Di lingkungan terkontainerisasi, log aplikasi tersebar di standard output dan file log berbagai kontainer Docker, sehingga menyulitkan manajemen dan pengambilannya. Gunakan LoongCollector dari Simple Log Service (SLS) untuk mengumpulkan log dari beberapa node ke dalam satu logstore, memungkinkan penyimpanan terpusat, penguraian terstruktur, penyamaran data, penyaringan, serta kueri dan analisis yang efisien.
Catatan penggunaan
Persyaratan izin: Akun Alibaba Cloud atau Pengguna RAM yang Anda gunakan untuk deployment harus memiliki izin
AliyunLogFullAccess.Versi Docker dan persyaratan LoongCollector:
Jika versi Docker Engine Anda adalah 29.0 atau lebih baru, atau jika versi minimum API Docker yang didukung adalah 1.42 atau lebih baru, Anda harus menggunakan LoongCollector 3.2.4 atau lebih baru. Jika tidak, LoongCollector tidak dapat mengumpulkan output standar kontainer atau log file.
Versi LoongCollector 3.2.4 dan lebih baru mendukung versi API Docker dari 1.24 hingga 1.48.
Versi LoongCollector 3.2.3 dan lebih lama mendukung versi API Docker dari 1.18 hingga 1.41.
Batasan pada Pengumpulan Keluaran Standar:
Anda harus menambahkan
"log-driver": "json-file"ke file konfigurasi Docker, daemon.json.Untuk CentOS 7.4 dan versi lebih baru, kecuali CentOS 8.0, Anda harus mengatur
fs.may_detach_mounts=1.
Batasan pengumpulan log teks: Hanya driver penyimpanan overlay dan overlay2 yang didukung. Untuk tipe driver lain, Anda harus memasang direktori log secara manual.
Proses pembuatan konfigurasi pengumpulan
Preparations: Buat proyek dan logstore. Proyek adalah unit manajemen resource yang digunakan untuk mengisolasi log dari aplikasi berbeda, sedangkan logstore digunakan untuk menyimpan log.
Configure a machine group (install LoongCollector): Instal LoongCollector pada server tempat Anda ingin mengumpulkan log dan tambahkan server tersebut ke kelompok mesin. Gunakan kelompok mesin untuk mengelola node pengumpulan secara terpusat, mendistribusikan konfigurasi, dan mengelola status server.
Create and configure log collection rules
Global and input configuration: Tentukan nama konfigurasi pengumpulan, sumber, dan cakupan pengumpulan log.
Log processing and structuring: Konfigurasikan aturan pemrosesan berdasarkan format log.
Log multi-baris: Berlaku untuk log tunggal yang mencakup beberapa baris, seperti stack exception Java atau traceback Python. Anda harus menggunakan ekspresi reguler untuk mengidentifikasi awal setiap log.
Penguraian terstruktur: Konfigurasikan plugin parsing, seperti mode ekspresi reguler, separator, atau NGINX, untuk mengekstraksi string mentah menjadi pasangan kunci-nilai terstruktur. Hal ini memudahkan kueri dan analisis selanjutnya.
Log filtering: Konfigurasikan daftar hitam pengumpulan dan aturan penyaringan konten untuk memfilter konten log yang valid. Praktik ini mengurangi transmisi dan penyimpanan data berlebih.
Log categorization: Konfigurasikan topik dan tag log untuk membedakan log dari aplikasi, kontainer, atau sumber path yang berbeda secara fleksibel.
Query and analysis configuration: Sistem mengaktifkan full-text index secara default, yang mendukung pencarian kata kunci. Kami merekomendasikan Anda mengaktifkan field index untuk kueri dan analisis presisi pada field terstruktur guna meningkatkan efisiensi pencarian.
Validation and troubleshooting: Setelah menyelesaikan konfigurasi, verifikasi bahwa log berhasil dikumpulkan. Jika mengalami masalah seperti tidak ada data yang dikumpulkan, kegagalan heartbeat, atau error parsing, lihat bagian FAQ.
Persiapan
Sebelum mengumpulkan log, Anda harus merencanakan dan membuat proyek serta logstore untuk mengelola dan menyimpan log. Jika Anda sudah memiliki resource yang diperlukan, lewati langkah ini dan lanjutkan ke Langkah 1: Konfigurasikan kelompok mesin (instal LoongCollector).
Buat proyek
Buat logstore
Klik nama proyek.
Di panel navigasi kiri, pilih
 dan klik +.
dan klik +.Di halaman Create logstore, konfigurasikan parameter inti berikut:
Logstore Name: Masukkan nama yang unik dalam proyek. Nama ini tidak dapat diubah setelah logstore dibuat.
Logstore Type: Pilih Standard atau Query berdasarkan perbandingan spesifikasi.
Billing Mode:
Pay-by-feature: Ditagih secara terpisah untuk resource seperti penyimpanan, pengindeksan, dan operasi baca/tulis. Mode ini cocok untuk skenario skala kecil atau ketika penggunaan fitur belum pasti.
Pay-by-ingested-data: Ditagih hanya berdasarkan jumlah data mentah yang ditulis. Mode ini menyediakan penyimpanan gratis selama 30 hari dan fitur gratis seperti transformasi dan pengiriman data. Mode ini cocok untuk skenario bisnis dengan periode penyimpanan mendekati 30 hari atau pipeline pemrosesan data yang kompleks.
Data Retention Period: Tentukan jumlah hari untuk menyimpan log. Nilai valid: 1 hingga 3650. Nilai 3650 menunjukkan penyimpanan permanen. Nilai default adalah 30.
Pertahankan pengaturan default untuk parameter lain dan klik OK. Untuk informasi lebih lanjut tentang parameter lain, lihat Kelola logstore.
Langkah 1: Konfigurasikan kelompok mesin (instal LoongCollector)
Deploy LoongCollector sebagai kontainer pada host Docker dan tambahkan host ke kelompok mesin. Gunakan kelompok mesin untuk mengelola beberapa node pengumpulan secara terpusat, mendistribusikan konfigurasi, dan memantau status.
Ambil image
Pada host yang telah menginstal Docker, jalankan perintah berikut untuk mengambil image LoongCollector. Ganti
${region_id}dengan ID wilayah host atau wilayah terdekat, seperticn-hangzhou, untuk meningkatkan kecepatan unduh dan stabilitas.# Alamat image LoongCollector docker pull aliyun-observability-release-registry.${region_id}.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyun # Alamat image Logtail docker pull registry.${region_id}.aliyuncs.com/log-service/logtail:v2.1.11.0-aliyunJalankan kontainer LoongCollector
Jalankan perintah berikut untuk menjalankan kontainer. Pastikan Anda memasang direktori dengan benar dan mengatur variabel lingkungan yang diperlukan:
docker run -d \ -v /:/logtail_host:ro \ -v /var/run/docker.sock:/var/run/docker.sock \ --env ALIYUN_LOGTAIL_CONFIG=/etc/ilogtail/conf/${sls_upload_channel}/ilogtail_config.json \ --env ALIYUN_LOGTAIL_USER_ID=${aliyun_account_id} \ --env ALIYUN_LOGTAIL_USER_DEFINED_ID=${user_defined_id} \ aliyun-observability-release-registry.${region_id}.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyunDeskripsi parameter:
${sls_upload_channel}: Saluran unggah log. Formatnya adalah Project Region-Network Transfer Type. Contoh:Tipe transfer
Format nilai konfigurasi
Contoh
Skenario
Transfer jaringan internal
regionIdcn-hangzhouInstance ECS dan proyek berada di wilayah yang sama.
