Instal paket dependensi dan jalankan fungsi Python kustom menggunakan komponen Skrip Python di Machine Learning Designer.
Lokasi komponen
Skrip Python berada di folder UserDefinedScript dalam daftar komponen Machine Learning Designer.
Prasyarat
-
Berikan izin yang diperlukan untuk Deep Learning Containers (DLC). Untuk informasi selengkapnya, lihat Ketergantungan dan otorisasi layanan cloud: DLC.
-
Komponen Skrip Python dijalankan pada sumber daya komputasi DLC. Kaitkan sumber daya komputasi DLC dengan ruang kerja Anda. Untuk informasi selengkapnya, lihat Mengelola ruang kerja.
-
Komponen Skrip Python menyimpan kode di Object Storage Service (OSS). Buat bucket OSS. Untuk informasi selengkapnya, lihat Membuat bucket.
PentingBucket OSS harus berada di wilayah yang sama dengan Machine Learning Designer dan DLC.
-
Pengguna RAM yang akan menggunakan komponen ini harus memiliki peran Algorithm Development di ruang kerja Anda. Untuk informasi selengkapnya, lihat Mengelola anggota ruang kerja. Jika pengguna RAM juga perlu menggunakan MaxCompute sebagai sumber data, berikan peran MaxCompute Developer.
Konfigurasi komponen
-
Port input
Komponen Skrip Python memiliki empat port input. Hubungkan ke data dari path OSS atau tabel MaxCompute.
-
Input path OSS
Input dari path OSS komponen hulu dipasang ke node tempat skrip Python dijalankan. Sistem secara otomatis meneruskan path file yang dipasang sebagai argumen. Misalnya,
--input1 /ml/input/data/input1menentukan path untuk port input pertama. Di skrip Anda, baca file yang dipasang dari/ml/input/data/input1seolah-olah itu file lokal. -
Input tabel MaxCompute
Input tabel MaxCompute tidak dipasang. Sebagai gantinya, sistem secara otomatis meneruskan informasi tabel ke skrip sebagai argumen URI. Misalnya,
python main.py --input1 odps://some-project-name/tables/tablemenunjukkan tabel MaxCompute untuk port input pertama. Untuk input berbasis URI, gunakan fungsiparse_odps_urldari templat kode komponen untuk mengurai metadata seperti ProjectName, TableName, dan Partition. Untuk informasi selengkapnya, lihat Contoh penggunaan.
-
-
Port output
Komponen Skrip Python memiliki empat port output. OSS Output Port 1 dan OSS Output Port 2 digunakan untuk output path OSS. Table Output Port 1 dan Table Output Port 2 digunakan untuk output tabel MaxCompute.
-
Output path OSS
Path OSS yang dikonfigurasi untuk parameter Job output path pada tab Code Config secara otomatis dipasang ke
/ml/output/. Port output OSS Output Port 1 dan OSS Output Port 2 komponen masing-masing berkorespondensi dengan subdirektori/ml/output/output1dan/ml/output/output2. Di skrip Anda, tulis file yang perlu diteruskan ke komponen hilir ke direktori-direktori ini seolah-olah itu file lokal. -
Output tabel MaxCompute
Jika ruang kerja saat ini dikonfigurasi dengan proyek MaxCompute, sistem akan secara otomatis meneruskan URI tabel sementara ke skrip Python, misalnya:
python main.py --output3 odps://<some-project-name>/tables/<output-table-name>. Gunakan PyODPS untuk membuat tabel yang ditentukan dalam URI tabel sementara tersebut, tulis data yang diproses oleh skrip Python ke tabel ini, lalu teruskan tabel tersebut ke komponen hilir melalui koneksi komponen. Untuk informasi selengkapnya, lihat contoh di bawah.
-
-
Parameter
Code Config
Parameter
Deskripsi
Job output path
Path OSS untuk output pekerjaan.
