Linear Support Vector Machine (SVM) adalah metode klasifikasi biner yang didasarkan pada teori pembelajaran statistik. Komponen ini menentukan batas keputusan yang memaksimalkan margin antara dua kelas dengan meminimalkan risiko struktural—tanpa menggunakan fungsi kernel.
Gunakan Linear SVM ketika:
Tugas klasifikasi bersifat biner (hanya melibatkan dua kelas).
Linear SVM tidak mendukung klasifikasi multikelas. Untuk tugas multikelas, gunakan komponen lain.
Referensi algoritma
Komponen Linear SVM mengimplementasikan metode Trust Region Newton untuk L2-SVM. Untuk detail selengkapnya, lihat bagian "Trust region method for L2-SVM" dalam Trust Region Newton Method for Large-Scale Logistic Regression.
Konfigurasi komponen
Tersedia dua metode konfigurasi: antarmuka visual Machine Learning Designer dan command line PAI. Gunakan antarmuka Designer untuk eksperimen interaktif; gunakan perintah PAI untuk alur kerja skript atau otomatis.
Metode 1: Konfigurasi di Machine Learning Designer
Port Masukan
Komponen Linear SVM memiliki satu port input. Hubungkan ke komponen Read Table.
Parameter
| Tab | Parameter | Wajib | Deskripsi |
|---|---|---|---|
| Fields Setting | Feature Columns | Ya | Kolom yang digunakan sebagai fitur. Tipe data yang diterima: BIGINT atau DOUBLE. |
| Fields Setting | Label Column | Ya | Kolom yang berisi label kelas. Tipe data yang diterima: BIGINT, DOUBLE, atau STRING. |
| Parameters Setting | Positive Sample Label | Tidak | Nilai label yang diperlakukan sebagai kelas positif. Jika tidak ditentukan, komponen akan memilih nilai secara acak. Tentukan parameter ini ketika distribusi kelas tidak seimbang. |
| Parameters Setting | Positive Penalty Factor | Tidak | Biaya yang diberikan untuk salah mengklasifikasikan contoh positif. Menaikkan nilai ini membuat model lebih memberatkan kesalahan pada kelas positif, yang berguna ketika false negative lebih merugikan. Nilai valid: (0, +∞). Default: 1.0. |
| Parameters Setting | Negative Penalty Factor | Tidak | Biaya yang diberikan untuk salah mengklasifikasikan contoh negatif. Menaikkan nilai ini membuat model lebih memberatkan kesalahan pada kelas negatif, yang berguna ketika false positive lebih merugikan. Nilai valid: (0, +∞). Default: 1.0. |
| Parameters Setting | Convergence Coefficient | Tidak | Toleransi konvergensi (epsilon). Pelatihan berhenti ketika perubahan antar iterasi turun di bawah nilai ini. Nilai yang lebih rendah meningkatkan presisi pelatihan tetapi memerlukan lebih banyak iterasi. Nilai valid: (0, 1). Default: 0.001. |
| Tuning | Cores | Tidak | Jumlah core CPU untuk pelatihan. Dialokasikan secara otomatis jika tidak ditentukan. |
| Tuning | Memory Size per Core | Tidak | Memori yang dialokasikan per core, dalam MB. Dialokasikan secara otomatis jika tidak ditentukan. |
Port Keluaran
Komponen ini menghasilkan model biner yang memiliki format yang sama dengan model batch untuk komponen prediksi downstream.
Metode 2: Jalankan perintah PAI
Gunakan komponen SQL Script untuk mengirimkan perintah PAI. Untuk instruksi penyiapan, lihat SQL Script.
PAI -name LinearSVM -project algo_public
-DinputTableName="bank_data"
-DmodelName="xlab_m_LinearSVM_6143"
-DfeatureColNames="pdays,emp_var_rate,cons_conf_idx"
-DlabelColName="y"
-DpositiveLabel="0"
-DpositiveCost="1.0"
-DnegativeCost="1.0"
-Depsilon="0.001";Parameter
| Parameter | Wajib | Deskripsi | Default |
|---|---|---|---|
inputTableName | Ya | Nama tabel input. | — |
inputTablepartitions | Tidak | Partisi yang digunakan untuk pelatihan. Format: Partition_name=value (tunggal) atau name1=value1/name2=value2 (multi-level). Pisahkan beberapa partisi dengan koma. | Semua partisi |
modelName | Ya | Nama untuk model output. | — |
featureColNames | Ya | Kolom fitur dari tabel input. | — |
labelColName | Ya | Nama kolom label. | — |
positiveLabel | Tidak | Nilai label untuk kelas positif. | Nilai acak dari kolom label |
positiveCost | Tidak | Faktor penalti positif. Menaikkan nilai ini membuat model lebih memberatkan kesalahan pada kelas positif. Nilai valid: (0, +∞). | 1.0 |
negativeCost | Tidak | Faktor penalti negatif. Menaikkan nilai ini membuat model lebih memberatkan kesalahan pada kelas negatif. Nilai valid: (0, +∞). | 1.0 |
epsilon | Tidak | Toleransi konvergensi. Nilai valid: (0, 1). | 0.001 |
enableSparse | Tidak | Atur ke true jika data input dalam format sparse. | false |
itemDelimiter | Tidak | Pembatas yang memisahkan pasangan kunci-nilai dalam input sparse. | , (koma) |
kvDelimiter | Tidak | Pembatas yang memisahkan kunci dan nilai dalam input sparse. | : (titik dua) |
coreNum | Tidak | Jumlah core CPU. Harus berupa bilangan bulat positif. | Dialokasikan otomatis |
memSizePerCore | Tidak | Memori per core, dalam MB. Nilai valid: 1–65536. | Dialokasikan otomatis |
Catatan penggunaan
Kelas tidak seimbang: Jika jumlah contoh positif dan negatif sangat tidak seimbang, atur Positive Sample Label secara eksplisit dan tingkatkan nilai positiveCost atau negativeCost untuk memberi bobot lebih tinggi pada kelas minoritas. Misalnya, jika false negative lebih merugikan daripada false positive, naikkan positiveCost di atas 1,0.
