このトピックでは、Nginx Ingress の問題の診断ワークフロー、トラブルシューティング方法、一般的なチェック、およびソリューションについて説明します。
目次
|
カテゴリ |
内容 |
|
診断プロセス |
|
|
トラブルシューティングのアプローチ |
|
|
一般的なトラブルシューティング方法 |
|
|
一般的な問題とソリューション |
背景情報
Kubernetes コミュニティは、公式の Ingress NGINX Controller をメンテナンスしています。ACK の Nginx Ingress Controller は、コミュニティバージョンを使用しており、すべてのコミュニティアノテーションをサポートしています。
Nginx Ingress リソースが正しく機能するためには、クラスターに Nginx Ingress Controller をデプロイして Ingress の転送ルールを解析する必要があります。Nginx Ingress Controller はリクエストを受信し、Ingress ルールと照合し、対応するバックエンドのサービス Pod に転送して処理します。Kubernetes におけるサービス、Nginx Ingress、Nginx Ingress Controller の関係は次のとおりです。
サービスはバックエンドサービスの抽象化です。1 つのサービスで、複数の同一のバックエンドサービスを表すことができます。
Nginx Ingress は、どのサービス Pod が HTTP または HTTPS リクエストを受信するかを指定するリバースプロキシルールを定義します。たとえば、リクエストは各リクエストのホストと URL パスに基づいて、異なるサービス Pod にルーティングされます。
Nginx Ingress Controller は、Nginx Ingress のリバースプロキシルールを解析する Kubernetes クラスター内のコンポーネントです。Ingress が追加、削除、または変更されると、Nginx Ingress Controller は直ちに転送ルールを更新します。コントローラーがリクエストを受信すると、これらのルールに基づいてリクエストを適切なサービス Pod に転送します。
Nginx Ingress Controller は API サーバーから Ingress リソースの変更を取得し、ロードバランサーに必要な設定ファイル (たとえば nginx.conf) を動的に生成し、ロードバランサーを再読み込み (たとえば、nginx -s reload を実行して Nginx を再読み込み) して新しいルーティングルールを適用します。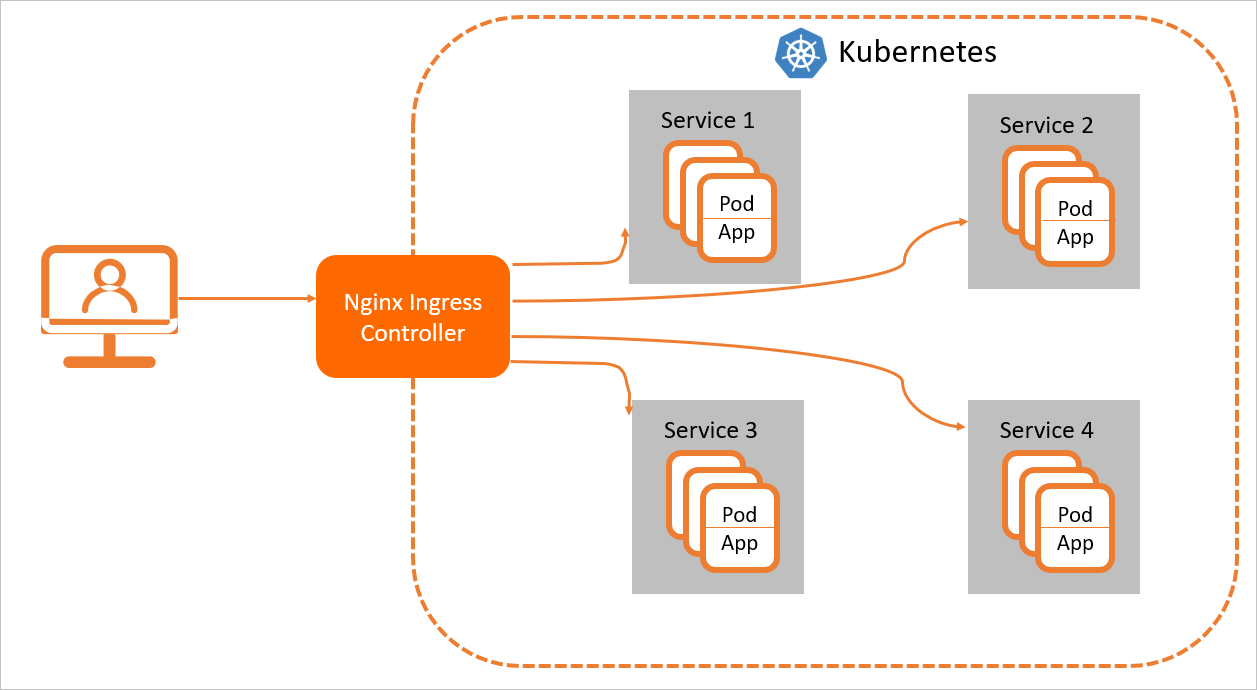
トラブルシューティングフロー
-
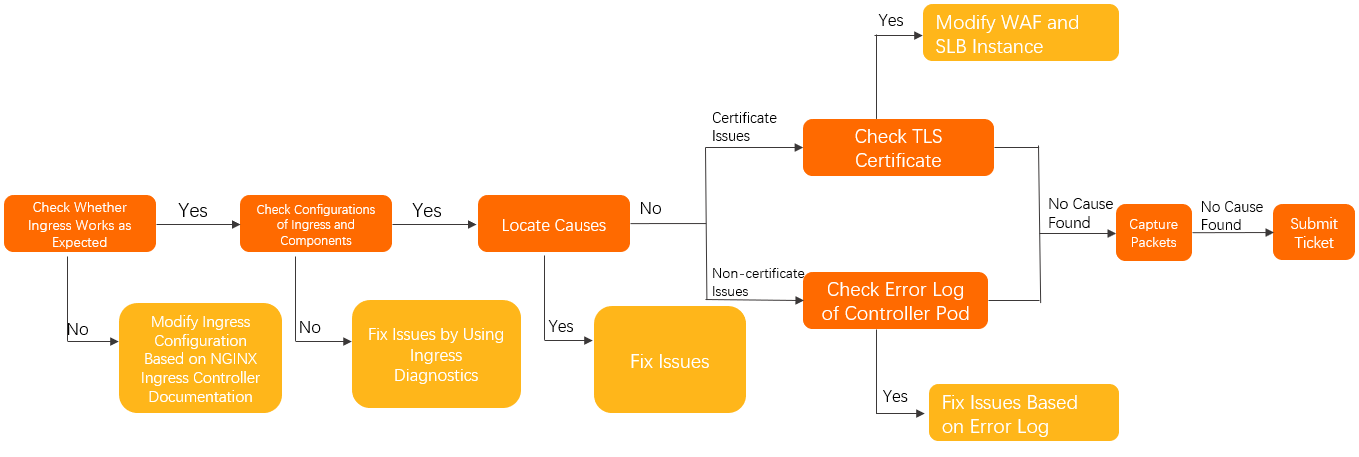
次のステップに従って、問題が Ingress にあるかを切り分け、Ingress コントローラーの設定を確認します。
-
コントローラー Pod で、アクセスが期待どおりに機能することを確認します。詳細については、「コントローラー Pod で Ingress およびバックエンド Pod に手動でアクセスする」をご参照ください。
-
NGINX Ingress Controller を正しく使用していることを確認します。詳細については、「NGINX Ingress Controller のコミュニティドキュメント」をご参照ください。
-
-
Ingress 診断機能を使用して Ingress およびコンポーネントの設定を確認し、推奨の変更を適用します。詳細なステップについては、「Ingress 診断機能の使用」をご参照ください。
-
トラブルシューティングガイドに従って、問題を診断し、解決します。
-
前のステップで問題が解決しない場合は、次の項目を確認します。
-
TLS 証明書の問題の場合:
-
ドメイン名で WAF またはトランスペアレント WAF 統合が有効になっているかどうかを確認します。
-
有効になっている場合は、WAF またはトランスペアレント WAF 統合に TLS 証明書が設定されていないことを確認してください。
-
有効になっていない場合は、次のステップに進みます。
-
-
SLB がレイヤー 7 リスナーを使用しているかどうかを確認します。
-
使用している場合は、レイヤー 7 リスナーに TLS 証明書が設定されていないことを確認してください。
-
使用していない場合は、次のステップに進みます。
-
-
-
TLS 証明書に関連しない問題の場合は、コントローラー Pod のエラーログを確認します。詳細については、「コントローラー Pod のエラーログの確認」をご参照ください。
-
-
問題が解決しない場合は、コントローラー Pod と対応するアプリケーション Pod でパケットキャプチャを実行し、根本原因を特定します。詳細については、「パケットキャプチャ」をご参照ください。
トラブルシューティング
|
問題領域 |
症状 |
解決策 |
|
アクセス失敗 |
クラスター内の Pod から Ingress にアクセスできません。 |
|
|
Ingress が自身にアクセスできません。 |
||
|
TCP または UDP Service にアクセスできません。 |
||
|
HTTPS アクセスの問題 |
Ingress が古い証明書、またはデフォルトの証明書を提供しています。 |
|
|
|
||
|
Ingress リソース作成時の問題 |
"failed calling webhook..." エラーが発生します。 |
|
|
Ingress は作成されますが、有効になりません。 |
||
|
想定外のアクセス動作 |
クライアントのソース IP を取得できません。 |
|
|
IP 許可リストが有効にならない、または想定どおりに動作しません。 |
||
|
Ingress で公開されている gRPC Service に接続できません。 |
||
|
カナリアリリースが有効になりません。 |
||
|
誤ったカナリアルールにより、トラフィックが正しくルーティングされません。 |
トラフィックのルーティングがカナリアルールと一致しない、または意図しないトラフィックがカナリア Service にルーティングされる |
|
|
|
||
|
502、503、413、または 499 などのエラーが発生します。 |
||
|
ページ上の一部のリソースの読み込み失敗 |
|
|
|
リソースリクエストで |
一般的なトラブルシューティング方法
Ingress 診断の使用
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
-
[診断] ページで、[Ingress 診断] をクリックします。
-
[Ingress 診断] パネルで、診断 をクリックし、問題が発生している URL (https://www.example.com など) を入力します。「同意する」を選択してから、診断開始 をクリックします。
診断が完了したら、結果に基づいて問題を解決します。
Log Service での controller Pod ログの表示
Ingress controller のアクセスログのフォーマットは、ConfigMap で定義されています。デフォルトでは、kube-system 名前空間の nginx-configuration ConfigMap です。
デフォルトでは、ACK Ingress controller は次のログフォーマットを使用します。
$remote_addr - [$remote_addr] - $remote_user [$time_local]
"$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length
$request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length
$upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name]ログフォーマットを変更する場合は、Log Service のログ収集ルールも更新する必要があります。そうしないと、Log Service コンソールでログが正しく表示されません。ログフォーマットを変更する際は、十分に注意してください。
Ingress controller のログは、Log Service コンソールで確認できます。詳細については、「ACK クラスターからコンテナログを収集する」をご参照ください。
Log Service コンソールの Raw ログ タブでは、各 Ingress controller ログエントリがキーと値のペアとして表示されます。各ログエントリには、HTTP アクセスフィールドに加えて、_container_name_、_namespace_、_pod_name_ などの Kubernetes メタデータフィールドが含まれます。