-
Direktori OSS yang dikonfigurasi dipasang ke path
/ml/output/di kontainer pekerjaan. Data yang ditulis ke path/ml/output/dipertahankan ke direktori OSS yang sesuai. -
Port output komponen OSS Output-1 dan OSS Output-2 masing-masing berkorespondensi dengan subpath
output1danoutput2di path/ml/output/. Ketika port output OSS komponen dihubungkan ke komponen hilir, komponen hilir menerima data dari subpath yang sesuai.
Code source
(Pilih salah satu)
Literal code
-
Python code: Path OSS tempat kode disimpan. Kode yang ditulis di editor disimpan ke path OSS ini. Nama file default untuk kode Python adalah
main.py.PentingSebelum Anda mengklik Save untuk pertama kalinya, pastikan bahwa path OSS yang ditentukan tidak berisi file dengan nama yang sama. Jika tidak, file yang ada akan ditimpa.
-
Editor kode Python: Editor kode menyediakan kode contoh secara default. Untuk informasi selengkapnya, lihat Contoh penggunaan. Tulis kode Anda langsung di editor.
Specify Git configuration
-
Git repository address: Alamat repositori Git.
-
Code branch: Cabang kode. Nilai default adalah master.
-
Code commit: ID commit. Parameter ini memiliki prioritas lebih tinggi daripada cabang. Jika Anda menentukan parameter ini, pengaturan cabang akan diabaikan.
-
Git username: Diperlukan jika Anda perlu mengakses repositori pribadi.
-
Git access token: Diperlukan untuk mengakses repositori kode pribadi. Untuk informasi selengkapnya, lihat Lampiran: Mendapatkan token akun GitHub.
Select code source
-
Select code source repositories: Pilih konfigurasi kode yang telah dibuat. Untuk informasi selengkapnya, lihat Konfigurasi kode.
-
Code branch: Cabang kode. Nilai default adalah master.
-
Code commit: ID commit. Parameter ini memiliki prioritas lebih tinggi daripada cabang. Jika Anda menentukan parameter ini, pengaturan cabang akan diabaikan.
Select OSS path
Di bidang OSS Code Path, pilih path tempat kode diunggah.
Command
Perintah untuk dieksekusi, seperti
python main.py.CatatanSistem secara otomatis menghasilkan perintah eksekusi berdasarkan nama skrip dan koneksi port komponen. Tidak diperlukan konfigurasi manual.
Advanced option
-
Third-party dependencies: Tentukan library pihak ketiga yang akan diinstal menggunakan format
requirements.txtPython. Sistem secara otomatis menginstal library ini sebelum node dijalankan.cycler==0.10.0 # via matplotlib kiwisolver==1.2.0 # via matplotlib matplotlib==3.2.1 numpy==1.18.5 pandas==1.0.4 pyparsing==2.4.7 # via matplotlib python-dateutil==2.8.1 # via matplotlib, pandas pytz==2020.1 # via pandas scipy==1.4.1 # via seaborn -
Enable container monitoring: Setelah Anda memilih opsi ini, kotak teks konfigurasi akan muncul. Tentukan parameter untuk pemantauan toleransi kesalahan di kotak teks tersebut.
Run Config
Parameter
Deskripsi
Select Resource Group
Pilih kelompok sumber daya DLC publik :
-
Jika Anda memilih kelompok sumber daya publik, konfigurasikan parameter InstanceType. Pilih instans CPU atau GPU. Nilai default adalah
ecs.c6.large.
Secara default, kelompok sumber daya default untuk sumber daya cloud-native DLC di ruang kerja saat ini digunakan.
VPC Settings
Pilih Virtual Private Cloud (VPC) yang sudah ada.
Security Group
Pilih grup keamanan yang sudah ada.
Advanced option
Jika Anda memilih opsi ini, konfigurasikan parameter berikut:
-
Instance count: Jumlah instans. Nilai default adalah 1.
-
Job image URI: URI image pekerjaan. Image default menggunakan XGBoost open-source versi 1.6.0. Jika Anda perlu menggunakan framework pembelajaran mendalam, ubah image tersebut.