Data sparse: Untuk fitur sparse berdimensi tinggi (misalnya, data teks atau data one-hot encoded), atur enableSparse=true serta sesuaikan itemDelimiter dan kvDelimiter agar sesuai dengan format data Anda.
Penyetelan resource: Biarkan Cores dan Memory Size per Core tidak diatur untuk sebagian besar beban kerja—platform akan mengalokasikan sumber daya secara otomatis berdasarkan ukuran data. Atur secara manual hanya jika Anda memerlukan alokasi sumber daya yang dapat diprediksi.
Contoh
Contoh ini melatih model klasifikasi biner Linear SVM pada set data kecil.
Gunakan data pelatihan berikut sebagai input.
id y f0 f1 f2 f3 f4 f5 f6 f7 1 -1 -0.294118 0.487437 0.180328 -0.292929 -1 0.00149028 -0.53117 -0.0333333 2 +1 -0.882353 -0.145729 0.0819672 -0.414141 -1 -0.207153 -0.766866 -0.666667 3 -1 -0.0588235 0.839196 0.0491803 -1 -1 -0.305514 -0.492741 -0.633333 4 +1 -0.882353 -0.105528 0.0819672 -0.535354 -0.777778 -0.162444 -0.923997 -1 5 -1 -1 0.376884 -0.344262 -0.292929 -0.602837 0.28465 0.887276 -0.6 6 +1 -0.411765 0.165829 0.213115 -1 -1 -0.23696 -0.894962 -0.7 7 -1 -0.647059 -0.21608 -0.180328 -0.353535 -0.791962 -0.0760059 -0.854825 -0.833333 8 +1 0.176471 0.155779 -1 -1 -1 0.052161 -0.952178 -0.733333 9 -1 -0.764706 0.979899 0.147541 -0.0909091 0.283688 -0.0909091 -0.931682 0.0666667 10 -1 -0.0588235 0.256281 0.57377 -1 -1 -1 -0.868488 0.1 Gunakan data uji berikut sebagai input.
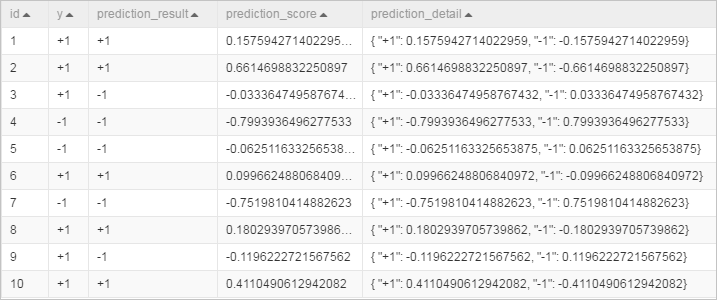
id y f0 f1 f2 f3 f4 f5 f6 f7 1 +1 -0.882353 0.0854271 0.442623 -0.616162 -1 -0.19225 -0.725021 -0.9 2 +1 -0.294118 -0.0351759 -1 -1 -1 -0.293592 -0.904355 -0.766667 3 +1 -0.882353 0.246231 0.213115 -0.272727 -1 -0.171386 -0.981213 -0.7 4 -1 -0.176471 0.507538 0.278689 -0.414141 -0.702128 0.0491804 -0.475662 0.1 5 -1 -0.529412 0.839196 -1 -1 -1 -0.153502 -0.885568 -0.5 6 +1 -0.882353 0.246231 -0.0163934 -0.353535 -1 0.0670641 -0.627669 -1 7 -1 -0.882353 0.819095 0.278689 -0.151515 -0.307329 0.19225 0.00768574 -0.966667 8 +1 -0.882353 -0.0753769 0.0163934 -0.494949 -0.903073 -0.418778 -0.654996 -0.866667 9 +1 -1 0.527638 0.344262 -0.212121 -0.356974 0.23696 -0.836038 -0.8 10 +1 -0.882353 0.115578 0.0163934 -0.737374 -0.56974 -0.28465 -0.948762 -0.933333 Buat pipeline seperti pada gambar berikut. Untuk informasi lebih lanjut, lihat Algorithm modeling.
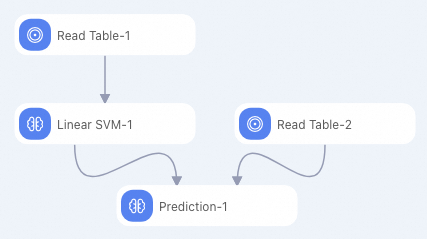
Konfigurasikan parameter yang tercantum dalam tabel berikut untuk komponen Linear SVM. Gunakan nilai default untuk semua parameter lainnya.
Tab Parameter Nilai Fields Setting Feature Columns Pilih f0, f1, f2, f3, f4, f5, f6, dan f7. Fields Setting Label Column Pilih y. Jalankan pipeline dan lihat hasil prediksi.