Komponen Linear Model Feature Importance menghitung skor pentingnya fitur untuk model linier, termasuk regresi linier dan regresi logistik untuk klasifikasi biner. Komponen ini mendukung format data masukan sparse maupun dense.
Gunakan komponen ini untuk mengidentifikasi fitur yang paling berkontribusi terhadap prediksi model—langkah kunci dalam debugging model, pemilihan fitur, dan membangun kepercayaan terhadap perilaku model.
Batasan
Komponen ini hanya dapat dijalankan pada sumber daya komputasi MaxCompute.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Model linier yang telah dilatih (regresi linier atau regresi logistik untuk klasifikasi biner)
Tabel input di MaxCompute yang berisi kolom fitur dan kolom label
Konfigurasi komponen
Konfigurasikan komponen menggunakan salah satu metode berikut.
Metode 1: Konsol PAI (Machine Learning Designer)
Atur parameter pada tab Fields Setting dan tab Tuning di Machine Learning Designer.
Fields Setting
| Parameter | Wajib | Deskripsi | Bawaan |
|---|---|---|---|
| Feature columns | Tidak | Kolom fitur untuk pelatihan dari tabel input | Semua kolom kecuali kolom label |
| Target column | Ya | Kolom label. Klik Select fields, cari kolom berdasarkan kata kunci, pilih kolom tersebut, lalu klik OK. | — |
| Input sparse format data | Tidak | Menentukan apakah data input dalam format sparse | — |
Tuning tab
| Parameter | Wajib | Deskripsi | Bawaan |
|---|---|---|---|
| Cores | Tidak | Jumlah core untuk komputasi | Ditentukan oleh sistem |
| Memory size per core | Tidak | Memori yang dialokasikan untuk setiap core, dalam MB | Ditentukan oleh sistem |
Metode 2: Perintah PAI
Jalankan komponen menggunakan perintah PAI. Gunakan komponen SQL Script untuk memanggil perintah PAI. Untuk informasi selengkapnya, lihat SQL Script.
PAI -name regression_feature_importance -project algo_public
-DmodelName=xlab_m_logisticregressi_20317_v0
-DoutputTableName=pai_temp_2252_20321_1
-DlabelColName=y
-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
-DenableSparse=false -DinputTableName=pai_dense_10_9;| Parameter | Wajib | Deskripsi | Bawaan |
|---|---|---|---|
inputTableName | Ya | Nama tabel input | Tidak ada |
outputTableName | Ya | Nama tabel output | Tidak ada |
labelColName | Ya | Kolom label dari tabel input | Tidak ada |
modelName | Ya | Nama model input | Tidak ada |
featureColNames | Tidak | Kolom fitur dari tabel input | Semua kolom kecuali kolom label |
inputTablePartitions | Tidak | Partisi yang akan dibaca dari tabel input | Seluruh tabel |
enableSparse | Tidak | Menentukan apakah data input dalam format sparse | false |
itemDelimiter | Tidak | Pembatas antar pasangan kunci-nilai dalam data sparse | Spasi |
kvDelimiter | Tidak | Pembatas antara kunci dan nilai dalam data sparse | Titik dua (:) |
lifecycle | Tidak | Siklus hidup tabel output | Tidak ditentukan |
coreNum | Tidak | Jumlah core | Ditentukan oleh sistem |
memSizePerCore | Tidak | Ukuran memori per core | Ditentukan oleh sistem |
Contoh
Contoh ini menggunakan set data bank_data untuk melatih model regresi logistik, lalu menghitung skor pentingnya fitur.
Buat tabel bernama
bank_datadan impor data. Untuk informasi selengkapnya, lihat Buat tabel dan Impor data ke tabel.Jalankan Pernyataan SQL berikut untuk menghasilkan data pelatihan:
CREATE TABLE IF NOT EXISTS pai_dense_10_9 AS SELECT age, campaign, pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, fixed_deposit FROM bank_data LIMIT 10;Buat dan jalankan pipeline di Machine Learning Designer. Untuk informasi selengkapnya tentang pembuatan pipeline, lihat Pemodelan algoritma.
Pada daftar komponen, cari dan seret tiga komponen berikut ke kanvas: Read Table, Logistic Regression for Multiclass Classification, dan Linear Model Feature Importance.
Sambungkan komponen sesuai urutan yang ditunjukkan pada gambar di atas.
Konfigurasikan setiap komponen:
Klik Read Table-1. Pada tab Select table, atur Table name menjadi
bank_data.Klik Logistic Regression for Multiclass Classification-1. Pada tab Fields Setting, atur Training feature columns menjadi
age,campaign,pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m, dannr_installed. Atur Target column menjadifixed_deposit.Klik Linear Model Feature Importance-1. Pada tab Fields Setting, atur Target column menjadi
fixed_deposit.
Klik
 untuk menjalankan pipeline.
untuk menjalankan pipeline.
Setelah pipeline selesai, klik kanan Linear Model Feature Importance-1 dan pilih View data > Model importance table.
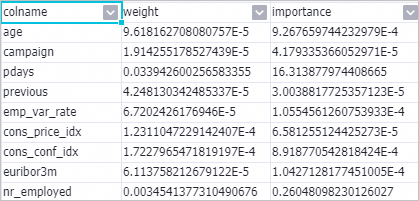 Tabel output berisi dua kolom:
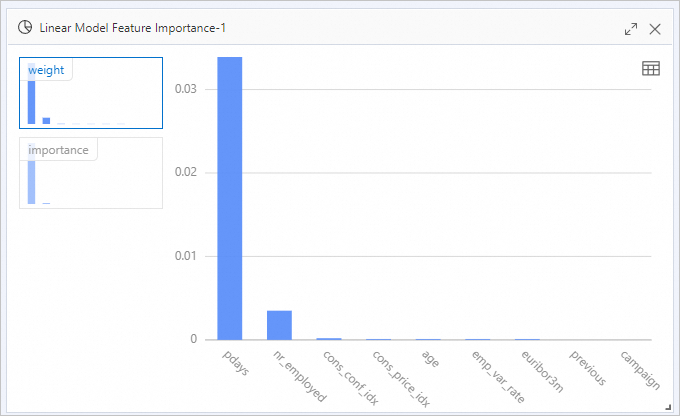
Tabel output berisi dua kolom:Kolom Rumus Apa yang diukur weightabs(w_)Nilai absolut koefisien fitur importanceabs(w_j) × STD(f_i)Koefisien yang diskalakan berdasarkan deviasi standar fitur (deviasi standar dari data pelatihan) Klik kanan Linear Model Feature Importance-1 dan pilih View analytics report untuk melihat peringkat pentingnya fitur dalam bentuk visualisasi.
Langkah berikutnya
Untuk ikhtisar semua komponen yang tersedia di Machine Learning Designer, lihat Overview of Machine Learning Designer.
Untuk mengeksplorasi komponen algoritma lainnya, lihat Referensi komponen: Ikhtisar semua komponen.