Topik ini menjelaskan kode status dan kesalahan umum yang dikembalikan saat memanggil layanan.
Deskripsi kode status
Kode status | Deskripsi |
200 | Layanan berhasil memproses permintaan. |
400 | Format Request Body tidak benar atau terjadi pengecualian dalam kode prosesor kustom. Catatan Jika kode prosesor kustom Anda melempar pengecualian, server akan mengembalikan kode status 400. Untuk membedakannya dari kesalahan lainnya, konfigurasikan prosesor kustom Anda untuk mengembalikan kode status tertentu untuk pengecualian. |
401 | Otentikasi layanan gagal. Untuk informasi lebih lanjut, lihat 401 Otorisasi Gagal. |
404 | Layanan tidak ditemukan. Untuk informasi lebih lanjut, lihat 404 Tidak Ditemukan. |
405 | Metode tidak diizinkan. Misalnya, server mengembalikan kesalahan 405 jika Anda mengirim permintaan POST ke server yang hanya mendukung permintaan GET. Coba gunakan metode HTTP yang berbeda. |
408 | Permintaan habis waktu. Server memiliki batas waktu default 5 detik untuk setiap permintaan. Anda dapat mengonfigurasi ini dengan menyetel bidang Catatan Total waktu pemrosesan untuk satu permintaan mencakup waktu komputasi Prosesor, waktu menerima paket data jaringan, dan waktu yang dihabiskan menunggu dalam antrian. |
429 | Permintaan memicu pembatasan laju.
|
450 | |
499 | Klien menutup koneksi. Saat klien secara aktif menutup koneksi, ia tidak menerima kode status 499. Sebagai gantinya, server mencatat permintaan yang belum diproses dari koneksi tersebut dengan kode status 499. Misalnya, jika klien memiliki timeout HTTP 30 ms dan latensi pemrosesan sisi server adalah 50 ms, klien meninggalkan permintaan setelah 30 ms dan menutup koneksi. Kode status 499 kemudian muncul dalam pemantauan sisi server. |
500 | Kesalahan server internal. Server mengalami kondisi tak terduga yang mencegahnya memenuhi permintaan. |
501 | Tidak Diimplementasikan. Server tidak mendukung fungsionalitas yang diperlukan untuk memenuhi permintaan. |
502 | Bad Gateway. Server, saat bertindak sebagai gateway atau proxy, menerima respons tidak valid dari server upstream. |
503 | Layanan Tidak Tersedia. Saat Anda mengakses layanan melalui gateway, jika semua instans layanan backend tidak dalam keadaan siap, gateway mengembalikan kode status 503. Untuk informasi lebih lanjut, lihat 503 no healthy upstream. |
504 | Timeout Gateway. Untuk informasi lebih lanjut, lihat 504 timeout. |
505 | Versi Protokol HTTP Tidak Didukung. Server tidak mendukung versi protokol HTTP yang digunakan dalam permintaan. |
Kode kesalahan pemanggilan SDK
Saat menggunakan SDK resmi EAS untuk memanggil layanan, SDK dapat menghasilkan kode kesalahan sendiri, yang mungkin berbeda dari yang dikembalikan oleh server. Selalu merujuk pada kode kesalahan dalam log gateway dan layanan sebagai sumber kebenaran.
Kode status | Deskripsi |
512 | Saat menggunakan EAS Golang SDK, jika klien secara aktif memutuskan koneksi, SDK mengembalikan kode kesalahan 512. Timeout sisi klien ini sesuai dengan Kode Status 499 di sisi server. |
Kesalahan umum
404 Tidak Ditemukan
Kesalahan 404 biasanya menunjukkan jalur permintaan tidak valid, badan permintaan salah, atau API yang tidak didukung oleh layanan. Gunakan skenario berikut untuk memecahkan masalah berdasarkan pesan kesalahan spesifik yang Anda terima.
Tipe kesalahan 1: {"object":"error","message":"Model `` tidak ada.","type":"NotFoundError","param":null,"code":404}
Penyebab: Parameter model dalam badan permintaan kosong atau tidak valid saat memanggil endpoint /v1/chat/completions dari layanan yang diterapkan dengan vLLM.