-
Job type: Ubah parameter ini hanya jika kode yang Anda kirimkan diimplementasikan untuk eksekusi terdistribusi. Nilai yang didukung adalah:
-
XGBoost/LightGBM Job
-
TensorFlow Job
-
PyTorch Job
-
MPI Job
-
-
Contoh penggunaan
Kode contoh default
Komponen Skrip Python menyediakan kode contoh berikut secara default.
import os
import argparse
import json
"""
Kode contoh untuk komponen Skrip Python
"""
# Lingkungan eksekusi MaxCompute default di ruang kerja saat ini, yang mencakup nama proyek MaxCompute dan titik akhir.
# Lingkungan ini disuntikkan hanya jika proyek MaxCompute ada di ruang kerja saat ini.
# Contoh: {"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}.
ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"
def init_odps():
from odps import ODPS
# Informasi tentang proyek MaxCompute default di ruang kerja saat ini.
mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])
o = ODPS(
access_id="<YourAccessKeyId>",
secret_access_key="<YourAccessKeySecret>",
# Pilih titik akhir berdasarkan wilayah tempat proyek Anda berada, misalnya: http://service.cn-shanghai.maxcompute.aliyun-inc.com/api.
endpoint=mc_execution["endpoint"],
project=mc_execution["odpsProject"],
)
return o
def parse_odps_url(table_uri):
from urllib import parse
parsed = parse.urlparse(table_uri)
project_name = parsed.hostname
r = parsed.path.split("/", 2)
table_name = r[2]
if len(r) > 3:
partition = r[3]
else:
partition = None
return project_name, table_name, partition
def parse_args():
parser = argparse.ArgumentParser(description="Contoh skrip komponen PythonV2.")
parser.add_argument("--input1", type=str, default=None, help="Port input komponen 1.")
parser.add_argument("--input2", type=str, default=None, help="Port input komponen 2.")
parser.add_argument("--input3", type=str, default=None, help="Port input komponen 3.")
parser.add_argument("--input4", type=str, default=None, help="Port input komponen 4.")
parser.add_argument("--output1", type=str, default=None, help="Port output OSS 1.")
parser.add_argument("--output2", type=str, default=None, help="Port output OSS 2.")
parser.add_argument("--output3", type=str, default=None, help="Tabel MaxCompute Output 1.")
parser.add_argument("--output4", type=str, default=None, help="Tabel MaxCompute Output 2.")
args, _ = parser.parse_known_args()
return args
def write_table_example(args):
# Contoh: Eksekusi pernyataan SQL untuk menyalin data dari tabel publik yang disediakan oleh PAI ke tabel sementara yang ditentukan untuk Table Output Port 1 (--output3).
output_table_uri = args.output3
o = init_odps()
project_name, table_name, partition = parse_odps_url(output_table_uri)
o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;")
def write_output1(args):
# Contoh: Tulis hasil data ke path OSS yang dipasang (subdirektori untuk OSS Output Port 1), dan hasil dapat diteruskan ke komponen hilir melalui koneksi.
output_path = args.output1
os.makedirs(output_path, exist_ok=True)
p = os.path.join(output_path, "result.text")
with open(p, "w") as f:
f.write("TestAccuracy=0.88")
if __name__ == "__main__":
args = parse_args()
print("Input1={}".format(args.input1))
print("Output1={}".format(args.output1))
# write_table_example(args)
# write_output1(args)
Deskripsi fungsi umum:
-
init_odps(): Menginisialisasi instans ODPS untuk membaca data tabel MaxCompute. Berikan AccessKeyId dan AccessKeySecret Anda. Untuk informasi selengkapnya tentang cara memperoleh Pasangan Kunci Akses, lihat Memperoleh Pasangan Kunci Akses. -
parse_odps_url(table_uri): Mengurai URI tabel MaxCompute input dan mengembalikan nama proyek, nama tabel, dan partisi. Formattable_uriadalahodps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/, misalnya,odps://test/tables/iris/pa=1/pb=1, di manapa=1/pb=1adalah partisi multi-level. -
parse_args(): Mengurai argumen yang diteruskan ke skrip. Data input dan output diteruskan ke skrip yang dieksekusi sebagai argumen.
