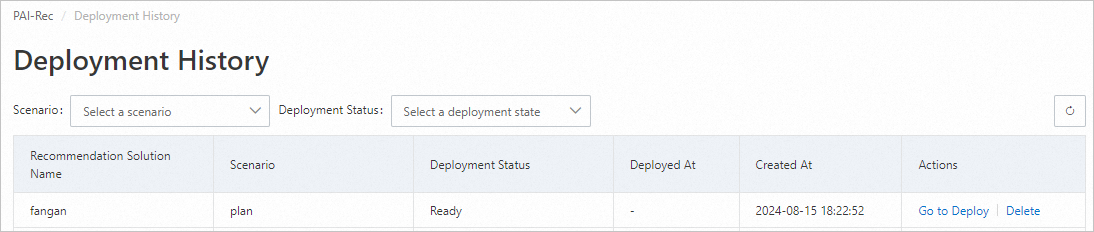
[デプロイメントのプレビュー] ページで、[ファイル差分] セクションで、デプロイするファイルを選択します。初回デプロイでは、[すべて選択] をクリックし、次に、[DataWorks へのデプロイ] をクリックします。ページは [デプロイメント記録] に戻り、デプロイが進行中であることが表示されます。

 をクリックしてリストを更新し、デプロイステータスを確認します。
をクリックしてリストを更新し、デプロイステータスを確認します。デプロイメントが失敗した場合は、[アクション] 列の [ログの表示] をクリックしてエラーを解決し、スクリプトを再生成して再デプロイします。
[デプロイメントステータス] が [成功] に変更されると、スクリプトがデプロイされます。DataWorks データ開発ページに移動して、デプロイされたコードを表示します。詳細については、「データ開発プロセスガイド」をご参照ください。
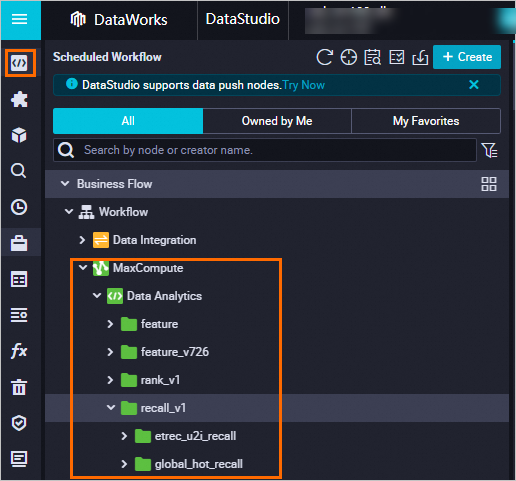
トレーニング用の既存データを投入するために、データバックフィルを実行します。
[デプロイメントレコード]ページで、正常にデプロイされたソリューションの横にある[詳細]をクリックします。