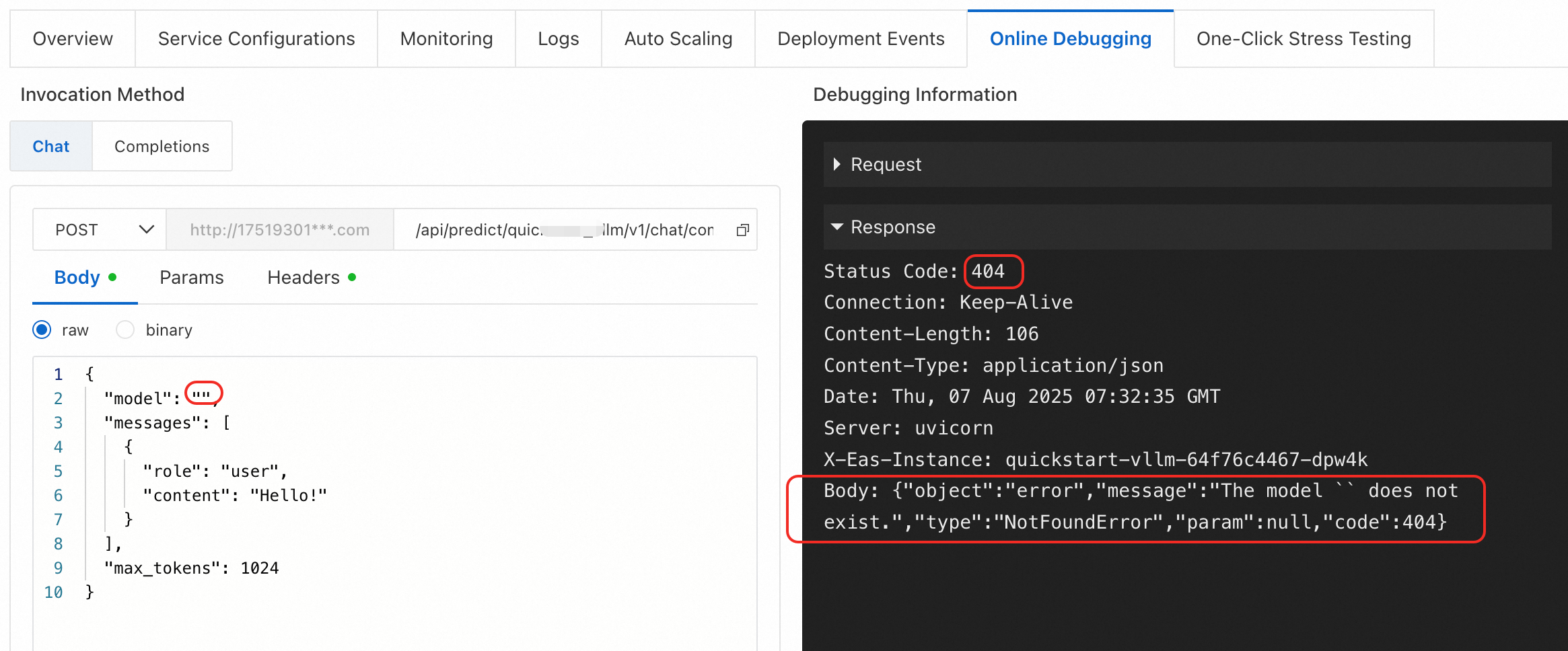
Solusi: Nilai parameter model harus berupa nama model yang valid. Query untuk nama model yang valid dengan menggunakan endpoint v1/models.
Tipe kesalahan 2: {"detail":"Not Found"}
Penyebab: Jalur permintaan tidak lengkap atau salah. Misalnya, saat memanggil endpoint chat layanan LLM, Anda tidak menambahkan path v1/chat/completions ke URL dasar.
