Model Large Mixture of Experts (MoE) seperti DeepSeek 671B memiliki jumlah parameter yang sangat besar sehingga tidak dapat dihosting oleh satu perangkat saja. Untuk mengatasi hal ini, EAS menyediakan solusi inferensi terdistribusi multi-node yang mengatasi keterbatasan perangkat keras dengan menerapkan satu instans layanan di beberapa mesin sekaligus serta mendukung penerapan dan eksekusi model skala besar secara efisien. Topik ini menjelaskan cara mengonfigurasi inferensi terdistribusi multi-node.
Catatan penggunaan
Beberapa citra resmi SGLang dan vLLM dari EAS atau Model Gallery secara native mendukung inferensi terdistribusi. Jika Anda menggunakan custom image untuk menerapkan inferensi terdistribusi, ikuti persyaratan jaringan dari framework inferensi terdistribusi yang digunakan serta pola pemrosesan terdistribusi standar. Untuk detailnya, lihat Cara kerja.
Cara kerja
Bagian ini menjelaskan konsep utama dan prinsip implementasi inferensi terdistribusi:
Unit instance
Dibandingkan dengan layanan inferensi EAS standar, inferensi terdistribusi memperkenalkan konsep unit instans (selanjutnya disebut Unit dalam topik ini). Instans dalam satu Unit berkoordinasi melalui komunikasi jaringan berkinerja tinggi serta pola seperti tensor parallelism (TP) dan pipeline parallelism (PP) untuk memproses setiap permintaan. Instans dalam satu Unit bersifat stateful, sedangkan Unit-unit tersebut sepenuhnya simetris dan tanpa status (stateless) relatif satu sama lain.
ID instans
Setiap instans dalam suatu Unit menerima ID instans melalui Variabel lingkungan. Untuk daftar Variabel lingkungan yang digunakan dalam suatu Unit beserta deskripsinya, lihat Lampiran. Instans menerima ID secara berurutan, yang dapat digunakan untuk menetapkan tugas berbeda ke instans yang berbeda.
Penanganan traffic
Secara default, setiap Unit hanya menangani traffic melalui instans 0-nya (RANK_ID = 0). Sistem menggunakan penemuan layanan (service discovery) untuk mengarahkan traffic pengguna ke instans 0 dari Unit yang berbeda. Setiap Unit kemudian memproses permintaan secara internal secara terdistribusi, dan menangani traffic secara independen tanpa saling mengganggu.

Pembaruan bergulir (rolling updates)
Saat pembaruan bergulir, suatu Unit dibangun ulang secara keseluruhan. Semua instans dalam Unit baru dimulai secara paralel. Setelah semua instans dalam Unit baru siap, sistem mengalihkan traffic dari Unit lama sebelum menghapus seluruh instansnya.

Siklus hidup
Unit Rebuild
Ketika suatu Unit dibuat ulang, semua instans dalam Unit lama dihapus secara paralel, dan semua instans dalam Unit baru juga dibuat secara paralel. Tidak ada penanganan khusus berdasarkan ID instans.
Pembuatan ulang instans
Secara default, siklus hidup setiap instans dalam suatu Unit mengikuti siklus hidup instans 0. Saat instans 0 dibuat ulang, semua instans lain dalam Unit tersebut juga dibuat ulang. Jika instans non-nol dibuat ulang, instans lain dalam Unit tersebut tidak terpengaruh.
Toleransi kesalahan terdistribusi
Penanganan kegagalan instans
Ketika sistem mendeteksi kegagalan pada salah satu instans layanan terdistribusi, sistem secara otomatis melakukan restart terhadap semua instans dalam Unit tersebut.
Tujuan: Mencegah inkonsistensi status kluster akibat titik kegagalan tunggal serta memastikan semua instans dimulai dalam lingkungan yang bersih dan konsisten.