Transfer Internet
regionId-internetcn-hangzhou-internetInstance ECS dan proyek berada di wilayah berbeda.
Server berasal dari penyedia cloud lain atau pusat data self-built.
Akselerasi transfer
regionId-accelerationcn-hangzhou-accelerationKomunikasi lintas wilayah di dalam dan luar Tiongkok.
${aliyun_account_id}: ID akun Alibaba Cloud.${user_defined_id}: ID kustom kelompok mesin. ID ini digunakan untuk mengikat kelompok mesin. Misalnya, gunakanuser-defined-docker-1. ID harus unik dalam wilayah tersebut.PentingKondisi startup berikut harus dipenuhi:
Tiga variabel lingkungan utama dikonfigurasi dengan benar:
ALIYUN_LOGTAIL_CONFIG,ALIYUN_LOGTAIL_USER_ID, danALIYUN_LOGTAIL_USER_DEFINED_ID.Direktori
/var/run/docker.sockdipasang. Direktori ini digunakan untuk mendengarkan event siklus hidup kontainer.Direktori root
/dipasang ke/logtail_host. Ini digunakan untuk mengakses sistem file host.
Verifikasi status berjalan kontainer
docker ps | grep loongcollectorContoh output yang diharapkan:
6ad510001753 aliyun-observability-release-registry.cn-beijing.cr.aliyuncs.com/loongcollector/loongcollector:v3.0.12.0-25723a1-aliyun "/usr/local/ilogtail…" About a minute ago Up About a minute recursing_shirleyKonfigurasikan kelompok mesin
Di panel navigasi kiri, pilih
 Resources > Machine Groups, klik
Resources > Machine Groups, klik  > Create Machine Group, konfigurasikan parameter berikut, dan klik OK:
> Create Machine Group, konfigurasikan parameter berikut, dan klik OK:Name: Masukkan nama kustom untuk kelompok mesin, seperti
docker-host-group.Machine Group Identifier: Pilih Custom Identifier.
Custom Identifier: Masukkan
${user_defined_id}yang Anda atur saat menjalankan kontainer. ID harus cocok persis. Jika tidak, asosiasi akan gagal.
Verifikasi status heartbeat kelompok mesin
Klik nama kelompok mesin baru untuk membuka halaman detail dan periksa :
OK: Menunjukkan bahwa LoongCollector terhubung ke SLS.
FAIL: Untuk informasi lebih lanjut tentang cara mengatasi masalah ini, lihat Troubleshoot heartbeat errors.
Langkah 2: Buat dan konfigurasikan aturan pengumpulan log
Tentukan log mana yang dikumpulkan oleh LoongCollector, cara mengurai strukturnya, cara menyaring konten, dan cara mengikat konfigurasi ke kelompok mesin yang terdaftar.
Di halaman
 Logstores, klik ikon
Logstores, klik ikon  di sebelah nama logstore target.
di sebelah nama logstore target.Klik
 di sebelah Data Collection. Di kotak dialog Quick Data Import, pilih templat berdasarkan sumber log dan klik Integrate Now.
di sebelah Data Collection. Di kotak dialog Quick Data Import, pilih templat berdasarkan sumber log dan klik Integrate Now.Standard output Docker: Pilih Docker Stdout and Stderr - New Version.
Dua templat tersedia untuk mengumpulkan standard output kontainer: versi baru dan lama. Kami merekomendasikan Anda menggunakan versi baru. Untuk informasi lebih lanjut tentang perbedaan antara versi baru dan lama, lihat Lampiran: Perbandingan versi lama dan baru standard output kontainer. Untuk menggunakan versi lama dalam pengumpulan, lihat Kumpulkan standard output dari kontainer Docker (Versi lama).
File log Docker: Pilih Docker File - Container.
Konfigurasikan Machine Group dan klik Next.
Scenario: Pilih Docker Containers.
Pindahkan kelompok mesin yang Anda buat di Langkah 1 dari daftar kelompok mesin sumber ke daftar kelompok mesin yang diterapkan.
Di halaman Logtail Configuration, konfigurasikan parameter berikut dan klik Next.
1. Konfigurasi global dan input
Sebelum memulai, pastikan Anda telah memilih templat impor data dan mengikat kelompok mesin. Pada langkah ini, tentukan nama konfigurasi pengumpulan, sumber log, dan cakupan pengumpulan.
Kumpulkan standard output Docker
Global Configurations
Configuration Name: Masukkan nama kustom untuk konfigurasi pengumpulan. Nama harus unik dalam proyek dan tidak dapat diubah setelah konfigurasi dibuat. Nama harus memenuhi konvensi berikut:
Hanya boleh berisi huruf kecil, angka, tanda hubung (-), dan garis bawah (_).
Harus dimulai dan diakhiri dengan huruf kecil atau angka.
Input Configurations
Nyalakan sakelar Stdout and Stderr atau Standard Error. Kedua sakelar ini dinyalakan secara default.
PentingKami merekomendasikan agar Anda tidak mengaktifkan standard output dan standard error secara bersamaan karena hal ini dapat menyebabkan kebingungan dalam log yang dikumpulkan.
Kumpulkan log teks kontainer Docker
Global Configurations:
Configuration Name: Masukkan nama kustom untuk konfigurasi pengumpulan. Nama harus unik dalam proyek dan tidak dapat diubah setelah konfigurasi dibuat. Nama harus memenuhi konvensi berikut:
Hanya boleh berisi huruf kecil, angka, tanda hubung (-), dan garis bawah (_).
Harus dimulai dan diakhiri dengan huruf kecil atau angka.
Input Configurations:
File Path Type:
Path in Container: Kumpulkan file log dari dalam kontainer.
Host Path: Kumpulkan log dari layanan lokal pada host.
File Path: Jalur absolut file log yang akan dikumpulkan.
Linux: Jalur harus dimulai dengan garis miring (`/`). Misalnya,
/data/mylogs/**/*.logmenunjukkan semua file yang memiliki ekstensi .log di direktori/data/mylogs.Windows: Jalur harus dimulai dengan huruf drive. Misalnya,
C:\Program Files\Intel\**\*.Log.
Maximum Directory Monitoring Depth: Kedalaman direktori maksimum yang dapat dicocokkan oleh karakter wildcard
**di File Path. Nilai default adalah 0, yang menunjukkan direktori saat ini. Nilai dapat berkisar dari 0 hingga 1000.Kami merekomendasikan Anda mengatur parameter ini ke 0 dan mengonfigurasi jalur ke direktori yang berisi file tersebut.
2. Pemrosesan dan strukturisasi log
Konfigurasikan aturan pemrosesan log untuk mengubah log mentah yang tidak terstruktur menjadi data terstruktur. Hal ini meningkatkan efisiensi kueri dan analisis log. Kami merekomendasikan Anda menambahkan sampel log sebelum mengonfigurasi aturan:
Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Log Sample dan masukkan konten log yang akan dikumpulkan. Sistem mengidentifikasi format log berdasarkan sampel dan membantu Anda menghasilkan ekspresi reguler serta aturan parsing. Hal ini menyederhanakan konfigurasi.