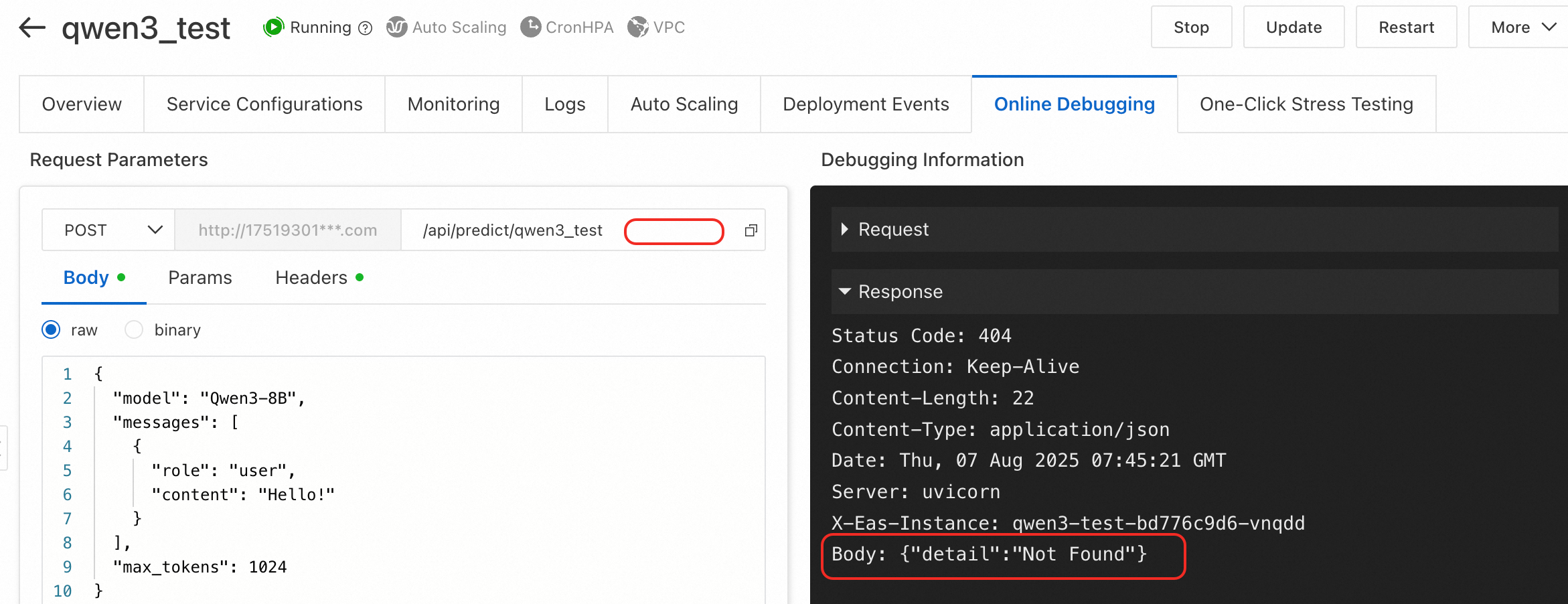
Solusi: Pastikan bahwa jalur permintaan API lengkap dan benar. Untuk layanan LLM, lihat Pemanggilan layanan LLM.
Jenis kesalahan 3: Memanggil endpoint /v1/models dari BladeLLM mengembalikan 404: Not Found.
Penyebab: Layanan yang diterapkan dengan BladeLLM tidak mendukung endpoint v1/models.
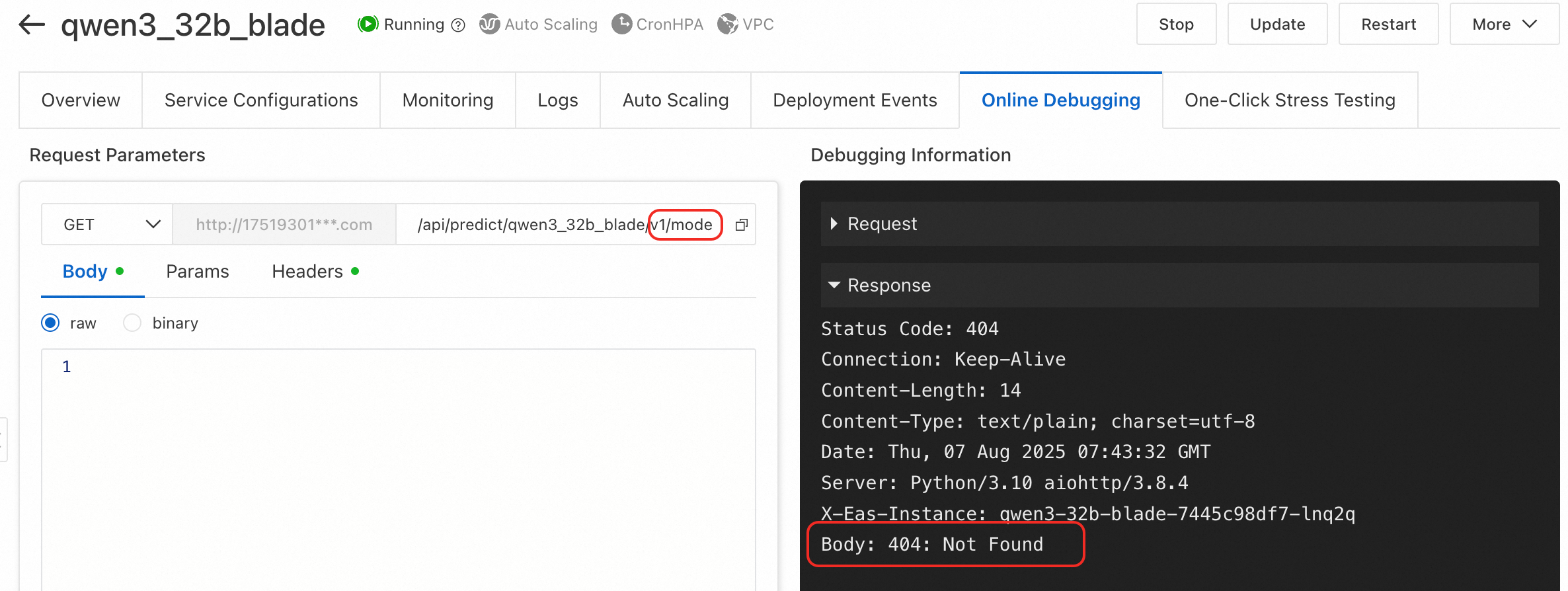
Solusi: Untuk daftar API yang didukung, lihat Konfigurasi Parameter Pemanggilan Layanan BladeLLM.