Log Service コンソールの一部のフィールド名は、実際のログのフィールド名とは異なります。次の表に、フィールドとその説明を示します。
|
フィールド |
説明 |
|
|
クライアントの実際の IP アドレス。 |
|
|
リクエストメソッド、URL、HTTP バージョンを含むリクエスト情報。 |
|
|
クライアントから最初のバイトを受信してから、レスポンスの最後のバイトを送信するまでの合計リクエスト時間。この値は、クライアントのネットワーク状態などの要因の影響を受ける可能性があり、リクエストの実際の処理速度を表すものではありません。 |
|
|
バックエンドアップストリームのアドレス。リクエストがバックエンドに到達しなかった場合、このフィールドは空になります。リクエストが複数のアップストリームに対してリトライされた場合、それらのアドレスがカンマ (,) 区切りで一覧表示されます。 |
|
|
バックエンドアップストリームから返された HTTP ステータスコード。標準の HTTP ステータスコードは、レスポンスがバックエンドアップストリームからのものであることを示します。利用可能なバックエンドがない場合、値は 502 になります。リクエストが複数のアップストリームに対してリトライされた場合、それらのステータスコードがカンマ (,) 区切りで一覧表示されます。 |
|
|
バックエンドアップストリームのレスポンス時間 (秒単位)。 |
|
|
バックエンドアップストリームの名前。命名形式は |
|
|
代替アップストリームの名前。リクエストがカナリア Service などの代替アップストリームにルーティングされた場合、このフィールドは空ではありません。 |
デフォルトでは、次のコマンドを実行して、コンテナ内で最近のアクセスログを直接表示することもできます。
kubectl logs <controller-pod-name> -n <namespace> | less出力例:
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:30 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 46b79dkahflhakjhdhfkah**** 47.11.**.**[]
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:31 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 fadgrerthflhakjhdhfkah**** 47.11.**.**[]controller Pod のエラーログの確認
Ingress controller Pod のログを調べて、問題を絞り込みます。controller Pod のエラーログは 2 つのタイプに分かれます。
-
コントローラーエラーログ:これらのログは、通常、Ingress 設定にエラーがある場合に生成されます。次のコマンドを実行して、コントローラーエラーログをフィルタリングします。
kubectl logs <controller-pod-name> -n <namespace> | grep -E ^[WE]説明Ingress controller の起動時に、いくつかの警告 (W) ログエントリが生成されることがあります。これは正常です。たとえば、kubeConfig の欠落や Ingress クラスの未指定に関する警告は、Ingress controller の正常な動作に影響を与えないため、無視できます。
-
Nginx エラーログ:これらのログは、リクエスト処理中にエラーが発生した場合に生成されます。次のコマンドを実行して、Nginx エラーログをフィルタリングします。
kubectl logs <controller-pod-name> -n <namespace> | grep error
Ingress とバックエンド Pod へのアクセス
-
次のコマンドを実行して、controller Pod のシェルを取得します。
kubectl exec <controller-pod-name> -n <namespace> -it -- bash -
curl や OpenSSL などのツールは、Pod にあらかじめインストールされています。これらのツールを使用して、接続性をテストし、証明書設定を確認できます。
-
次のコマンドを実行して、Ingress 経由でバックエンドへのアクセスをテストします。
# your.domain.com をテスト対象のドメイン名に置き換えます。 curl -H "Host: your.domain.com" http://127.0.0.1/ # http の場合 curl --resolve your.domain.com:443:127.0.0.1 https://127.0.0.1/ # https の場合 -
次のコマンドを実行して、証明書情報を確認します。
openssl s_client -servername your.domain.com -connect 127.0.0.1:443 -
バックエンド Pod にアクセスして、その動作を確認します。
説明Ingress controller は、Service の ClusterIP を使用してバックエンド Pod にアクセスしません。代わりに、Pod IP に直接アクセスします。
-
次のコマンドを実行して、バックエンド Pod の IP アドレスを取得します。
kubectl get pod -n <namespace> <pod-name> -o wide出力例:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-dp-7f5fcc7f-**** 1/1 Running 0 23h 10.71.0.146 cn-beijing.192.168.**.** <none> <none>出力は、バックエンド Pod の IP アドレスが 10.71.0.146 であることを示しています。
-
controller Pod で次のコマンドを実行して、バックエンド Pod にアクセスし、接続が機能していることを確認します。
curl http://<your-pod-ip>:<port>/path
-
-
Nginx Ingress のトラブルシューティングコマンド
-
kubectl-plugin
公式の Kubernetes Ingress controller は、もともと Nginx をベースにしていましたが、バージョン 0.25.0 で OpenResty に切り替わりました。コントローラーは、API サーバー上の Ingress リソースの変更を監視し、対応する Nginx 設定を自動的に生成してから、Nginx を再読み込みして変更を適用します。詳細については、「公式ドキュメント」をご参照ください。
Ingress リソースが増えるにつれて、すべての設定が 1 つの長い nginx.conf ファイルに統合され、デバッグが困難になります。バージョン 0.14.0 以降、アップストリームセクションは lua-resty-balancer を使用して動的に生成されるため、デバッグはさらに複雑になっています。これに対処するため、コミュニティは kubectl プラグイン ingress-nginx を提供することで、ingress-nginx 設定のデバッグプロセスを簡素化しました。詳細については、「kubectl-plugin」をご参照ください。
次のコマンドを実行して、ingress-nginx controller が現在認識しているバックエンドサービスに関する情報を取得します。
kubectl ingress-nginx backends -n ingress-nginx -
dbg コマンド
kubectl プラグインに加えて、
dbgコマンドを使用して情報を表示し、診断を実行できます。-
次のコマンドを実行して、Nginx Ingress コンテナのシェルを取得します。
kubectl exec -it -n kube-system <nginx-ingress-pod-name> -- bash -
/dbgを実行すると、次のような出力が表示されます。nginx-ingress-controller-69f46d8b7-qmt25:/$ /dbg dbg is a tool for quickly inspecting the state of the nginx instance Usage: dbg [command] Available Commands: backends Inspect the dynamically-loaded backends information certs Inspect dynamic SSL certificates completion Generate the autocompletion script for the specified shell conf Dump the contents of /etc/nginx/nginx.conf general Output the general dynamic lua state help Help about any command Flags: -h, --help help for dbg --status-port int Port to use for the lua HTTP endpoint configuration. (default 10246) Use "dbg [command] --help" for more information about a command.
