CPU 制限は、コンテナーが使用できる CPU の最大量を制御します。実際の使用量がこの制限に達すると、カーネルがコンテナーの処理速度を制限(スロットル)します。このスロットルにより、サービス品質が低下します。CPU バースト機能は、スロットルを検出し、コンテナーのパラメーターを自動的に調整します。負荷が急増する際には、CPU バーストがコンテナーに追加の CPU リソースを提供します。これにより、CPU 関連のパフォーマンスボトルネックが緩和され、特に遅延の影響を受けやすいアプリケーションにおいてサービス品質が向上します。
本ドキュメントの内容をより深く理解し、本機能を活用するには、まずCFS スケジューラおよびノードの CPU 管理ポリシーについて学習してください。
CPU バーストを有効にする理由
Kubernetes クラスターでは、CPU 制限を用いてコンテナーが消費できる CPU の最大量を制限します。これにより、複数のコンテナー間でリソースを公平に共有でき、あるコンテナーが他のコンテナーのリソースを枯渇させることを防ぎます。
CPU は時分割共有リソースです。複数のプロセスまたはコンテナーが CPU のタイムスライスを共有します。CPU 制限を設定すると、オペレーティングシステムのカーネルは Completely Fair Scheduler(CFS)を用いて、各スケジューリングサイクル内でコンテナーに割り当てる CPU 時間を制御します。このサイクル長は cpu.cfs_period_us で設定されます。また、1 サイクルあたりに許可される CPU 時間は cpu.cfs_quota_us で設定されます。たとえば、コンテナーの CPU 制限が 4 の場合、カーネルは 100 ms のスケジューリングサイクルごとに、そのコンテナーの CPU 時間を 400 ms に制限します。
メリット
CPU 使用率は、コンテナーの健全性を監視するための主要なメトリックです。クラスター管理者は、通常これをもとに CPU 制限を設定します。秒単位のメトリックと比較して、ミリ秒単位の CPU 使用率は、ピークや短期的な変動をより明確に示します。以下のグラフでは、秒単位で測定された CPU 使用率(紫線)は、4 コアを大きく下回っているように見えますが、ミリ秒単位(緑線)では、一部の期間において 4 コアを超える使用率が観測されます。CPU 制限を 4 コアに設定した場合、スロットルによりスレッドが一時停止され、応答遅延(RT)が増加します。これは、ロングテール RT 問題の主な原因です。
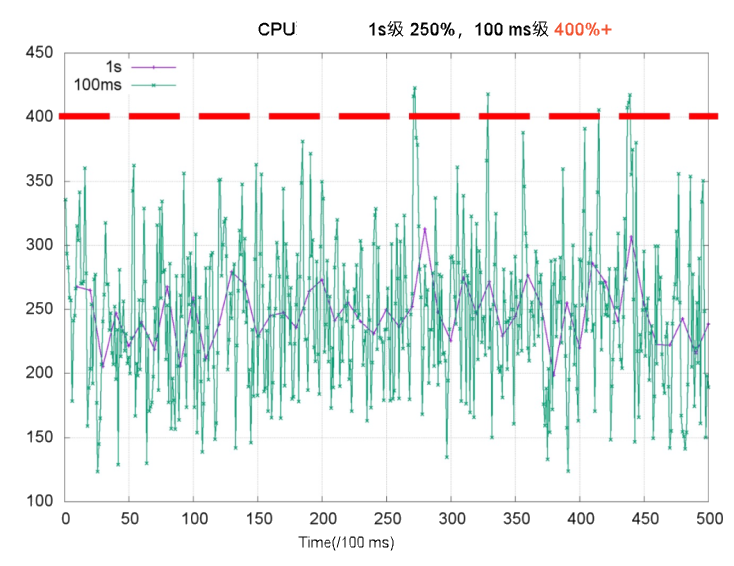
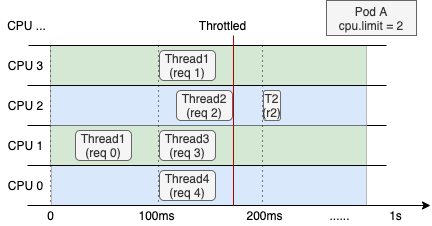
次の図は、4 コアノード上で CPU 制限が 2 に設定された Web サービスコンテナーにおける CPU リソース割り当てを示しています。左側は通常の動作を、右側は CPU バーストを有効化後の動作を表します。
直近 1 秒間の全体的な CPU 使用率が低くても、スロットルにより Thread 2 は req 2 の処理を完了するまで次のスケジューリングサイクルを待機する必要があります。これによりリクエスト RT が増加し、ロングテール RT の一般的な原因となります。 | CPU バーストを有効化すると、コンテナーは未使用の CPU 時間を蓄積できます。この蓄積された時間を負荷の急増時に活用することで、パフォーマンスが向上し、遅延が低減します。 |
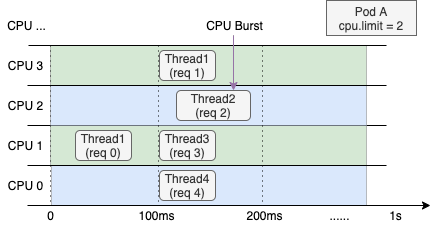
CPU バーストは、CPU 需要が急激に増加する状況でも有効です。たとえば、サービストラフィックが急増した場合、ack-koordinator は数秒以内に CPU ボトルネックを解消し、ノード全体の負荷を安全に保ちます。
ack-koordinator は、ノードの cgroup 内の cfs quota パラメーターのみを調整します。Pod の仕様(spec)内の CPU 制限フィールドは変更しません。
適用範囲/利用シーン
CPU バーストの典型的なユースケースは以下のとおりです。
CPU 使用率が大部分の時間、CPU 制限を下回っているにもかかわらず、スロットルが発生し、アプリケーションのパフォーマンスに悪影響を与えている場合。CPU バーストを有効化することで、コンテナーはバースト時に蓄積された CPU 時間を利用できます。これにより、スロットルが解消され、サービス品質が向上します。