Jenis kesalahan 4: Halaman debugging online mengembalikan kesalahan 404 tanpa informasi lain.
Penyebab: Jalur permintaan salah. Saat Anda menggunakan debugging online, URL dasar biasanya http://123***.cn-hangzhou.pai-eas.aliyuncs.com/predict/service_name. Salah mengubah atau menghapus bagian nama layanan dari URL menghasilkan kesalahan 404.
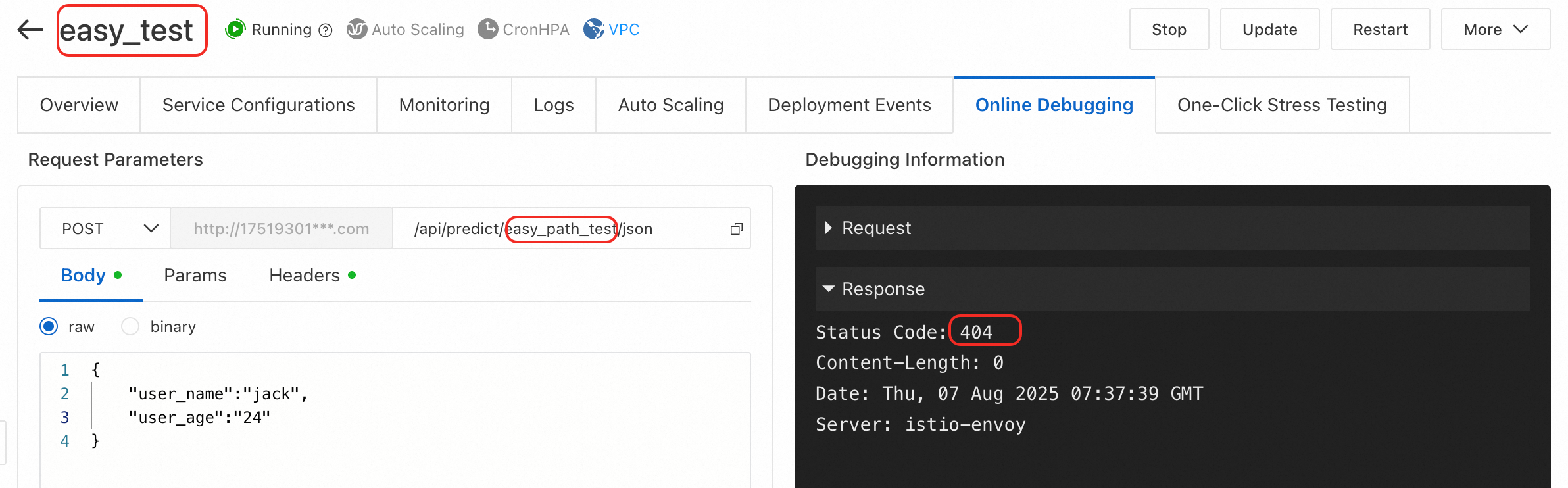
Solusi: Saat Anda menggunakan debugging online, Anda biasanya tidak perlu mengubah atau menghapus URL default. Tambahkan jalur API spesifik yang ingin Anda panggil.