特定のドメイン名の証明書が存在するかどうかを確認します。
/dbg certs get <hostname>すべてのバックエンドサービス情報を一覧表示します。
/dbg backends all -
Nginx Ingress のステータス
Nginx には、ランタイム統計を出力する組み込みのステータスエンドポイントが用意されています。Nginx Ingress コンテナ内で、curl を使用してポート 10246 の nginx_status エンドポイントにアクセスし、リクエストと接続の統計を表示できます。
-
次のコマンドを実行して、Nginx Ingress コンテナのシェルを取得します。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash -
次のコマンドを実行して、Nginx の現在のリクエストと接続の統計を表示します。
nginx-ingress-controller-79c5b4d87f-xxx:/etc/nginx$ curl localhost:10246/nginx_status Active connections: 12865 server accepts handled requests 22717127 22717127 823821421 Reading: 0 Writing: 382 Waiting: 12483起動以降、Nginx は 22,717,127 件の接続を処理し、823,821,421 件のリクエストを処理しました。これは、接続あたり平均して約 36.2 件のリクエストを処理したことになります。
-
Active connections:アクティブな接続の合計数。この例では、値は 12,865 です。
-
Reading:Nginx が現在リクエストヘッダーを読み取っている接続の数。この例では、値は 0 です。
-
Writing:Nginx が現在レスポンスを送信している接続の数。この例では、値は 382 です。
-
Waiting:キープアライブ接続の数。この例では、値は 12,483 です。
-
パケットキャプチャ
問題の原因を特定できない場合は、パケットキャプチャを実行します。
-
初期調査結果に基づいて、ネットワークの問題が Ingress Pod とアプリケーション Pod のどちらにあるかを判断します。十分な情報がない場合は、両方の Pod でパケットをキャプチャできます。
-
影響を受けるアプリケーション Pod または Ingress Pod をホストしているノードにログインします。
-
ECS インスタンス上 (コンテナ内ではなく) で、次のコマンドを実行して、特定の Pod に関連するトラフィックをキャプチャし、ファイルに保存します。
tcpdump -i any host <Ingress-pod-IP-or-application-pod-IP> -C 20 -W 200 -w /tmp/ingress.pcap -
ログを監視します。予想されるエラーが発生したら、パケットキャプチャを停止します。
-
キャプチャされたパケット情報とアプリケーションエラーログを照らし合わせて、問題を特定します。
説明-
通常の状況では、パケットキャプチャはサービスに影響を与えません。わずかな CPU 負荷とディスク I/O が追加されるだけです。
-
上記のコマンドは、キャプチャファイルをローテーションします。最大 200 個の .pcap ファイルが生成され、各ファイルのサイズは 20 MB です。
-
クラスター内から外部ロードバランサーのアドレスへのアクセス失敗
現象
クラスターでは、一部のノード上の Pod は Nginx Ingress Controller の外部アドレス (ロードバランサーインスタンスの IP アドレス) を介してバックエンド Pod にアクセスできませんが、他のノード上の Pod はアクセスできます。
原因
この問題は、コントローラーの Service の externalTrafficPolicy 設定が原因で発生します。この設定は、外部トラフィックの処理方法を決定します。Local に設定すると、コントローラー Pod と同じノード上のバックエンド Pod のみがリクエストを受信できます。Cluster に設定すると、すべてのバックエンド Pod に正常にアクセスできます。クラスター内のリソースがロードバランサー Service の外部アドレスを使用する場合、そのリクエストも外部トラフィックとして扱われます。
解決策
-
(推奨) Kubernetes クラスター内から、Service の ClusterIP またはサービス名を使用して Service にアクセスします。Ingress のサービス名は
nginx-ingress-lb.kube-systemです。 -
kubectl edit svc nginx-ingress-lb -n kube-systemコマンドを実行して、Ingress Service を編集します。ロードバランサー Service のexternalTrafficPolicyをClusterに変更します。クラスターの CNI プラグインが Flannel の場合、クライアントソース IP は失われます。Terway を使用する場合、クライアントソース IP は保持されます。
-
例:
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/backend-type: eni # ENI に直接 labels: app: nginx-ingress-lb name: nginx-ingress-lb namespace: kube-system spec: externalTrafficPolicy: ClusterService のアノテーションの詳細については、「アノテーションを使用した Classic Load Balancer (CLB) の設定」をご参照ください。
Ingress コントローラーにアクセスできない
現象
Flannel クラスターでは、Ingress Pod からドメイン名、SLB IP、または ClusterIP を介して Ingress にアクセスすると、一部またはすべてのリクエストが失敗します。
原因
デフォルトの Flannel 設定では、ヘアピンが無効になっています。
解決策
-
(推奨) Terway ネットワークプラグインを使用してクラスターを再作成し、ワークロードを新しいクラスターに移行します。
-
クラスターを再作成できない場合は、Flannel の設定を変更して
hairpinModeを有効にします。設定を変更した後、Flannel Pod を再作成して変更を適用します。-
次のコマンドを実行して、Flannel の設定を編集します。
kubectl edit cm kube-flannel-cfg -n kube-system -
出力のcni-conf.json セクションで、
delegateオブジェクトに"hairpinMode": trueを追加します。例:
cni-conf.json: | { "name": "cb0", "cniVersion":"0.3.1", "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true } } -
次のコマンドを実行して、Flannel Pod を削除します。システムは新しい設定で自動的にそれらの Pod を再作成します。
kubectl delete pod -n kube-system -l app=flannel
-
デフォルトまたは古いTLS証明書が返され続ける
現象
クラスター内で Secret を追加または変更し、Ingress で secretName を指定した後も、リクエストに対してデフォルトの証明書 (Kubernetes Ingress Controller Fake Certificate) または古い証明書が返され続けます。
原因
-
クラスター内の Ingress コントローラーから証明書が返されていません。
-
証明書が無効なため、コントローラーが証明書を正しく読み込めていません。
-
Ingress コントローラーは SNI (Server Name Indication) を使用して正しい証明書を返しますが、TLS ハンドシェイクに SNI 拡張が含まれていない可能性があります。
解決策
-
次のいずれかの方法を使用して、TLS ハンドシェイクに SNI 拡張が含まれていることを確認してください。
