BladeLLM adalah mesin inferensi yang dirancang khusus untuk mengoptimalkan model bahasa besar (LLM) dan menerapkan model berperforma tinggi. Dengan arsitektur teknis canggih serta antarmuka pengguna yang ramah, BladeLLM menawarkan performa luar biasa untuk menghadapi peluang dan tantangan baru di bidang LLM. Ini menjadikan BladeLLM sebagai solusi ideal bagi perusahaan yang ingin menerapkan LLM dan melakukan inferensi.
Arsitektur teknis
Gambar berikut menunjukkan arsitektur teknis BladeLLM.
Platform penerapan
BladeLLM kompatibel dengan berbagai arsitektur GPU, termasuk NVIDIA, AMD, dan GPU lainnya. BladeLLM juga terintegrasi mendalam dengan Elastic Algorithm Service (EAS) untuk penjadwalan dan manajemen sumber daya, menyediakan penerapan model satu atap yang efisien dan andal.
BladeLLM
Komputasi Model
BladeLLM dilengkapi dengan operator berperforma tinggi dan kompilasi AI. Pustaka operator LLM fleksibel BlaDNN melampaui pustaka mainstream dalam cakupan fitur dan performa. FlashNN, pustaka operator AI terkompilasi dari BladeLLM, dapat diperluas di berbagai platform perangkat keras untuk mencocokkan performa operator yang dioptimalkan secara manual.
Kompresi kuantisasi merupakan salah satu metode optimasi model utama dalam skenario inferensi LLM. BladeLLM mendukung algoritma canggih seperti GPTQ, AWQ, SmoothQuant, dan SmoothQuant+, yang secara signifikan meningkatkan throughput dan mengurangi latensi.
BladeLLM mendukung inferensi terdistribusi di beberapa GPU, menyediakan strategi paralelisme tensor dan paralelisme pipa, serta mendukung derajat paralelisme arbitrer untuk mengatasi hambatan memori GPU pada LLM.
Mesin Generasi
Selain optimasi dalam komputasi model, BladeLLM memiliki runtime sepenuhnya asinkron yang dirancang khusus untuk skenario LLM. Permintaan pengguna dikirimkan secara asinkron ke modul penjadwalan batch, diteruskan secara asinkron ke mesin generasi, dan diproses menggunakan dekode asinkron.
BladeLLM mendukung metode pemrosesan batch berkelanjutan, yang meningkatkan throughput dan kecepatan respons paket pertama.
Prompt Cache memungkinkan BladeLLM memperoleh hasil perhitungan sebelumnya dari cache untuk permintaan berulang atau serupa, mengurangi waktu respons.
Selama dekode, BladeLLM menggunakan metode dekode efisien seperti dekode spekulatif dan dekode lookahead untuk memprediksi token berikutnya tanpa mengorbankan akurasi.
Kerangka Layanan
Seiring bertambahnya skala model, sumber daya instance tunggal tidak dapat memenuhi persyaratan, sehingga model perlu diterapkan di beberapa instance. BladeLLM menerapkan strategi penjadwalan terdistribusi yang efisien dan digabungkan dengan rute LLM cerdas dari EAS. Dengan cara ini, BladeLLM mencapai distribusi permintaan dinamis dan distribusi beban seimbang untuk memaksimalkan pemanfaatan kluster.
Skenario
BladeLLM mendukung berbagai skenario, termasuk obrolan, Generasi yang Ditingkatkan Pencarian (RAG), multimodal, dan mode JSON, menyediakan solusi penerapan model yang efisien.
Pengalaman pengguna
BladeLLM memprioritaskan pengalaman pengguna yang ramah untuk menyederhanakan penerapan dan penggunaan LLM.
Pemulaan Sederhana dan Nyaman: BladeLLM menyediakan penerapan berbasis skenario di EAS dengan gambar pra-konfigurasi, perintah startup, dan parameter umum. Pengguna hanya perlu memilih model open source atau kustom serta tipe instance yang sesuai untuk mencapai penerapan layanan model satu klik.
Pemanggilan Fleksibel dan Mudah: BladeLLM mendukung antarmuka respons streaming dan non-streaming menggunakan HTTP Server-Sent Events (SSE). Antarmuka ini kompatibel dengan protokol OpenAI untuk integrasi sistem bisnis cepat.
Kompatibilitas Model Kuat dan Kaya: Format model BladeLLM kompatibel dengan standar komunitas seperti Hugging Face dan ModelScope, memungkinkan pengguna langsung menggunakan bobot model yang ada tanpa konversi tambahan.