Skenario 1: Pemrosesan log multi-baris (seperti log stack Java)
Log seperti stack exception Java dan objek JSON sering kali mencakup beberapa baris. Dalam mode pengumpulan default, log ini dibagi menjadi beberapa catatan tidak lengkap, yang menyebabkan hilangnya konteks. Untuk mengatasi masalah ini, aktifkan mode pengumpulan multi-baris dan konfigurasikan ekspresi reguler untuk awal baris guna menggabungkan baris berurutan dari log yang sama menjadi satu entri log lengkap.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Dalam mode pengumpulan default, setiap baris dianggap sebagai log independen, memecah informasi stack dan kehilangan konteks | Dengan mode multi-baris diaktifkan, ekspresi reguler untuk awal baris mengidentifikasi log lengkap, mempertahankan struktur semantik penuh. |
|
|
|

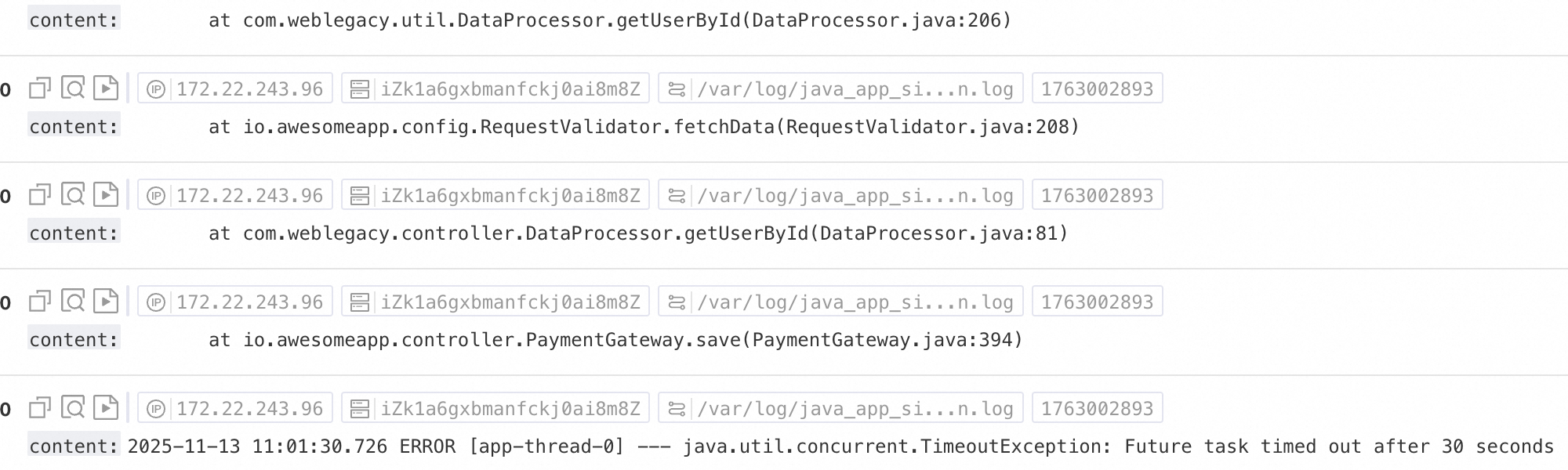

Konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, nyalakan Multi-line Mode:
Type: Pilih Custom atau Multi-line JSON.
Custom: Format log mentah tidak tetap. Anda harus mengonfigurasi Regex to Match First Line untuk mengidentifikasi baris awal setiap entri log.
Regex to Match First Line: Mendukung pembuatan otomatis atau input manual. Ekspresi reguler harus mencocokkan satu baris data lengkap. Misalnya, ekspresi reguler yang cocok dalam contoh sebelumnya adalah
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*.Pembuatan otomatis: Klik Generate. Lalu, di kotak teks Log Sample, pilih konten log yang akan diekstraksi dan klik Automatically Generate.
Input manual: Klik Manually Enter Regular Expression. Setelah memasukkan ekspresi, klik Validate.
Multi-line JSON: Jika log mentah semuanya dalam format JSON standar, SLS secara otomatis menangani jeda baris dalam satu log JSON.
Processing Method If Splitting Fails:
Discard: Jika sepotong teks tidak cocok dengan aturan awal baris, teks tersebut dibuang.
Retain Single Line: Teks yang tidak cocok dipecah dan dipertahankan dalam mode baris tunggal asli.
Skenario 2: Logging terstruktur
Jika log mentah berupa teks tidak terstruktur atau semi-terstruktur, seperti log akses NGINX atau log output aplikasi, kueri dan analisis langsung sering kali tidak efisien. SLS menyediakan berbagai plugin parsing data yang dapat secara otomatis mengonversi log mentah dengan format berbeda menjadi data terstruktur. Hal ini memberikan fondasi data yang kuat untuk analisis, pemantauan, dan peringatan selanjutnya.
Contoh efek:
Log Mentah | Log yang diurai |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration:
Tambahkan plugin parsing: Klik Add Processor dan konfigurasikan plugin seperti parsing ekspresi reguler, parsing separator, atau parsing JSON yang sesuai dengan format log. Misalnya, untuk mengumpulkan log NGINX, pilih .
NGINX Log Configuration: Salin definisi lengkap
log_formatdari file konfigurasi server NGINX (nginx.conf) dan tempelkan ke kotak teks ini.Contoh:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';PentingDefinisi format harus persis sama dengan format yang digunakan untuk menghasilkan log di server. Jika tidak, parsing log akan gagal.
Parameter umum: Parameter berikut muncul di beberapa plugin parsing data. Fungsi dan penggunaannya konsisten.
Original Field: Nama field sumber yang akan diurai. Nilai default adalah
content, yang menunjukkan seluruh konten log yang dikumpulkan.Retain Original Field if Parsing Fails: Kami merekomendasikan Anda menyalakan sakelar ini. Jika log gagal diurai oleh plugin karena ketidakcocokan format, opsi ini memastikan konten log asli tidak hilang dan dipertahankan di field mentah yang ditentukan.
Retain Original Field if Parsing Succeeds: Jika Anda memilih opsi ini, konten log asli dipertahankan bahkan jika log berhasil diurai.
3. Penyaringan log
Saat pengumpulan log, pengumpulan besar-besaran log bernilai rendah atau tidak relevan tanpa seleksi—seperti log tingkat DEBUG atau INFO—memboroskan sumber daya penyimpanan, meningkatkan biaya, memengaruhi efisiensi kueri, dan menimbulkan risiko kebocoran data. Untuk mengatasi masalah ini, terapkan strategi penyaringan detail halus untuk pengumpulan log yang efisien dan aman.
Kurangi biaya melalui penyaringan konten
Saring log berdasarkan konten field. Misalnya, kumpulkan hanya log tingkat WARNING atau ERROR.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Kumpulkan hanya log |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration:
Klik Add Processor dan pilih :
Field Name: Field log yang akan digunakan untuk penyaringan.
Field Value: Ekspresi reguler yang akan digunakan untuk penyaringan. Hanya pencocokan teks penuh yang didukung. Pencocokan kata kunci parsial tidak didukung.
Kontrol cakupan pengumpulan dengan daftar hitam
Gunakan daftar hitam untuk mengecualikan direktori atau file tertentu. Hal ini mencegah log yang tidak relevan atau sensitif diunggah.
Langkah konfigurasi: Di bagian Input Configurations pada halaman Logtail Configuration, aktifkan Collection Blacklist dan klik Add.
