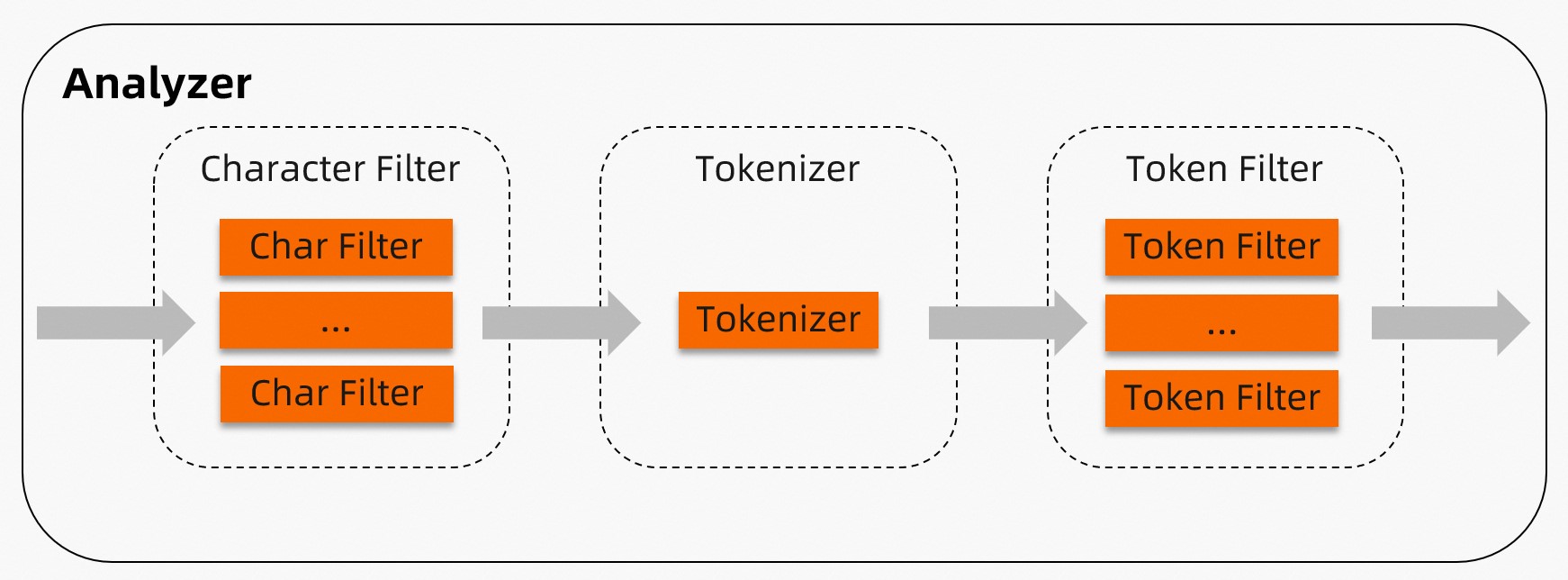
Analyzer mengurai dan memecah bidang teks sehingga TairSearch dapat membangun indeks serta menjawab kueri teks lengkap. Setiap analyzer menjalankan tiga tahap secara berurutan: filter karakter, tokenizer, dan filter token. TairSearch menyediakan sembilan analyzer bawaan. Untuk kebutuhan khusus, Anda dapat membuat analyzer kustom dari komponen-komponen individual.
| Tahap | Tujuan | Jumlah per analyzer |
|---|---|---|
| Filter karakter | Melakukan pra-pemrosesan teks mentah sebelum tokenisasi (misalnya, mengganti :) dengan _happy_) | Nol atau lebih, dijalankan berurutan |
| Tokenizer | Memecah teks yang telah diproses menjadi token | Tepat satu |
| Filter token | Melakukan pasca-pemrosesan setiap token (misalnya, mengubah ke huruf kecil, menghapus stop word, stemming) | Nol atau lebih, dijalankan berurutan |
Pilih analyzer
| Analyzer | Paling cocok untuk | Tokenisasi berdasarkan | Mengubah ke huruf kecil | Menyaring stop words |
|---|---|---|---|---|
| Standard | Sebagian besar bahasa | Batas kata Unicode | Ya | Ya |
| Stop | Sebagian besar bahasa (fokus pada stop word) | Karakter non-huruf | Ya | Ya |
| Jieba | Teks bahasa Tionghoa | Kamus terlatih | Hanya token bahasa Inggris | Ya |
| IK | Teks bahasa Tionghoa (kompatibel dengan Elasticsearch) | Kamus terlatih (dua mode) | Ya (default) | Opsional |
| Pattern | Logika pembatas kustom | Pola regex | Opsional | Opsional |
| Whitespace | Teks yang telah ditokenisasi atau terstruktur | Karakter whitespace | Tidak | Tidak |
| Simple | Teks Barat, tidak peka huruf besar/kecil | Karakter non-huruf | Ya | Tidak |
| Keyword | Bidang pencocokan eksak | Tidak ada pemecahan (seluruh bidang = satu token) | Tidak | Tidak |
| Language | Bahasa alami tertentu | Aturan spesifik bahasa | Ya | Ya |
Cara kerja
Analyzer memproses dokumen melalui tiga tahap berurutan.
