Label Propagation Classification adalah algoritma pembelajaran semi-terawasi yang dirancang untuk menyebarkan informasi label antara titik data berlabel dan tidak berlabel menggunakan struktur graf. Algoritma ini membangun graf berdasarkan kesamaan antar titik data dan secara iteratif memperbarui distribusi label dari node hingga mencapai konvergensi. Dengan menggunakan informasi dari sejumlah kecil sampel berlabel, algoritma ini mampu memperluas klasifikasi ke seluruh dataset, sehingga meningkatkan performa klasifikasi.
Deskripsi Algoritma
Ketika sistem menjalankan algoritma Label Propagation Classification, label setiap vertex disebarkan ke vertex tetangga berdasarkan kesamaan. Pada setiap langkah penyebaran, setiap vertex memperbarui labelnya berdasarkan label dari vertex tetangganya. Semakin tinggi kesamaan, semakin besar pengaruh penandaan dari vertex tetangga terhadap vertex tersebut. Selama proses penyebaran, label dari data berlabel tetap tidak berubah dan berfungsi sebagai sumber untuk penyebaran ke data tidak berlabel. Setelah iterasi selesai, distribusi probabilitas dari vertex serupa cenderung menjadi serupa, sehingga vertex dapat diklasifikasikan ke dalam kategori yang sama.
Konfigurasikan Komponen
Metode 1: Konfigurasikan komponen di halaman pipeline
Anda dapat menambahkan komponen Label Propagation Classification di halaman pipeline Machine Learning Designer dalam konsol Platform for AI (PAI). Tabel berikut menggambarkan parameter yang digunakan.
Tab | Parameter | Deskripsi |
Fields Setting | Vertex Table: Vertex Column | Kolom vertex dalam tabel vertex. |
Vertex Table: Label Column | Kolom label vertex dalam tabel vertex. | |
Vertex Table: Weight Column | Kolom bobot vertex dalam tabel vertex. | |
Edge Table: Source Vertex Column | Kolom vertex awal dalam tabel edge. | |
Edge Table: Target Vertex Column | Kolom vertex tujuan dalam tabel edge. | |
Edge Table: Select Weight Column | Kolom bobot edge dalam tabel edge. | |
Parameters Setting | Maximum Number of Iterations | Jumlah maksimum iterasi. Nilai default: 30. |
Damping Coefficient | Koefisien redaman. Nilai default: 0.8. | |
Convergence Coefficient | Koefisien konvergensi. Nilai default: 0.000001. | |
Tuning | Number of Workers | Jumlah vertex untuk eksekusi pekerjaan paralel. Tingkat paralelisme dan biaya komunikasi kerangka meningkat dengan nilai parameter ini. |
Worker Memory (MB) | Ukuran maksimum memori yang dapat digunakan oleh satu pekerjaan. Unit: MB. Nilai default: 4096. Jika ukuran memori yang digunakan melebihi nilai parameter ini, kesalahan |
Metode 2: Konfigurasikan komponen menggunakan perintah PAI
Anda dapat mengonfigurasi komponen Label Propagation Classification menggunakan perintah PAI. Anda dapat menggunakan komponen SQL Script untuk menjalankan perintah PAI. Untuk informasi lebih lanjut, lihat Skenario 4: Jalankan perintah PAI dalam komponen SQL script di topik "SQL Script".
