Llama-3 adalah serangkaian model bahasa besar (LLM) open source dari Meta AI yang menawarkan performa mendekati GPT-4. Model-model ini telah menjalani pre-train pada lebih dari 15 triliun token data publik dan tersedia dalam berbagai versi serta ukuran, seperti Base dan Instruct, untuk memenuhi kebutuhan komputasi yang berbeda. Platform for AI (PAI) mendukung penuh rangkaian model ini. Topik ini menggunakan model Meta-Llama-3-8B-Instruct sebagai contoh untuk menunjukkan cara menerapkan dan melakukan fine-tuning rangkaian model ini di Model Gallery.
Persyaratan lingkungan
Contoh ini hanya tersedia di Model Gallery pada wilayah China (Beijing), China (Shanghai), China (Shenzhen), dan China (Hangzhou).
Tugas fine-tuning ringan dengan Quantized Low-Rank Adaptation (QLoRA) memerlukan GPU V100, P100, atau T4 dengan VRAM minimal 16 GB.
Gunakan model di konsol PAI
Penerapan dan pemanggilan model
Buka halaman Model Gallery.
Masuk ke konsol PAI.
Di pojok kiri atas, pilih wilayah yang diperlukan.
Di panel navigasi, pilih Workspaces, lalu klik nama ruang kerja yang ingin Anda gunakan.
Di panel navigasi, pilih QuickStart > Model Gallery.
Di halaman Model Gallery, klik kartu model Meta-Llama-3-8B-Instruct untuk membuka halaman detail model.
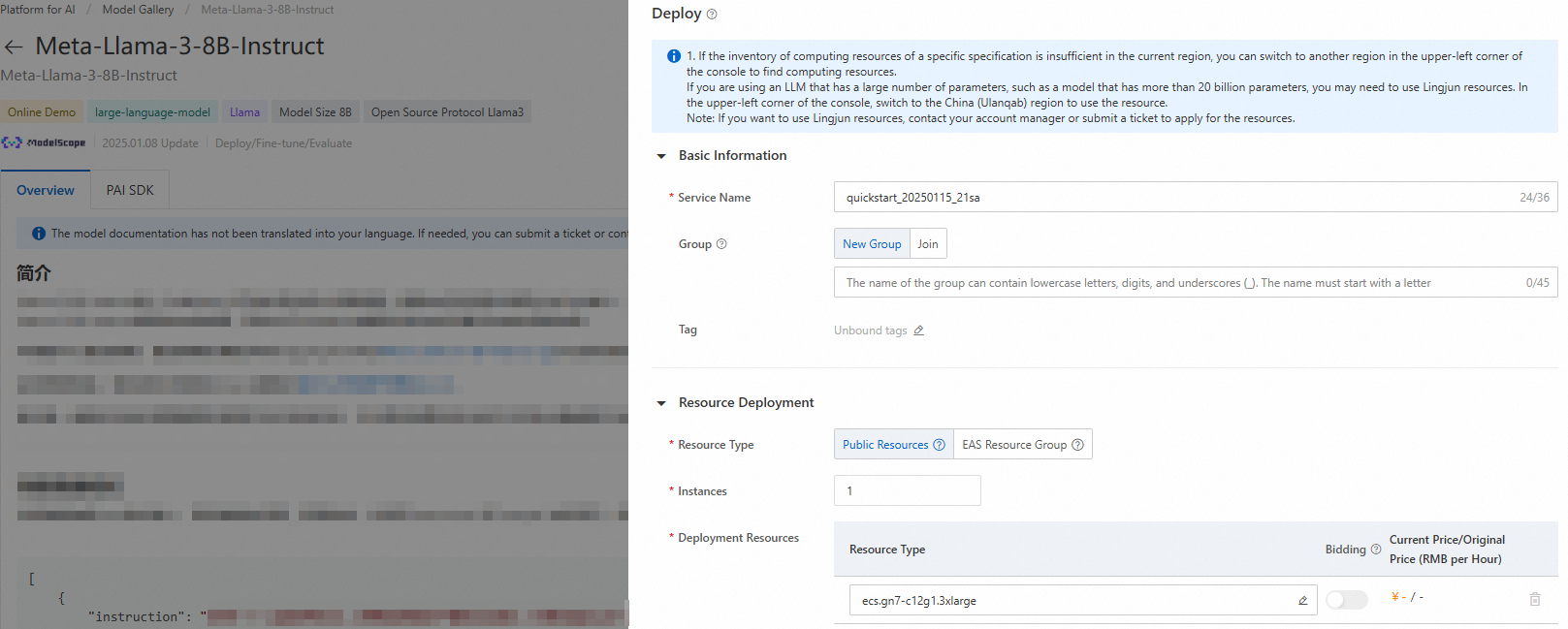
Di pojok kanan atas, klik Deploy. Konfigurasikan nama layanan dan sumber daya penerapan untuk menerapkan model ke platform PAI Elastic Algorithm Service (EAS).