-
SNI をサポートする最新のブラウザを使用してください。
-
openssl s_clientコマンドで証明書をテストする際に、-servernameパラメータを含めてください。 -
curlを使用する場合は、Hostヘッダーを指定して IP アドレスにリクエストを送信するのではなく、--resolveパラメータを使用するか、hosts ファイルを編集してドメイン名をマッピングしてください。
-
-
WAF、WAF 透過的アクセス、または SLB レイヤー7 リスナーに TLS 証明書が設定されていないことを確認してください。TLS 証明書は、クラスター内の Ingress コントローラーから返される必要があります。
-
インテリジェント運用コンソールで Ingress 診断を実行して、設定の問題とエラーログを確認してください。詳細については、「Ingress 診断を使用する」をご参照ください。
-
次のコマンドを実行して、Ingress Pod のエラーログを手動で確認し、ログに記載されている提案に基づいて変更を行ってください。
kubectl logs <ingress pod name> -n <pod 名前空間> | grep -E ^[EW]
Ingress 経由で gRPC に接続できない
症状
Ingress 経由で gRPC サービスにアクセスできません。
原因
-
Ingress リソースにバックエンドプロトコルのアノテーションがありません。
-
gRPC サービスは、Ingress 経由で公開される場合、TLS 接続を必要とします。
解決策
-
Ingress リソースに次のアノテーションを追加します:
nginx.ingress.kubernetes.io/backend-protocol: "GRPC"。 -
クライアントが TLS ポート経由で暗号化トラフィックを送信するようにしてください。
バックエンド HTTPS Service に接続できない
症状
-
Ingress の背後にある HTTPS Service にアクセスできません。
-
リクエストに対し、
The plain HTTP request was sent to HTTPS portというメッセージを含む 400 ステータスコードが返される場合があります。
原因
Ingress コントローラーはデフォルトで、バックエンド Pod に HTTP リクエストを送信します。
解決策
Ingress リソースに次のアノテーションを設定してください: nginx.ingress.kubernetes.io/backend-protocol:"HTTPS"。
Ingress Pod で送信元 IP を保持できない
症状
クライアントの送信元 IP アドレスが Ingress Pod で保持されません。代わりに、アプリケーションはノードの IP アドレスや 100.XX.XX.XX 範囲のアドレスなどの内部 IP アドレスを受信します。
原因
-
Ingress を公開するサービスの
externalTrafficPolicyはClusterに設定されています。 -
サーバーロードバランサー (SLB) インスタンスがレイヤー 7 プロキシとして設定されています。
-
Web アプリケーションファイアウォール (WAF) または透過型 WAF サービスが使用されています。
解決策
-
お使いのサービスの
externalTrafficPolicyがClusterに設定されており、レイヤー 4 SLB インスタンスによって公開されている場合:externalTrafficPolicyをLocalに変更します。この変更により、クラスター内のポッドが SLB IP アドレスを介して Ingress にアクセスできなくなる可能性があります。解決策については、「クラスター内からクラスター LoadBalancer の外部アドレスにアクセスできない」をご参照ください。 -
レイヤー 7 SLB インスタンス、WAF、または透過型 WAF などのレイヤー 7 プロキシを使用する場合は、次の手順に従ってください。
-
レイヤー 7 プロキシが X-Forwarded-For リクエストヘッダーを追加するように設定されていることを確認してください。
-
Ingress Controller ConfigMap (デフォルトでは kube-system 名前空間の nginx-configuration) に、
enable-real-ip: "true"を追加します。 -
ログをチェックして、送信元 IP が保持されていることを確認してください。
-
-
トラフィックパスに、Ingress コントローラーの前段にある追加のリバースプロキシサービスなど、複数の転送ステップが含まれる場合は、
enable-real-ipを有効にし、ログでremote_addrフィールドの値を確認します。これにより、Ingress コンテナーが X-Forwarded-For リクエストヘッダーでクライアントのソース IP アドレスを受信しているかどうかを確認できます。受信していない場合は、リクエストが Ingress コントローラーに到達する前に、たとえば X-Forwarded-For ヘッダーにソース IP アドレスを追加するなどして、リクエストに含めるようにしてください。
カナリア ルールが有効にならない
症状
クラスターでカナリアリリースを設定しましたが、カナリア ルールが有効になりません。
原因
-
canary-*アノテーションを使用する際に、nginx.ingress.kubernetes.io/canary: "true"アノテーションが設定されていません。 -
Nginx Ingress Controller のバージョン 0.47.0 より前では、Ingress ルールの
Hostフィールドにサービスドメイン名を含む必要があり、空にすることはできません。
ソリューション
-
nginx.ingress.kubernetes.io/canary: "true"アノテーションがない場合は追加します。Nginx Ingress Controller のバージョンが 0.47.0 より前で Host フィールドが空の場合は、Ingress ルールの Host フィールドをサービスドメイン名に設定します。詳細については、「ルーティングルール」をご参照ください。 -
これらのシナリオが該当しない場合は、「カナリアリリースルールで設定されたとおりにトラフィックが分散されない、またはトラフィックがカナリアサービスにルーティングされる」をご参照ください。
意図しないトラフィックのカナリア Service へのルーティング
症状
カナリア ルールを設定しましたが、トラフィックが指定どおりに分散されません。また、他の標準 Ingress からのトラフィックがカナリア Service にルーティングされることがあります。
原因
Nginx Ingress Controller は、カナリア ルールを単一の Ingress ではなく、同じ Service を共有するすべての Ingress に適用します。
この動作の詳細については、「カナリア ルールを持つ Ingress が同じ Service を共有するすべての Ingress に影響する」をご参照ください。
解決策
Ingress (service-match や関連する canary-* アノテーションを使用する場合を含め) のカナリアリリースを有効にするには、既存の Pod を指す専用 Service (安定 Service とカナリア Service の 2 つ) を作成します。次に、その特定の Ingress でカナリア ルールを有効にします。詳細については、「Nginx Ingress を使用してカナリアリリースとブルーグリーンデプロイメントを実装する」をご参照ください。
Ingress の作成時のエラー:「failed calling webhook」
現象
Ingress リソースを作成すると、「Internal error occurred: failed calling webhook...」というエラーが表示されます。
完全なエラーコードは APISERVER_500 です。詳細なメッセージは Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": POST https://ingress-nginx-controller-admission.kube-system.svc:443/networking/v1beta1/ingresses?timeout=10s: context deadline exceeded です。「context deadline exceeded」というフレーズは、根本原因である Webhook 呼び出しのタイムアウトを示しています。
原因
Ingress リソースを作成する際、Service (デフォルトでは ingress-nginx-controller-admission) がその設定を検証する必要があります。呼び出しチェーン内のコンポーネント (たとえば、Service または Ingress コントローラーが削除された場合など) が利用できない場合、検証は失敗し、API サーバーは Ingress リソースを拒否します。