Contoh 1: Rangkai dengan komponen lain
Contoh ini memodifikasi templat prediksi penyakit jantung untuk menunjukkan cara menggunakan komponen Skrip Python bersama dengan komponen Machine Learning Designer lainnya. Konfigurasi pipeline:
Konfigurasi pipeline:
-
Buat pipeline dari templat prediksi penyakit jantung dan buka. Untuk informasi selengkapnya, lihat Prediksi penyakit jantung.
-
Tarik komponen Skrip Python ke kanvas, ubah namanya menjadi
SMOTE, dan konfigurasikan kode berikut.PentingLibrary
imblearntidak termasuk dalam image. Tambahkanimblearndi bidang Third-party dependencies pada tab Code Config. Library tersebut akan diinstal secara otomatis sebelum node dijalankan.import argparse import json import os from odps.df import DataFrame from imblearn.over_sampling import SMOTE from urllib import parse from odps import ODPS ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): # Informasi tentang proyek MaxCompute default di ruang kerja saat ini. mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<Your_AccessKeyId>", secret_access_key="<Your_AccessKeySecret>", # Pilih titik akhir berdasarkan wilayah tempat proyek Anda berada, misalnya: http://service.cn-shanghai.maxcompute.aliyun-inc.com/api. endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def get_max_compute_table(table_uri, odps): parsed = parse.urlparse(table_uri) project_name = parsed.hostname table_name = parsed.path.split('/')[2] table = odps.get_table(project_name + "." + table_name) return table def run(): parser = argparse.ArgumentParser(description='Contoh skrip komponen PythonV2.') parser.add_argument( '--input1', type=str, default=None, help='Port input komponen 1.' ) parser.add_argument( '--output3', type=str, default=None, help='Port input komponen 1.' ) args, _ = parser.parse_known_args() print('Input1={}'.format(args.input1)) print('output3={}'.format(args.output3)) o = init_odps() imbalanced_table = get_max_compute_table(args.input1, o) df = DataFrame(imbalanced_table).to_pandas() sm = SMOTE(random_state=2) X_train_res, y_train_res = sm.fit_resample(df, df['ifhealth'].ravel()) new_table = o.create_table(get_max_compute_table(args.output3, o).name, imbalanced_table.schema, if_not_exists=True) with new_table.open_writer() as writer: writer.write(X_train_res.values.tolist()) if __name__ == '__main__': run()Ganti <Your_AccessKeyId> dan <Your_AccessKeySecret> dalam kode dengan AccessKeyId dan AccessKeySecret Anda sendiri. Untuk informasi selengkapnya tentang cara memperoleh Pasangan Kunci Akses, lihat Memperoleh Pasangan Kunci Akses.
-
Hubungkan komponen SMOTE di hilir komponen Split. Komponen ini menggunakan algoritma SMOTE untuk oversampling data pelatihan, menyeimbangkan distribusi kelas dengan membuat sampel sintetis untuk kelas minoritas.
-
Hubungkan data baru dari komponen SMOTE ke komponen Logistic Regression for Binary Classification untuk pelatihan.
-
Hubungkan model yang telah dilatih ke data prediksi dan komponen evaluasi yang sama seperti model di cabang kiri untuk perbandingan berdampingan. Setelah komponen berhasil dijalankan, klik ikon visualisasi (
 ) untuk melihat hasil evaluasi akhir.