Opsi Optimasi Siap Pakai: BladeLLM mendukung fitur optimasi seperti kompresi kuantisasi, pengambilan sampel spekulatif, dan cache prompt, memungkinkan pengguna mengonfigurasi parameter dengan mudah.
Dukungan Produksi Stabil dan Komprehensif: BladeLLM menyediakan gambar siap produksi serta alat pemantauan dan pengujian performa waktu nyata di EAS untuk memastikan operasi bisnis pelanggan yang stabil dan andal.
Perbandingan performa
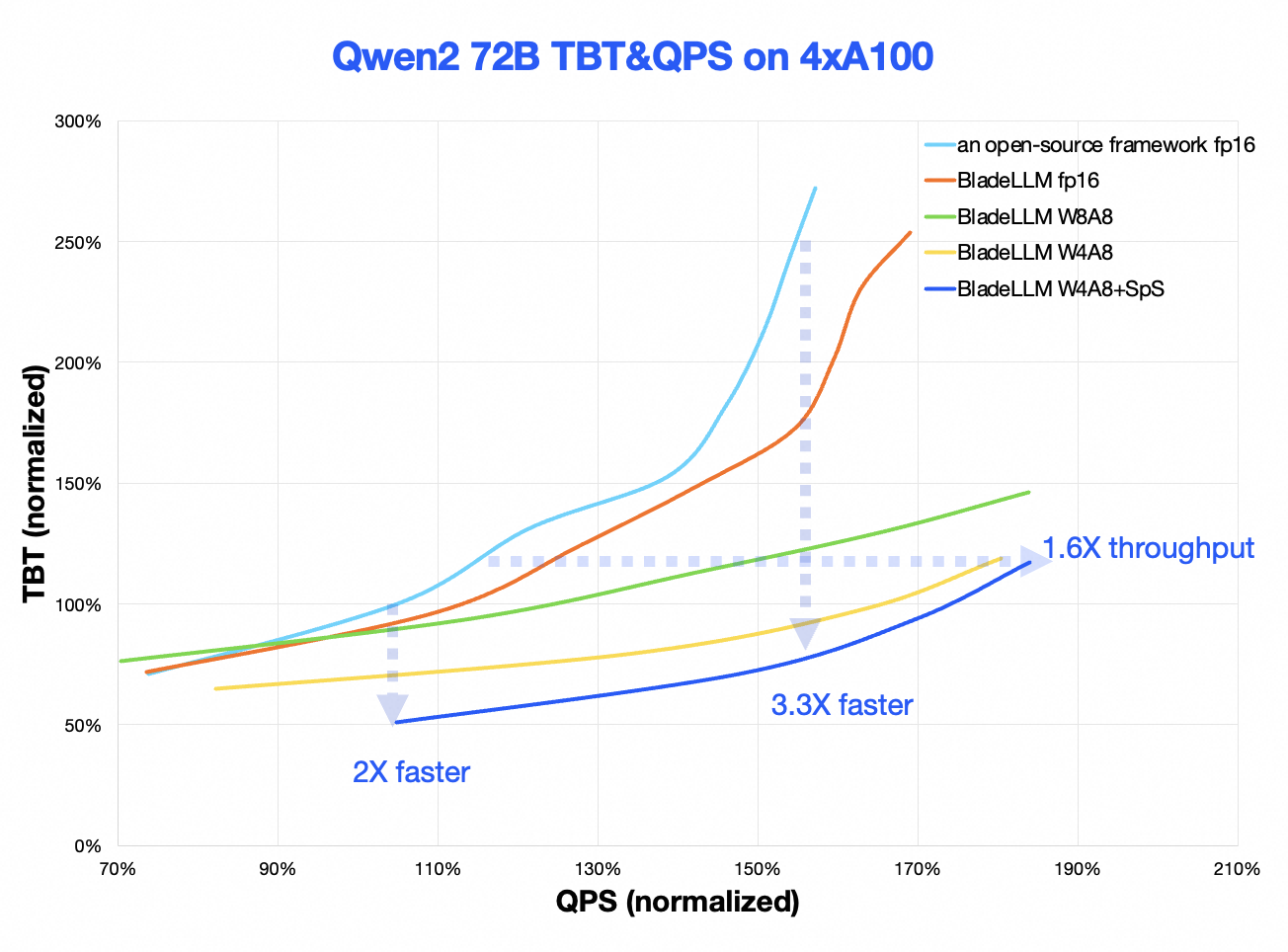
Berikut ini menjelaskan perbedaan antara performa BladeLLM v0.8.0 dan kerangka kerja open source utama.