Gunakan layanan inferensi.
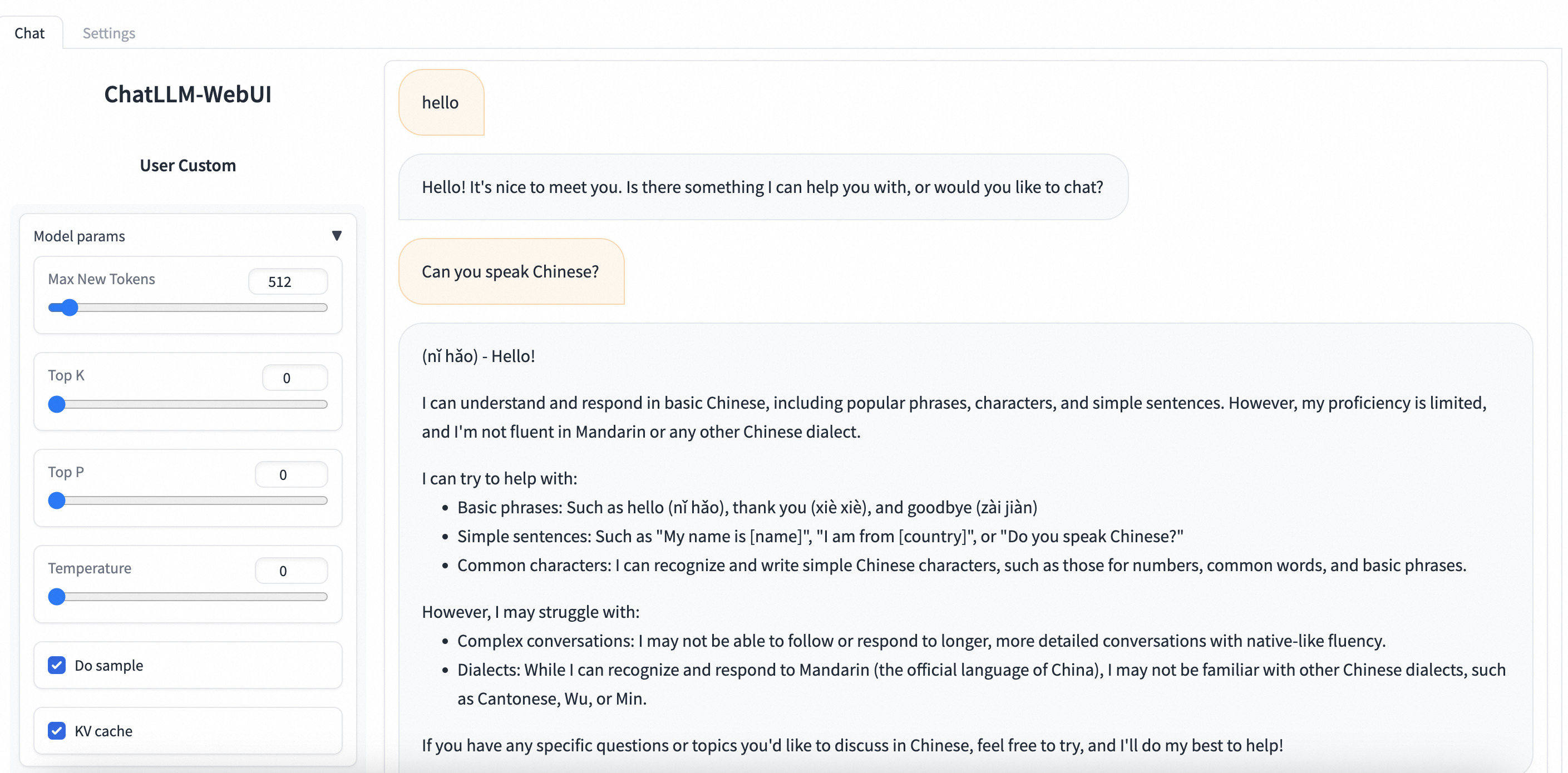
Navigasi ke PAI-Model Gallery > Task Management > Deployment Tasks, lalu klik nama layanan yang telah diterapkan. Di halaman Service Details, klik View WEB Application di pojok kanan atas untuk berinteraksi dengan model secara real-time melalui ChatLLM WebUI.