Tipe kesalahan 5: Panggilan API ke ComfyUI mengembalikan "404 not found page".
400 Bad Request
Format badan permintaan tidak benar. Periksa dengan cermat format badan permintaan, seperti struktur JSON, nama bidang, dan tipe data.
401 Otorisasi Gagal
Token otentikasi hilang, salah, atau digunakan secara tidak tepat. Periksa hal berikut:
Periksa apakah token benar. Di halaman Overview layanan, klik View Invocation Information di bagian Basic Information.
CatatanSecara default, layanan secara otomatis menghasilkan token otentikasi. Anda juga dapat menentukan token kustom dan memperbaruinya selama pembaruan layanan.
Periksa apakah token diatur dengan benar.
Jika Anda menggunakan perintah
curl, tambahkan token ke bidangAuthorizationdalam Header HTTP. Contohnya:curl -H 'Authorization: NWMyN2UzNjBiZmI2YT***' http:// xxx.cn-shanghai.aliyuncs.com/api/predict/echo.Jika Anda menggunakan SDK untuk mengakses layanan, panggil fungsi
SetToken()yang sesuai. Untuk informasi lebih lanjut, lihat Petunjuk penggunaan Java SDK.
504 timeout
Server, saat bertindak sebagai gateway atau proxy, tidak menerima respons tepat waktu dari server upstream. Ini biasanya berarti inferensi model memakan waktu terlalu lama. Untuk menyelesaikan masalah ini:
Dalam kode klien Anda, tingkatkan timeout permintaan HTTP.
Untuk tugas yang berjalan lama, gunakan mode Layanan Antrian EAS (Pemanggilan Asinkron), yang dirancang untuk menangani tugas inferensi batch atau berjalan lama.
450: Permintaan dibuang karena antrian penuh
Saat instans komputasi sisi server menerima permintaan, ia pertama-tama menempatkan permintaan dalam antrian. Saat pekerja dalam instans tersedia, ia mengambil data dari antrian untuk diproses. Jumlah pekerja default adalah 5, yang dapat Anda sesuaikan dengan menggunakan bidang metadata.rpc.worker_threads dalam file JSON buat layanan. Jika waktu pemrosesan pekerja terlalu lama, permintaan dapat menumpuk di antrian. Saat antrian penuh, instans segera menolak permintaan baru dengan Kode Status 450 untuk mencegah penumpukan antrian yang berlebihan sehingga meningkatkan latensi dan membuat layanan tidak tersedia. Panjang antrian default adalah 64, yang dapat Anda sesuaikan dengan menggunakan bidang metadata.rpc.max_queue_size dalam file JSON buat layanan.
Membatasi panjang antrian juga bertindak sebagai bentuk pembatasan laju untuk mencegah lonjakan lalu lintas menyebabkan kegagalan layanan berantai.
Solusi:
Jika Anda menerima sejumlah kecil kode status 450, Anda dapat mencoba ulang permintaan. Karena instans sisi server independen, percobaan ulang mungkin diarahkan ke instans yang kurang sibuk, membuat masalah transparan bagi klien. Namun, jangan mencoba ulang tanpa batas, karena ini akan mengalahkan tujuan perlindungan pembatasan laju.
Jika semua permintaan mengembalikan kode status 450, ini mungkin menunjukkan bahwa kode di dalam prosesor macet. Jika semua pekerja deadlock saat memproses permintaan dan tidak lagi mengambil data dari antrian, Anda perlu men-debug kode prosesor untuk menemukan bug.
503 no healthy upstream
Anda menerima kesalahan 503 dengan pesan "no healthy upstream" selama debugging online:

Lakukan pemecahan masalah sebagai berikut:
Periksa status instans. Jika instans telah berhenti, Mulai Ulang Layanan.