Pencocokan penuh dan pencocokan wildcard didukung untuk direktori dan nama file. Karakter wildcard yang didukung adalah tanda bintang (`*`) dan tanda tanya (`?`).
File Path Blacklist: Jalur file yang akan diabaikan. Contoh:
/home/admin/private*.log: Mengabaikan semua file di direktori/home/admin/yang diawali dengan "private" dan diakhiri dengan ".log" selama pengumpulan./home/admin/private*/*_inner.log: Mengabaikan file yang diakhiri dengan "_inner.log" di direktori yang diawali dengan "private" di bawah direktori/home/admin/selama pengumpulan.
File Blacklist: Nama file yang akan diabaikan selama pengumpulan. Contoh:
app_inner.log: Mengabaikan semua file bernamaapp_inner.logselama pengumpulan.
Directory Blacklist: Jalur direktori tidak boleh diakhiri dengan garis miring (`/`). Contoh:
/home/admin/dir1/: Daftar hitam direktori tidak berlaku./home/admin/dir*: Mengabaikan file di semua subdirektori direktori/home/admin/yang diawali dengan "dir" selama pengumpulan./home/admin/*/dir: Mengabaikan semua file di subdirektori bernama "dir" di tingkat kedua direktori/home/admin/selama pengumpulan. Misalnya, file di direktori/home/admin/a/dirdiabaikan, sedangkan file di direktori/home/admin/a/b/dirdikumpulkan.
Penyaringan kontainer
Tetapkan kondisi pengumpulan berdasarkan metadata kontainer, seperti variabel lingkungan, label pod, namespace, dan nama kontainer, untuk mengontrol secara tepat log kontainer mana yang dikumpulkan.
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, aktifkan Container Filtering dan klik Add.
Beberapa kondisi digabungkan menggunakan operator logika AND. Semua pencocokan ekspresi reguler didasarkan pada mesin ekspresi reguler RE2 Go, yang memiliki beberapa keterbatasan dibandingkan mesin seperti PCRE. Saat menulis ekspresi reguler, ikuti batasan yang dijelaskan di Lampiran: Batasan ekspresi reguler (penyaringan kontainer).
Daftar Hitam/Putih Variabel Lingkungan: Tentukan kondisi variabel lingkungan untuk kontainer dari mana Anda ingin mengumpulkan log.
Daftar Hitam/Putih Label Pod K8s: Tentukan kondisi label untuk pod tempat kontainer yang akan dikumpulkan berada.
Pencocokan Reguler Nama Pod K8s: Tentukan kontainer yang akan dikumpulkan berdasarkan nama pod.
Pencocokan Reguler Namespace K8s: Tentukan kontainer yang akan dikumpulkan berdasarkan nama namespace.
Pencocokan Reguler Nama Kontainer K8s: Tentukan kontainer yang akan dikumpulkan berdasarkan nama kontainer.
Daftar Hitam/Putih Label Kontainer: Kumpulkan log dari kontainer yang labelnya memenuhi kondisi yang ditentukan. Parameter ini digunakan dalam skenario Docker dan tidak direkomendasikan untuk skenario Kubernetes.
4. Kategorisasi log
Dalam skenario di mana beberapa aplikasi atau instans berbagi format log yang sama, sulit membedakan sumber log. Hal ini menyebabkan kurangnya konteks selama kueri dan efisiensi analisis rendah. Untuk mengatasi masalah ini, konfigurasikan topik dan tag log untuk mencapai asosiasi konteks otomatis dan kategorisasi logis.
Konfigurasikan topik
Jika beberapa aplikasi atau instans memiliki format log yang sama tetapi path berbeda, seperti /apps/app-A/run.log dan /apps/app-B/run.log, sulit membedakan sumber log yang dikumpulkan. Anda dapat menghasilkan topik berdasarkan kelompok mesin, nama kustom, atau ekstraksi path file untuk membedakan log dari aplikasi atau sumber path yang berbeda secara fleksibel.
Langkah konfigurasi: : Pilih metode pembuatan topik. Tiga tipe berikut didukung:
Machine Group Topic: Jika konfigurasi pengumpulan diterapkan pada beberapa kelompok mesin, LoongCollector secara otomatis menggunakan nama kelompok mesin tempat server tersebut berada sebagai nilai field
__topic__untuk diunggah. Ini cocok untuk skenario di mana log dibagi berdasarkan kluster host.Custom: Formatnya adalah
customized://<custom_topic_name>, misalnya,customized://app-login. Ini cocok untuk skenario topik statis dengan pengidentifikasi bisnis tetap.File Path Extraction: Ekstrak informasi kunci dari jalur lengkap file log untuk menandai sumber log secara dinamis. Ini cocok untuk situasi di mana beberapa pengguna atau aplikasi berbagi nama file log yang sama tetapi memiliki path berbeda.
Jika beberapa pengguna atau layanan menulis log ke direktori tingkat atas berbeda tetapi sub-path dan nama file-nya sama, sumber tidak dapat dibedakan hanya berdasarkan nama file. Misalnya:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.logKonfigurasikan File Path Extraction dan gunakan ekspresi reguler untuk mengekstrak informasi kunci dari jalur lengkap. Hasil yang cocok diunggah ke logstore sebagai topik.
Aturan ekstraksi: Berdasarkan grup penangkapan ekspresi reguler
Saat Anda mengonfigurasi ekspresi reguler, sistem secara otomatis menentukan format field output berdasarkan jumlah dan penamaan grup penangkapan. Aturannya sebagai berikut:
Dalam ekspresi reguler untuk jalur file, Anda harus melakukan escape terhadap garis miring (/).
Tipe grup penangkapan
Skenario
Field yang dihasilkan
Contoh Regex
Contoh jalur yang cocok
Field yang dihasilkan
Grup penangkapan tunggal (hanya satu
(.*?))Hanya satu dimensi yang diperlukan untuk membedakan sumber (seperti username, lingkungan)
Menghasilkan field
__topic__\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__:userABeberapa grup penangkapan - tidak bernama (beberapa
(.*?))Beberapa dimensi diperlukan tetapi tidak ada label semantik
Menghasilkan field tag
__tag__:__topic_{i}__, di mana{i}adalah nomor urut grup penangkapan\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA;__tag__:__topic_2__svcABeberapa grup penangkapan - bernama (menggunakan
(?P<name>.*?)Beberapa dimensi diperlukan dan Anda ingin makna field jelas untuk memudahkan kueri dan analisis
Menghasilkan field tag
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
Penambahan tag log
Aktifkan fitur pengayaan tag log untuk mengekstrak informasi kunci dari variabel lingkungan kontainer atau label pod Kubernetes dan melampirkan informasi tersebut sebagai tag. Hal ini mencapai pengelompokan log detail halus.
Langkah konfigurasi: Di bagian Input Configurations pada halaman Logtail Configuration, aktifkan Log Tag Enrichment dan klik Add.
Environment Variables: Konfigurasikan nama variabel lingkungan dan nama tag. Nilai variabel lingkungan disimpan di nama tag.
Nama Variabel Lingkungan: Tentukan nama variabel lingkungan yang akan diekstraksi.
Nama Tag: Nama tag variabel lingkungan.
Pod Labels: Konfigurasikan nama label pod dan nama tag. Nilai label pod disimpan di nama tag.
Nama Label Pod: Nama label pod Kubernetes yang akan diekstraksi.
Nama Tag: Nama tag.