Tahap 1 — Filter karakter: Nol atau lebih filter karakter melakukan pra-pemrosesan teks dokumen mentah sesuai urutan yang ditentukan. Misalnya, filter karakter pemetaan dapat mengganti "(:" dengan "happy" sebelum tokenisasi dimulai.
Tahap 2 — Tokenizer: Tepat satu tokenizer memecah teks (yang mungkin telah difilter) menjadi token. Misalnya, tokenizer whitespace memecah "I am very happy" menjadi ["I", "am", "very", "happy"].
Tahap 3 — Filter token: Nol atau lebih filter token melakukan pasca-pemrosesan terhadap token dari tokenizer sesuai urutan yang ditentukan. Misalnya, filter token stop menghapus kata umum seperti "the" dan "is".
Analyzer bawaan
Standard
Analyzer standard merupakan pilihan default untuk sebagian besar bahasa. Analyzer ini memecah teks berdasarkan batas kata Unicode (sesuai Unicode Standard Annex #29), mengubah semua token menjadi huruf kecil, serta menghapus stop word umum.
Components: standard tokenizer → lowercase token filter → stop token filter
Tidak ada filter karakter yang disertakan.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
stopwords | Array stop word yang akan disaring. Menggantikan daftar default sepenuhnya. | Lihat di bawah |
max_token_length | Panjang maksimum karakter per token. Token yang lebih panjang dari nilai ini akan dipotong pada batas tersebut. | 255 |
Stop word default:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in",
"into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the",
"their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "standard"
}
}
}
}// Stop word dan panjang token kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard",
"max_token_length": 10,
"stopwords": ["memory", "disk", "is", "a"]
}
}
}
}
}Stop
Analyzer stop memecah teks pada setiap karakter non-huruf, mengubah semua token menjadi huruf kecil, serta menghapus stop word.
Components: lowercase tokenizer → stop token filter
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
stopwords | Array stop word yang akan disaring. Menggantikan daftar default sepenuhnya. | Sama seperti standard |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "stop"
}
}
}
}// Stop word kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "stop",
"stopwords": ["memory", "disk", "is", "a"]
}
}
}
}
}Jieba
Analyzer jieba direkomendasikan untuk teks bahasa Tionghoa. Analyzer ini memecah teks menggunakan segmentasi berbasis kamus jieba, mengubah token bahasa Inggris menjadi huruf kecil, serta menghapus stop word.
Components: jieba tokenizer → lowercase token filter → stop token filter
Analyzer jieba memuat kamus bawaan berukuran 20 MB ke dalam memori. Hanya satu salinan yang dimuat secara global. Penggunaan pertama jieba mungkin menyebabkan lonjakan latensi singkat saat kamus dimuat.
Kata dalam kamus kustom tidak boleh mengandung spasi atau karakter berikut:
\t,\n,,,。
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
userwords | Array string yang ditambahkan ke kamus default. Lihat kamus default Jiebakamus default jieba. | Kosong |
use_hmm | Menggunakan model Markov tersembunyi (HMM) untuk menangani kata di luar kamus. | true |
stopwords | Array stop word yang akan disaring. Menggantikan daftar default sepenuhnya. Lihat stop word default Jiebastop word default jieba. | Daftar bawaan |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "jieba"
}
}
}
}// Kamus kustom, stop word, dan HMM
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "jieba",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"use_hmm": true
}
}
}
}
}IK
Analyzer IK memecah teks bahasa Tionghoa dan kompatibel dengan plug-in analyzer IK untuk Alibaba Cloud Elasticsearch. Analyzer ini mendukung dua mode:
`ik_max_word`: mengidentifikasi semua token yang mungkin.
`ik_smart`: menyaring hasil mode
ik_max_worduntuk mengidentifikasi token yang paling mungkin.
