ネイティブ Kubernetes ResourceQuota の静的リソース割り当てメカニズムは、クラスタのリソース使用率の低下につながる可能性があります。この問題を解決するために、Container Service for Kubernetes (ACK) は、スケジューリングフレームワーク拡張メカニズムに基づく容量スケジューリング機能を提供します。この機能は、弾性クォータグループを使用してリソースの共有をサポートすると同時に、ユーザーのリソースクォータを確保することで、クラスタのリソース使用率を効果的に向上させます。
前提条件
Kubernetes 1.20 以降を実行する ACK マネージド Pro クラスタ が作成されていること。クラスタをアップグレードするには、「ACK マネージドクラスターを作成する」をご参照ください。
主な機能
マルチユーザー クラスタ環境では、管理者はさまざまなユーザーに十分なリソースを確保するために、固定リソースを割り当てます。従来のモードでは、静的リソース割り当てにネイティブ Kubernetes ResourceQuota を使用します。ただし、ユーザー間でのリソース使用の時間とパターンの違いにより、一部のユーザーはリソースの制約を受ける一方で、他のユーザーはアイドル状態のクォータを持っている場合があります。これにより、全体的なリソース使用率が低下します。
この問題を解決するために、ACK はスケジューリングフレームワーク拡張メカニズムに基づいて、スケジューリング側で容量スケジューリング機能をサポートしています。この機能は、リソースの共有を使用して全体的なリソース使用率を向上させ、ユーザーへのリソース割り当てを保証します。容量スケジューリングの具体的な機能は次のとおりです。
さまざまなレベルでのリソースクォータの定義のサポート: 会社の組織図など、ビジネスニーズに応じて複数レベルの弾性クォータを構成します。弾性クォータグループのリーフノードは複数の名前空間に対応できますが、各名前空間は 1 つのリーフノードにのみ属することができます。
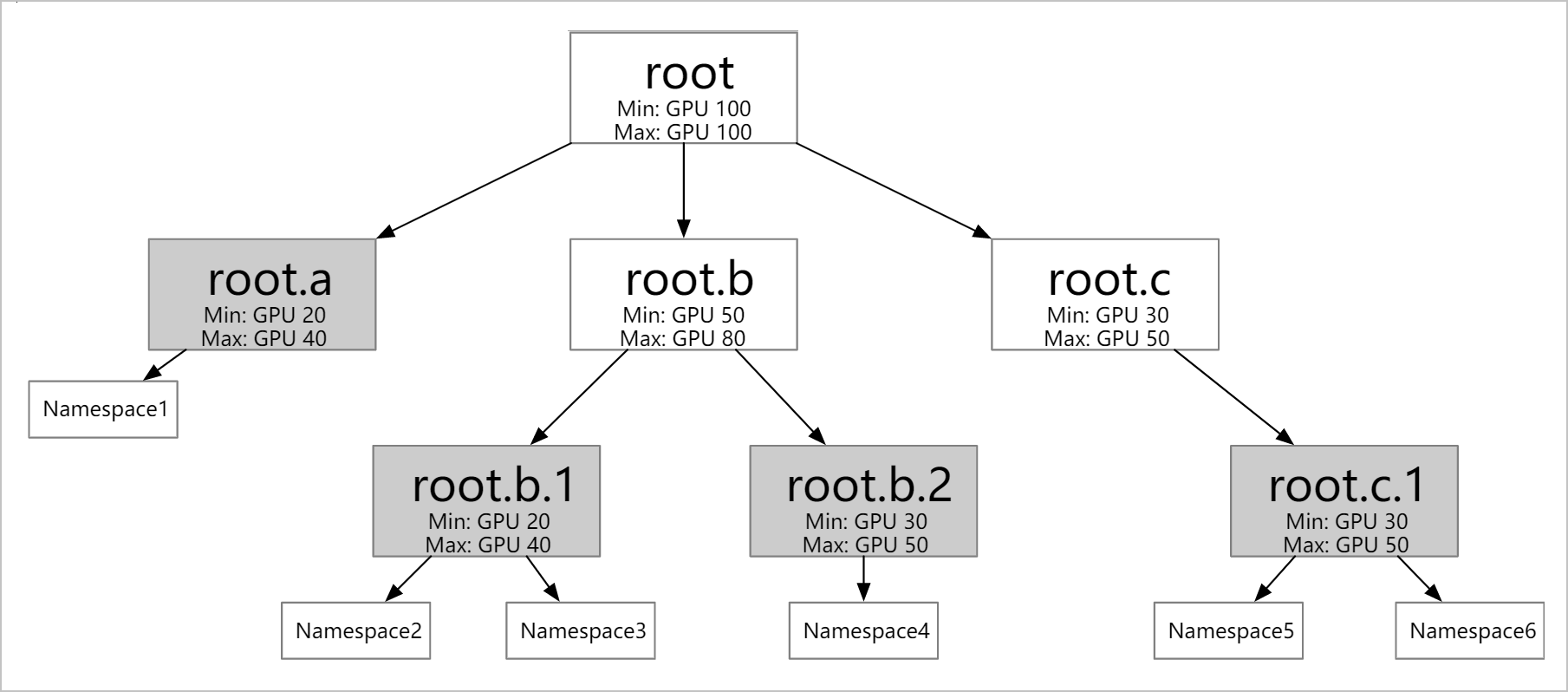
異なる弾性クォータ間でのリソースの借用と回収のサポート。
Min: 使用できる保証リソースを定義します。クラスタのリソースが不足した場合、すべてのユーザーの最小リソースの合計量は、クラスタのリソースの合計量よりも少なくなければなりません。
Max: 使用できるリソースの最大量を定義します。
ワークロードは他のユーザーからアイドル状態のリソースクォータを借用できますが、借用後に使用できるリソースの合計量は、依然として Max 値を超えません。未使用の Min リソースクォータは借用できますが、元のユーザーが使用する必要がある場合は回収できます。
さまざまなリソースの構成のサポート: CPU とメモリのリソースに加えて、GPU や Kubernetes でサポートされているその他の拡張リソースの構成もサポートしています。
ノードへのクォータのアタッチのサポート: ResourceFlavor を使用してノードを選択し、ResourceFlavor を ElasticQuotaTree のクォータに関連付けます。関連付けの後、弾性クォータ内のポッドは、ResourceFlavor によって選択されたノードにのみスケジュールできます。
容量スケジューリングの構成例
このクラスタ例では、ノードは 56 個の vCPU と 224 GiB のメモリを搭載した ecs.sn2.13xlarge マシンです。
次の名前空間を作成します。
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4次の YAML ファイルに従って、対応する弾性クォータグループを作成します。
上記の YAML ファイルに従って、
namespacesフィールドに対応する名前空間を構成し、childrenフィールドに対応する子弾性クォータを構成します。次の要件を満たす必要があります。同じ弾性クォータでは、Min ≤ Max。
子弾性クォータの Min 値の合計は、親クォータの Min 値以下である必要があります。
ルートノードの Min は Max と等しく、クラスタの総リソース以下です。
各名前空間は 1 つのリーフのみに属します。リーフには複数の名前空間を含めることができます。
弾性クォータグループが正常に作成されたかどうかを確認します。
kubectl get ElasticQuotaTree -n kube-system予期される出力:
NAME AGE elasticquotatree 68s
アイドル状態のリソースを借用する
次の YAML ファイルに従って、