5. Konfigurasi output
Secara default, semua log dikirim ke logstore saat ini dengan kompresi lz4. Untuk mengirim log dari sumber yang sama ke logstore berbeda, ikuti langkah-langkah berikut:
Distribusi dinamis ke beberapa target
-
Mengirim log ke beberapa target hanya tersedia untuk LoongCollector 3.0.0 dan lebih baru. Fitur ini tidak didukung oleh Logtail.
-
Hingga lima target output dapat dikonfigurasi.
-
Setelah Anda mengonfigurasi beberapa target output, konfigurasi pengumpulan tidak lagi terlihat di daftar konfigurasi pengumpulan logstore saat ini. Untuk melihat, memodifikasi, atau menghapus konfigurasi distribusi multi-target, lihat Bagaimana cara mengelola konfigurasi distribusi multi-target?
Prosedur: Di bagian Output Configurations pada halaman Logtail Configuration
-
Klik
 untuk memperluas konfigurasi output.
untuk memperluas konfigurasi output. -
Klik Add Output Targets dan konfigurasikan pengaturan berikut:
-
Logstore: Pilih logstore target.
-
Compression Method: Pilih lz4 atau zstd.
-
Route Settings: Merutekan log berdasarkan field tag. Log yang cocok dengan aturan routing dikirim ke logstore target. Jika konfigurasi ini kosong, semua log yang dikumpulkan dikirim ke logstore target.
-
Tag Name: Nama field tag yang digunakan untuk routing. Masukkan nama field secara langsung, seperti
__path__, tanpa awalan__tag__:. Field tag terbagi menjadi dua kategori:Untuk informasi lebih lanjut tentang tag, lihat Kelola tag pengumpulan LoongCollector.
-
Terkait Agen: Tag ini terkait dengan agen pengumpulan dan independen dari plugin apa pun. Contohnya termasuk
__hostname__dan__user_defined_id__. -
Terkait Plugin Input: Tag ini bergantung pada plugin input, yang menambahkan dan memperkaya log dengan informasi relevan. Contohnya termasuk
__path__untuk pengumpulan file, dan_pod_name_dan_container_name_untuk pengumpulan Kubernetes.
-
-
Tag Value: Jika nilai tag log cocok dengan nilai ini, log dikirim ke logstore target ini.
-
Discard this tag?: Jika Anda mengaktifkan opsi ini, field tag ini dihapus dari log yang diunggah.
-
-
Langkah 3: Konfigurasikan kueri dan analisis
Setelah menyelesaikan pemrosesan log dan konfigurasi plugin, klik Next untuk membuka halaman Query and Analysis Configurations:
Sistem mengaktifkan Full-text Index secara default, yang mendukung pencarian kata kunci pada konten log asli.
Untuk melakukan kueri presisi berdasarkan field, klik Automatic Index Generation setelah Preview Data dimuat di halaman. SLS menghasilkan field index berdasarkan entri pertama dalam data pratinjau.
Setelah menyelesaikan konfigurasi, klik Next untuk menyelesaikan seluruh proses pengumpulan.
Langkah 4: Validasi dan troubleshooting
Setelah konfigurasi pengumpulan selesai dan diterapkan ke kelompok mesin, sistem secara otomatis mendistribusikan konfigurasi dan mulai mengumpulkan log inkremental.
Lihat log yang diunggah
Konfirmasi bahwa ada konten baru di file log: LoongCollector hanya mengumpulkan log inkremental. Jalankan
tail -f /path/to/your/log/filedan picu operasi bisnis untuk memastikan log baru sedang ditulis.Kueri log: Buka halaman kueri dan analisis logstore target, klik Search & Analyze (rentang waktu default adalah 15 menit terakhir), dan periksa apakah log baru masuk. Setiap log teks kontainer Docker yang dikumpulkan berisi field berikut secara default:
Nama field
Deskripsi
__source__
Alamat IP kontainer LoongCollector (Logtail).
_container_ip_
Alamat IP kontainer aplikasi.
__tag__:__hostname__
Nama host Docker tempat LoongCollector (Logtail) berada.
__tag__:__path__
Jalur pengumpulan log.
__tag__:__receive_time__
Waktu log tiba di server.
__tag__:__user_defined_id__
ID kustom kelompok mesin.
FAQ
Koneksi heartbeat kelompok mesin adalah FAIL
Periksa ID pengguna: Jika tipe server Anda bukan ECS, atau jika instance ECS dan proyek dimiliki oleh akun Alibaba Cloud yang berbeda, periksa apakah ID pengguna yang benar ada di direktori yang ditentukan berdasarkan tabel berikut.
Linux: Jalankan perintah
cd /etc/ilogtail/users/ && touch <uid>untuk membuat file ID pengguna.Windows: Buka direktori
C:\LogtailData\users\dan buat file kosong bernama<uid>.
Jika file yang dinamai dengan ID akun Alibaba Cloud proyek saat ini ada di jalur yang ditentukan, ID pengguna dikonfigurasi dengan benar.
Periksa ID kelompok mesin: Jika Anda menggunakan ID kustom untuk kelompok mesin, periksa apakah file
user_defined_idada di direktori yang ditentukan. Jika ada, periksa apakah konten file konsisten dengan ID kustom yang dikonfigurasi untuk kelompok mesin.Sistem
Direktori yang ditentukan
Solusi
Linux
/etc/ilogtail/user_defined_id# Konfigurasikan ID kustom. Jika direktori tidak ada, buat secara manual. echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows
C:\LogtailData\user_defined_idBuat file baru
user_defined_iddi direktoriC:\LogtailDatadan tulis ID kustom ke dalamnya. (Jika direktori tidak ada, buat secara manual.)Jika ID pengguna dan ID kelompok mesin dikonfigurasi dengan benar, lihat Troubleshoot masalah kelompok mesin LoongCollector (Logtail) untuk troubleshooting lebih lanjut.
Tidak ada data yang dikumpulkan untuk log
Periksa log inkremental: Setelah Anda mengonfigurasi LoongCollector (Logtail) untuk pengumpulan, jika tidak ada log baru di file log yang akan dikumpulkan, LoongCollector (Logtail) tidak mengumpulkan log dari file tersebut.
Periksa status heartbeat kelompok mesin: Buka halaman
 Resources > Machine Groups, klik nama kelompok mesin target, dan di bagian , periksa status Heartbeat.
Resources > Machine Groups, klik nama kelompok mesin target, dan di bagian , periksa status Heartbeat.Jika heartbeat OK, kelompok mesin terhubung ke proyek SLS.
Jika heartbeat FAIL: Untuk informasi lebih lanjut tentang cara mengatasi masalah ini, lihat Koneksi heartbeat kelompok mesin adalah FAIL.
Konfirmasi apakah konfigurasi pengumpulan LoongCollector (Logtail) telah diterapkan ke kelompok mesin: Meskipun konfigurasi pengumpulan LoongCollector (Logtail) dibuat, log tidak dikumpulkan jika konfigurasi tidak diterapkan ke kelompok mesin.
Buka halaman
 Resources > Machine Groups dan klik nama kelompok mesin target untuk membuka halaman Machine Group Configurations.
Resources > Machine Groups dan klik nama kelompok mesin target untuk membuka halaman Machine Group Configurations.Di halaman tersebut, lihat Manage Configuration. Sisi kiri menampilkan All Logtail Configurations, dan sisi kanan menampilkan Applied Logtail Configurations. Jika konfigurasi pengumpulan LoongCollector (Logtail) target telah dipindahkan ke area terapan di sebelah kanan, konfigurasi telah berhasil diterapkan ke kelompok mesin target.