Komponen: IK tokenizer (tidak ada filter token secara default)
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
stopwords | Array stop word yang akan disaring. Menggantikan daftar default sepenuhnya. | Sama seperti standard |
userwords | Array string yang ditambahkan ke kamus IK default. Lihat kamus IK default. | Kosong |
quantifiers | Array kuantifier yang ditambahkan ke kamus kuantifier IK default. Lihat kamus kuantifier default. | Kosong |
enable_lowercase | Mengonversi huruf kapital menjadi huruf kecil sebelum tokenisasi. | true |
Jika kamus kustom Anda berisi huruf kapital, atur enable_lowercase ke false. Konversi ke huruf kecil terjadi sebelum pemecahan, sehingga entri kapital dalam kamus tidak akan pernah cocok.
Contoh konfigurasi:
// Konfigurasi default: kedua mode IK
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "ik_smart"
},
"f1": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}// Stop word, kamus, dan kuantifier kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_ik_smart_analyzer": {
"type": "ik_smart",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"quantifiers": ["ns"],
"enable_lowercase": false
},
"my_ik_max_word_analyzer": {
"type": "ik_max_word",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"quantifiers": ["ns"],
"enable_lowercase": false
}
}
}
}
}Pattern
Analyzer pattern memecah teks menggunakan ekspresi reguler. Secara default, teks yang cocok diperlakukan sebagai pembatas (token adalah teks di antara kecocokan). Analyzer ini juga mengubah token menjadi huruf kecil dan menyaring stop word.
Components: pattern tokenizer → lowercase token filter → stop token filter
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
pattern | Ekspresi reguler. Teks yang cocok dengan pola digunakan sebagai pembatas. Lihat sintaks RE2. | \W+ |
stopwords | Array stop word. Menggantikan daftar default sepenuhnya. | Sama seperti standard |
lowercase | Mengonversi token menjadi huruf kecil. | true |
flags | Diatur ke CASE_INSENSITIVE agar regex tidak peka huruf besar/kecil. | Kosong (peka huruf besar/kecil) |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "pattern"
}
}
}
}// Pola kustom dengan pencocokan tidak peka huruf besar/kecil
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "pattern",
"pattern": "\\'([^\\']+)\\'",
"stopwords": ["aaa", "@"],
"lowercase": false,
"flags": "CASE_INSENSITIVE"
}
}
}
}
}Whitespace
Analyzer whitespace memecah teks pada karakter whitespace. Analyzer ini tidak mengubah token menjadi huruf kecil atau menghapus stop word.
Komponen: whitespace tokenizer
Parameter opsional: Tidak ada
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}Simple
Analyzer simple memecah teks pada setiap karakter non-huruf dan mengubah semua token menjadi huruf kecil. Analyzer ini tidak menyaring stop word.
Komponen: lowercase tokenizer
Parameter opsional: Tidak ada
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "simple"
}
}
}
}Keyword
Analyzer keyword memperlakukan seluruh nilai bidang sebagai satu token tanpa pemecahan apa pun. Gunakan analyzer ini untuk bidang yang memerlukan kueri pencocokan eksak, seperti ID, kode status, atau tag.
Komponen: keyword tokenizer
Parameter opsional: Tidak ada
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "keyword"
}
}
}
}Language
Analyzer language mendukung tokenisasi spesifik bahasa dan penghapusan stop word untuk sekumpulan bahasa tetap: arabic, cjk, chinese, brazilian, czech, german, greek, persian, french, dutch, dan russian.
Parameter opsional:
| Parameter | Deskripsi | Default | Bahasa yang didukung |
|---|---|---|---|
stopwords | Array stop word. Menggantikan daftar default. Lihat Lampiran 4 untuk daftar default. | Spesifik bahasa | Semua kecuali chinese |
stem_exclusion | Array kata yang batang katanya tidak diekstraksi. Misalnya, menambahkan "apples" mencegahnya direduksi menjadi "apple". | Kosong | brazilian, german, french, dutch |
Stop word analyzer chinese tidak dapat dimodifikasi.Contoh konfigurasi:
// Konfigurasi default (Arab)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "arabic"
}
}
}
}// Stop word dan pengecualian stemming kustom (Jerman)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "german",
"stopwords": ["ein"],
"stem_exclusion": ["speicher"]
}
}
}
}
}Analyzer kustom
Buat analyzer kustom ketika tidak ada analyzer bawaan yang sesuai dengan kebutuhan Anda. Definisikan analyzer di settings dan rujuk berdasarkan nama di mappings.
Parameter:
| Parameter | Wajib | Deskripsi | Nilai valid |
|---|---|---|---|
type | Ya | Mengidentifikasi ini sebagai analyzer kustom. | custom |
tokenizer | Ya | Tokenizer yang akan digunakan. Hanya satu yang diizinkan. | whitespace, lowercase, standard, classic, letter, keyword, jieba, pattern, ik_max_word, ik_smart |
char_filter | Tidak | Array filter karakter yang diterapkan sebelum tokenisasi. | mapping (lihat Lampiran 1) |
filter | Tidak | Array filter token yang diterapkan setelah tokenisasi. | classic, elision, lowercase, snowball, stop, asciifolding, length, arabic_normalization, persian_normalization (lihat Lampiran 3) |
Contoh: analyzer kustom dengan penggantian emotikon dan penghapusan stop word
// Filter karakter mengganti emotikon dan memperluas "&" sebelum tokenisasi.