Jika status layanan adalah Berjalan, instans mungkin memiliki sumber daya yang tidak cukup, seperti CPU, memori, atau Memori GPU, yang mengarah pada kurangnya ruang buffer.
Jika Anda menggunakan sumber daya publik, coba buat panggilan lagi selama jam non-puncak, atau beralih ke spesifikasi sumber daya atau wilayah yang berbeda.
Jika Anda menggunakan sumber daya khusus (Kelompok Sumber Daya EAS), pastikan kelompok sumber daya telah memesan cukup CPU, memori, dan Memori GPU untuk instans. Kami merekomendasikan menyisakan setidaknya 20% sumber daya gratis sebagai buffer.
Skenario umum lainnya adalah status layanan Berjalan dan semua instans Siap setelah penyebaran. Namun, permintaan memicu bug dalam kode, yang menyebabkan instans layanan backend mogok dan menjadi tidak responsif. Dalam situasi ini, gateway mengembalikan Kode Status 503 ke klien. Untuk mengidentifikasi dan memperbaiki bug, gunakan log.
Kesalahan: Token tak terduga 12606 saat mengharapkan token awal 200006
Saat Anda menggunakan vllm untuk menerapkan gpt-oss, panggilan layanan mungkin mengembalikan kesalahan berikut:

Solusi: Coba terapkan dengan percepatan SGLang.
kesalahan pemanggilan curl: no URL specified
Anda menerima kesalahan tidak ada URL yang ditentukan setelah Anda mengirim permintaan dengan perintah berikut:
curl -X http://17****.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/service_name/**path** \
-H "Content-Type: application/json" \
-H "Authorization: **********==" \
-d '{"***":"****"}'Penyebab: Perintah curl menggunakan flag -X tetapi kehilangan metode, seperti POST.
Pemanggilan mengembalikan pengkodean ASCII
Ubah kode Anda sebagai berikut:
from flask import Flask, Response
@app.route('/hello', methods=['POST'])
def get_advice():
result = "result"
return Response(result, mimetype='text/plain', charset='utf-8')Bagaimana cara menyelesaikan "[WARN] koneksi ditutup: Akhir file" atau "Tulis aliran tidak valid: Akhir file" di log layanan?
Log peringatan ini menunjukkan bahwa klien atau server menutup koneksi, dan server sedang mencoba menulis respons kembali ke koneksi yang ditutup tersebut. Koneksi dapat ditutup dengan dua cara:
Timeout sisi server: Dalam mode Processor, timeout sisi server default adalah 5 detik. Anda dapat mengubah ini dengan menggunakan parameter
metadata.rpc.keepalivelayanan. Saat timeout tercapai, server menutup koneksi dan mencatat kode status 408 dalam pemantauannya.Timeout sisi klien: Pengaturan kode pemanggilan Anda menentukan timeout sisi klien. Jika klien tidak menerima respons HTTP dalam periode timeout yang dikonfigurasikan, ia secara aktif menutup koneksi. Server kemudian mencatat kode status 499 dalam pemantauannya.
kesalahan koneksi upstream atau disconnect/reset sebelum header. alasan reset: terminasi koneksi
Masalah seperti timeout koneksi persisten atau beban instans yang tidak seimbang biasanya menyebabkan kesalahan ini. Jika waktu pemrosesan sisi server melebihi timeout HTTP yang dikonfigurasikan di klien, klien meninggalkan permintaan dan secara aktif menutup koneksi. Kode status 499 kemudian muncul dalam pemantauan sisi server. Anda dapat memeriksa metrik pemantauan untuk konfirmasi lebih lanjut. Untuk tugas inferensi yang memakan waktu, terapkan layanan inferensi asinkron.
Bagaimana cara menyelesaikan kegagalan debugging online untuk layanan yang diterapkan dengan prosesor Tensorflow/Pytorch?
Untuk alasan performa, Prosesor TensorFlow/PyTorch menggunakan format protobuf non-teks biasa untuk badan permintaan. Debugging online saat ini hanya mendukung input teks biasa. Oleh karena itu, Anda tidak dapat men-debug layanan yang diterapkan dengan prosesor ini langsung di konsol. Gunakan SDK EAS yang disediakan untuk memanggil layanan. Untuk informasi tentang SDK dalam berbagai bahasa, lihat SDK Pemanggilan Layanan.