コンテナーが起動時および初期読み込み時に高 CPU を使用し、読み込み完了後に CPU 使用率が低く安定する場合。CPU バーストを有効化すれば、過剰に高い CPU 制限を設定する必要がなくなります。コンテナーは起動時に余分な CPU 時間を利用できるため、起動が高速化します。
前提条件
ACK マネージドクラスター Pro エディションを、Kubernetes バージョン 1.18 以降で作成します。詳細については、「ACK マネージドクラスターの作成」および「クラスターの手動アップグレード」をご参照ください。
説明オペレーティングシステムとして、Alibaba Cloud Linux の使用を推奨します。詳細については、「CPU バーストポリシーを有効化するには Alibaba Cloud Linux を使用する必要がありますか?」をご参照ください。
ack-koordinator コンポーネントをインストールします。バージョンは 0.8.0 以降を使用してください。詳細については、「ack-koordinator」をご参照ください。
構成
CPU バーストは、Pod のアノテーションを用いて特定の Pod に対して有効化できます。また、ConfigMap を用いてクラスター全体または名前空間単位で有効化することも可能です。
アノテーションを用いた特定 Pod への CPU バーストの有効化
Pod の YAML ファイルの metadata フィールド内に、CPU バーストのアノテーションを追加します。この設定は、該当の Pod のみに適用されます。
Deployment などのワークロードに設定を適用する場合は、template.metadata フィールド内に適切なアノテーションを設定します。
annotations:
# この Pod に対して CPU バーストを有効化するには、auto を指定します。
koordinator.sh/cpuBurst: '{"policy": "auto"}'
# この Pod に対して CPU バーストを無効化するには、none を指定します。
koordinator.sh/cpuBurst: '{"policy": "none"}'ConfigMap を用いたクラスター単位での有効化
デフォルトでは、ConfigMap はクラスター全体の CPU バーストを構成します。
以下の ConfigMap の例を用いて、configmap.yaml というファイルを作成します。
apiVersion: v1 data: cpu-burst-config: '{"clusterStrategy": {"policy": "auto"}}' #cpu-burst-config: '{"clusterStrategy": {"policy": "cpuBurstOnly"}}' #cpu-burst-config: '{"clusterStrategy": {"policy": "none"}}' kind: ConfigMap metadata: name: ack-slo-config namespace: kube-systemConfigMap
ack-slo-configが kube-system 名前空間に存在するかどうかを確認します。存在する場合、他の設定を変更しないよう、PATCH を用いて更新します。
kubectl patch cm -n kube-system ack-slo-config --patch "$(cat configmap.yaml)"存在しない場合、以下のコマンドで作成します。
kubectl apply -f configmap.yaml
ConfigMap を用いた名前空間単位での有効化
名前空間を指定することで、その名前空間内の Pod に対する CPU バーストポリシーを構成できます。このポリシーは、指定した名前空間に適用されます。
以下の ConfigMap の例を用いて、configmap.yaml というファイルを作成します。