namespace1にサービスをデプロイします。ポッドのレプリカ数は 5 で、各ポッドは 5 個の vCPU をリクエストします。クラスタ内のポッドのデプロイメントステータスを確認します。
kubectl get pods -n namespace1予期される出力:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 70s nginx1-744b889544-6l4s9 1/1 Running 0 70s nginx1-744b889544-cgzlr 1/1 Running 0 70s nginx1-744b889544-w2gr7 1/1 Running 0 70s nginx1-744b889544-zr5xz 0/1 Pending 0 70s現在のクラスタにはアイドル状態のリソースがあるため (
root.max.cpu=40)、namespace1内のポッドによってリクエストされた CPU リソースがroot.a.1によって構成された 10 (min.cpu=10) を超えると、ポッドは他のアイドル状態のリソースを借用し続けることができます。リクエストできる最大の CPU リソースは、root.a.1によって構成された 20 (max.cpu=20) です。ポッドによってリクエストされた CPU リソースの量が 20 (
max.cpu=20) を超えると、リソースをリクエストする追加のポッドはすべて Pending 状態になります。したがって、リクエストされた 5 つのポッドのうち、4 つは Running 状態、1 つは Pending 状態です。
次の YAML ファイルに従って、
namespace2にサービスをデプロイします。ポッドのレプリカ数は 5 で、各ポッドは 5 個の vCPU をリクエストします。クラスタ内のポッドのデプロイメントステータスを確認します。
kubectl get pods -n namespace1予期される出力:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 111s nginx1-744b889544-6l4s9 1/1 Running 0 111s nginx1-744b889544-cgzlr 1/1 Running 0 111s nginx1-744b889544-w2gr7 1/1 Running 0 111s nginx1-744b889544-zr5xz 0/1 Pending 0 111skubectl get pods -n namespace2予期される出力:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-4gl8s 1/1 Running 0 111s nginx2-556f95449f-crwk4 1/1 Running 0 111s nginx2-556f95449f-gg6q2 0/1 Pending 0 111s nginx2-556f95449f-pnz5k 1/1 Running 0 111s nginx2-556f95449f-vjpmq 1/1 Running 0 111snginx1と同様です。現在のクラスタにはアイドル状態のリソースがあるため (root.max.cpu=40)、namespace2内のポッドによってリクエストされた CPU リソースがroot.a.2によって構成された 10 (min.cpu=10) を超えると、ポッドは他のアイドル状態のリソースを借用し続けることができます。リクエストできる最大の CPU リソースは、root.a.2によって構成された 20 (max.cpu=20) です。ポッドによってリクエストされた CPU リソースの量が 20 (
max.cpu=20) を超えると、リソースをリクエストする追加のポッドはすべて Pending 状態になります。したがって、リクエストされた 5 つのポッドのうち、4 つは Running 状態、1 つは Pending 状態です。この時点で、クラスタ内の
namespace1とnamespace2のポッドによって占有されているリソースは、rootによって構成された 40 (root.max.cpu=40) に達しています。
借用したリソースを返却する
次の YAML ファイルに従って、
namespace3にサービスをデプロイします。ポッドのレプリカ数は 5 で、各ポッドは 5 個の vCPU をリクエストします。次のコマンドを実行して、クラスタ内のポッドのデプロイメントステータスを確認します。