Pemulihan terkoordinasi
Setelah instans direstart, sistem menunggu hingga semua instans dalam Unit mencapai status siap yang konsisten menggunakan penghalang sinkronisasi (synchronization barrier). Proses bisnis baru dimulai setelah semua instans siap.
Tujuan:
Mencegah kegagalan saat NCCL membentuk grup komunikasi akibat ketidakkonsistenan status instans.
Memastikan sinkronisasi startup yang ketat di seluruh node yang terlibat dalam tugas inferensi terdistribusi.
Toleransi kesalahan terdistribusi dinonaktifkan secara default. Untuk mengaktifkannya, atur parameter unit.guard. Contoh konfigurasi:
{
"unit": {
"size": 2,
"guard": true
}
}Konfigurasi inferensi terdistribusi multi-node
Penerapan satu klik menggunakan Model Gallery
Kami merekomendasikan penggunaan Model Gallery untuk penerapan terdistribusi multi-node.
Inferensi terdistribusi hanya didukung jika engine inferensi adalah SGLang atau vLLM.
Pilih sumber daya penerapan yang sesuai dengan templat yang Anda pilih.
Penerapan kustom menggunakan EAS
Masuk ke Konsol PAI. Pilih Wilayah di bagian atas halaman, lalu pilih ruang kerja yang diinginkan dan klik Elastic Algorithm Service (EAS).
Create a service: Di tab Inference Service, klik Deploy Service. Pilih Custom Model Deployment > Custom Deployment.
Update a service: Di tab Inference Service, temukan layanan target Anda dalam daftar layanan. Di kolom Actions, klik Update.
Dalam formulir konfigurasi parameter, atur parameter kunci berikut. Untuk detail parameter lainnya, lihat Custom Deployment.
Di bagian Environment Information, konfigurasikan runtime image dan perintah startup:
Image Configuration: Dalam daftar Alibaba Cloud Image, pilih citra vLLM atau SGLang.