apiVersion: v1 kind: ConfigMap metadata: name: ack-slo-pod-config namespace: koordinator-system # 初回使用前に、この名前空間を手動で作成してください。 data: # 選択した名前空間に対して CPU バーストを有効化または無効化します。 cpu-burst: | { "enabledNamespaces": ["allowed-ns"], "disabledNamespaces": ["blocked-ns"] } # allowed-ns 名前空間内のすべての Pod に対して CPU バーストを有効化します(ポリシーは auto)。 # blocked-ns 名前空間内のすべての Pod に対して CPU バーストを無効化します(ポリシーは none)。ConfigMap
ack-slo-configが kube-system 名前空間に存在するかどうかを確認します。存在する場合、他の設定を変更しないよう、PATCH を用いて更新します。
kubectl patch cm -n kube-system ack-slo-config --patch "$(cat configmap.yaml)"存在しない場合、以下のコマンドで作成します。
kubectl apply -f configmap.yaml
操作手順
この例では、Web サービスアプリケーションを用いて、CPU バーストがアクセス遅延を低減する方法を示し、そのパフォーマンス向上効果を実証します。
検証手順
以下の YAML を用いて、apache-demo.yaml というファイルを作成します。
CPU バーストのアノテーションを
metadataフィールド内に追加し、この Pod に対して CPU バーストを有効化します。apiVersion: v1 kind: Pod metadata: name: apache-demo annotations: koordinator.sh/cpuBurst: '{"policy": "auto"}' # CPU バーストを有効化します。 spec: containers: - command: - httpd - -D - FOREGROUND image: registry.cn-zhangjiakou.aliyuncs.com/acs/apache-2-4-51-for-slo-test:v0.1 imagePullPolicy: Always name: apache resources: limits: cpu: "4" memory: 10Gi requests: cpu: "4" memory: 10Gi nodeName: $nodeName # 実際のノード名に置き換えてください。 hostNetwork: False restartPolicy: Never schedulerName: default-schedulerテストアプリケーションとして Apache HTTP Server をデプロイします。
kubectl apply -f apache-demo.yamlwrk2 を用いてリクエストを送信します。
# オープンソースの wrk2 ツールをダウンロードおよび展開します。詳細については、https://github.com/giltene/wrk2 をご参照ください。 # Apache イメージでは Gzip 圧縮が有効化されており、サーバー側のリクエスト処理をシミュレートします。 # ロードテストを実行します。$target_ip_address を Apache Pod の IP アドレスに置き換えてください。 ./wrk -H "Accept-Encoding: deflate, gzip" -t 2 -c 12 -d 120 --latency --timeout 2s -R 24 http://$target_ip_address:8010/static/file.1m.test説明コマンド内のターゲットアドレスを、Apache Pod の IP アドレスに置き換えてください。
-Rパラメーターを変更することで、QPS の負荷を調整できます。
結果分析
以下の表は、Alibaba Cloud Linux およびコミュニティ版 CentOS における、CPU バーストの有効/無効時のパフォーマンス比較を示しています。
すべて無効:CPU バーストポリシーが
noneに設定されています。すべて有効:CPU バーストポリシーが
autoに設定されています。
以下の数値は理論値です。実際の結果はご利用の環境によって異なります。
Alibaba Cloud Linux | すべてシャットダウン | すべて有効 |