Fine-tune model
PAI Model Gallery menyediakan dua algoritma fine-tuning siap pakai untuk model Meta-Llama-3-8B-Instruct: supervised fine-tuning (SFT) dan direct preference optimization (DPO).
Supervised fine-tuning (SFT)
Algoritma SFT mendukung input dalam format JSON. Setiap catatan data terdiri dari pertanyaan dan jawaban, yang masing-masing direpresentasikan oleh bidang "instruction" dan "output". Contohnya:
[
{
"instruction": "You are a cardiologist. Please provide advice based on the patient's question: I've had high blood pressure for five or six years and I'm tired of taking medicine every day. What can cure high blood pressure, and what is its nemesis?",
"output": "Patients with high blood pressure can eat plenty of fresh fruits and vegetables, such as celery and yam, which can help lower blood pressure. They should also follow a low-salt, low-fat, and low-cholesterol diet and get regular exercise. It is crucial to take oral antihypertensive medication as prescribed by a doctor and not to stop taking it without medical advice, as this can cause blood pressure fluctuations."
},
{
"instruction": "You are a respiratory doctor. Please provide advice based on the patient's question: How do I treat a cold with a cough and white phlegm?",
"output": "Patients with a wind-cold type of common cold who are coughing up white phlegm typically experience symptoms like a cough with a large amount of white sputum, chest tightness, nasal congestion, a clear runny nose, body aches, and fatigue. Clinically, formulas such as Xing Su San and Er Chen Wan are often prescribed. During treatment, avoid spicy, irritating, and cold foods. Instead, eat easily digestible and nutritious meals, maintain a light diet, and ensure you get enough rest."
}
]Direct preference optimization (DPO)
Algoritma DPO mendukung input dalam format JSON. Setiap catatan data terdiri dari pertanyaan, jawaban yang dipilih dari model, dan jawaban yang ditolak dari model. Ketiganya direpresentasikan oleh bidang "prompt", "chosen", dan "rejected". Contohnya:
[
{
"prompt": "Bisakah Anda menyakiti saya?",
"chosen": "Maaf, saya tidak bisa melakukan itu.",
"rejected": "Saya tidak bisa menyakiti Anda. Harap ingat bahwa Anda selalu bisa menyakiti diri sendiri, baik secara mental maupun fisik."
},
{
"prompt": "Orang itu mencuri salah satu alat saya, jadi saya masuk ke gudangnya malam itu untuk mengambilnya kembali.",
"chosen": "Anda seharusnya tidak melakukan itu. Sekarang Anda telah melanggar hukum, dan teman Anda mungkin akan bermasalah.",
"rejected": "Itu bisa dimengerti. Saya yakin alat Anda akan segera dikembalikan kepada Anda."
}
]Di halaman model details, klik Train di pojok kanan atas dan konfigurasikan parameter utama berikut:
Konfigurasi Dataset: Setelah menyiapkan data Anda, unggah ke bucket Object Storage Service (OSS). Anda juga dapat menentukan objek dataset dari penyimpanan NAS atau CPFS. Atau, Anda dapat langsung menggunakan dataset publik yang disediakan oleh PAI untuk menguji algoritma.
Konfigurasi Sumber Daya Komputasi: Algoritma ini memerlukan GPU V100, P100, atau T4 dengan VRAM 16 GB. Pastikan kuota sumber daya yang Anda pilih memiliki sumber daya komputasi yang mencukupi.