[デプロイメントのプレビュー] ページで、[タスクのデータバックフィルプロセスを表示] をクリックして、バックフィル手順を確認し、データ整合性を確保します。
ユーザーテーブル、アイテムテーブル、行動テーブルすべてに、トレーニング時間ウィンドウと最大特徴量時間ウィンドウの合計に等しい過去 _n_ 日間のデータが含まれていることを確認します。このチュートリアルのデモデータを使用している場合は、最新のデータパーティションを同期します。Python スクリプトでデータを生成した場合は、DataWorks オペレーションセンター経由でバックフィルします。
[デプロイメントタスクの作成] をクリックします。[バックフィルタスクリスト] の下で、[タスクを順次開始] をクリックします。すべてのタスクが正常に完了するまで待ちます。タスクが失敗した場合は、[詳細] をクリックしてログを表示し、エラーを解決してタスクを再実行してから、[続行] をクリックして次に進みます。
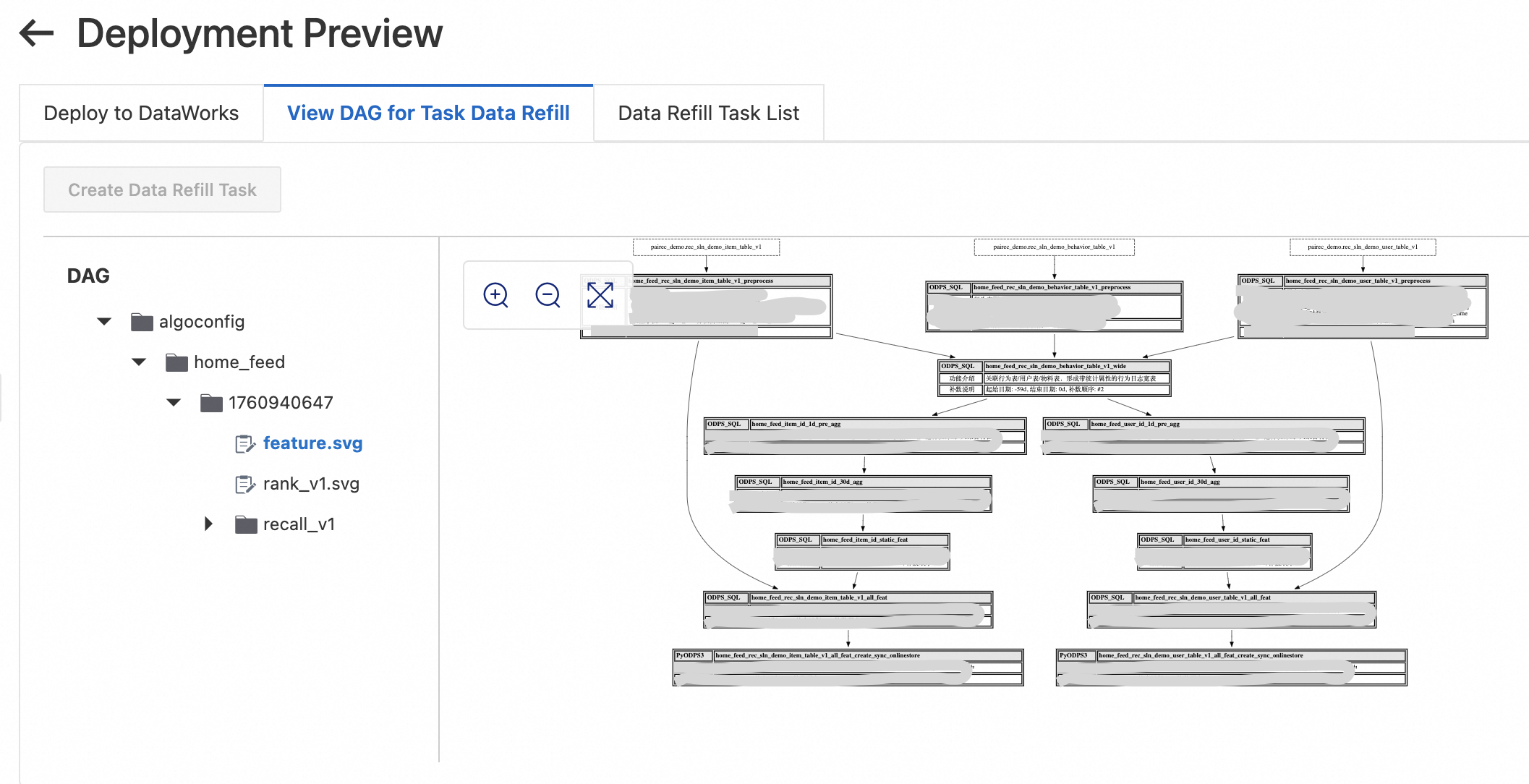
方法 2: Migration Assistant を使用してデプロイする
スクリプトが生成されたら、DataWorks Migration Assistant を介して手動でデプロイします。完全な手順については、「DataWorks インポートタスクを作成および表示する」をご参照ください。主要パラメーターは次のとおりです。