// Tokenizer whitespace memecah berdasarkan spasi.
// Filter token mengubah ke huruf kecil dan menghapus stop word.
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase", "stop"],
"char_filter": ["emoticons", "conjunctions"]
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":) => _happy_", ":( => _sad_"]
},
"conjunctions": {
"type": "mapping",
"mappings": ["&=>and"]
}
}
}
}
}Lampiran 1: Filter karakter yang didukung
Mapping character filter
Mengganti string tertentu menggunakan pasangan kunci-nilai. Ketika input berisi kunci, kunci tersebut diganti dengan nilai yang sesuai. Beberapa filter karakter pemetaan dapat digunakan dalam satu analyzer.
Parameter:
| Parameter | Wajib | Deskripsi |
|---|---|---|
mappings | Ya | Array aturan penggantian. Setiap aturan harus menggunakan format "key => value". Contoh: "& => and". |
Contoh konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"char_filter": ["emoticons"]
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":) => _happy_", ":( => _sad_"]
}
}
}
}
}Lampiran 2: Tokenizer yang didukung
whitespace
Memecah teks pada karakter whitespace. Token yang melebihi max_token_length dipotong pada batas tersebut.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
max_token_length | Panjang maksimum karakter per token. Token yang lebih panjang dari nilai ini dipotong pada batas tersebut. | 255 |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace"
}
}
}
}
}// Panjang token maksimum kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "whitespace",
"max_token_length": 2
}
}
}
}
}standard
Memecah teks menggunakan algoritma Segmentasi Teks Unicode (Unicode Standard Annex #29). Cocok untuk sebagian besar bahasa.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
max_token_length | Panjang maksimum karakter per token. Token yang lebih panjang dari nilai ini dipotong pada batas tersebut. | 255 |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard"
}
}
}
}
}// Panjang token maksimum kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "standard",
"max_token_length": 2
}
}
}
}
}classic
Memecah teks menggunakan aturan tata bahasa Inggris dan menangani pola tertentu secara khusus:
Memecah pada tanda baca dan menghapusnya. Titik (
.) yang diapit oleh karakter non-whitespace dipertahankan — misalnya,red.appletidak dipecah, tetapired. applemenghasilkanreddanapple.Memecah pada tanda hubung, kecuali jika token berisi angka (diinterpretasikan sebagai nomor produk dan dipertahankan utuh).
Mengenali alamat email dan hostname sebagai satu token.
Token yang melebihi max_token_length dilewati, bukan dipecah.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
max_token_length | Panjang maksimum karakter per token. Token yang lebih panjang dari nilai ini dilewati. | 255 |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "classic"
}
}
}
}
}// Panjang token maksimum kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "classic",
"max_token_length": 2
}
}
}
}
}letter
Memecah teks pada setiap karakter non-huruf. Berfungsi baik untuk bahasa Eropa.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "letter"
}
}
}
}
}lowercase
Memecah teks pada setiap karakter non-huruf dan mengonversi semua token menjadi huruf kecil. Setara dengan menggabungkan tokenizer letter dengan filter token lowercase, tetapi lebih cepat karena hanya melintasi dokumen sekali.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "lowercase"
}
}
}
}
}keyword
Memperlakukan seluruh input sebagai satu token tanpa pemecahan. Biasanya dipasangkan dengan filter token seperti lowercase.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "keyword"
}
}
}
}
}jieba
Memecah teks bahasa Tionghoa menggunakan kamus terlatih. Direkomendasikan untuk bidang berbahasa Tionghoa.