解決策
-
Webhook の呼び出しチェーンをチェックして、必要なすべてのリソースが正しく実行されているかを確認してください。チェーンは、ValidatingWebhookConfiguration → Service → Pod です。
-
Ingress コントローラーの Pod でアドミッション機能が有効になっており、外部からアクセス可能であるかを確認してください。
-
Ingress コントローラーが削除された場合、または Webhook 機能が不要な場合は、ValidatingWebhookConfiguration リソースを削除してください。
HTTPS アクセス時の SSL_ERROR_RX_RECORD_TOO_LONG エラー
症状
HTTPS でアクセスすると、SSL_ERROR_RX_RECORD_TOO_LONG または routines:CONNECT_CR_SRVR_HELLO:wrong version number というエラーが発生します。
原因
HTTPS リクエストが、HTTP ポートなどの HTTPS 以外のポートに送信されています。
一般的な原因は次のとおりです。
-
SLB のポート 443 が Ingress Pod のポート 80 にマッピングされています。
-
Ingress controller Service のポート 443 が Ingress Pod のポート 80 にマッピングされています。
解決策
SLB または Service の設定を変更し、HTTPS トラフィックが正しいポートにルーティングされるようにしてください。
一般的な HTTP エラーコード
症状:
リクエストは 502、503、413、499 など、2xx または 3xx 以外のエラーを返します。
原因と解決策:
アクセスログを確認し、エラーが Ingress コントローラーから返されたものかどうかを判断します。詳細については、「Log Service を使用して NGINX Ingress コントローラーのアクセスログを表示する」をご参照ください。その場合は、次の解決策を参照してください。
-
413 エラー:
-
原因:NGINX Ingress コントローラーは正常に動作していますが、リクエストデータのサイズが許可された上限を超えています。
-
解決策:
kubectl edit cm -n kube-system nginx-configurationを実行して、コントローラーの設定を変更します。必要に応じてnginx.ingress.kubernetes.io/client-max-body-sizeとnginx.ingress.kubernetes.io/proxy-body-sizeの値を調整します (デフォルト:20 m)。
-
-
499 エラー:
-
原因:クライアントが途中で切断しました。これは必ずしもコンポーネントまたはバックエンドサービスに問題があることを示すものではありません。
-
解決策:
-
アプリケーションによっては、少数の 499 エラーは正常であり、無視できます。
-
多数の 499 エラーが発生する場合は、バックエンドサービスの処理時間とクライアント側のリクエストタイムアウトが想定どおりに設定されているかどうかを確認します。
-
-
-
502 エラー:
-
原因:NGINX Ingress コントローラーは正常に動作していますが、コントローラー Pod がターゲットのバックエンド Pod に接続できません。
-
解決策:
-
エラーが常に発生する場合:
-
バックエンド Service または Pod の設定が正しくない場合、このエラーが発生する可能性があります。バックエンド Service のポート設定と、コンテナ内のアプリケーションコードを確認します。
-
-
エラーが断続的に発生する場合:
-
NGINX Ingress コントローラー Pod の負荷が高い場合、このエラーが発生する可能性があります。コントローラーに関連付けられたロードバランサーインスタンスのリクエスト数と接続数を確認することで、負荷を評価できます。コントローラーにより多くのリソースを割り当てるには、「高負荷シナリオ向けに NGINX Ingress コントローラーを設定する」をご参照ください。
-
このエラーは、バックエンド Pod がセッションをアクティブに閉じた場合に発生する可能性があります。NGINX Ingress コントローラーは、デフォルトで永続的な接続を有効にします。バックエンドの永続的な接続のアイドルタイムアウト期間が、コントローラーのアイドルタイムアウト期間 (デフォルト:900 秒) よりも長いことを確認します。
-
-
上記の方法で問題を特定できない場合は、分析のためにパケットキャプチャを実行します。
-
-
-
503 エラー:
-
原因:Ingress コントローラーがバックエンド Pod を見つけられないか、すべてのバックエンド Pod に到達できません。
-
解決策:
-
エラーが断続的に発生する場合:
-
502 エラーの解決策を参照してください。
-
バックエンド Service の Readiness 状態を確認し、適切なヘルスチェックを設定します。
-
-
エラーが常に発生する場合:
バックエンド Service が正しく設定されており、エンドポイントがあるかどうかを確認します。
-
-
net::ERR_HTTP2_SERVER_REFUSED_STREAM エラー
症状
一部のリソースのロードに失敗し、ブラウザーの開発者コンソールに net::ERR_HTTP2_SERVER_REFUSED_STREAM または net::ERR_FAILED エラーが表示されます。
原因
同時リソースリクエストの数が、HTTP/2 接続の最大ストリーム制限を超えています。
解決策
-
(推奨) ConfigMap で、
http2-max-concurrent-streams(デフォルト:128) をワークロードに適した値に増やします。詳細については、「http2-max-concurrent-streams」をご参照ください。 -
または、HTTP/2 サポートを無効にするには、ConfigMap で
use-http2をfalseに設定します。詳細については、「use-http2」をご参照ください。
エラー:「The param of ServerGroupName is illegal」
原因
ServerGroupName は namespace+svcName+port のフォーマットです。サーバーグループ名は 2~128 文字である必要があり、文字または漢字で始まり、数字、ピリオド (.)、アンダースコア (_)、ハイフン (-) を含めることができます。
解決策
命名規則に従ってサーバーグループ名を変更してください。
Ingress 作成エラー: "certificate signed by unknown authority"
Ingress を作成すると、クラスターはエラーコード APISERVER_500 と次のメッセージを返します: Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": Post https://ingress-nginx-controller-admission.kube-system.svc:443/networking/v1beta1/ingresses?timeout=10s: x509: certificate signed by unknown authority
原因
このエラーは、クラスター内の複数の Ingress Deployment が Secret、Service、または Webhook 設定などのリソースを共有している場合に発生します。このリソースの重複により、Admission Webhook がバックエンドサービスと通信する際に SSL 証明書の不一致が発生し、検証の失敗につながります。
解決策
Ingress を再デプロイし、各 Deployment が一意のリソースセットを使用していることを確認してください。Ingress Deployment のリソースの詳細については、「ACK コンポーネント管理で Nginx Ingress Controller をアップグレードするときに実行される更新内容」をご参照ください。
ヘルスチェックの失敗による Ingress Pod の再起動
症状
ヘルスチェックの失敗により、コントローラー Pod が再起動します。
原因
-
Ingress Pod またはそのノードが高負荷状態にある場合、ヘルスチェックが失敗する可能性があります。
-
クラスターノードで
tcp_tw_reuseまたはtcp_timestampsカーネルパラメーターが設定されている場合、ヘルスチェックが失敗する可能性があります。
解決策
-