) untuk melihat hasil evaluasi akhir.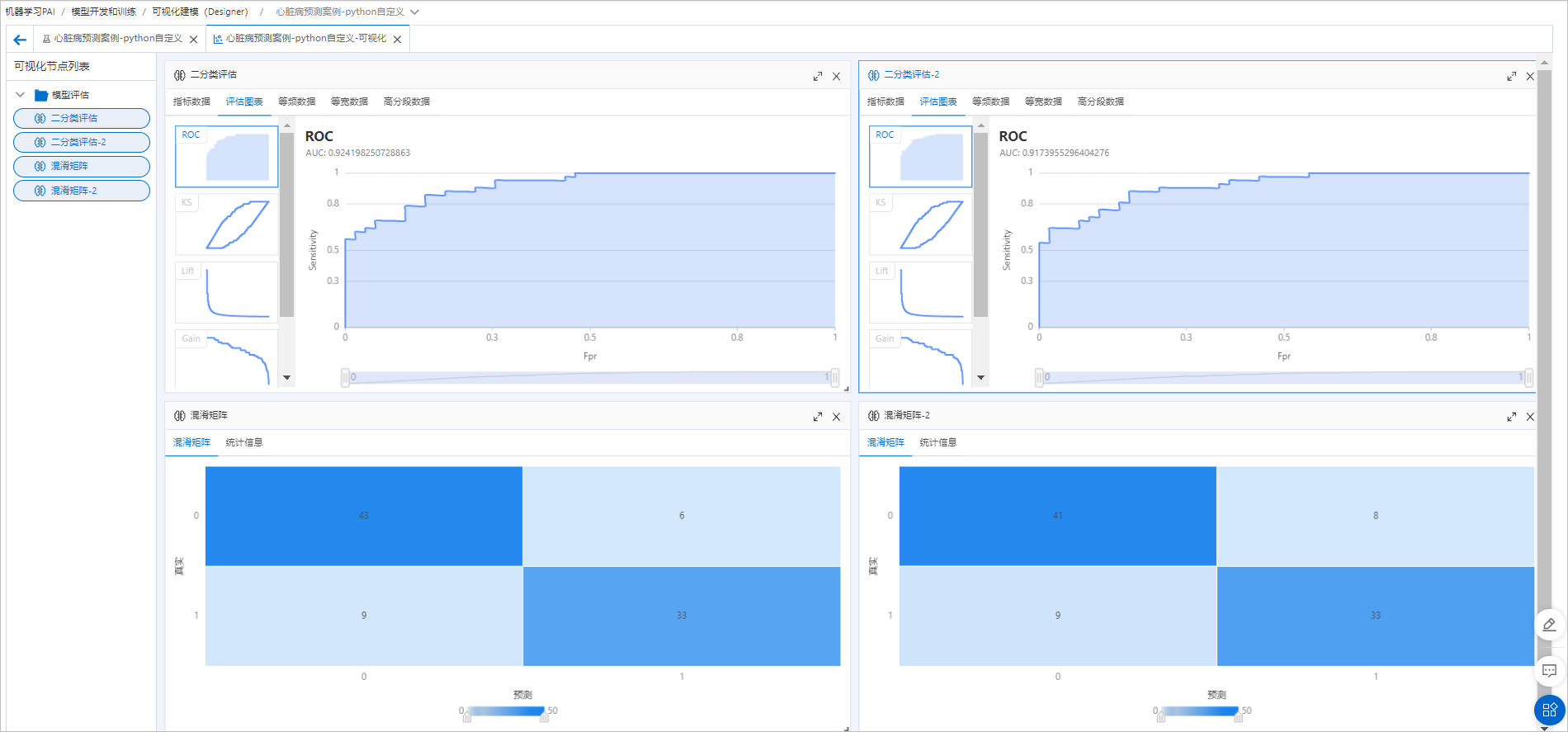
Oversampling tambahan tidak secara signifikan meningkatkan kinerja model, yang menunjukkan bahwa distribusi sampel asli dan model tersebut sudah efektif.
Contoh 2: Mengatur pekerjaan DLC
Hubungkan beberapa komponen Skrip Python di Machine Learning Designer untuk mengatur dan menjadwalkan pipeline pekerjaan DLC. Gambar berikut menunjukkan contoh memulai empat pekerjaan DLC yang diatur dalam Directed Acyclic Graph (DAG) untuk mengontrol urutan eksekusinya.
