EAS secara otomatis memeriksa daya komputasi GPU dan kesehatan komunikasi antar-node untuk penerapan inferensi terdistribusi skala besar.
Cakupan penerapan
Fitur ini berlaku untuk layanan inferensi terdistribusi multi-node yang diterapkan pada Sumber daya komputasi cerdas Lingjun.
Konsep utama
-
Waktu deteksi:
-
Sebelum startup instans: Berjalan sebelum aplikasi dalam instans layanan (Pod) dimulai untuk mendeteksi masalah perangkat keras atau jaringan guna mencegah kegagalan startup.
-
Saat waktu proses instans: Berjalan sebagai proses latar belakang bersamaan dengan layanan.
-
-
Item pemeriksaan:
-
Sebelum startup instans: Pemeriksaan performa komputasi, pemeriksaan komunikasi node, dan cross-check antara komputasi dan komunikasi.
-
Saat waktu proses instans: Hanya C4D (pemeriksaan kesehatan GPU).
-
Untuk detail mengenai item pemeriksaan, lihat Lampiran: Item pemeriksaan.
-
-
Penanganan kondisi abnormal:
-
Kegagalan startup instans: Jika ditemukan masalah, sistem menghentikan proses startup instans saat ini.
-
Tidak ada aksi: Sistem hanya mencatat event tanpa mengambil tindakan lain.
-
Prosedur
Aktifkan dan konfigurasikan pemantauan komputasi
-
Masuk ke Konsol PAI. Pilih wilayah di bagian atas halaman, lalu pilih ruang kerja yang diinginkan dan klik Elastic Algorithm Service (EAS).
-
Klik Deploy Service. Di bagian Custom Model Deployment, klik Custom Deployment.
-
Di bagian Features, di bawah Stability Guarantee, aktifkan Compute monitoring & fault tolerance. Di panel yang muncul, konfigurasikan parameter pemeriksaan. Untuk menggunakan file JSON sebagai gantinya, lihat Lampiran: Parameter file JSON.
CatatanKedua pemeriksaan "Before running" dan "Instance running" dapat ditambahkan.
-
Konfigurasikan pemeriksaan pra-jalankan (opsional):
-
Waktu deteksi: Pilih Before running.
-
Item pemeriksaan: Pilih item pemeriksaan sesuai kebutuhan, seperti Run Compute Performance Check dan Run Node Communication Check. Secara default, GPU GEMM, All-Reduce (single-node), dan All-Reduce (between two nodes) diaktifkan.
-
Tetapkan timeout yang sesuai berdasarkan perkiraan durasi di Item pemeriksaan. Pemeriksaan dijalankan secara berurutan. Timeout default adalah 5 menit. Pemeriksaan yang melebihi waktu ini dianggap gagal.
-
Penanganan kondisi abnormal: Nilai default adalah Instance startup failed. Pilih Rebuild Instance berdasarkan kebijakan disaster recovery Anda.
-
-
Konfigurasikan pemeriksaan saat berjalan (opsional):
-
Waktu deteksi: Pilih Instance running.
-
Item pemeriksaan: Hanya C4D yang tersedia.
-
Penanganan kondisi abnormal: Hanya Ignore yang tersedia.
-
-
Lihat hasil pemeriksaan
Setelah mengonfigurasi fitur ini, lihat laporan pemeriksaan dengan salah satu cara berikut:
-
Metode 1: Dari daftar instans
-
Di halaman detail layanan, buka tab Overview.
-
Di Service Instance, temukan instans target dan klik View results di kolom Actions.

-
-
Metode 2: Dari event penerapan
-
Di halaman detail layanan, buka tab Deployment Events.
-
Temukan event bertipe
SanityCheckSucceededatauSanityCheckFaileddan klik View results di kolom Actions.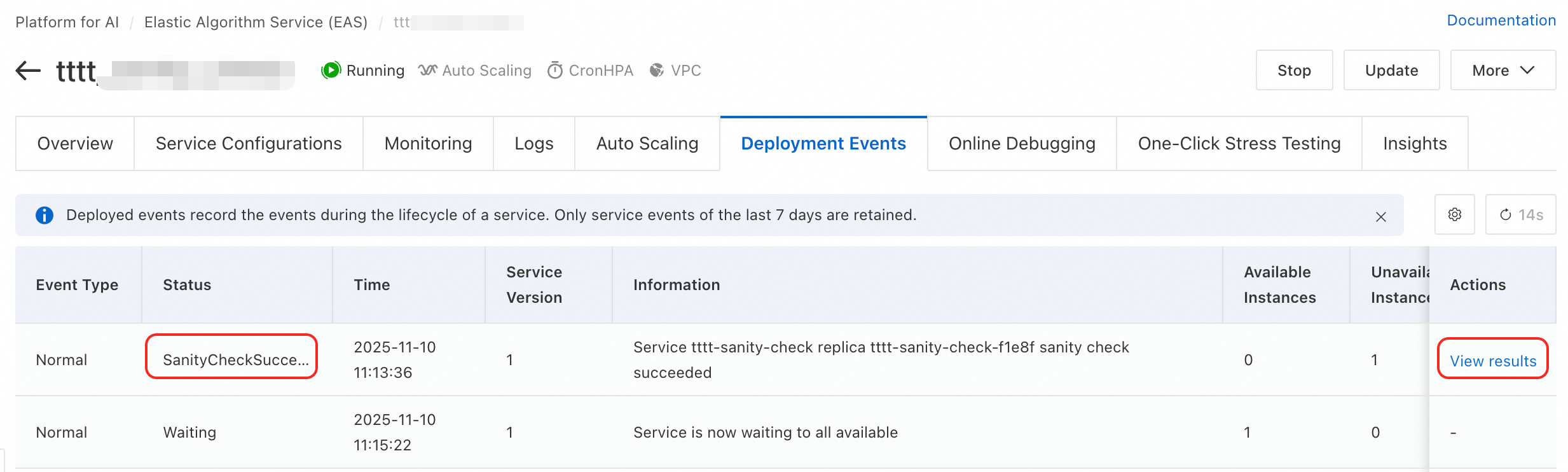
-
Panel Health check results akan muncul. Lihat laporan detail untuk setiap item pemeriksaan.
FAQ
Apa penyebab umum kegagalan pemeriksaan All-Reduce?
Kegagalan pemeriksaan All-Reduce biasanya menunjukkan masalah komunikasi jaringan seperti latensi tinggi, kehilangan paket parah, atau konfigurasi Remote Direct Memory Access (RDMA) yang salah antar-node. Gunakan data detail dalam laporan untuk mendiagnosis node dengan komunikasi lambat.
Lampiran: Item pemeriksaan
|
Item pemeriksaan |
Deskripsi |
Perkiraan durasi |
|
|
Sebelum startup instans |
|||
|
Pemeriksaan performa komputasi |
GPU GEMM |
Memeriksa performa GPU GEMM untuk mengidentifikasi:
|
1 menit |
|
GPU Kernel Launch |
Memeriksa latensi peluncuran kernel GPU untuk mengidentifikasi:
|
1 menit |
|
|
Pemeriksaan komunikasi node |
All-Reduce |
Memeriksa performa komunikasi antar-node melalui berbagai pola untuk mengidentifikasi:
|
Per pemeriksaan komunikasi kolektif: 5 menit |
|
All-to-All |
|||
|
All-Gather |
|||
|
Multi-All-Reduce |
|||
|
PyTorch-Gloo |
Memeriksa komunikasi antar-node melalui PyTorch Gloo untuk mengidentifikasi node rusak. |
1 menit |
|
|
Network Connectivity |
Memeriksa konektivitas jaringan node head atau tail untuk mengidentifikasi masalah konektivitas. |
2 menit |
|
|
Cross-check untuk komputasi dan komunikasi |
MatMul/All-Reduce Overlap |
Memeriksa performa single-node saat kernel komunikasi dan komputasi tumpang tindih untuk mengidentifikasi:
|
1 menit |
|
Saat waktu proses instans |
|||
|
C4D |
Memeriksa kesehatan GPU selama waktu proses instans. |
||
Lampiran: Parameter file JSON
Contoh konfigurasi
{
"aimaster": {
"runtime_check": {
"fail_action": "retain",
"micro_benchmarks": "c4d"
},
"sanity_check": {
"fail_action": "retain",
"micro_benchmarks": "gemm_flops,all_reduce_1,all_reduce_2,kernel_launch,all_reduce,all_to_all_2,all_gather_2,all_gather,multi_all_reduce_2,multi_all_reduce,pytorch_gloo_2,network_connectivity,comp_comm_overlap",
"timeout": 100
}
}
}Parameter
|
Parameter |
Deskripsi |
||
|
aimaster |
runtime_check Pemeriksaan yang dilakukan selama waktu proses instans. |
fail_action |
Aksi yang diambil saat kondisi abnormal terdeteksi. |
|
micro_benchmarks |
Item pemeriksaan. Nilai valid: C4D. |
||
|
sanity_check Pemeriksaan yang dilakukan sebelum startup instans. |
fail_action |
Aksi yang diambil saat kondisi abnormal terdeteksi. |
|
|
micro_benchmarks |
Item pemeriksaan. Pisahkan beberapa item dengan koma. |
||
|
timeout |
Durasi maksimum pemeriksaan, dalam menit. |
||