Kata dalam kamus kustom tidak boleh mengandung spasi atau karakter berikut: \t, \n, ,, 。
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
userwords | Array string yang ditambahkan ke kamus default. Lihat kamus default jieba. | Kosong |
use_hmm | Menggunakan model Markov tersembunyi (HMM) untuk menangani kata di luar kamus. | true |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "jieba"
}
}
}
}
}// Kamus kustom
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "jieba",
"userwords": ["Redis", "open-source", "flexible"],
"use_hmm": true
}
}
}
}
}pattern
Memecah teks menggunakan ekspresi reguler. Secara default, teks yang cocok diperlakukan sebagai pembatas. Gunakan parameter group untuk memperlakukan teks yang cocok sebagai token.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
pattern | Ekspresi reguler. Lihat sintaks RE2. | \W+ |
group | Mengontrol cara hasil regex digunakan. -1 menggunakan teks yang cocok sebagai pembatas. 0 menggunakan kecocokan penuh sebagai token. 1 atau lebih tinggi menggunakan grup tangkapan yang sesuai sebagai token. | -1 |
flags | Diatur ke CASE_INSENSITIVE agar regex tidak peka huruf besar/kecil. | Kosong (peka huruf besar/kecil) |
Contoh perilaku `group`:
Regex: "a(b+)c", input: "abbbcdefabc"
group: 0→ token:[ abbbc, abc ](kecocokan penuh)group: 1→ token:[ bbb, b ](grup tangkapan pertama)
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "pattern"
}
}
}
}
}// Pola kustom dengan grup tangkapan
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "pattern_tokenizer"
}
},
"tokenizer": {
"pattern_tokenizer": {
"type": "pattern",
"pattern": "AB(A(\\w+)C)",
"flags": "CASE_INSENSITIVE",
"group": 2
}
}
}
}
}IK
Memecah teks bahasa Tionghoa. Mendukung dua mode:
`ik_max_word`: mengidentifikasi semua token yang mungkin (granularitas maksimum).
`ik_smart`: mengidentifikasi token yang paling mungkin (granularitas lebih kasar).
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
stopwords | Array stop word. Menggantikan daftar default sepenuhnya. | Sama seperti standard |
userwords | Array string yang ditambahkan ke kamus IK default. Lihat kamus IK default. | Kosong |
quantifiers | Array kuantifier yang ditambahkan ke kamus kuantifier default. Lihat kamus kuantifier default. | Kosong |
enable_lowercase | Mengonversi huruf kapital menjadi huruf kecil sebelum tokenisasi. | true |
Jika kamus kustom Anda berisi huruf kapital, atur enable_lowercase ke false. Konversi ke huruf kecil terjadi sebelum pemecahan.
Contoh konfigurasi:
// Konfigurasi default: kedua mode IK
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_ik_smart_analyzer": {
"type": "custom",
"tokenizer": "ik_smart"
},
"my_custom_ik_max_word_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word"
}
}
}
}
}// Kamus, stop word, dan kuantifier kustom
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_ik_smart_analyzer": {
"type": "custom",
"tokenizer": "my_ik_smart_tokenizer"
},
"my_custom_ik_max_word_analyzer": {
"type": "custom",
"tokenizer": "my_ik_max_word_tokenizer"
}
},
"tokenizer": {
"my_ik_smart_tokenizer": {
"type": "ik_smart",
"userwords": ["The tokenizer for the Chinese language", "The custom stop words"],
"stopwords": ["about", "test"],
"quantifiers": ["ns"],
"enable_lowercase": false
},
"my_ik_max_word_tokenizer": {
"type": "ik_max_word",
"userwords": ["The tokenizer for the Chinese language", "The custom stop words"],
"stopwords": ["about", "test"],
"quantifiers": ["ns"],
"enable_lowercase": false
}
}
}
}
}Lampiran 3: Filter token yang didukung
classic
Menghapus 's posesif dari akhir token dan menghapus titik dari akronim. Misalnya, Fig. menjadi Fig.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "classic",
"filter": ["classic"]
}
}
}
}
}elision
Menghapus elisi tertentu dari awal token. Terutama digunakan untuk teks bahasa Prancis (misalnya, l'avion → avion).
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
articles | Array elisi yang akan dihapus. Menggantikan daftar default sepenuhnya. | ["l", "m", "t", "qu", "n", "s", "j"] |
articles_case | Apakah pencocokan elisi peka huruf besar/kecil. | false |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["elision"]
}
}
}
}
}// Elisi kustom dengan pencocokan peka huruf besar/kecil
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["elision_filter"]
}
},
"filter": {
"elision_filter": {
"type": "elision",
"articles": ["l", "m", "t", "qu", "n", "s", "j"],
"articles_case": true
}
}
}
}
}lowercase
Mengonversi semua token menjadi huruf kecil.
Parameter opsional:
| Parameter | Deskripsi | Nilai valid |
|---|---|---|
language | Menerapkan aturan pengubahan huruf kecil spesifik bahasa. Jika tidak diatur, aturan standar bahasa Inggris yang berlaku. | greek, russian |
Contoh konfigurasi:
// Konfigurasi default (Inggris)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase"]
}
}
}
}
}// Pengubahan huruf kecil spesifik bahasa (Yunani dan Rusia)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_greek_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_russian_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_greek_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["greek_lowercase"]
},
"my_custom_russian_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["russian_lowercase"]
}
},
"filter": {
"greek_lowercase": {
"type": "lowercase",
"language": "greek"
},
"russian_lowercase": {
"type": "lowercase",
"language": "russian"
}
}
}
}
}snowball
Menyaring batang kata dari setiap token. Misalnya, cats menjadi cat dan running menjadi run.