Jika kode eksekusi untuk pekerjaan DLC tidak perlu membaca data dari node hulu atau meneruskan data ke node hilir, koneksi antar node hanya merepresentasikan dependensi penjadwalan dan urutan eksekusi.
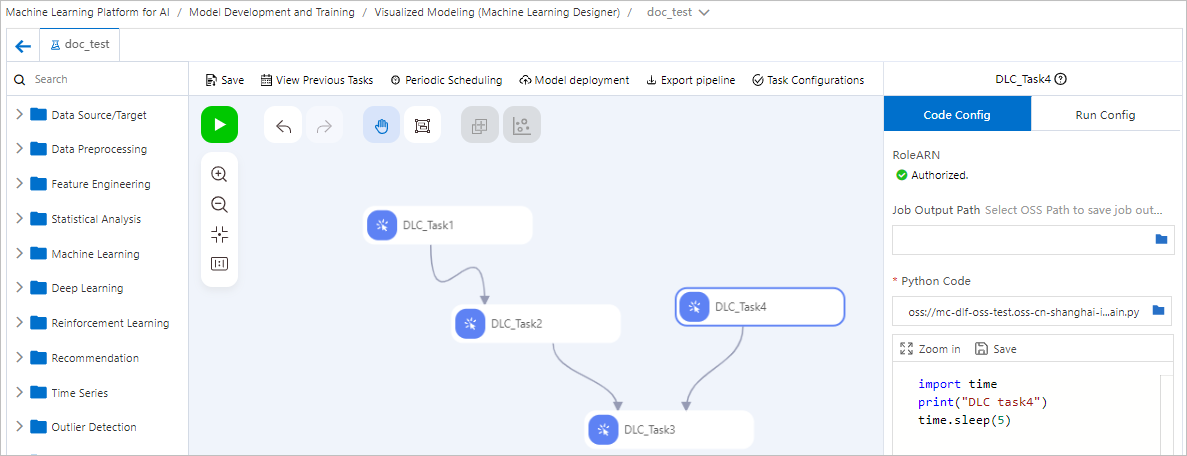 Terapkan seluruh pipeline yang dikembangkan di Machine Learning Designer ke DataWorks untuk eksekusi terjadwal. Untuk informasi selengkapnya, lihat Gunakan DataWorks untuk menjadwalkan pipeline Machine Learning Designer guna eksekusi offline.
Terapkan seluruh pipeline yang dikembangkan di Machine Learning Designer ke DataWorks untuk eksekusi terjadwal. Untuk informasi selengkapnya, lihat Gunakan DataWorks untuk menjadwalkan pipeline Machine Learning Designer guna eksekusi offline.
Contoh 3: Meneruskan variabel global
-
Konfigurasikan variabel global.
Di halaman pipeline Machine Learning Designer, klik area kosong kanvas dan konfigurasikan variabel pada tab Global Variables di panel kanan.