PAI -name LabelPropagationClassification
-project algo_public
-DinputEdgeTableName=LabelPropagationClassification_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DinputVertexTableName=LabelPropagationClassification_func_test_node
-DvertexCol=node
-DvertexLabelCol=label
-DoutputTableName=LabelPropagationClassification_func_test_result
-DhasEdgeWeight=true
-DedgeWeightCol=edge_weight
-DhasVertexWeight=true
-DvertexWeightCol=label_weight
-Dalpha=0.8
-Depsilon=0.000001;Parameter | Diperlukan | Nilai Default | Deskripsi |
inputEdgeTableName | Ya | Tidak ada nilai default | Nama tabel edge input. |
inputEdgeTablePartitions | Tidak | Tabel penuh | Partisi dalam tabel edge input. |
fromVertexCol | Ya | Tidak ada nilai default | Kolom vertex awal dalam tabel edge input. |
toVertexCol | Ya | Tidak ada nilai default | Kolom vertex tujuan dalam tabel edge input. |
inputVertexTableName | Ya | Tidak ada nilai default | Nama tabel vertex input. |
inputVertexTablePartitions | Tidak | Tabel penuh | Partisi dalam tabel vertex input. |
vertexCol | Ya | Tidak ada nilai default | Kolom vertex dalam tabel vertex input. |
outputTableName | Ya | Tidak ada nilai default | Nama tabel output. |
outputTablePartitions | Tidak | Tidak ada nilai default | Partisi dalam tabel output. |
lifecycle | Tidak | Tidak ada nilai default | Siklus hidup tabel output. |
workerNum | Tidak | Tidak ada nilai default | Jumlah vertex untuk eksekusi pekerjaan paralel. Tingkat paralelisme dan biaya komunikasi kerangka meningkat dengan nilai parameter ini. |
workerMem | Tidak | 4096 | Ukuran maksimum memori yang dapat digunakan oleh satu pekerjaan. Unit: MB. Nilai default: 4096. Jika ukuran memori yang digunakan melebihi nilai parameter ini, kesalahan |
splitSize | Tidak | 64 | Ukuran pemisahan data. Unit: MB. |
hasEdgeWeight | Tidak | false | Menentukan apakah edge dalam tabel edge input memiliki bobot. |
edgeWeightCol | Tidak | Tidak ada nilai default | Kolom bobot edge dalam tabel edge input. |
hasVertexWeight | Tidak | false | Menentukan apakah vertex dalam tabel vertex input memiliki bobot. |
vertexWeightCol | Tidak | Tidak ada nilai default | Kolom bobot vertex dalam tabel vertex input. |
alpha | Tidak | 0.8 | Koefisien redaman. |
epsilon | Tidak | 0.000001 | Koefisien konvergensi. |
maxIter | Tidak | 30 | Jumlah maksimum iterasi. |
Contoh
Tambahkan komponen SQL Script. Hilangkan centang pada Use Script Mode dan Whether the system adds a create table statement. Kemudian, masukkan pernyataan SQL berikut.
drop table if exists LabelPropagationClassification_func_test_edge; create table LabelPropagationClassification_func_test_edge as select * from ( select 'a' as flow_out_id, 'b' as flow_in_id, 0.2 as edge_weight union all select 'a' as flow_out_id, 'c' as flow_in_id, 0.8 as edge_weight union all select 'b' as flow_out_id, 'c' as flow_in_id, 1.0 as edge_weight union all select 'd' as flow_out_id, 'b' as flow_in_id, 1.0 as edge_weight )tmp ; drop table if exists LabelPropagationClassification_func_test_node; create table LabelPropagationClassification_func_test_node as select * from ( select 'a' as node,'X' as label, 1.0 as label_weight union all select 'd' as node,'Y' as label, 1.0 as label_weight )tmp;Struktur Data
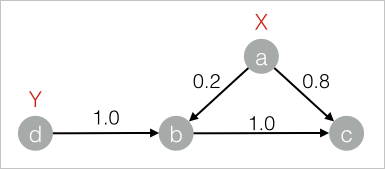
Tambahkan komponen SQL Script lainnya. Hilangkan centang pada Use Script Mode dan Whether the system adds a create table statement. Masukkan pernyataan SQL berikut dan hubungkan kedua komponen pada langkah 1 dan 2.
drop table if exists ${o1}; PAI -name LabelPropagationClassification -project algo_public -DinputEdgeTableName=LabelPropagationClassification_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DinputVertexTableName=LabelPropagationClassification_func_test_node -DvertexCol=node -DvertexLabelCol=label -DoutputTableName=${o1} -DhasEdgeWeight=true -DedgeWeightCol=edge_weight -DhasVertexWeight=true -DvertexWeightCol=label_weight -Dalpha=0.8 -Depsilon=0.000001;Klik
 di sudut kiri atas untuk menjalankan pipeline.
di sudut kiri atas untuk menjalankan pipeline.Klik kanan komponen SQL Script pada langkah 2 dan pilih View Data > SQL Script Output untuk melihat hasil pelatihan.
| node | tag | weight | | ---- | --- | ------------------- | | a | X | 1.0 | | c | X | 0.5370370370370371 | | c | Y | 0.4629629629629629 | | b | X | 0.16666666666666666 | | b | Y | 0.8333333333333333 | | d | Y | 1.0 |