Jika konfigurasi pengumpulan LoongCollector (Logtail) target belum dipindahkan ke area terapan di sebelah kanan, klik Modify. Di daftar All Logtail Configurations di sebelah kiri, pilih nama konfigurasi LoongCollector (Logtail) target, klik
 untuk memindahkannya ke area terapan di sebelah kanan, lalu klik Save.
untuk memindahkannya ke area terapan di sebelah kanan, lalu klik Save.
Error pengumpulan log atau format salah
Pendekatan troubleshooting: Situasi ini menunjukkan bahwa koneksi jaringan dan konfigurasi dasar normal. Masalah utamanya adalah ketidakcocokan antara konten log dan aturan parsing. Anda perlu melihat pesan error spesifik untuk menemukan masalah:
Di halaman Logtail Configuration, klik nama konfigurasi LoongCollector (Logtail) yang mengalami error pengumpulan. Di tab Log Collection Error, klik Select Time Range untuk mengatur rentang kueri.
Di bagian , lihat metrik alarm log error dan temukan solusi yang sesuai di Jenis error umum dalam pengumpulan data.
Langkah selanjutnya
Visualisasi data: Gunakan dasbor visualisasi untuk memantau tren metrik utama.
Peringatan otomatis untuk anomali data: Siapkan kebijakan peringatan untuk mengetahui anomali sistem secara real-time.
Perintah umum
Lihat status berjalan LoongCollector (Logtail)
docker exec ${logtail_container_id} /etc/init.d/ilogtaild statusLihat informasi seperti nomor versi, alamat IP, dan waktu startup LoongCollector (Logtail)
docker exec ${logtail_container_id} cat /usr/local/ilogtail/app_info.jsonLihat log berjalan LoongCollector (Logtail)
Log berjalan LoongCollector (Logtail) disimpan di direktori /usr/local/ilogtail/ di dalam kontainer. Nama file-nya adalah ilogtail.LOG, dan file yang diputar disimpan terkompresi sebagai ilogtail.LOG.x.gz. Contoh:
# Lihat log berjalan LoongCollector
docker exec a287de895e40 tail -n 5 /usr/local/ilogtail/loongcollector.LOG
# Lihat log berjalan Logtail
docker exec a287de895e40 tail -n 5 /usr/local/ilogtail/ilogtail.LOGContoh output:
[2025-08-25 09:17:44.610496] [info] [22] /build/loongcollector/file_server/polling/PollingModify.cpp:75 polling modify resume:succeeded
[2025-08-25 09:17:44.610497] [info] [22] /build/loongcollector/file_server/polling/PollingDirFile.cpp:100 polling discovery resume:starts
[2025-08-25 09:17:44.610498] [info] [22] /build/loongcollector/file_server/polling/PollingDirFile.cpp:103 polling discovery resume:succeeded
[2025-08-25 09:17:44.610499] [info] [22] /build/loongcollector/file_server/FileServer.cpp:117 file server resume:succeeded
[2025-08-25 09:17:44.610500] [info] [22] /build/loongcollector/file_server/EventDispatcher.cpp:1019 checkpoint dump:succeededMulai ulang LoongCollector (Logtail)
# Hentikan loongcollector
docker exec a287de895e40 /etc/init.d/ilogtaild stop
# Mulai loongcollector
docker exec a287de895e40 /etc/init.d/ilogtaild startFAQ
Pesan error umum
Fenomena error | Penyebab | Solusi |
| Wilayah proyek tidak konsisten dengan kontainer LoongCollector (Logtail). | Periksa konfigurasi wilayah di |
| Konfigurasi jalur file salah. | Konfirmasi bahwa jalur log di kontainer aplikasi cocok dengan konfigurasi pengumpulan. |
Error log: The parameter is invalid : uuid=none
Deskripsi masalah: Log LoongCollector (Logtail) (/usr/local/ilogtail/ilogtail.LOG) berisi log error The parameter is invalid : uuid=none.
Solusi: Buat file product_uuid di host, masukkan UUID valid apa pun, seperti 169E98C9-ABC0-4A92-B1D2-AA6239C0D261, dan pasang file ini ke direktori /sys/class/dmi/id/product_uuid kontainer LoongCollector (Logtail).
Bagaimana file log atau standard output kontainer yang sama dapat dikumpulkan oleh beberapa konfigurasi pengumpulan secara bersamaan?
Secara default, untuk mencegah duplikasi data, SLS membatasi setiap sumber log hanya dikumpulkan oleh satu konfigurasi pengumpulan:
File log teks hanya dapat cocok dengan satu konfigurasi Logtail.
Standard output kontainer (stdout):
Jika Anda menggunakan templat standard output versi baru, hanya dapat dikumpulkan oleh satu konfigurasi pengumpulan standard output secara default.
Jika Anda menggunakan templat standard output versi lama, tidak diperlukan konfigurasi tambahan, dan secara default mendukung pengumpulan beberapa salinan.
Masuk ke Konsol Simple Log Service dan buka proyek target.
Di panel navigasi kiri, pilih
Logstores dan temukan logstore target.Klik ikon
di sebelah namanya untuk memperluas logstore.Klik Logtail Configuration. Di daftar konfigurasi, temukan konfigurasi Logtail target dan klik Manage Logtail Configuration di kolom Actions.
Di halaman konfigurasi Logtail, klik Edit dan gulir ke bagian Input Configurations:
Untuk mengumpulkan log file teks: Aktifkan Allow File to Be Collected for Multiple Times.
Untuk mengumpulkan standard output kontainer: Nyalakan Allow Collection by Different Logtail Configurations.
Bagaimana cara mengelola konfigurasi distribusi multi-target?
Konfigurasi distribusi multi-target dikaitkan dengan beberapa logstore. Kelola konfigurasi ini dari halaman manajemen tingkat proyek:
-
Masuk ke Konsol Simple Log Service dan klik nama proyek target.
-
Di halaman proyek, pilih
 dari panel navigasi kiri.Catatan
dari panel navigasi kiri.CatatanHalaman ini menyediakan manajemen terpusat untuk semua konfigurasi pengumpulan dalam proyek, termasuk konfigurasi yang tetap ada setelah logstore terkaitnya dihapus secara tidak sengaja.
Lampiran: Penjelasan detail plugin parsing native
Di bagian Processing Configuration pada halaman Logtail Configuration, tambahkan plugin pemrosesan untuk mengonfigurasi pemrosesan terstruktur untuk log mentah. Untuk menambahkan plugin pemrosesan ke konfigurasi pengumpulan yang sudah ada, ikuti langkah-langkah berikut:
Di panel navigasi kiri, pilih
 Logstores dan temukan logstore target.
Logstores dan temukan logstore target.Klik ikon
 di sebelah namanya untuk memperluas logstore.
di sebelah namanya untuk memperluas logstore.Klik Logtail Configuration. Di daftar konfigurasi, temukan konfigurasi Logtail target dan klik Manage Logtail Configuration di kolom Actions.
Di halaman konfigurasi Logtail, klik Edit.
Bagian ini hanya memperkenalkan plugin pemrosesan yang umum digunakan yang mencakup skenario pemrosesan log umum. Untuk informasi lebih lanjut tentang fitur lain, lihat Plugin pemrosesan ekstensi.
