デフォルトでは、共有 GPU スケジューリングの最小メモリ割り当て単位は 1 GiB です。より細かい GPU メモリ割り当てが必要な場合は、最小メモリ割り当て単位を調整できます。このトピックでは、共有 GPU スケジューリングの最小メモリ割り当て単位を 128 MiB に変更する方法について説明します。
前提条件
Kubernetes 1.18.8 以降を実行する ACK マネージド Pro クラスタ が作成されていること。詳細については、「ACK マネージドクラスターを作成する」および「UpgradeCluster」をご参照ください。
注意事項
Pod に aliyun.com/gpu-mem フィールドが指定されている場合、Pod は GPU リソースを要求します。クラスタに GPU リソースを要求する Pod が含まれている場合は、共有 GPU スケジューリングの最小メモリ割り当て単位を変更する前に、これらの Pod を削除する必要があります。そうしないと、スケジューラ台帳が乱れる可能性があります。
[GPU 共有は有効になっているが、メモリ分離は無効になっている] ノードに対してのみ、最小メモリ割り当て単位を調整できます。これらのノードには、ack.node.gpu.schedule=share ラベルが付いています。ack.node.gpu.schedule=cgpu ラベルが付いているノードでは、[GPU 共有とメモリ分離] の両方が有効になっています。メモリ分離モジュールの制限により、最小メモリ割り当て単位を 128 MiB に変更した場合でも、各 GPU は最大 16 個の Pod しか作成できません。
最小メモリ割り当て単位を 128 MiB に設定した場合、ノードの自動スケーリングを有効にしても、クラスタ内のノードは自動的にスケーリングされません。たとえば、Pod の aliyun.com/gpu-mem フィールドを 32 に設定したとします。この場合、クラスタ内の使用可能な GPU メモリが Pod のメモリ要求を満たすのに不十分な場合、新しいノードは追加されず、Pod は Pending 状態のままになります。
2021 年 10 月 20 日より前に作成されたクラスタを使用している場合は、チケットを送信してスケジューラを再起動する必要があります。新しい最小メモリ割り当て単位は、スケジューラが再起動された後にのみ有効になります。
最小メモリ割り当て単位を調整する
ack-ai-installer がインストールされていない場合
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、管理するクラスタを見つけ、その名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
ページの下部にある [デプロイ] をクリックします。表示されるページで、[スケジューリング ポリシー拡張 (バッチ タスク スケジューリング、GPU 共有、トポロジー対応 GPU スケジューリング)] を選択し、[詳細設定] をクリックします。
次のセクションに
gpuMemoryUnit: 128MiBパラメータを追加し、[OK] をクリックします。
構成後、[クラウドネイティブ AI スイートをデプロイ] をクリックします。
ack-ai-installer の [ステータス] が [デプロイ中] から [デプロイ済み] に変わるまで待ちます。これは、ack-ai-installer がデプロイされたことを示します。
ack-ai-installer がインストールされている場合
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、管理するクラスタを見つけ、その名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
クラウドネイティブ AI スイートページで、コンポーネントリストから ack-ai-installer を見つけ、[アクション] 列の [アンインストール] をクリックします。[コンポーネントのアンインストール] メッセージで、[確認] をクリックします。
ack-ai-installer がアンインストールされた後、[アクション] 列の [デプロイ] をクリックします。[パラメータ] パネルで、コードに
gpuMemoryUnit: 128MiBを追加します。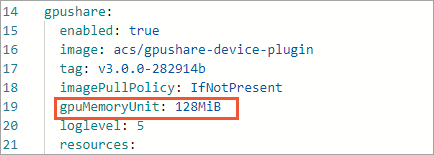
[OK] をクリックします。
ack-ai-installer の [ステータス] が [デプロイ中] から [デプロイ済み] に変わるまで待ちます。これは ack-ai-installer がデプロイされたことを示します。
例
次のサンプルコードは、Pod の GPU メモリを要求する方法の例を示しています。この例では、aliyun.com/gpu-mem フィールドは 16 に設定され、最小メモリ割り当て単位は 128 MiB です。したがって、Pod によって要求される GPU メモリの合計量は 2 GiB です。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: binpack
labels:
app: binpack
spec:
replicas: 1
serviceName: "binpack-1"
podManagementPolicy: "Parallel"
selector: # define how the deployment finds the pods it manages デプロイメントが管理対象の Pod をどのように検出するかを定義します
matchLabels:
app: binpack-1
template: # The pod specifications. Pod の仕様
metadata:
labels:
app: binpack-1
spec:
containers:
- name: binpack-1
image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5
command:
- bash
- gpushare/run.sh
resources:
limits:
# 128 MiB
aliyun.com/gpu-mem: 16 # 16 * 128 MiB = 2 GiB