Parameter opsional:
| Parameter | Deskripsi | Default | Nilai valid |
|---|---|---|---|
language | Bahasa yang aturan stemming-nya diterapkan. | english | english, german, french, dutch |
Contoh konfigurasi:
// Konfigurasi default (Inggris)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["snowball"]
}
}
}
}
}// Stemming bahasa Inggris dengan tokenizer standard
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["my_filter"]
}
},
"filter": {
"my_filter": {
"type": "snowball",
"language": "english"
}
}
}
}
}stop
Menghapus stop word dari aliran token.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
stopwords | Array stop word. Menggantikan daftar default sepenuhnya. | Sama seperti standard |
ignoreCase | Apakah pencocokan stop word tidak peka huruf besar/kecil. | false |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["stop"]
}
}
}
}
}// Stop word kustom dengan pencocokan tidak peka huruf besar/kecil
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["stop_filter"]
}
},
"filter": {
"stop_filter": {
"type": "stop",
"stopwords": ["the"],
"ignore_case": true
}
}
}
}
}asciifolding
Mengonversi karakter alfabet, numerik, dan simbolik di luar blok Unicode Latin Dasar ke ekuivalen ASCII-nya. Misalnya, é menjadi e dan ü menjadi u. Gunakan filter ini untuk menormalisasi karakter beraksen dalam teks Eropa.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["asciifolding"]
}
}
}
}
}length
Menghapus token yang lebih pendek atau lebih panjang dari panjang karakter yang ditentukan.
Parameter opsional:
| Parameter | Deskripsi | Default |
|---|---|---|
min | Jumlah minimum karakter yang harus dimiliki token agar dipertahankan. | 0 |
max | Jumlah maksimum karakter yang boleh dimiliki token agar dipertahankan. | 2147483647 (2^31 - 1) |
Contoh konfigurasi:
// Konfigurasi default
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["length"]
}
}
}
}
}// Pertahankan hanya token antara 2 hingga 5 karakter
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["length_filter"]
}
},
"filter": {
"length_filter": {
"type": "length",
"max": 5,
"min": 2
}
}
}
}
}Normalization
Menormalisasi karakter spesifik bahasa. Gunakan arabic_normalization untuk teks Arab dan persian_normalization untuk teks Persia. Pasangkan filter ini dengan tokenizer standard untuk hasil terbaik.
Konfigurasi:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_arabic_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_persian_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_arabic_analyzer": {
"type": "custom",
"tokenizer": "arabic",
"filter": ["arabic_normalization"]
},
"my_persian_analyzer": {
"type": "custom",
"tokenizer": "arabic",
"filter": ["persian_normalization"]
}
}
}
}
}Lampiran 4: Stop word default untuk analyzer bahasa
arabic
["من","ومن","منها","منه","في","وفي","فيها","فيه","و","ف","ثم","او","أو","ب","بها","به","ا","أ","اى","اي","أي","أى","لا","ولا","الا","ألا","إلا","لكن","ما","وما","كما","فما","عن","مع","اذا","إذا","ان","أن","إن","انها","أنها","إنها","انه","أنه","إنه","بان","بأن","فان","فأن","وان","وأن","وإن","التى","التي","الذى","الذي","الذين","الى","الي","إلى","إلي","على","عليها","عليه","اما","أما","إما","ايضا","أيضا","كل","وكل","لم","ولم","لن","ولن","هى","هي","هو","وهى","وهي","وهو","فهى","فهي","فهو","انت","أنت","لك","لها","له","هذه","هذا","تلك","ذلك","هناك","كانت","كان","يكون","تكون","وكانت","وكان","غير","بعض","قد","نحو","بين","بينما","منذ","ضمن","حيث","الان","الآن","خلال","بعد","قبل","حتى","عند","عندما","لدى","جميع"]cjk
["with","will","to","this","there","then","the","t","that","such","s","on","not","no","it","www","was","is","","into","their","or","in","if","for","by","but","they","be","these","at","are","as","and","of","a"]brazilian