Aturan menggabungkan plugin (berlaku untuk LoongCollector / Logtail 2.0 dan versi lebih baru):
Plugin pemrosesan native dan plugin pemrosesan ekstensi dapat digunakan secara independen atau digabungkan sesuai kebutuhan.
Kami merekomendasikan Anda memprioritaskan plugin pemrosesan native karena menawarkan kinerja lebih baik dan stabilitas lebih tinggi.
Jika fitur native tidak dapat memenuhi kebutuhan bisnis Anda, tambahkan plugin pemrosesan ekstensi setelah plugin pemrosesan native yang dikonfigurasi untuk melakukan pemrosesan tambahan.
Batasan urutan:
Semua plugin dijalankan secara berurutan sesuai urutan konfigurasinya, yang membentuk rantai pemrosesan. Perhatikan bahwa Semua plugin pemrosesan native harus mendahului plugin pemrosesan ekstensi apa pun. Setelah Anda menambahkan plugin pemrosesan ekstensi, Anda tidak dapat menambahkan plugin pemrosesan native lagi.
Parsing ekspresi reguler
Ekstrak field log menggunakan ekspresi reguler dan uraikan log menjadi pasangan kunci-nilai. Setiap field dapat dikueri dan dianalisis secara independen.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Menggunakan plugin parsing regex |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih :
Regular Expression: Digunakan untuk mencocokkan log. Mendukung pembuatan otomatis atau input manual:
Pembuatan otomatis:
Klik Generate.
Di Log Sample, sorot konten log yang akan diekstraksi.
Klik Generate Regular Expression.

Input manual: Klik Manually Enter Regular Expression berdasarkan format log.
Setelah menyelesaikan konfigurasi, klik Validate untuk menguji apakah ekspresi reguler dapat mengurai konten log dengan benar.
Extracted Field: Atur nama field (Key) yang sesuai untuk konten log yang diekstraksi (Value).
Untuk informasi lebih lanjut tentang parameter lain, lihat deskripsi parameter konfigurasi umum di Skenario 2: Logging terstruktur.
Parsing separator
Strukturisasi konten log menggunakan separator, dan uraikan menjadi beberapa pasangan kunci-nilai. Separator karakter tunggal dan multi-karakter didukung.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Bagi field berdasarkan karakter yang ditentukan |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih .
Delimiter: Tentukan karakter yang digunakan untuk membagi konten log.
Contoh: Untuk file format CSV, pilih Custom dan masukkan koma (,).
Quote: Jika nilai field berisi separator, Anda harus menentukan quote untuk membungkus field guna mencegah pembagian yang salah.
Extracted Field: Atur nama field (Key) yang sesuai untuk setiap kolom sesuai urutan pemisahan. Aturannya sebagai berikut:
Nama field hanya boleh berisi huruf, angka, dan garis bawah (_).
Harus dimulai dengan huruf atau garis bawah (_).
Panjang maksimum adalah 128 byte.
Untuk informasi lebih lanjut tentang parameter lain, lihat deskripsi parameter konfigurasi umum di Skenario 2: Logging terstruktur.
Parsing JSON standar
Strukturisasi log JSON tipe Objek dengan menguraikannya menjadi pasangan kunci-nilai.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Ekstraksi otomatis kunci-nilai JSON standar |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih .
Original Field: Nilai default adalah content. Field ini digunakan untuk menyimpan konten log mentah yang akan diurai.
Untuk informasi lebih lanjut tentang parameter lain, lihat deskripsi parameter konfigurasi umum di Skenario 2: Logging terstruktur.
Parsing JSON bersarang
Uraikan log JSON bersarang menjadi pasangan kunci-nilai dengan menentukan kedalaman ekspansi.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Kedalaman ekspansi: 0, menggunakan kedalaman ekspansi sebagai awalan | Kedalaman ekspansi: 1, menggunakan kedalaman ekspansi sebagai awalan |
| | |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih :
Original Field: Nama field mentah yang akan diekspansi, misalnya,
content.JSON Expansion Depth: Tingkat ekspansi objek JSON. Nilai 0 menunjukkan ekspansi penuh, yang merupakan nilai default. Nilai 1 menunjukkan tingkat saat ini.
Character to Concatenate Expanded Keys: Penghubung untuk nama field selama ekspansi JSON. Penghubung default adalah garis bawah (_).
Name Prefix of Expanded Keys: Tentukan awalan untuk nama field setelah ekspansi JSON.
Expand Array: Nyalakan sakelar ini untuk mengekspansi array menjadi pasangan kunci-nilai dengan indeks.
Contoh:
{"k":["a","b"]}diekspansi menjadi{"k[0]":"a","k[1]":"b"}.Untuk mengganti nama field yang diekspansi, misalnya dari prefix_s_key_k1 menjadi new_field_name, tambahkan plugin Rename Field untuk menyelesaikan pemetaan.
Untuk informasi lebih lanjut tentang parameter lain, lihat deskripsi parameter konfigurasi umum di Skenario 2: Logging terstruktur.
Parsing array JSON
Gunakan fungsi json_extract function untuk mengekstraksi objek JSON dari array JSON.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Ekstrak struktur array JSON |
| |
Langkah konfigurasi: Pada bagian Processor Configurations di halaman Logtail Configuration, ubah Processing Method menjadi SPL, konfigurasikan SPL Statement, lalu gunakan fungsi json_extract untuk mengekstraksi objek JSON dari array JSON.
Contoh: Ekstrak elemen dari array JSON di field log content dan simpan hasilnya di field baru json1 dan json2.
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Parsing log Apache
Strukturisasi konten log berdasarkan definisi di file konfigurasi log Apache dan uraikan menjadi beberapa pasangan kunci-nilai.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Format Log Umum Apache |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih :
Log Format: combined
APACHE LogFormat Configuration: Sistem secara otomatis mengisi konfigurasi berdasarkan Log Format.
PentingVerifikasi konten yang diisi otomatis untuk memastikan bahwa konten tersebut persis sama dengan LogFormat yang didefinisikan di file konfigurasi server Apache. File tersebut biasanya terletak di /etc/apache2/apache2.conf.
Untuk informasi lebih lanjut tentang parameter lain, lihat deskripsi parameter konfigurasi umum di Skenario 2: Logging terstruktur.
Penyamaran data
Sembunyikan data sensitif dalam log.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Hasil penyamaran |
| |
Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih .
Original Field: Field mentah yang berisi konten log sebelum parsing.
Data Masking Method:
const: Ganti konten sensitif dengan string yang dimodifikasi.
md5: Ganti konten sensitif dengan hash MD5-nya.
Replacement String: Jika Anda mengatur Masking Method ke const, Anda harus memasukkan string untuk mengganti konten sensitif.
Content Expression that Precedes Replaced Content: Digunakan untuk menemukan konten sensitif. Konfigurasikan parameter ini menggunakan sintaks RE2.
Content Expression to Match Replaced Content: Ekspresi untuk konten sensitif. Konfigurasikan parameter ini menggunakan sintaks RE2.
Parsing waktu
Uraikan field waktu dalam log dan atur hasil parsing sebagai nilai field __time__ log.
Contoh efek:
Log mentah tanpa pemrosesan apa pun | Parsing waktu |
|
|

Langkah konfigurasi: Di bagian Processor Configurations pada halaman Logtail Configuration, klik Add Processor dan pilih :
Original Field: Field mentah yang berisi konten log sebelum parsing.
Time Format: Atur format waktu yang sesuai berdasarkan konten waktu dalam log.