Ingress Pod をスケールアウトし、問題が解決したことを確認してください。詳細については、「高可用性のための Nginx Ingress コントローラーのデプロイ」をご参照ください。
-
tcp_tw_reuseカーネルパラメーターを無効にするか 2 に設定し、tcp_timestampsカーネルパラメーターを無効にしてください。その後、問題が解決したことを確認してください。
TCP および UDP Service の追加
-
tcp-servicesまたはudp-servicesConfigMap にエントリを追加します。デフォルトでは、これらの ConfigMap はingress-nginx名前空間にあります。たとえば、外部ポート 9000 を
default名前空間のexample-goService のポート 8080 にマッピングする場合:apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: ingress-nginx data: 9000: "default/example-go:8080" # ポート 9000 を Service のポート 8080 にマッピング -
Ingress Deployment のコンテナ定義に、マッピングしたポートを追加します。デフォルトでは、これは
ingress-nginx名前空間のnginx-ingress-controllerDeployment です。 -
Ingress コントローラーを公開する Service に、マッピングしたポートを追加します。
詳細については、「TCP および UDP Service の公開」をご参照ください。
Ingress ルールが有効にならない
症状
Ingress ルールを追加または変更しましたが、有効になりません。
考えられる原因
-
Ingress 設定にエラーがあり、新しい Ingress ルールが正しく読み込まれません。
-
Ingress リソースの設定が正しくありません。
-
Ingress コントローラーに、Ingress リソースの変更をウォッチするために必要な権限がありません。
-
既存の Ingress がドメイン名に
server-aliasを使用しているため、新しい Ingress と競合し、ルールが無視されます。
解決策
-
インテリジェント O&M コンソールの Ingress 診断ツールを使用して問題を診断し、画面の指示に従ってください。詳細については、「Ingress 診断機能を使用する」をご参照ください。
-
既存の Ingress リソースに設定エラーまたは競合がないか確認してください。
-
rewrite-targetアノテーションがないパスで正規表現を使用する場合は、nginx.ingress.kubernetes.io/use-regex: "true"アノテーションが設定されていることを確認してください。 -
PathType が期待どおりに設定されていることを確認してください。デフォルトでは、
ImplementationSpecificはPrefixと同一に機能します。
-
-
Ingress コントローラーに関連付けられた ClusterRole、ClusterRoleBinding、Role、RoleBinding、および ServiceAccount が存在することを確認してください。デフォルトでは、これらの名前はすべて
ingress-nginxです。 -
コントローラー Pod のコンテナに入り、nginx.conf ファイルに追加されたルールを確認します。
-
次のコマンドを実行して、コンテナログを手動で確認し、問題を特定してください。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
パスの書き換えによるロードの失敗またはホワイトスクリーン
現象
Ingress の rewrite-target アノテーションを使用してアクセスパスを書き換えると、一部のリソースの読み込みに失敗するか、画面が真っ白になります。
原因
-
rewrite-targetアノテーションに正規表現が設定されていません。 -
アプリケーションがハードコードされた絶対パスを使用してリソースをリクエストしています。
解決策
-
正規表現とキャプチャグループを使用して、
rewrite-targetアノテーションを設定します。 詳細については、「リライト」をご参照ください。 -
フロントエンドのリクエストが正しいパスを使用していることを確認してください。
アップグレード後の SLS ログ解析の修正
症状
ingress-nginx-controller コンポーネントには、主に 0.20 と 0.30 の 2 つのバージョンがあります。コンソールの アドオン管理 を使用してコンポーネントをバージョン 0.20 から 0.30 にアップグレードした後、カナリアリリースまたはブルーグリーンデプロイメントを使用すると、Ingress ダッシュボードにバックエンドサービスのトラフィック情報が正しく表示されません。
原因
バージョン 0.20 と 0.30 では、デフォルトのログフォーマットが異なります。そのため、カナリアリリースまたはブルーグリーンデプロイメントを使用する場合、Ingress ダッシュボードでログが正しく解析されません。
解決策
この問題を修正するには、nginx-configuration ConfigMap と k8s-nginx-ingress の設定を更新します。
-
nginx-configuration ConfigMapを更新します。-
nginx-configuration ConfigMapを変更していない場合は、次の内容をnginx-configuration.yamlとして保存し、kubectl apply -f nginx-configuration.yamlを実行します。apiVersion: v1 kind: ConfigMap data: allow-backend-server-header: "true" enable-underscores-in-headers: "true" generate-request-id: "true" ignore-invalid-headers: "true" log-format-upstream: $remote_addr - [$remote_addr] - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length $request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name] max-worker-connections: "65536" proxy-body-size: 20m proxy-connect-timeout: "10" reuse-port: "true" server-tokens: "false" ssl-redirect: "false" upstream-keepalive-timeout: "900" worker-cpu-affinity: auto metadata: labels: app: ingress-nginx name: nginx-configuration namespace: kube-system -
nginx-configuration ConfigMapを変更している場合は、次のコマンドを実行して、設定を上書きせずに問題を修正します:kubectl edit configmap nginx-configuration -n kube-system
log-format-upstreamフィールドの末尾に[$proxy_alternative_upstream_name]を追加し、保存して終了します。 -
-
k8s-nginx-ingressの設定を更新します。次の内容を
k8s-nginx-ingress.yamlとして保存し、kubectl apply -f k8s-nginx-ingress.yamlコマンドを実行して設定を適用します。
エラー: "cannot list/get/update resource"
症状
「コントローラー Pod のエラーログを確認する」で説明されているようにコントローラー Pod のエラーを確認すると、次のようなエラーログが見つかることがあります。
User "system:serviceaccount:kube-system:ingress-nginx" cannot list/get/update resource "xxx" in API group "xxx" at the cluster scope/ in the namespace "kube-system"原因
Nginx Ingress Controller には、関連するリソースを更新するために必要な権限がありません。
解決策
-
ログを確認して、ClusterRole と Role のどちらが問題の原因になっているかを判断します。
-
ログに
at the cluster scopeが含まれている場合、問題は ClusterRole (ingress-nginx) が原因です。 -
