Model Gallery mencakup berbagai Large Language Model (LLM) pre-train dan menyediakan kemampuan evaluasi model yang komprehensif untuk membantu Anda mengevaluasi kemampuan LLM.
Ikhtisar Fungsi
Fitur evaluasi model menilai LLM dalam dua dimensi:
Evaluasi dengan dataset kustom
Evaluasi berbasis aturan: Gunakan metrik ROUGE dan BLEU untuk mengukur kesamaan antara prediksi model dan jawaban ground truth.
Evaluasi LLM-as-a-Judge: Gunakan model juri berbasis PAI Qwen2 untuk memberi skor pada setiap output model secara individual. Metode ini sangat efektif untuk skenario tanya jawab terbuka dan kompleks.
Evaluasi dengan dataset publik
Evaluasi model pada dataset publik standar industri seperti MMLU, TriviaQA, HellaSwag, GSM8K, C-Eval, dan TruthfulQA.
Sediakan skor benchmark yang selaras dengan standar evaluasi industri.
Model yang didukung: Semua jenis model HuggingFace AutoModelForCausalLM.
Fitur baru: Penilaian LLM-as-a-Judge telah tersedia. Sebuah Large Language Model (LLM) berbasis Qwen2 berperan sebagai juri untuk memberi skor pada output model. Ini sangat ideal untuk skenario tanya jawab terbuka dan kompleks. Anda dapat mencobanya secara gratis di Mode Ahli dalam Evaluasi Model. [2024.09.01]
Skenario
Evaluasi model merupakan bagian penting dalam pengembangan model. Berikut adalah kasus penggunaan umum:
Benchmarking model
Evaluasi kemampuan umum model menggunakan dataset publik.
Bandingkan model Anda dengan benchmark industri atau model lainnya.
Evaluasi kemampuan spesifik domain
Terapkan model pada domain tertentu.
Bandingkan performa model pre-train dan fine-tuned di berbagai domain.
Evaluasi seberapa baik model menerapkan pengetahuan domain.
Pengujian regresi model
Buat set data pengujian regresi.
Evaluasi performa model dalam skenario bisnis nyata.
Tentukan apakah model memenuhi standar produksi.
Informasi Penagihan
Biaya penyimpanan OSS: Mencakup penyimpanan dataset evaluasi dan hasilnya. Untuk informasi lebih lanjut, lihat informasi penagihan OSS.
Biaya tugas evaluasi DLC: Mencakup eksekusi tugas evaluasi. Untuk informasi lebih lanjut, lihat informasi penagihan DLC.
Persiapan Data
Fitur evaluasi model mendukung evaluasi menggunakan dataset kustom maupun dataset publik seperti C-Eval.
Dataset publik:
PAI saat ini menyediakan dataset publik berikut: MMLU, TriviaQA, HellaSwag, GSM8K, C-Eval, dan TruthfulQA. Anda dapat langsung menggunakannya. Dataset publik tambahan akan segera ditambahkan.
Dataset kustom:
Anda dapat menyediakan file evaluasi dalam format JSONL. Unggah ke OSS dan buat dataset kustom. Untuk informasi lebih lanjut, lihat Unggah file OSS dan Buat dan kelola dataset. Format file adalah sebagai berikut:
Gunakan
questionuntuk melabeli kolom pertanyaan danansweruntuk melabeli kolom jawaban. Atau, Anda dapat memilih kolom tertentu pada halaman evaluasi. Jika Anda hanya perlu melakukan evaluasi dataset kustom–LLM-as-a-Judge, kolomanswerbersifat opsional.{"question": "Apakah Tiongkok menemukan pembuatan kertas? Apakah ini benar?", "answer": "Benar"} {"question": "Apakah Tiongkok menemukan mesiu? Apakah ini benar?", "answer": "Benar"}Contoh file: eval.jsonl
Alur Kerja

Langkah 1: Pilih model
Anda dapat menuju halaman Model Gallery.
Masuk ke Konsol PAI.