apache RT-p99 | 107.37 ms | 67.18 ms(−37.4%) |
CPU スロットル比率 | 33.3% | 0% |
Pod の平均 CPU 使用率 | 31.8% | 32.6% |
CentOS | 一括シャットダウン | すべて有効 |
apache RT-p99 | 111.69 ms | 71.30 ms(−36.2%) |
CPU スロットル比率 | 33% | 0% |
Pod の平均 CPU 使用率 | 32.5% | 33.8% |
これらの結果から、以下のことがわかります。
CPU バーストを有効化すると、p99 RT メトリックが大幅に向上します。
CPU バーストを有効化すると、CPU スロットルが大幅に低減します。一方、Pod の平均 CPU 使用率はほぼ変化しません。
高度な構成
高度な CPU バーストパラメーターは、ConfigMap または Pod のアノテーションで構成できます。両方の設定が存在する場合、Pod のアノテーションが優先されます。アノテーションが設定されていない場合、ack-koordinator は名前空間レベルの ConfigMap を確認します。名前空間レベルの ConfigMap も設定されていない場合、ack-koordinator はクラスター全体の ConfigMap を使用します。
例:
# 例:ConfigMap ack-slo-config。
data:
cpu-burst-config: |
{
"clusterStrategy": {
"policy": "auto",
"cpuBurstPercent": 1000,
"cfsQuotaBurstPercent": 300,
"sharePoolThresholdPercent": 50,
"cfsQuotaBurstPeriodSeconds": -1
}
}
# 例:Pod のアノテーション。
koordinator.sh/cpuBurst: '{"policy": "auto", "cpuBurstPercent": 1000, "cfsQuotaBurstPercent": 300, "cfsQuotaBurstPeriodSeconds": -1}'以下の表に、高度な CPU バーストパラメーターの一覧を示します。
アノテーション および ConfigMap の列は、各パラメーターが Pod のアノテーションまたは ConfigMap のいずれで構成可能かを示します。![]() は対応していることを、
は対応していることを、![]() は対応していないことを意味します。
は対応していないことを意味します。
パラメーター | 型 | 説明 | アノテーション | ConfigMap |
| string |
|
|
|
| int | デフォルト: Alibaba Cloud Linux カーネルレベルの CPU バースト弾力性の場合、これは CPU 制限を超えて CPU バーストが拡大される倍率を設定します。cgroup パラメーター たとえば、デフォルト設定では、 |
|
|
| int | デフォルト: CFS クォータ弾力性が有効化されている場合、これは cgroup パラメーター |
|
|
| int | デフォルト: CFS クォータ弾力性が有効化されている場合、これは Pod が増加したクォータ( |
|
|
| int | デフォルト: CFS クォータ弾力性が有効化されている場合、これはノードの安全な CPU 使用率しきい値を設定します。使用率がこのしきい値を超えると、クォータが増加したすべての Pod の |
|
|
CFS クォータの自動調整(
policyをcfsQuotaBurstOnlyまたはautoに設定)を有効化すると、Pod のcpu.cfs_quota_usパラメーターは、スロットルイベントに基づいて動的に変化します。Pod のストレステスト中は、Pod の CPU 使用率を監視するか、一時的に CFS クォータの自動調整(
policyをcpuBurstOnlyまたはnoneに設定)を無効化してください。これにより、本番環境でのリソース弾力性が安定します。
よくある質問
以前の ack-slo-manager プロトコルで CPU バーストを使用していました。ack-koordinator へのアップグレード後も引き続き機能しますか?