kubectl get pods -n namespace1予期される出力:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 6m17s nginx1-744b889544-cgzlr 1/1 Running 0 6m17s nginx1-744b889544-nknns 0/1 Pending 0 3m45s nginx1-744b889544-w2gr7 1/1 Running 0 6m17s nginx1-744b889544-zr5xz 0/1 Pending 0 6m17skubectl get pods -n namespace2予期される出力:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-crwk4 1/1 Running 0 4m22s nginx2-556f95449f-ft42z 1/1 Running 0 4m22s nginx2-556f95449f-gg6q2 0/1 Pending 0 4m22s nginx2-556f95449f-hfr2g 1/1 Running 0 3m29s nginx2-556f95449f-pvgrl 0/1 Pending 0 3m29skubectl get pods -n namespace3予期される出力:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 4m nginx3-578877666-nfdwv 0/1 Pending 0 4m10s nginx3-578877666-psszr 0/1 Pending 0 4m11s nginx3-578877666-xfsss 1/1 Running 0 4m22s nginx3-578877666-xpl2p 0/1 Pending 0 4m10snginx3の弾性クォータroot.b.1のminパラメータは10に設定されています。構成されたminリソースが使用可能であることを保証するために、スケジューラは以前にroot.aの下のroot.bから借用されたポッドリソースを返却します。これにより、nginx3は少なくとも 10 (min.cpu=10) 個の CPU コアを取得して、動作を保証できます。スケジューラは、
root.aの下のジョブの優先度、可用性、作成時間などの要素を総合的に考慮し、以前に占有されていたリソース (10 個の vCPU) を返却する対応するポッドを選択します。したがって、nginx3が 10 (min.cpu=10) 個の CPU コアを取得した後、2 つのポッドは Running 状態になり、残りの 3 つは Pending 状態のままです。次の YAML ファイルに従って、
namespace4にサービスnginx4をデプロイします。ポッドのレプリカ数は 5 で、各ポッドは 5 個の CPU コアをリクエストします。次のコマンドを実行して、クラスタ内のポッドのデプロイメントステータスを確認します。
kubectl get pods -n namespace1予期される出力:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-cgzlr 1/1 Running 0 8m20s nginx1-744b889544-cwx8l 0/1 Pending 0 55s nginx1-744b889544-gjkx2 0/1 Pending 0 55s nginx1-744b889544-nknns 0/1 Pending 0 5m48s nginx1-744b889544-zr5xz 1/1 Running 0 8m20skubectl get pods -n namespace2予期される出力:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-cglpv 0/1 Pending 0 3m45s nginx2-556f95449f-crwk4 1/1 Running 0 9m31s nginx2-556f95449f-gg6q2 1/1 Running 0 9m31s nginx2-556f95449f-pvgrl 0/1 Pending 0 8m38s nginx2-556f95449f-zv8wn 0/1 Pending 0 3m45skubectl get pods -n namespace3予期される出力:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 8m46s nginx3-578877666-nfdwv 0/1 Pending 0 8m56s nginx3-578877666-psszr 0/1 Pending 0 8m57s nginx3-578877666-xfsss 1/1 Running 0 9m8s nginx3-578877666-xpl2p 0/1 Pending 0 8m56skubectl get pods -n namespace4予期される出力:
nginx4-754b767f45-g9954 1/1 Running 0 4m32s nginx4-754b767f45-j4v7v 0/1 Pending 0 4m32s nginx4-754b767f45-jk2t7 0/1 Pending 0 4m32s nginx4-754b767f45-nhzpf 0/1 Pending 0 4m32s nginx4-754b767f45-tv5jj 1/1 Running 0 4m32sminパラメーターのroot.b.2弾性クォータ(nginx4用)は10に設定されています。構成済みのminリソースが使用可能であることを保証するために、スケジューラはroot.a下のroot.bから以前に借用されたポッドリソースを返します。これにより、nginx4は、操作を保証するために少なくとも 10 (min.cpu=10) CPU コアを取得できます。スケジューラは、
root.a下のジョブの優先度、可用性、および作成時間などの要素を総合的に考慮し、対応するポッドを選択して、以前に占有されていたリソース (10 vCPU) を返します。そのため、nginx4が 10 (min.cpu=10) CPU コアを取得した後、2 つのポッドは実行中状態になり、残りの 3 つは保留中状態のままです。この時点で、クラスタ内のすべての弾性クォータは、
minで設定された保証リソースを使用しています。
ResourceFlavor 構成例
前提条件
ResourceFlavorCRD を参照して ResourceFlavor をインストールします (ACK Scheduler はデフォルトではインストールしません)。
ResourceFlavor リソースでは、nodeLabels フィールドのみが有効です。
スケジューラのバージョンが 6.9.0 以上であること。コンポーネントのリリースノートについては、「kube-scheduler」をご参照ください。コンポーネントのアップグレードエントリについては、「コンポーネント」をご参照ください。
ResourceFlavor は、Kubernetes カスタムリソース定義 (CRD) として、ノードラベル (NodeLabels) を定義することにより、弾性クォータとノード間のバインディング関係を確立します。特定の弾性クォータに関連付けられている場合、そのクォータの配下のポッドは、クォータリソースの総量によって制限されるだけでなく、NodeLabels と一致する目的のノードにのみスケジュールできます。
ResourceFlavor の例
ResourceFlavor の例を次に示します。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: "spot"
spec:
nodeLabels:
instance-type: spot弾性クォータを関連付ける例
弾性クォータを ResourceFlavor に関連付けるには、attributes フィールドを使用して ElasticQuotaTree で宣言する必要があります。次のコードは例を示しています。
apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system
spec:
root:
children:
- attributes:
resourceflavors: spot
max:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
min:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
name: child
namespaces:
- default
max:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
min:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
name: root送信後、クォータ child に属するポッドは、instance-type: spot ラベルが付いたノードにのみスケジュールされます。
参照資料
kube-scheduler のリリースレコードの詳細については、「kube-scheduler」をご参照ください。
kube-scheduler はギャングスケジューリングをサポートしています。これは、関連付けられたポッドのグループが同時に正常にスケジュールされる必要があることを意味します。そうでない場合、いずれもスケジュールされません。 kube-scheduler は、Spark や Hadoop などのビッグデータ処理タスクシナリオに適しています。詳細については、「ギャングスケジューリングの操作」をご参照ください。