Pada panel navigasi di sebelah kiri, klik Workspaces. Lalu, pilih dan masuk ke workspace target Anda.
Pada panel navigasi di sebelah kiri, pilih QuickStart > Model Gallery untuk menuju halaman Model Gallery.
Anda dapat menemukan model yang mendukung evaluasi.
Anda dapat memfilter model yang dapat dievaluasi di Model Gallery. Pada bagian filter Supported Operations, pilih Evaluate untuk menampilkan hanya model yang mendukung evaluasi.
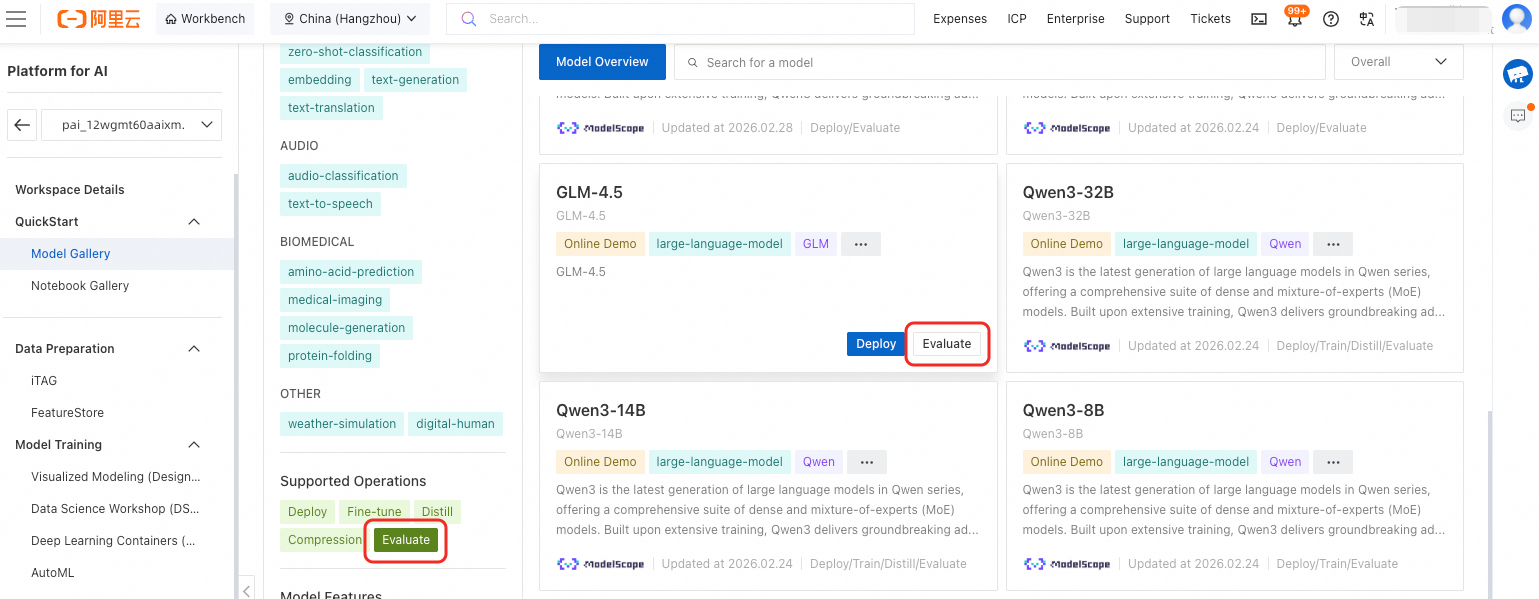
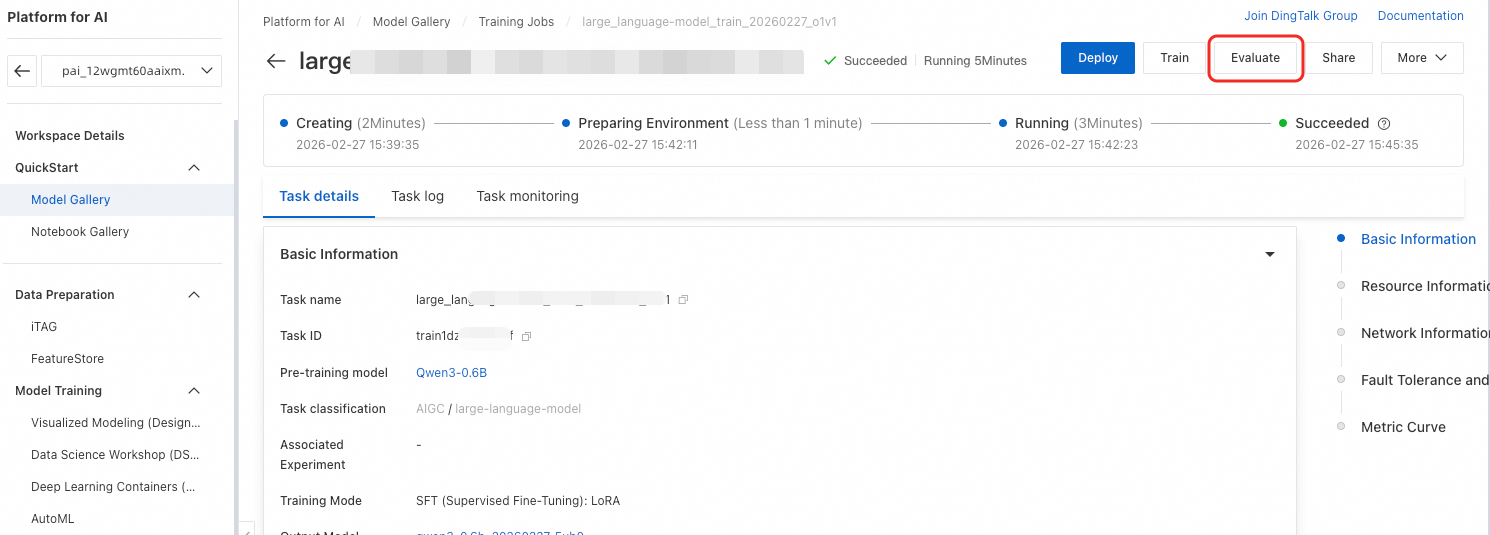
Anda dapat mengevaluasi model fine-tuned. Jika suatu model mendukung evaluasi, versi fine-tuned-nya juga mendukung evaluasi. Di halaman Model Gallery, klik Job Management > Training Jobs di pojok kiri atas. Lalu, klik nama pekerjaan target untuk membuka halaman detailnya. Klik tombol Evaluate di pojok kanan atas.
Langkah 2: Konfigurasikan tugas evaluasi
Anda dapat mengevaluasi menggunakan dataset publik maupun kustom. Anda juga dapat mengatur hiperparameter, menggunakan evaluasi LLM-as-a-Judge, serta memilih beberapa dataset publik sekaligus.
Anda dapat mengonfigurasi parameter dasar:
Job Name: Nama unik yang dihasilkan secara otomatis.
Result Output Path: Jalur OSS tempat hasil evaluasi disimpan.
Label: Anda dapat menggunakan tag untuk mencari, menemukan, melakukan operasi batch, dan mengalokasikan biaya dalam berbagai dimensi.
Anda dapat mengonfigurasi metode evaluasi:
Evaluation Method: Anda dapat memilih salah satu dari berikut:
Set Dataset to Public: Anda dapat memilih beberapa dataset.
Custom Dataset: Anda dapat menentukan kolom pertanyaan dan jawaban referensi. Jika Anda hanya memerlukan evaluasi LLM-as-a-Judge, kolom jawaban referensi bersifat opsional.
Dataset Source: Anda dapat memilih Select OSS File atau Select an existing dataset..
Evaluation Method: Anda dapat memilih Judge Model Evaluation atau General Metric Evaluation.