以前の Pod アノテーションでは alibabacloud.com/cpuBurst を使用していました。ack-koordinator は、この旧プロトコルを完全にサポートしています。シームレスにアップグレードできます。
ack-koordinator の旧プロトコルバージョンに対する互換性期間は、2023 年 7 月 30 日に終了します。旧プロトコルバージョンのリソースパラメーターを最新バージョンへアップグレードすることを強く推奨します。
ack-koordinator は、以下のプロトコルバージョンと互換性があります。
ack-koordinator のバージョン | alibabacloud.com プロトコル | koordinator.sh プロトコル |
≥0.2.0 | 対応 | 非対応 |
≥0.8.0 | 対応 | 対応 |
CPU バーストを有効化した後も、なぜ CPU スロットルが発生するのですか?
主な原因と対処法は以下のとおりです。
構成の構文に誤りがあると、CPU バーストが有効化されません。修正および検証については、「高度な構成」をご参照ください。
CPU 使用率が
cfsQuotaBurstPercentの制限に達した場合、CPU リソースが不足しているためにスロットルが発生することがあります。アプリケーションの実際のニーズに合わせて、CPU のリクエストおよび制限値を調整してください。
CPU バーストは、2 つの cgroup パラメーター(
cpu.cfs_quota_usおよびcpu.cfs_burst_us)を調整します。「高度な構成」をご参照ください。cpu.cfs_quota_usは、ack-koordinator がスロットルを検出した後にのみ更新されるため、わずかな遅延があります。cpu.cfs_burst_usは設定値から即座に更新されるため、応答が速くなります。最も良い結果を得るには、Alibaba Cloud Linux を使用してください。
cpu.cfs_quota_usの調整には保護機構があり、全体的な安全性のウォーターマークしきい値としてsharePoolThresholdPercentが設定されます。全体の使用率が過度に高くなると、個々の Pod による干渉を防ぐため、cpu.cfs_quota_usが初期値にリセットされます。アプリケーションの実際の状況に応じて、適切なマシンの安全性しきい値を設定し、高マシン使用率がアプリケーションのパフォーマンスに影響を与えないようにしてください。
CPU バーストポリシーを有効化するには、Alibaba Cloud Linux を使用する必要がありますか?
ack-koordinator の CPU バーストは、Alibaba Cloud Linux および CentOS のすべてのオープンソースカーネルで動作します。ただし、Alibaba Cloud Linux の使用を推奨します。そのカーネル機能により、ack-koordinator はより細かい粒度で CPU 弾力性を提供できます。詳細については、「cgroup v1 インターフェイスを用いた CPU バーストの有効化」をご参照ください。
CPU バーストを有効化した後、アプリケーションが異なるスレッド数を報告するのはなぜですか?
これは、CPU バーストの動作メカニズムが、特定のアプリケーションがシステムリソースを取得する方法と競合するためです。ack-koordinator は、CPU バーストを実装する際に、コンテナーの基盤となる cgroup パラメーターである cpu.cfs_quota_us を動的に調整します。この値は、現在のスケジューリングサイクル内でコンテナーが利用可能な CPU 時間クォータを表します。ack-koordinator は、アプリケーションの負荷に応じてこのクォータを動的にスケールします。
Java の Runtime.getRuntime().availableProcessors() など、多くのアプリケーションは、利用可能な CPU コア数を計算するために、cpu.cfs_quota_us を直接読み取ります。そのため、CPU クォータが動的に調整されると、アプリケーションが取得するコア数も変化し、スレッドプールサイズなど、この値に依存するパラメーターが不安定になります。
代わりに、アプリケーションは、Pod の仕様(spec)で定義された固定の limits.cpu 値に依存するようにしてください。
環境変数を注入:
resourceFieldRefを用いて、Pod のlimits.cpu値をコンテナーに環境変数として注入します。env: - name: CPU_LIMIT valueFrom: resourceFieldRef: resource: limits.cpuアプリケーションコードを更新: スレッドプールサイズの計算および設定時に、起動ロジックを変更して、まず
CPU_LIMITを読み取るようにします。これにより、CPU バーストによるクォータの変更があっても、安定的かつ信頼性の高い動作が保証されます。