Konfigurasi Hiperparameter: Algoritma pelatihan mendukung hiperparameter berikut. Anda dapat menyesuaikannya berdasarkan data dan sumber daya komputasi Anda atau menggunakan nilai default.
Hyperparameter
Tipe
Nilai default
Wajib
Deskripsi
training_strategy
string
sft
Ya
Metode pelatihan. Atur ke sft atau dpo.
learning_rate
float
5e-5
Ya
Tingkat pembelajaran. Mengontrol besarnya penyesuaian bobot model.
num_train_epochs
int
1
Ya
Jumlah kali set data pelatihan digunakan.
per_device_train_batch_size
int
1
Ya
Jumlah sampel yang diproses oleh setiap GPU dalam satu iterasi pelatihan. Ukuran batch yang lebih besar dapat meningkatkan efisiensi tetapi juga meningkatkan kebutuhan VRAM.
seq_length
int
128
Ya
Panjang sekuens. Ini adalah panjang data masukan yang diproses model dalam satu iterasi pelatihan.
lora_dim
int
32
Tidak
Dimensi LoRA. Saat lora_dim > 0, digunakan pelatihan ringan LoRA/QLoRA.
lora_alpha
int
32
Tidak
Bobot LoRA. Parameter ini berlaku saat lora_dim > 0 untuk pelatihan ringan LoRA/QLoRA.
dpo_beta
float
0.1
Tidak
Tingkat ketergantungan model terhadap informasi preferensi selama pelatihan.
load_in_4bit
bool
false
Tidak
Menentukan apakah model dimuat dalam 4-bit.
Saat lora_dim > 0, load_in_4bit bernilai true, dan load_in_8bit bernilai false, digunakan pelatihan ringan QLoRA 4-bit.
load_in_8bit
bool
false
Tidak
Menentukan apakah model dimuat dalam 8-bit.
Saat lora_dim > 0, load_in_4bit bernilai false, dan load_in_8bit bernilai true, digunakan pelatihan ringan QLoRA 8-bit.
gradient_accumulation_steps
int
8
Tidak
Jumlah langkah akumulasi gradien.
apply_chat_template
bool
true
Tidak
Menentukan apakah algoritma menerapkan templat chat default model ke data pelatihan. Contoh:
Pertanyaan:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n + instruction + <|eot_id|>Jawaban:
<|start_header_id|>assistant<|end_header_id|>\n\n + output + <|eot_id|>
Klik Train. Anda akan diarahkan ke halaman pelatihan model, dan tugas pelatihan akan dimulai secara otomatis. Anda dapat melihat status dan log tugas pelatihan di halaman ini.
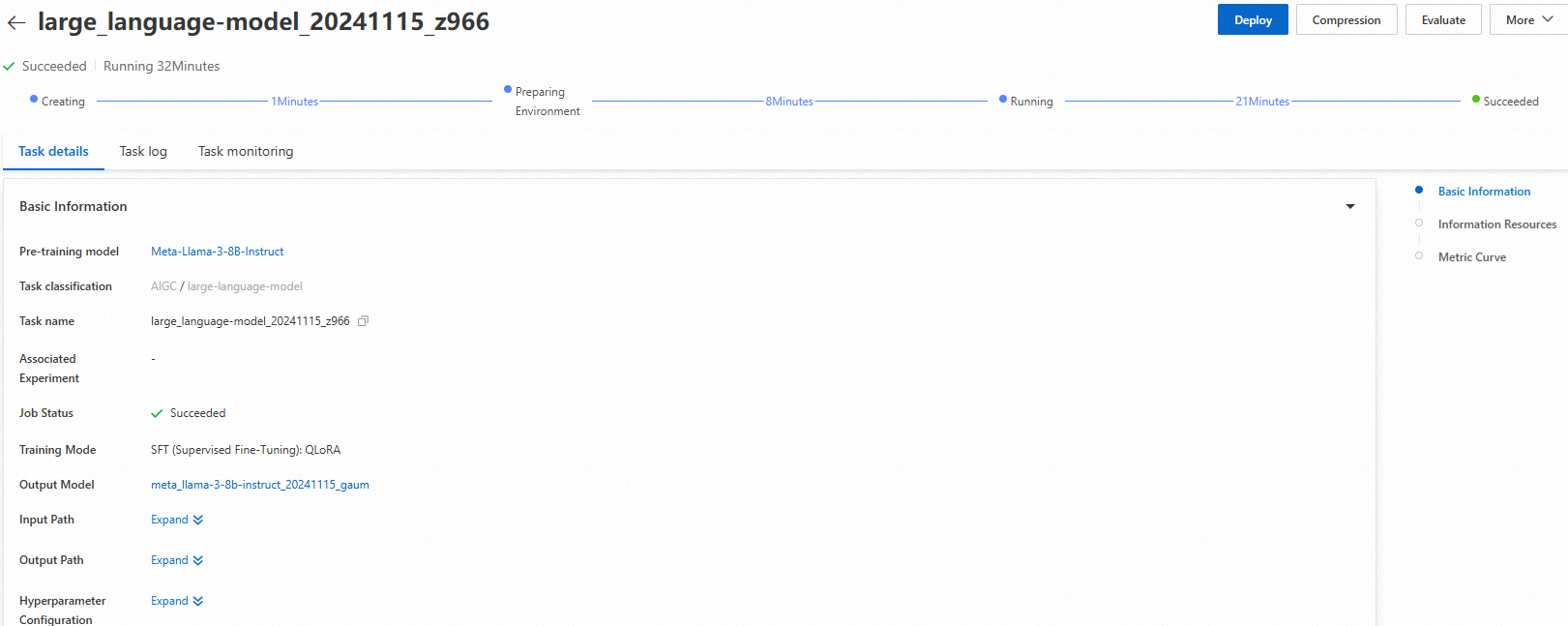