PAI-Judge Model Service Token: Parameter ini dikonfigurasi otomatis saat Anda menggunakan evaluasi LLM-as-a-Judge. Anda juga dapat memperolehnya dari halaman LLM-as-a-Judge.
Konfigurasikan sumber daya komputasi:
Resource Group Type: Pilih kelompok sumber daya publik bayar sesuai penggunaan atau kuota sumber daya langganan yang telah Anda buat.
Setelah selesai mengonfigurasi parameter, klik OK untuk mengirimkan tugas. Halaman akan secara otomatis dialihkan ke halaman detail tugas. Tunggu hingga tugas selesai. Lalu, klik Evaluation Report untuk melihat laporan.
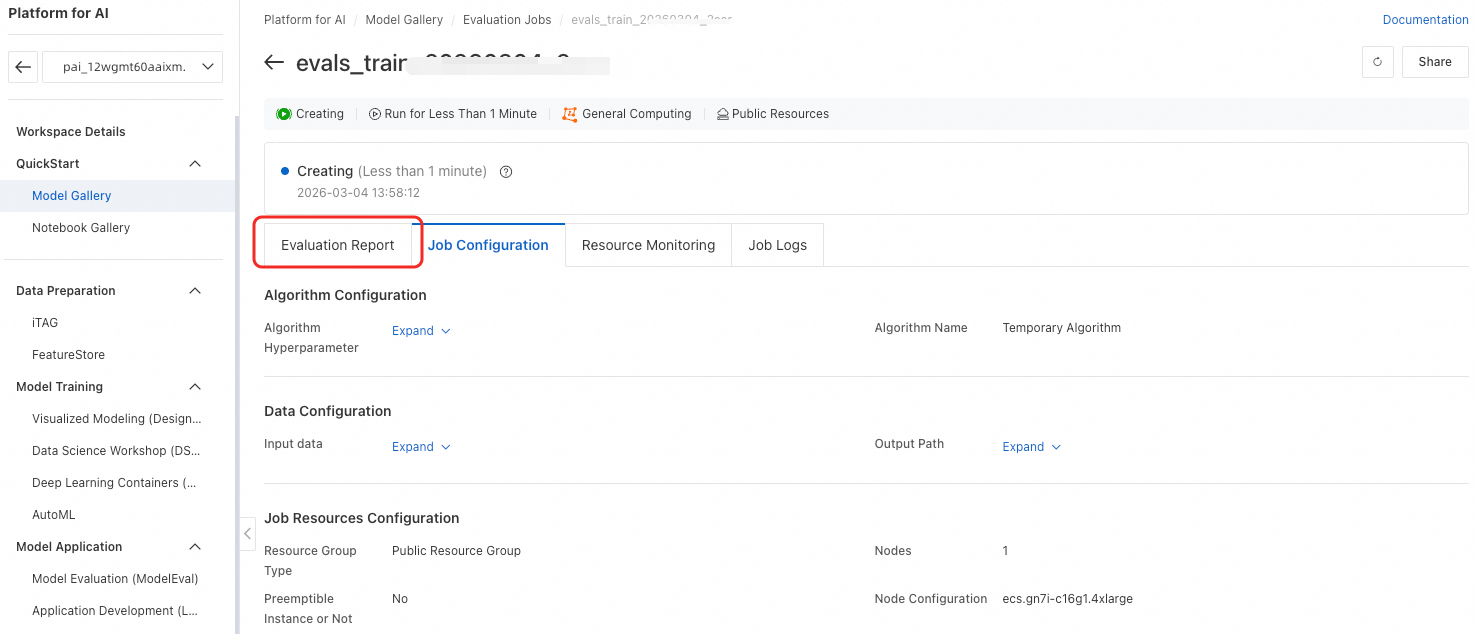
Lihat Hasil Evaluasi
Daftar Tugas Evaluasi
Di halaman Model Gallery, klik Job Management. Lalu, alihkan ke tab Evaluation Jobs.