ログに
in the namespace "kube-system"が含まれている場合、問題は Role (kube-system/ingress-nginx) が原因です。
-
-
必要な権限とバインディングが存在することを確認します。
-
ClusterRole の場合:
-
ClusterRole
ingress-nginxと ClusterRoleBindingingress-nginxが存在することを確認します。存在しない場合は、作成するか、バックアップから復元するか、コンポーネントをアンインストールして再インストールします。 -
ClusterRole
ingress-nginxには、ログに示されている権限 (以下の例では、networking.k8s.ioAPI グループのingressesリソースをlistする権限) が含まれていることを確認します。権限が不足している場合は、手動で ClusterRole に追加します。E0629 17:26:22.916137 8 reflector.go:138] k8s.io/client-go@v0.23.6/tools/cache/reflector.go:167: Failed to watch *v1.Ingress: failed to list *v1.Ingress: ingresses.networking.k8s.io is forbidden: User "system:serviceaccount:kube-system:ingress-nginx" cannot list resource "ingresses" in API group "networking.k8s.io" at the cluster scope
-
-
Role の場合:
-
Role
kube-system/ingress-nginxと RoleBindingkube-system/ingress-nginxが存在することを確認します。存在しない場合は、作成するか、バックアップから復元するか、コンポーネントをアンインストールして再インストールします。 -
Role
kube-system/ingress-nginxには、ログに示されている権限 (以下の例では、ConfigMapingress-controller-leader-nginxのupdate権限) が含まれていることを確認します。権限が不足している場合は、手動で Role に追加します。E0629 17:07:09.111640 9 leaderelection.go:367] Failed to update lock: configmaps "ingress-controller-leader-nginx" is forbidden: User "system:serviceaccount:kube-system:ingress-nginx" cannot update resource "configmaps" in API group "" in the namespace "kube-system"
-
-
設定ファイルのテスト失敗
症状
「コントローラー Pod のエラーログの確認」で説明されているように Pod のコントローラーログを確認すると、次のようなエラーログが見つかることがあります:
requeuing……nginx: configuration file xxx test failed (multiple lines)原因
設定エラーにより、Nginx は設定をリロードできません。原因は通常、Ingress ルールまたは ConfigMap に挿入されたスニペットの構文エラーです。
解決策
-
ログのエラーメッセージを確認して問題を特定します。
warnレベルのメッセージは無視できます。エラーメッセージが不明確な場合は、ログのファイルと行番号を使用して Pod 内のファイルを確認します。たとえば、次のログは、ファイル/tmp/nginx/nginx-cfg2825306115の 449 行目にエラーがあることを示しています。E0629 19:54:09.340338 8 queue.go:130] "requeuing" err=< ----------------------------------------------------------------------- Error: exit status 1 2022/06/29 19:54:09 [warn] 179#179: the "http2_max_field_size" directive is obsolete, use the "large_client_header_buffers" directive instead in /tmp/nginx/nginx-cfg2825306115:146 nginx: [warn] the "http2_max_field_size" directive is obsolete, use the "large_client_header_buffers" directive instead in /tmp/nginx/nginx-cfg2825306115:146 2022/06/29 19:54:09 [warn] 179#179: the "http2_max_header_size" directive is obsolete, use the "large_client_header_buffers" directive instead in /tmp/nginx/nginx-cfg2825306115:147 nginx: [warn] the "http2_max_header_size" directive is obsolete, use the "large_client_header_buffers" directive instead in /tmp/nginx/nginx-cfg2825306115:147 2022/06/29 19:54:09 [warn] 179#179: the "http2_max_requests" directive is obsolete, use the "keepalive_requests" directive instead in /tmp/nginx/nginx-cfg2825306115:148 nginx: [warn] the "http2_max_requests" directive is obsolete, use the "keepalive_requests" directive instead in /tmp/nginx/nginx-cfg2825306115:148 2022/06/29 19:54:09 [emerg] 179#179: unexpected "}" in /tmp/nginx/nginx-cfg2825306115:449 nginx: [emerg] unexpected "}" in /tmp/nginx/nginx-cfg2825306115:449 nginx: configuration file /tmp/nginx/nginx-cfg2825306115 test failed次のコマンドを実行して、指定された行周辺の設定にエラーがないか確認してください。
# Pod にログインします。 kubectl exec -n <namespace> <controller pod name> -it -- bash # 行番号付きでファイルを表示し、エラー周辺の設定を確認します。 cat -n /tmp/nginx/nginx-cfg2825306115 -
エラーメッセージと設定ファイルを使用して、設定ミスを特定し、修正してください。
エラー: "Unexpected error validating SSL certificate"
症状
「Controller Pod のエラーログを確認する」に従って Controller Pod のログを確認すると、次のような Controller のエラーログが見つかることがあります。
Unexpected error validating SSL certificate "xxx" for server "xxx"W0629 20:39:10.993206 7 controller.go:1364] Unexpected error validating SSL certificate "default/tls-secret" for server "test.example.com": x509: certificate is not valid for any names, but wanted to match test.example.com
W0629 20:39:10.993238 7 controller.go:1365] Validating certificate against DNS names. This will be deprecated in a future version