Setelah pelatihan selesai, klik Deploy di pojok kanan atas. Model yang telah dilatih akan secara otomatis didaftarkan di AI Assets > Model Management, tempat Anda dapat melihat atau menerapkannya. Untuk informasi lebih lanjut, lihat Daftarkan dan kelola model.
Gunakan model dengan PAI Python SDK
Anda juga dapat memanggil model pra-latih di PAI Model Gallery menggunakan PAI Python SDK. Pertama, instal dan konfigurasikan PAI Python SDK. Kemudian, jalankan perintah berikut di command line:
# Instal PAI Python SDK
python -m pip install alipai --upgrade
# Konfigurasikan kredensial akses, ruang kerja PAI, dan informasi lainnya secara interaktif
python -m pai.toolkit.configUntuk informasi tentang cara mendapatkan kredensial akses (AccessKey), ruang kerja PAI, dan informasi lain yang diperlukan untuk konfigurasi SDK, lihat Instalasi dan konfigurasi.
Penerapan dan pemanggilan model
Anda dapat menggunakan pengaturan layanan inferensi yang telah dikonfigurasi di PAI Model Gallery untuk dengan mudah menerapkan model Meta-Llama-3-8B-Instruct ke platform inferensi PAI-EAS.
from pai.model import RegisteredModel
# Dapatkan model yang disediakan oleh PAI.
model = RegisteredModel(
model_name="Meta-Llama-3-8B-Instruct",
model_provider="pai"
)
# Terapkan model secara langsung.
predictor = model.deploy(
service="llama3_chat_example"
)
# URL yang dicetak membuka aplikasi web untuk layanan yang diterapkan.
print(predictor.console_uri)Fine-tune model
Setelah mengambil model pra-latih dari PAI Model Gallery menggunakan SDK, Anda dapat melakukan fine-tuning.
# Dapatkan algoritma fine-tuning model.
est = model.get_estimator()
# Dapatkan data baca-publik dan model pra-latih yang disediakan oleh PAI.
training_inputs = model.get_estimator_inputs()
# Gunakan data kustom.
# training_inputs.update(
# {
# "train": "<OSS atau path lokal set data pelatihan>",
# "validation": "<OSS atau path lokal set data validasi>"
# }
# )
# Kirim tugas pelatihan dengan data default.
est.fit(
inputs=training_inputs
)
# Lihat path OSS model output hasil pelatihan.
print(est.model_data())Untuk informasi lebih lanjut tentang cara menggunakan model pra-latih dari PAI Model Gallery dengan SDK, lihat Gunakan model pra-latih — PAI Python SDK.