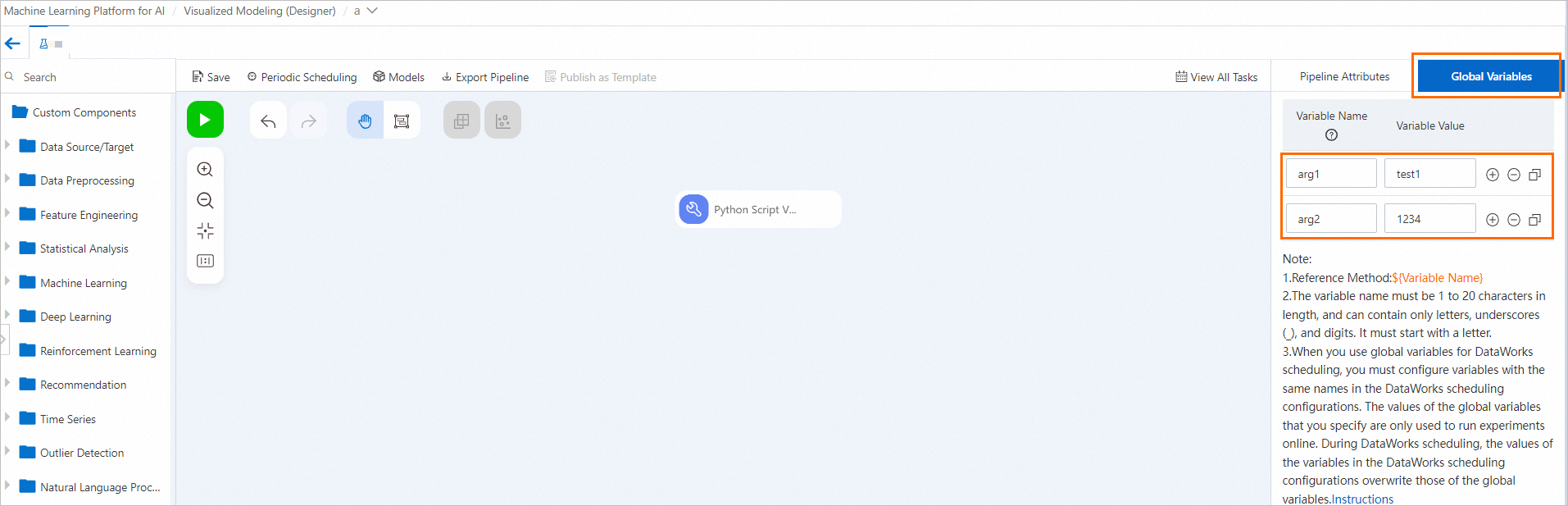
-
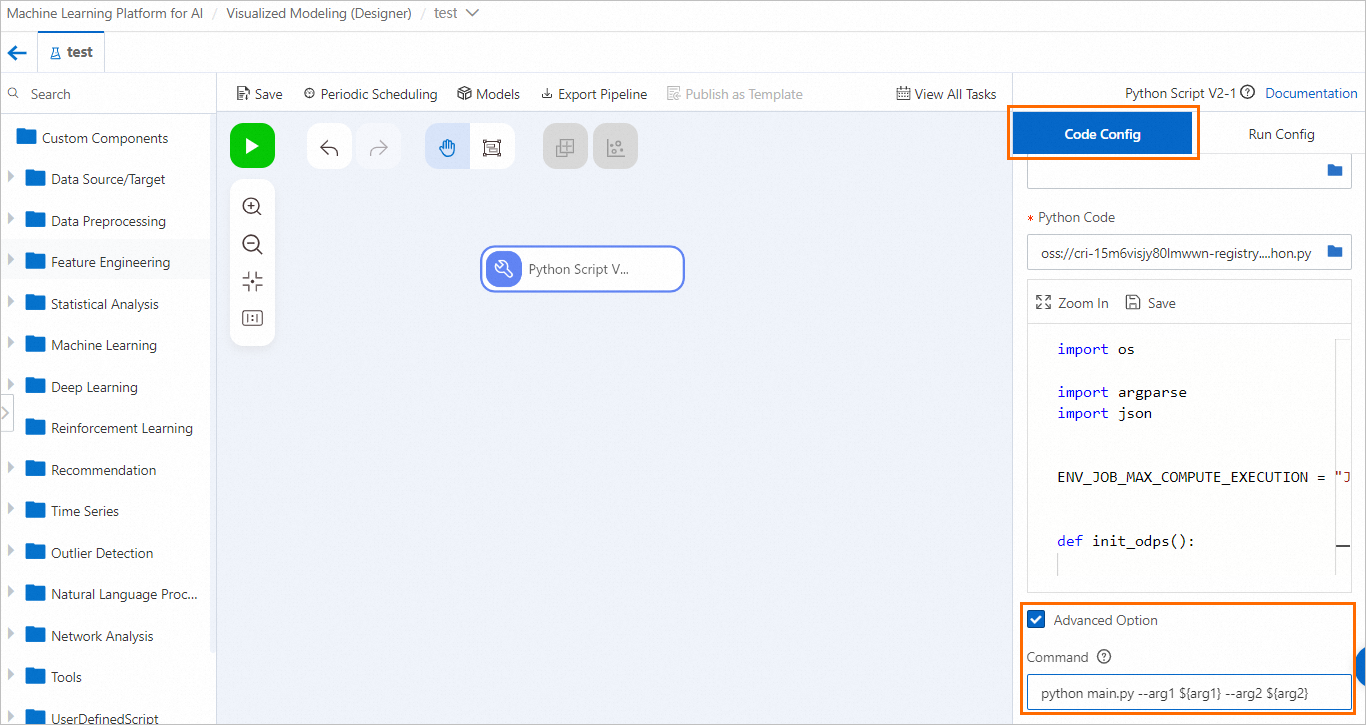
Teruskan variabel global yang dikonfigurasi ke komponen Skrip Python dengan salah satu dari dua cara berikut.