Time Zone: Pilih zona waktu field waktu log. Secara default, zona waktu mesin digunakan, yaitu zona waktu lingkungan tempat proses LoongCollector (Logtail) berada.
Lampiran: Batasan ekspresi reguler (penyaringan kontainer)
Ekspresi reguler yang digunakan untuk Container Filtering didasarkan pada mesin RE2 Go, yang memiliki beberapa batasan sintaks dibandingkan mesin lain seperti PCRE. Perhatikan hal berikut saat menulis ekspresi reguler:
1. Perbedaan sintaks grup bernama
Go menggunakan sintaks (?P<name>...) untuk mendefinisikan grup bernama dan tidak mendukung sintaks (?<name>...) dari PCRE.
Contoh yang benar:
(?P<year>\d{4})Sintaks salah:
(?<year>\d{4})
2. Fitur regex yang tidak didukung
Fitur regex umum tetapi kompleks berikut tidak tersedia di RE2. Hindari penggunaannya:
Assertion:
(?=...),(?!...),(?<=...),(?<!...)Ekspresi kondisional:
(?(condition)true|false)Pencocokan rekursif:
(?R),(?0)Referensi subprogram:
(?&name),(?P>name)Grup atomik:
(?>...)
3. Rekomendasi penggunaan
Kami merekomendasikan Anda menggunakan alat seperti Regex101 untuk men-debug ekspresi reguler. Pilih mode Golang (RE2) untuk validasi guna memastikan kompatibilitas. Jika Anda menggunakan sintaks yang tidak didukung yang disebutkan di atas, plugin tidak akan mengurai atau mencocokkan dengan benar.
Lampiran: Perbandingan versi lama dan baru standard output kontainer
Untuk meningkatkan efisiensi penyimpanan log dan konsistensi pengumpulan, format metadata log untuk standard output kontainer telah ditingkatkan. Format baru mengkonsolidasikan metadata ke field __tag__, yang mencapai optimalisasi penyimpanan dan standardisasi format.
Keunggulan utama versi standard output baru
Peningkatan kinerja signifikan
Direkayasa ulang dalam C++, kinerja meningkat 180% hingga 300% dibandingkan implementasi Go lama.
Mendukung plugin native untuk pemrosesan data dan pemrosesan paralel multi-threading, yang sepenuhnya memanfaatkan sumber daya sistem.
Mendukung kombinasi fleksibel plugin native dan Go untuk memenuhi kebutuhan skenario kompleks.
Keandalan lebih tinggi
Mendukung antrian rotasi log standard output. Mekanisme pengumpulan log disatukan dengan mekanisme pengumpulan file, yang memberikan keandalan tinggi dalam skenario dengan rotasi log standard output yang cepat.
Konsumsi sumber daya lebih rendah
Penggunaan CPU berkurang 20% hingga 25%.
Penggunaan memori berkurang 20% hingga 25%.
Konsistensi O&M yang ditingkatkan
Konfigurasi parameter terpadu: Parameter konfigurasi plugin pengumpulan standard output baru konsisten dengan plugin pengumpulan file.
Manajemen metadata terpadu: Penamaan field metadata kontainer dan lokasi penyimpanan log tag disatukan dengan skenario pengumpulan file. Sisi konsumen hanya perlu mempertahankan satu set logika pemrosesan.
Perbandingan fitur versi baru dan lama
Dimensi fitur
Fitur versi lama
Fitur versi baru
Metode penyimpanan
Metadata langsung disematkan dalam konten log sebagai field biasa.
Metadata disimpan terpusat di tag
__tag__.Efisiensi penyimpanan
Setiap log membawa metadata lengkap berulang-ulang, yang mengonsumsi lebih banyak ruang penyimpanan.
Beberapa log dalam konteks yang sama dapat menggunakan kembali metadata, yang menghemat biaya penyimpanan.
Konsistensi format
Tidak konsisten dengan format pengumpulan file kontainer.
Penamaan field dan struktur penyimpanan sepenuhnya selaras dengan pengumpulan file kontainer, yang memberikan pengalaman terpadu.
Metode akses kueri
Dapat dikueri langsung berdasarkan nama field, seperti
_container_name_.Memerlukan akses ke pasangan kunci-nilai yang sesuai melalui
__tag__, seperti__tag__: _container_name_.Tabel pemetaan field metadata kontainer
Nama field versi lama
Nama field versi baru
_container_ip_
__tag__:_container_ip_
_container_name_
__tag__:_container_name_
_image_name_
__tag__:_image_name_
_namespace_
__tag__:_namespace_
_pod_name_
__tag__:_pod_name_
_pod_uid_
__tag__:_pod_uid_
Dalam versi baru, semua field metadata disimpan di area tag log dalam format
__tag__:<key>, bukan disematkan dalam konten log.Dampak perubahan versi baru terhadap pengguna
Adaptasi sisi konsumen: Karena lokasi penyimpanan berubah dari "konten" ke "tag", logika konsumsi log pengguna perlu disesuaikan. Misalnya, Anda harus mengakses field melalui __tag__ selama kueri.
Kompatibilitas SQL: SQL kueri telah secara otomatis diadaptasi untuk kompatibilitas, sehingga pengguna tidak perlu memodifikasi pernyataan kueri mereka untuk memproses log versi baru dan lama secara bersamaan.
Informasi lebih lanjut
Parameter konfigurasi global
Parameter konfigurasi input
Parameter konfigurasi pemrosesan
Wilayah
Masuk ke Konsol Simple Log Service. Di daftar proyek, klik proyek target.
Klik ikon
 di sebelah nama proyek untuk membuka halaman ikhtisar proyek.
di sebelah nama proyek untuk membuka halaman ikhtisar proyek.Di bagian Informasi Dasar, Anda dapat melihat nama wilayah proyek saat ini. Untuk pemetaan antara nama wilayah dan ID Wilayah, lihat tabel berikut.
Wilayah adalah lokasi geografis pusat data fisik tempat layanan cloud dihosting. ID Wilayah adalah pengidentifikasi unik untuk wilayah layanan cloud.
Nama wilayah
ID Wilayah
China (Qingdao)
cn-qingdao
China (Beijing)
cn-beijing
China (Zhangjiakou)
cn-zhangjiakou
China (Hohhot)
cn-huhehaote
China (Ulanqab)
cn-wulanchabu
China (Hangzhou)
cn-hangzhou
China (Shanghai)
cn-shanghai
China (Nanjing - Local Region - Decommissioning)
cn-nanjing
China (Fuzhou - Local Region - Decommissioning)
cn-fuzhou
China (Shenzhen)
cn-shenzhen
China (Heyuan)
cn-heyuan
China (Guangzhou)
cn-guangzhou
Filipina (Manila)
ap-southeast-6
Korea Selatan (Seoul)
ap-northeast-2
Malaysia (Kuala Lumpur)
ap-southeast-3
Jepang (Tokyo)
ap-northeast-1
Thailand (Bangkok)
ap-southeast-7
China (Chengdu)
cn-chengdu
Singapura
ap-southeast-1
Indonesia (Jakarta)
ap-southeast-5
China (Hong Kong)
cn-hongkong
Jerman (Frankfurt)
eu-central-1
AS (Virginia)
us-east-1
AS (Silicon Valley)
us-west-1
Inggris (London)
eu-west-1
UAE (Dubai)
me-east-1
SAU (Riyadh - Partner Region)
me-central-1