Kurva TTFT-QPS: BladeLLM meningkatkan Waktu Untuk Token Pertama (TTFT) sebesar 2 hingga 3 kali dalam skenario beban tipikal dan menggandakan permintaan per detik (QPS) dalam skenario dengan persyaratan latensi tipikal untuk TTFT.
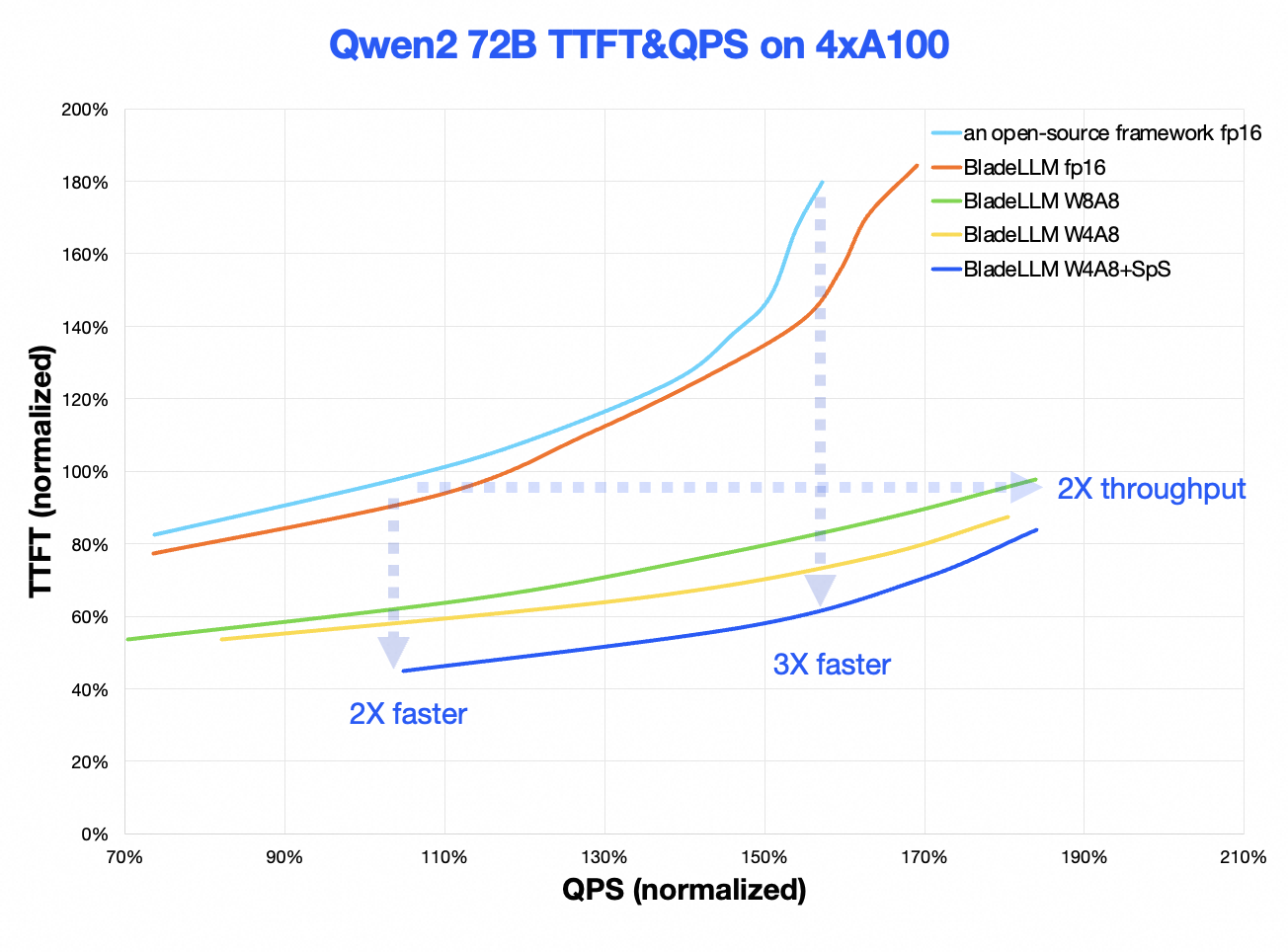
Kurva TBT-QPS: BladeLLM meningkatkan Waktu Antar Token (TBT) sekitar 2 hingga 3,3 kali dalam skenario beban tipikal dan QPS sebesar 1,6 kali dalam skenario dengan persyaratan latensi tipikal untuk TTFT.