["uns","umas","uma","teu","tambem","tal","suas","sobre","sob","seu","sendo","seja","sem","se","quem","tua","que","qualquer","porque","por","perante","pelos","pelo","outros","outro","outras","outra","os","o","nesse","nas","na","mesmos","mesmas","mesma","um","neste","menos","quais","mediante","proprio","logo","isto","isso","ha","estes","este","propios","estas","esta","todas","esses","essas","toda","entre","nos","entao","em","eles","qual","elas","tuas","ela","tudo","do","mesmo","diversas","todos","diversa","seus","dispoem","ou","dispoe","teus","deste","quer","desta","diversos","desde","quanto","depois","demais","quando","essa","deles","todo","pois","dele","dela","dos","de","da","nem","cujos","das","cujo","durante","cujas","portanto","cuja","contudo","ele","contra","como","com","pelas","assim","as","aqueles","mais","esse","aquele","mas","apos","aos","aonde","sua","e","ao","antes","nao","ambos","ambas","alem","ainda","a"]czech
["a","s","k","o","i","u","v","z","dnes","cz","tímto","budeš","budem","byli","jseš","muj","svým","ta","tomto","tohle","tuto","tyto","jej","zda","proc","máte","tato","kam","tohoto","kdo","kterí","mi","nám","tom","tomuto","mít","nic","proto","kterou","byla","toho","protože","asi","ho","naši","napište","re","což","tím","takže","svých","její","svými","jste","aj","tu","tedy","teto","bylo","kde","ke","pravé","ji","nad","nejsou","ci","pod","téma","mezi","pres","ty","pak","vám","ani","když","však","neg","jsem","tento","clánku","clánky","aby","jsme","pred","pta","jejich","byl","ješte","až","bez","také","pouze","první","vaše","která","nás","nový","tipy","pokud","muže","strana","jeho","své","jiné","zprávy","nové","není","vás","jen","podle","zde","už","být","více","bude","již","než","který","by","které","co","nebo","ten","tak","má","pri","od","po","jsou","jak","další","ale","si","se","ve","to","jako","za","zpet","ze","do","pro","je","na","atd","atp","jakmile","pricemž","já","on","ona","ono","oni","ony","my","vy","jí","ji","me","mne","jemu","tomu","tem","temu","nemu","nemuž","jehož","jíž","jelikož","jež","jakož","nacež"]german
["wegen","mir","mich","dich","dir","ihre","wird","sein","auf","durch","ihres","ist","aus","von","im","war","mit","ohne","oder","kein","wie","was","es","sie","mein","er","du","daß","dass","die","als","ihr","wir","der","für","das","einen","wer","einem","am","und","eines","eine","in","einer"]greek
["ο","η","το","οι","τα","του","τησ","των","τον","την","και","κι","κ","ειμαι","εισαι","ειναι","ειμαστε","ειστε","στο","στον","στη","στην","μα","αλλα","απο","για","προσ","με","σε","ωσ","παρα","αντι","κατα","μετα","θα","να","δε","δεν","μη","μην","επι","ενω","εαν","αν","τοτε","που","πωσ","ποιοσ","ποια","ποιο","ποιοι","ποιεσ","ποιων","ποιουσ","αυτοσ","αυτη","αυτο","αυτοι","αυτων","αυτουσ","αυτεσ","αυτα","εκεινοσ","εκεινη","εκεινο","εκεινοι","εκεινεσ","εκεινα","εκεινων","εκεινουσ","οπωσ","ομωσ","ισωσ","οσο","οτι"]persian
["انان","نداشته","سراسر","خياه","ايشان","وي","تاكنون","بيشتري","دوم","پس","ناشي","وگو","يا","داشتند","سپس","هنگام","هرگز","پنج","نشان","امسال","ديگر","گروهي","شدند","چطور","ده","و","دو","نخستين","ولي","چرا","چه","وسط","ه","كدام","قابل","يك","رفت","هفت","همچنين","در","هزار","بله","بلي","شايد","اما","شناسي","گرفته","دهد","داشته","دانست","داشتن","خواهيم","ميليارد","وقتيكه","امد","خواهد","جز","اورده","شده","بلكه","خدمات","شدن","برخي","نبود","بسياري","جلوگيري","حق","كردند","نوعي","بعري","نكرده","نظير","نبايد","بوده","بودن","داد","اورد","هست","جايي","شود","دنبال","داده","بايد","سابق","هيچ","همان","انجا","كمتر","كجاست","گردد","كسي","تر","مردم","تان","دادن","بودند","سري","جدا","ندارند","مگر","يكديگر","دارد","دهند","بنابراين","هنگامي","سمت","جا","انچه","خود","دادند","زياد","دارند","اثر","بدون","بهترين","بيشتر","البته","به","براساس","بيرون","كرد","بعضي","گرفت","توي","اي","ميليون","او","جريان","تول","بر","مانند","برابر","باشيم","مدتي","گويند","اكنون","تا","تنها","جديد","چند","بي","نشده","كردن","كردم","گويد","كرده","كنيم","نمي","نزد","روي","قصد","فقط","بالاي","ديگران","اين","ديروز","توسط","سوم","ايم","دانند","سوي","استفاده","شما","كنار","داريم","ساخته