Saat melatih model pembelajaran mesin, dataset berdimensi tinggi dapat memperlambat proses pelatihan dan menambahkan kebisingan. Principal Component Analysis (PCA) mengurangi dimensi dengan mengekstraksi sejumlah kecil komponen utama yang tidak berkorelasi dari fitur asli Anda, sambil mempertahankan varians sebanyak mungkin. Gunakan komponen PCA di Machine Learning Designer pada Platform for AI (PAI) untuk melakukan pra-pemrosesan data tabular sebelum pelatihan model tahap berikutnya.
Batasan
Komponen PCA hanya menerima data dalam dense format. Matriks sparse tidak didukung.
Konfigurasikan komponen
Tersedia dua metode konfigurasi: editor pipeline visual untuk pengaturan interaktif atau perintah PAI untuk alur kerja skrip dan otomatis.
Metode 1: Konfigurasikan di halaman pipeline
Di Machine Learning Designer, buka pipeline Anda, pilih komponen PCA, lalu atur parameter berikut.
| Tab | Parameter | Deskripsi |
|---|---|---|
| Fields setting | Feature columns | Kolom yang dipilih dari tabel input untuk dianalisis. |
| Fields setting | Appended columns | Kolom yang ditambahkan ke tabel output setelah reduksi dimensi. |
| Parameters setting | Data size ratio | Rasio varians terjelaskan yang akan dipertahankan. Nilai valid: (0, 1). Default: 0,9. |
| Parameters setting | Feature decomposition mode | Matriks yang digunakan untuk mendekomposisi fitur. |
| Parameters setting | Data conversion method | Metode yang digunakan untuk memproses data sebelum dekomposisi. |
| Tuning | Lifecycle | Siklus hidup tabel output. Harus berupa bilangan bulat positif. |
| Tuning | Cores | Jumlah core yang dialokasikan. Digunakan bersama dengan Memory size per node (Unit: MB). Nilai valid: [1, 9999]. |
| Tuning | Memory size per node (Unit: MB) | Memori per core, dalam MB. Nilai valid: [1024, 64 × 1024]. |
Metode 2: Gunakan perintah PAI
Jalankan perintah PAI melalui komponen SQL Script. Untuk informasi lebih lanjut, lihat SQL Script.
PAI -name PrinCompAnalysis
-project algo_public
-DinputTableName=bank_data
-DeigOutputTableName=pai_temp_2032_17900_2
-DprincompOutputTableName=pai_temp_2032_17900_1
-DselectedColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed
-DtransType=Simple
-DcalcuType=CORR
-DcontriRate=0.9;Parameter wajib
| Parameter | Deskripsi |
|---|---|
inputTableName | Tabel input yang digunakan untuk pelatihan. |
selectedColNames | Kolom yang dipilih untuk analisis. Pisahkan beberapa nama kolom dengan koma (,). Mendukung kolom bertipe data INT atau DOUBLE. |
eigOutputTableName | Tabel output yang berisi nilai eigen dan vektor eigen. |
princompOutputTableName | Tabel output setelah reduksi dimensi dan kebisingan komponen utama. |
Parameter opsional
| Parameter | Deskripsi | Default |
|---|---|---|
contriRate | Rasio varians terjelaskan yang akan dipertahankan. Nilai valid: (0, 1). | 0.9 |
transType | Metode pra-pemrosesan data. Nilai valid: Simple, Sub-Mean, Normalization. | Simple |
calcuType | Matriks dekomposisi fitur. Nilai valid: CORR, COVAR_SAMP, COVAR_POP. | CORR |
remainColumns | Kolom dari tabel asli yang dibawa ke output setelah reduksi dimensi. | None |
coreNum | Jumlah core. Digunakan bersama dengan memSizePerCore. Nilai valid: [1, 9999]. | Ditentukan oleh sistem |
memSizePerCore | Memori per core, dalam MB. Nilai valid: [1024, 64 × 1024]. | Ditentukan oleh sistem |
lifecycle | Siklus hidup tabel output. Harus berupa bilangan bulat positif. | None |
Contoh
Contoh berikut menggunakan tabel bank_data dengan tujuh kolom numerik (pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed) dan mempertahankan 90% varians terjelaskan menggunakan dekomposisi matriks korelasi.
Tabel output contoh
Tabel data setelah reduksi dimensi — berisi komponen utama yang dipertahankan sebagai kolom baru.
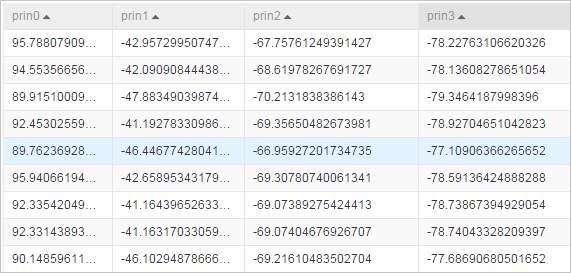
Tabel nilai eigen — menampilkan nilai eigen dan rasio varians terjelaskan kumulatif untuk setiap komponen. Gunakan tabel ini untuk memastikan jumlah komponen yang dipertahankan dan apakah ambang batas
contriRatetelah tercapai.