W0629 20:39:10.993252 7 controller.go:1370] SSL certificate "default/tls-secret" does not contain a Common Name or Subject Alternative Name for server "test.example.com": x509: certificate is not valid for any names, but wanted to match test.example.com原因
このエラーは、証明書 の設定ミスが原因で発生します。一般的な原因は、Ingress リソースに設定された ドメイン名 と、証明書 に含まれる ドメイン名 の不一致です。サブジェクトの別名 が欠落しているなどの一部の警告レベルのログは、証明書 の機能に影響を与えない場合があります。これがユースケースにとって実際の問題かどうかを判断してください。
解決策
エラーメッセージを基に、クラスター 内の 証明書 に以下の問題がないか確認してください。
-
証明書ファイル (.crt) と秘密鍵ファイル (.key) のフォーマットと内容が正しいことを確認してください。 -
証明書内のドメイン名(共通名やサブジェクトの別名など) が、Ingressリソースに設定されたドメイン名と一致していることを確認してください。 -
証明書の有効期限が切れていないか確認してください。
コントローラー内に残留した設定ファイル
症状
バージョン 1.10 より前の Nginx Ingress Controller には既知のバグがあります。通常、コントローラーは生成された nginx-cfg ファイルを速やかにクリーンアップします。しかし、Ingress 設定のエラーが原因でレンダリングされた nginx.conf が無効になると、コントローラーはこれらの不正な設定ファイルを削除できなくなります。これにより nginx-cfgxxx ファイルが徐々に蓄積され、ディスク領域が大幅に消費されます。
1.6M nginx-cfg1093913015
1.6M nginx-cfg1093943092
1.6M nginx-cfg1093985057
1.6M nginx-cfg1093989258
1.6M nginx-cfg1094101515
1.6M nginx-cfg1094200269
1.6M nginx-cfg1094291268
1.6M nginx-cfg1094298834
1.6M nginx-cfg1094398542
0 nginx-cfg1094455202
1.6M nginx-cfg1094500903
1.6M nginx-cfg1094513787
1.6M nginx-cfg1094539327
1.6M nginx-cfg1094651267
0 nginx-cfg1094749495
0 nginx-cfg1094766605
1.6M nginx-cfg1094774347
1.6M nginx-cfg1094799028
1.6M nginx-cfg109483858
1.6M nginx-cfg1094903817
1.6M ...原因
この問題は、クリーンアップロジックの欠陥によって引き起こされます。クリーンアップメカニズムは、正しく生成された設定ファイルは削除しますが、無効なものは削除できず、システム上に残ります。詳細については、「コミュニティの GitHub Issue #11568」をご参照ください。
解決策
この問題を解決するには、次のいずれかの解決策を実行します。
-
Nginx Ingress Controller をバージョン 1.10 以降にアップグレードします。詳細については、「Nginx Ingress Controller コンポーネントのアップグレード」をご参照ください。
-
残留した
nginx-cfgxxxファイルを定期的に削除します。スクリプトを作成してこのプロセスを自動化し、手作業を減らすことができます。 -
無効な設定ファイルの生成を防ぐために、適用する前に新しい Ingress 設定を検証します。
コントローラーのアップグレード後、Pod が Pending 状態のままになる
症状
Nginx Ingress Controller をアップグレードすると、Pod のスケジュールに失敗し、長時間 Pending 状態のままになることがあります。
原因
Nginx Ingress Controller のアップグレード中、デフォルトのノードアフィニティと Pod アンチアフィニティのルールにより、新しい Pod のスケジュールが妨げられることがあります。クラスターに十分な利用可能リソースがあることを確認する必要があります。
次のコマンドを実行して、根本原因を調査してください。
kubectl -n kube-system describe pod <pending-pod-name>kubectl -n kube-system get events解決策
次のいずれかの解決策をお試しください。
-
クラスターリソースのスケールアウト: 新しいノードを追加して、アフィニティの要件を満たします。詳細については、「ノードプールの手動スケール」をご参照ください。
-
アフィニティの調整: リソースが限られている場合は、
kubectl edit deploy nginx-ingress-controller -n kube-systemコマンドを実行して、Pod アンチアフィニティの要件を緩和します。これにより、Pod を同じノードにスケジュールできるようになりますが、このアプローチは高可用性を低下させる可能性があります。
Nginx Ingress で複数の CLB を使用した場合の TCP ストリームの混線
症状
Flannel CNI と IPVS ネットワークモードを使用する Container Service for Kubernetes (ACK) クラスターでは、Nginx Ingress Controller が複数の Classic Load Balancer (CLB) にバインドされている場合、高い同時実行性の状況で TCP ストリームの混線が発生する可能性があります。パケットキャプチャにより、次の異常が明らかになることがあります。
-
パケットの再送
-
TCP コネクションリセット
ingress Pod からのパケットキャプチャで、Wireshark で TCP stream でフィルタリングすると、パケットの再送とリセット信号が確認できます。以下は、プロトコル分析の出力例です。
Filter: tcp.stream eq 7517
Frame 197967: 2582 bytes on wire (20656 bits), 2582 bytes captured (20656 bits)
Ethernet II, Src: 66:4b:c1:20:9a:0a (66:4b:c1:20:9a:0a), Dst: d6:79:26:1b:14:4d (d6:79:26:1b:14:4d)
Internet Protocol Version 4, Src: 172.30.3.183, Dst: xxx
Transmission Control Protocol, Src Port: 80, Dst Port: 1458, Seq: 1284522488, Ack: 173965101, Len: 2516
Selected packet (Frame 197967):
Src: 172.30.3.183 -> Dst: xxx
TCP Seq: 2516
Sequence number: 1284522488
Acknowledgement: 173965101
Timestamp value: 1789595929
Hex dump (partial):
0000 d6 79 26 1b 14 4d 66 4b c1 20 9a 0a 08 45 b0
0010 ...
Info column shows multiple entries including:
[ACK] Seq=xxx Ack=xxx
[TCP Window Full]
[TCP Retransmission]
[RST]原因
Flannel ネットワークプラグインで構成された ACK クラスターでは、CLB は Nginx Ingress Controller が実行されているノードの NodePort にトラフィックを転送します。ただし、複数の Service が異なる NodePort を使用している場合、高い同時実行性の状況で IPVS でセッションの競合が発生する可能性があります。
解決策
-
単一のロードバランサーの使用: Nginx Ingress Controller 用に
LoadBalancer Serviceを 1 つだけ作成します。他の CLB をノードのNodePortに手動でバインドして、競合の可能性を低減します。 -
複数のアクティブな NodePort の回避: 単一のノード上で、複数のアクティブな
NodePortを持たないようにして、IPVS セッションの競合のリスクを低減します。