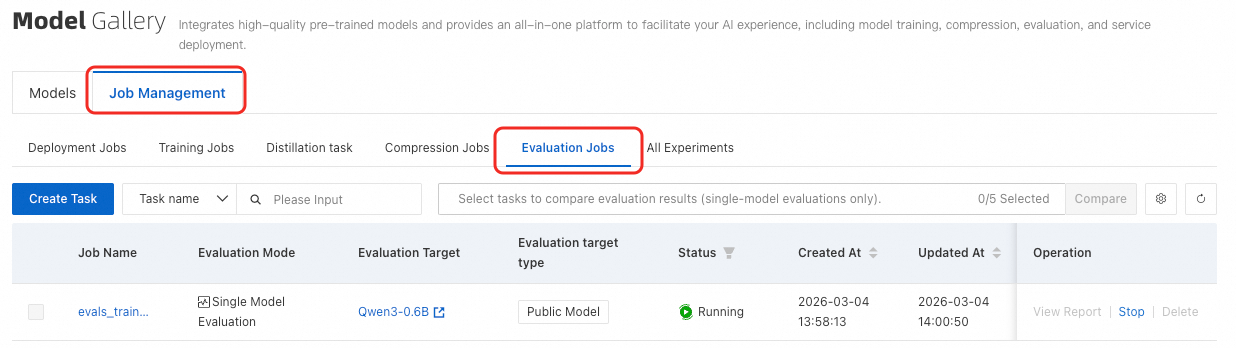
Hasil Tugas Tunggal
Di halaman daftar tugas evaluasi, klik View Report pada kolom Actions untuk tugas evaluasi target. Hal ini akan membuka halaman detail tugas. Di bagian Evaluation Report, Anda dapat melihat skor untuk dataset kustom maupun publik.
Halaman Hasil Evaluasi Dataset Kustom

Jika Anda memilih General Metric Evaluation, grafik radar menampilkan skor untuk metrik ROUGE dan BLEU. Metrik default untuk dataset kustom mencakup metrik berikut: rouge-1-f, rouge-1-p, rouge-1-r, rouge-2-f, rouge-2-p, rouge-2-r, rouge-l-f, rouge-l-p, rouge-l-r, bleu-1, bleu-2, bleu-3, dan bleu-4.
Metrik ROUGE:
Metrik ROUGE-n mengukur tumpang tindih N-gram. ROUGE-1 dan ROUGE-2 paling umum digunakan. Keduanya masing-masing berkorespondensi dengan unigram dan bigram:
rouge-1-p (Presisi): Rasio unigram dalam ringkasan sistem yang cocok dengan unigram dalam ringkasan referensi.
rouge-1-r (Recall): Rasio unigram dalam ringkasan referensi yang muncul dalam ringkasan sistem.
rouge-1-f (F-score): Rata-rata harmonik antara presisi dan recall.
rouge-2-p (Presisi): Rasio bigram dalam ringkasan sistem yang cocok dengan bigram dalam ringkasan referensi.
rouge-2-r (Recall): Rasio bigram dalam ringkasan referensi yang muncul dalam ringkasan sistem.
rouge-2-f (F-score): Rata-rata harmonik antara presisi dan recall.
ROUGE-L menggunakan longest common subsequence (LCS):
rouge-l-p (Presisi): Presisi berdasarkan kecocokan LCS antara ringkasan sistem dan referensi.
rouge-l-r (Recall): Recall berdasarkan kecocokan LCS antara ringkasan sistem dan referensi.
rouge-l-f (F-score): F-score berdasarkan kecocokan LCS antara ringkasan sistem dan referensi.
Metrik BLEU:
BLEU (Bilingual Evaluation Understudy) adalah metrik populer lainnya untuk mengevaluasi kualitas penerjemahan mesin. Metrik ini memberi skor pada output dengan mengukur tumpang tindih N-gram terhadap sekumpulan terjemahan referensi.
bleu-1: Mengukur tumpang tindih unigram.
bleu-2: Mengukur tumpang tindih bigram.
bleu-3: Mengukur tumpang tindih trigram (tiga kata berurutan).
bleu-4: Mengukur tumpang tindih 4-gram.