-
Klik node komponen Skrip Python. Di panel kanan, pada tab Code Config, pilih Advanced option dan konfigurasikan variabel global sebagai parameter masuk di bidang Command.
-
Modifikasi kode Python untuk mengurai argumen menggunakan
argparse.Kode Python yang diperbarui adalah sebagai berikut. Kode ini menggunakan variabel global yang dikonfigurasi pada langkah 1 sebagai contoh. Perbarui kode sesuai dengan variabel global Anda yang sebenarnya. Ganti kode di area pengeditan kode pada tab Code Config node komponen Skrip Python.
import os import argparse import json """ Kode contoh untuk komponen Skrip Python """ ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): from odps import ODPS mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<YourAccessKeyId>", secret_access_key="<YourAccessKeySecret>", endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def parse_odps_url(table_uri): from urllib import parse parsed = parse.urlparse(table_uri) project_name = parsed.hostname r = parsed.path.split("/", 2) table_name = r[2] if len(r) > 3: partition = r[3] else: partition = None return project_name, table_name, partition def parse_args(): parser = argparse.ArgumentParser(description="Contoh skrip komponen PythonV2.") parser.add_argument("--input1", type=str, default=None, help="Port input komponen 1.") parser.add_argument("--input2", type=str, default=None, help="Port input komponen 2.") parser.add_argument("--input3", type=str, default=None, help="Port input komponen 3.") parser.add_argument("--input4", type=str, default=None, help="Port input komponen 4.") parser.add_argument("--output1", type=str, default=None, help="Port output OSS 1.") parser.add_argument("--output2", type=str, default=None, help="Port output OSS 2.") parser.add_argument("--output3", type=str, default=None, help="Tabel MaxCompute Output 1.") parser.add_argument("--output4", type=str, default=None, help="Tabel MaxCompute Output 2.") # Tambahkan kode berdasarkan variabel global yang dikonfigurasi. parser.add_argument("--arg1", type=str, default=None, help="Argumen 1.") parser.add_argument("--arg2", type=int, default=None, help="Argumen 2.") args, _ = parser.parse_known_args() return args def write_table_example(args): output_table_uri = args.output3 o = init_odps() project_name, table_name, partition = parse_odps_url(output_table_uri) o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;") def write_output1(args): output_path = args.output1 os.makedirs(output_path, exist_ok=True) p = os.path.join(output_path, "result.text") with open(p, "w") as f: f.write("TestAccuracy=0.88") if __name__ == "__main__": args = parse_args() print("Input1={}".format(args.input1)) print("Output1={}".format(args.output1)) # Tambahkan kode berdasarkan variabel global yang dikonfigurasi. print("Argument1={}".format(args.arg1)) print("Argument2={}".format(args.arg2)) # write_table_example(args) # write_output1(args)
-