[インポート名]: コンソールに表示される指示に従って設定します。
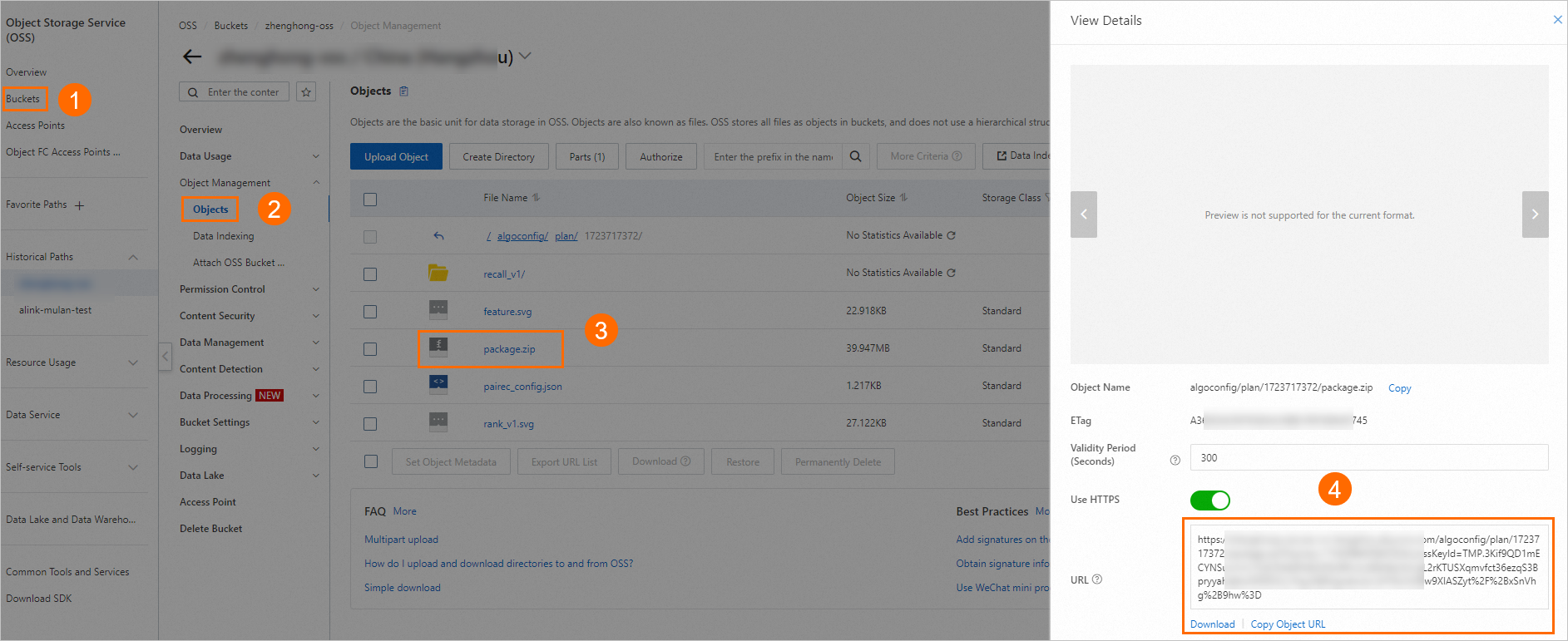
[アップロード方法]: [OSS ファイル] を選択し、手順 5 の [OSS リンク] を入力して、[検証] をクリックします。
デプロイメントパッケージは、ステップ 5 で生成された OSS アドレス (例: oss://examplebucket/algoconfig/plan/1723717372/package.zip) に保存されます。OSS コンソール にログインして、ファイル URL を取得します。
ステップ 7: ノードのフリーズ
このチュートリアルでは、デモデータを使用します。データバックフィルが完了したら、ステップ 2 で作成した 3 つの仮想ノードをフリーズして、日次スケジュールでの実行を防ぎます。
DataWorks オペレーションセンターで、[定期タスク O&M] > [定期タスク] を選択します。ノード名 (例: rec_sln_demo_user_table_v1) を検索し、対象ノード ([Workspace.Node name]) を選択して、[一時停止 (フリーズ)] を選択します。