Command: Setelah Anda memilih citra, sistem akan mengatur perintah startup secara otomatis. Jangan mengubahnya.
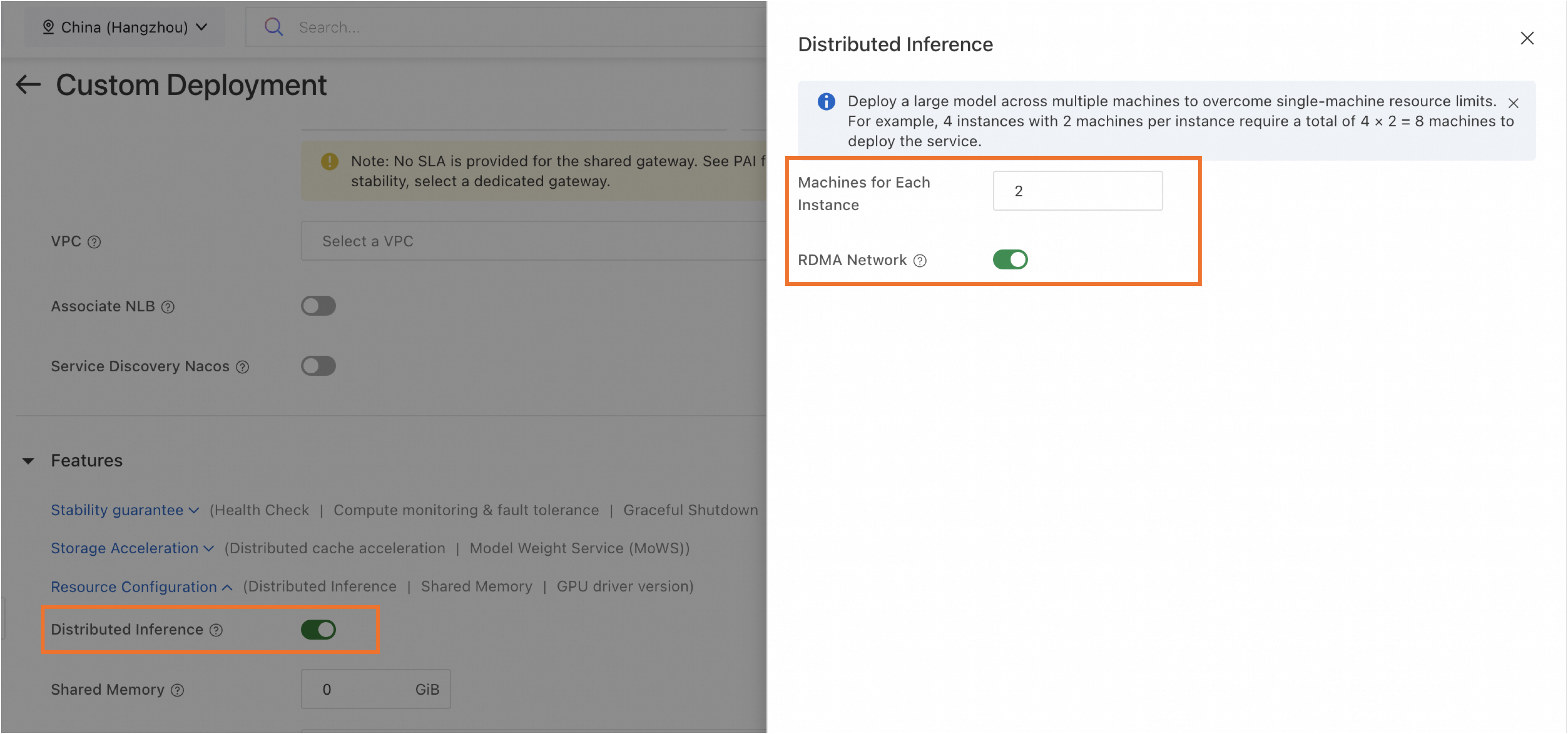
Di bagian Features, aktifkan Distributed Inference, lalu atur parameter kunci berikut:
Parameter
Description
Number of Machines for Single-Replica Deployment
Jumlah mesin yang digunakan untuk satu instans inferensi model. Nilai minimum adalah 2.
RDMA Network
Aktifkan RDMA untuk memastikan koneksi jaringan berkecepatan tinggi antar mesin.
CatatanRDMA hanya tersedia untuk layanan yang diterapkan pada Sumber daya komputasi cerdas Lingjun.
Setelah selesai mengonfigurasi parameter, klik Deploy atau Update.
Lampiran
Saat menerapkan layanan inferensi terdistribusi, Anda sering perlu mengonfigurasi jaringan—misalnya, menggunakan framework seperti Torch Distributed atau Ray. Jika Anda mengonfigurasi VPC atau RDMA, setiap instans memiliki beberapa network interface controller (NIC). Anda harus menentukan NIC mana yang digunakan untuk jaringan antar-instans.
RDMA enabled: Secara default menggunakan NIC RDMA (net0).
RDMA disabled: Menggunakan NIC VPC (eth1) yang dikonfigurasi oleh pengguna.
Anda meneruskan pengaturan terkait melalui Variabel lingkungan dan menggunakannya dalam perintah startup. Contoh:
Nama Variabel Lingkungan | Description | Contoh Nilai |
RANK_ID | ID instans, dimulai dari 0 dan bertambah 1. | 0 |
COMM_IFNAME | NIC yang digunakan untuk jaringan antar-instans:
| net0 |
RANK_IP | Alamat IP yang digunakan untuk jaringan antar-instans—yaitu IP dari NIC yang ditentukan oleh COMM_IFNAME. | 11.*.*.* |
MASTER_ADDRESS | Alamat IP instans 0 (RANK_ID = 0)—yaitu IP dari NIC yang ditentukan oleh COMM_IFNAME untuk instans 0. | 11.*.*.* |