Jika Anda memilih evaluasi LLM-as-a-Judge, halaman tersebut menampilkan metrik statistik dari skor model juri.
Model juri adalah LLM berbasis Qwen2 yang telah difine-tune oleh PAI. Performanya setara dengan GPT-4 pada benchmark open-source seperti Alighbench. Dalam beberapa skenario, performanya bahkan melampaui GPT-4.
Halaman ini menampilkan empat metrik statistik dari skor model juri:
Mean: Skor rata-rata yang diberikan oleh LLM juri (tidak termasuk skor tidak valid). Skor berkisar antara 1 hingga 5. Nilai yang lebih tinggi menunjukkan tanggapan model yang lebih baik.
Median: Skor median yang diberikan oleh LLM juri (tidak termasuk skor tidak valid). Skor berkisar antara 1 hingga 5. Nilai yang lebih tinggi menunjukkan tanggapan model yang lebih baik.
Standard Deviation: Deviasi standar dari skor yang diberikan oleh LLM juri (tidak termasuk skor tidak valid). Dengan mean dan median yang sama, deviasi standar yang lebih kecil menunjukkan performa model yang lebih baik.
Skewness: Kemencengan distribusi skor LLM juri (tidak termasuk skor tidak valid). Skew positif berarti ekor lebih panjang di sisi kanan (skor tinggi). Skew negatif berarti ekor lebih panjang di sisi kiri (skor rendah).
Halaman ini juga menampilkan detail evaluasi untuk setiap baris dalam file evaluasi di bagian bawah.
Halaman Hasil Evaluasi Dataset Publik
Jika tugas evaluasi Anda menggunakan dataset publik, grafik radar menampilkan skor di berbagai dataset tersebut.

Grafik kiri menampilkan skor lintas domain. Setiap domain mungkin memiliki beberapa dataset terkait. Untuk dataset dalam domain yang sama, kami merata-ratakan skor model untuk memperoleh satu skor domain.
Grafik kanan menampilkan skor untuk setiap dataset publik. Anda dapat merujuk dokumentasi resmi masing-masing dataset untuk mengetahui cakupan evaluasinya.
Bandingkan Beberapa Tugas Evaluasi
Untuk membandingkan hasil dari beberapa model, Anda dapat mengelompokkannya dalam satu halaman. Di halaman daftar tugas evaluasi, pilih tugas yang ingin Anda bandingkan di sebelah kiri. Lalu, klik Compare di pojok kanan atas untuk membuka halaman perbandingan:

Hasil Perbandingan Dataset Kustom

Hasil Perbandingan Dataset Publik

Analisis Hasil
Evaluasi Dataset Kustom
Evaluasi metrik umum: Menggunakan metode pencocokan teks NLP standar untuk menghitung kesamaan antara output model dan ground truth. Skor yang lebih tinggi menunjukkan performa model yang lebih baik. Paling cocok untuk mengevaluasi seberapa baik model sesuai dengan skenario spesifik menggunakan data spesifik domain.
Evaluasi LLM-as-a-Judge: Memanfaatkan keunggulan LLM untuk mengevaluasi kualitas output pada tingkat semantik. Skor mean dan median yang lebih tinggi serta deviasi standar yang lebih rendah menunjukkan performa model yang lebih baik. Dibandingkan dengan pencocokan teks sederhana, metode ini memberikan penilaian kualitas output yang lebih akurat.
Evaluasi Dataset Publik
Ini adalah metode evaluasi LLM paling umum. Metode ini menggunakan dataset evaluasi open-source yang mencakup berbagai domain—seperti matematika dan pemrograman—untuk memberikan penilaian kemampuan yang komprehensif. Skor yang lebih tinggi menunjukkan performa model yang lebih baik.
Referensi
Anda juga dapat menggunakan evaluasi model melalui PAI Python SDK, bukan hanya melalui Konsol. Untuk informasi lebih lanjut, lihat notebook berikut: