Pelaku penipuan jarang bertindak sendiri. Mereka beroperasi dalam jaringan—berbagi akun, alamat, perangkat, dan kontak. Sistem berbasis aturan tradisional mengevaluasi setiap individu secara terpisah dan mengabaikan koneksi tersembunyi ini. Algoritma graf mendeteksi penipuan dengan menganalisis hubungan antarindividu, bukan hanya atribut masing-masing.
Tutorial ini menjelaskan cara menggunakan templat pipeline Financial Risk Management di PAI Designer untuk menghitung skor probabilitas penipuan bagi setiap individu dalam jaringan hubungan.
Cara pipeline mendeteksi penipuan
Pipeline merepresentasikan individu sebagai vertex dan hubungan mereka sebagai edge. Setiap edge memiliki nilai count yang mengukur kedekatan—nilai yang lebih tinggi menunjukkan hubungan yang lebih kuat.
Tiga komponen algoritma graf dijalankan secara berurutan:
Maximum Connected Subgraph — mengklasifikasikan individu dalam graf hubungan menjadi dua kelompok dan memberikan ID pada masing-masing kelompok. Kemudian, bersama komponen SQL Script dan JOIN, menghapus individu yang tidak terkait dengan memilih himpunan yang berisi jumlah terbesar individu yang saling terhubung.
Single-Source Shortest Path — mengukur jumlah individu yang harus dihubungi Enoch untuk mencapai target. Bidang output
distancemencatat jumlah hop tersebut.Label Propagation Classification — menyebarkan label penipuan dari kasus yang diketahui (Evan, seorang penipu) melalui jaringan. Label menyebar dari vertex berlabel ke vertex yang berdekatan dengannya. Bidang output
weightmencatat probabilitas bahwa setiap individu adalah penipu.
Dataset
Pipeline menggunakan dataset hubungan dengan bidang-bidang berikut.
| Field | Type | Description |
|---|---|---|
start_point | STRING | Vertex awal suatu edge. Nama seseorang. |
end_point | STRING | Vertex akhir suatu edge. Nama seseorang. |
count | DOUBLE | Kedekatan antara dua orang. Nilai yang lebih tinggi menunjukkan hubungan yang lebih dekat. |
Gambar berikut menunjukkan data sampel yang digunakan dalam pipeline. 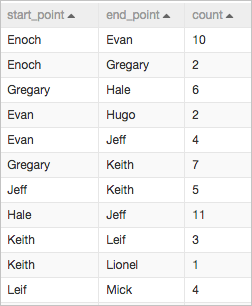
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Ruang kerja PAI. Untuk instruksi penyiapan, lihat dokumentasi PAI.
Akses ke Konsol PAI dengan izin untuk menggunakan Designer.
Buat dan jalankan pipeline
Langkah 1: Buka Designer
Masuk ke PAI console.
Di panel navigasi sebelah kiri, klik Workspaces. Pada halaman Workspaces, klik nama ruang kerja Anda.
Di panel navigasi sebelah kiri, pilih Model Training > Visualized Modeling (Designer).
Langkah 2: Buat pipeline dari templat
Pada halaman Visualized Modeling (Designer), klik tab Preset Templates.
Temukan templat Financial Risk Management dan klik Create.
Pada kotak dialog Create Pipeline, tinjau parameter-parameter tersebut. Parameter Data Storage menetapkan path bucket Object Storage Service (OSS) tempat pipeline menyimpan data sementara dan model selama waktu proses. Nilai default sudah sesuai untuk tutorial ini.
Klik OK. Pembuatan pipeline memerlukan waktu sekitar 10 detik.
Pada tab Pipelines, klik ganda pipeline Financial Risk Management untuk membukanya di Kanvas.
Kanvas menampilkan pipeline dengan tiga bagian. ![]()
| Section | Components | Purpose |
|---|---|---|
| ① | Maximum Connected Subgraph → SQL Script → JOIN | Mengklasifikasikan individu ke dalam dua kelompok dan memberikan ID pada masing-masing kelompok. Lalu menghapus individu yang tidak terkait dengan memilih himpunan yang memiliki jumlah terbesar individu yang saling terhubung. |
| ② | Single-Source Shortest Path | Menghitung jumlah individu yang harus dihubungi Enoch untuk mencapai target. Bidang distance dalam output mencatat nilai ini. |
| ③ | Data Source → Label Propagation Classification → SQL Script | Mengimpor data berlabel (di mana weight = probabilitas penipuan), menyebarkan label penipuan dari pelaku penipuan yang diketahui melalui jaringan ke vertex yang berdekatan, dan memfilter hasilnya untuk menampilkan probabilitas penipuan setiap individu. |
Langkah 3: Jalankan pipeline dan lihat hasilnya
Di pojok kiri atas Kanvas, klik
 untuk menjalankan pipeline.
untuk menjalankan pipeline.Setelah eksekusi selesai, klik kanan SQL di Kanvas dan pilih View Data.
Tabel output menampilkan probabilitas setiap individu sebagai penipu.
Mengapa algoritma graf mendeteksi penipuan yang tidak terdeteksi oleh sistem berbasis aturan
Gambar berikut menunjukkan contoh graf hubungan. Panah merepresentasikan hubungan seperti rekan kerja atau saudara. Dalam graf ini, Enoch adalah pelanggan tepercaya dan Evan adalah penipu. 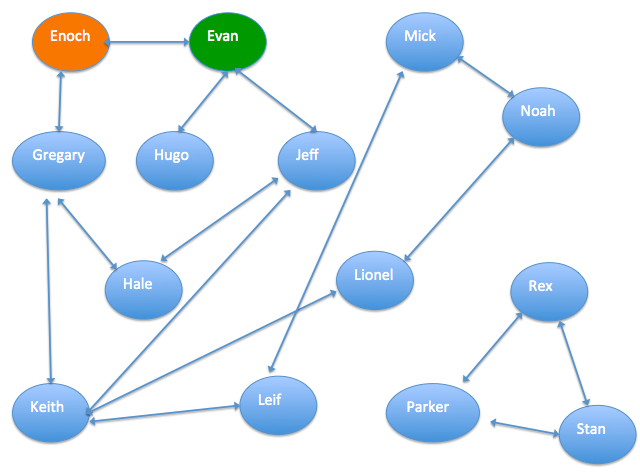
Machine Learning Platform for AI (PAI) menyediakan beberapa komponen algoritma graf untuk analisis hubungan, termasuk K-Core, Maximum Connected Subgraph, dan Label Propagation Classification. Komponen-komponen ini menganalisis struktur hubungan untuk mengungkap sinyal risiko yang tidak terdeteksi oleh model tingkat individu.
Cara kerja label propagation: Label Propagation Classification adalah algoritma klasifikasi semi-supervised. Algoritma ini menggunakan graf hubungan dan data berlabel sebagai input, lalu memprediksi label vertex yang tidak berlabel berdasarkan label vertex yang telah berlabel. Propagasi label menyebarkan label setiap vertex ke vertex yang berdekatan dengannya.