","طور","امده","رفته","نخست","بيست","نزديك","طي","كنيد","از","انها","تمامي","داشت","يكي","طريق","اش","چيست","روب","نمايد","گفت","چندين","چيزي","تواند","ام","ايا","با","ان","ايد","ترين","اينكه","ديگري","راه","هايي","بروز","همچنان","پاعين","كس","حدود","مختلف","مقابل","چيز","گيرد","ندارد","ضد","همچون","سازي","شان","مورد","باره","مرسي","خويش","برخوردار","چون","خارج","شش","هنوز","تحت","ضمن","هستيم","گفته","فكر","بسيار","پيش","براي","روزهاي","انكه","نخواهد","بالا","كل","وقتي","كي","چنين","كه","گيري","نيست","است","كجا","كند","نيز","يابد","بندي","حتي","توانند","عقب","خواست","كنند","بين","تمام","همه","ما","باشند","مثل","شد","اري","باشد","اره","طبق","بعد","اگر","صورت","غير","جاي","بيش","ريزي","اند","زيرا","چگونه","بار","لطفا","مي","درباره","من","ديده","همين","گذاري","برداري","علت","گذاشته","هم","فوق","نه","ها","شوند","اباد","همواره","هر","اول","خواهند","چهار","نام","امروز","مان","هاي","قبل","كنم","سعي","تازه","را","هستند","زير","جلوي","عنوان","بود"]french
["ô","être","vu","vous","votre","un","tu","toute","tout","tous","toi","tiens","tes","suivant","soit","soi","sinon","siennes","si","se","sauf","s","quoi","vers","qui","quels","ton","quelle","quoique","quand","près","pourquoi","plus","à","pendant","partant","outre","on","nous","notre","nos","tienne","ses","non","qu","ni","ne","mêmes","même","moyennant","mon","moins","va","sur","moi","miens","proche","miennes","mienne","tien","mien","n","malgré","quelles","plein","mais","là","revoilà","lui","leurs","","toutes","le","où","la","l","jusque","jusqu","ils","hélas","ou","hormis","laquelle","il","eu","nôtre","etc","est","environ","une","entre","en","son","elles","elle","dès","durant","duquel","été","du","voici","par","dont","donc","voilà","hors","doit","plusieurs","diverses","diverse","divers","devra","devers","tiennes","dessus","etre","dessous","desquels","desquelles","ès","et","désormais","des","te","pas","derrière","depuis","delà","hui","dehors","sans","dedans","debout","vôtre","de","dans","nôtres","mes","d","y","vos","je","concernant","comme","comment","combien","lorsque","ci","ta","nບnmoins","lequel","chez","contre","ceux","cette","j","cet","seront","que","ces","leur","certains","certaines","puisque","certaine","certain","passé","cependant","celui","lesquelles","celles","quel","celle","devant","cela","revoici","eux","ceci","sienne","merci","ce","c","siens","les","avoir","sous","avec","pour","parmi","avant","car","avait","sont","me","auxquels","sien","sa","excepté","auxquelles","aux","ma","autres","autre","aussi","auquel","aujourd","au","attendu","selon","après","ont","ainsi","ai","afin","vôtres","lesquels","a"]dutch
["andere","uw","niets","wil","na","tegen","ons","wordt","werd","hier","eens","onder","alles","zelf","hun","dus","kan","ben","meer","iets","me","veel","omdat","zal","nog","altijd","ja","want","u","zonder","deze","hebben","wie","zij","heeft","hoe","nu","heb","naar","worden","haar","daar","der","je","doch","moet","tot","uit","bij","geweest","kon","ge","zich","wezen","ze","al","zo","dit","waren","men","mijn","kunnen","wat","zou","dan","hem","om","maar","ook","er","had","voor","of","als","reeds","door","met","over","aan","mij","was","is","geen","zijn","niet","iemand","het","hij","een","toen","in","toch","die","dat","te","doen","ik","van","op","en","de"]russian
["а","без","более","бы","был","была","были","было","быть","в","вам","вас","весь","во","вот","все","всего","всех","вы","где","да","даже","для","до","его","ее","ей","ею","если","есть","еще","же","за","здесь","и","из","или","им","их","к","как","ко","когда","кто","ли","либо","мне","может","мы","на","надо","наш","не","него","нее","нет","ни","них","но","ну","о","об","однако","он","она","они","оно","от","очень","по","под","при","с","со","так","также","такой","там","те","тем","то","того","тоже","той","только","том","ты","у","уже","хотя","чего","чей","чем","что","чтобы","чье","чья","эта","эти","это","я"]