Fungsi agregat yang didefinisikan pengguna (UDAF) mengurangi beberapa baris input menjadi satu nilai output—mirip dengan fungsi bawaan seperti SUM atau AVG, tetapi menggunakan logika kustom yang Anda definisikan dalam Java.
Cara kerja
MaxCompute memproses UDAF dalam pipeline terdistribusi melalui tiga fase:
| Fase | Metode yang dipanggil | Apa yang terjadi |
|---|---|---|
| Map (iterate) | iterate() | Setiap worker membaca partisi data masukannya dan memanggil iterate() sekali per baris, mengakumulasi hasil ke dalam buffer lokal. |
| Combine/shuffle (merge) | merge() | Worker saling bertukar buffer parsial. merge() menggabungkan buffer parsial dari satu worker ke buffer utama, mengkonsolidasikan hasil dari berbagai tugas map. |
| Reduce (terminate) | terminate() | Setelah semua buffer digabung, terminate() mengekstraksi nilai output akhir dari buffer. |
Karena data berpindah antar worker terdistribusi, buffer agregasi harus dapat diserialisasi. Implementasikan antarmuka Writable untuk mengonversi objek dalam memori menjadi urutan byte guna transmisi jaringan dan penyimpanan disk.
Struktur kode UDAF
UDAF Java terdiri dari komponen-komponen berikut:
| Komponen | Wajib | Deskripsi |
|---|---|---|
| Paket Java | Tidak | Mengemas kelas Anda ke dalam file JAR |
| Kelas dasar | Ya | com.aliyun.odps.udf.Aggregator dan com.aliyun.odps.udf.annotation.Resolve |
com.aliyun.odps.udf.UDFException | Tidak | Digunakan dalam metode inisialisasi dan terminasi |
@Resolve annotation | Ya | Mendeklarasikan tipe data input dan output |
| Kelas Java kustom | Ya | Memperluas Aggregator; mendefinisikan buffer dan logika Anda |
Metode wajib
Perluas com.aliyun.odps.udf.Aggregator dan implementasikan metode-metode berikut:
import com.aliyun.odps.udf.ContextFunction;
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDFException;
public abstract class Aggregator implements ContextFunction {
// Dipanggil sekali sebelum pemrosesan dimulai. Gunakan untuk inisialisasi.
@Override
public void setup(ExecutionContext ctx) throws UDFException {}
// Dipanggil sekali setelah pemrosesan selesai. Gunakan untuk pembersihan.
@Override
public void close() throws UDFException {}
// Membuat buffer agregasi baru yang kosong untuk setiap kelompok.
abstract public Writable newBuffer();
// Fase Map: dipanggil sekali per baris input. Akumulasikan data ke dalam buffer.
// args tidak boleh null, tetapi nilai individual dalam args bisa null (menunjukkan input SQL NULL).
abstract public void iterate(Writable buffer, Writable[] args) throws UDFException;
// Fase Combine/reduce: menggabungkan buffer parsial (partial) ke dalam buffer utama.
abstract public void merge(Writable buffer, Writable partial) throws UDFException;
// Fase Reduce: mengekstraksi nilai output akhir dari buffer yang telah digabung sepenuhnya.
abstract public Writable terminate(Writable buffer) throws UDFException;
}Metode wajib vs opsional:
| Metode | Wajib | Kapan dijalankan |
|---|---|---|
newBuffer() | Selalu | Sebelum memproses setiap kelompok |
iterate() | Selalu | Fase Map — sekali per baris input |
merge() | Selalu | Fase Combine/shuffle — menggabungkan buffer parsial dari worker berbeda |
terminate() | Selalu | Fase Reduce — menghasilkan output akhir |
setup() | Hanya jika Anda memerlukan inisialisasi | Sebelum tugas dimulai |
close() | Hanya jika Anda memerlukan pembersihan | Setelah tugas selesai |
iterate()danmerge()berbagi instance buffer yang sama dalam satu kelompok. Rancang buffer Anda agar dapat mengakumulasi data dari keduanya tanpa konflik.
Buffer agregasi
Buffer agregasi menyimpan hasil antara saat data mengalir melalui pipeline terdistribusi. Implementasikan antarmuka Writable agar dapat diserialisasi:
import com.aliyun.odps.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
private static class MyBuffer implements Writable {
// Menyerialisasi field buffer ke aliran byte untuk transmisi jaringan.
@Override
public void write(DataOutput out) throws IOException {
// Tulis setiap field dalam urutan tetap.
}
// Mendeserialisasi field kembali dari aliran byte.
@Override
public void readFields(DataInput in) throws IOException {
// Baca setiap field dalam urutan yang sama seperti write().
}
}Baca dan tulis field dalam urutan yang sama. Ketidaksesuaian antara write() dan readFields() menyebabkan korupsi data diam-diam yang sulit didebug.
@Resolve annotation
Deklarasikan tipe input dan tipe kembalian menggunakan anotasi @Resolve. MaxCompute memeriksa konsistensi tipe selama penguraian semantik—ketidaksesuaian akan mengembalikan error sebelum pekerjaan dijalankan.
Format:
@Resolve('<arg_type_list> -> <return_type>')| Bagian | Deskripsi |
|---|---|
arg_type_list | Daftar tipe input yang dipisahkan koma. Atur ke * untuk menerima jumlah argumen apa pun, atau biarkan kosong untuk tidak menerima argumen. |
return_type | Satu tipe kembalian. UDAF selalu mengembalikan satu kolom. |
Tipe yang didukung meliputi: BIGINT, STRING, DOUBLE, BOOLEAN, DATETIME, DECIMAL, FLOAT, BINARY, DATE, DECIMAL(presisi,skala), CHAR, VARCHAR, ARRAY, MAP, STRUCT, dan tipe kompleks bersarang.
Pilih tipe data berdasarkan edisi tipe data proyek MaxCompute Anda. Untuk detailnya, lihat Edisi tipe data.
Contoh:
| Anotasi | Tipe input | Tipe kembalian |
|---|---|---|
@Resolve('bigint,double->string') | BIGINT atau DOUBLE | STRING |
@Resolve('*->string') | Apa saja | STRING |
@Resolve('->double') | Tidak ada | DOUBLE |
@Resolve('array<bigint>->struct<x:string, y:int>') | ARRAY\<BIGINT\> | STRUCT\<x:STRING, y:INT\> |
Tipe data
Tulis UDAF menggunakan tipe objek Java atau tipe Writable Java. Huruf pertama nama tipe Java harus kapital (misalnya, String, bukan string). Jangan gunakan tipe primitif—tipe tersebut tidak dapat merepresentasikan nilai SQL NULL, yang dipetakan MaxCompute ke null Java.
Tipe Writable Java sebagai tipe input atau kembalian memerlukan edisi tipe data MaxCompute V2.0 atau lebih baru.
| Tipe MaxCompute | Tipe Java | Tipe Writable Java |
|---|---|---|
| TINYINT | java.lang.Byte | ByteWritable |
| SMALLINT | java.lang.Short | ShortWritable |
| INT | java.lang.Integer | IntWritable |
| BIGINT | java.lang.Long | LongWritable |
| FLOAT | java.lang.Float | FloatWritable |
| DOUBLE | java.lang.Double | DoubleWritable |
| DECIMAL | java.math.BigDecimal | BigDecimalWritable |
| BOOLEAN | java.lang.Boolean | BooleanWritable |
| STRING | java.lang.String | Text |
| VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
| BINARY | com.aliyun.odps.data.Binary | BytesWritable |
| DATE | java.sql.Date | DateWritable |
| DATETIME | java.util.Date | DatetimeWritable |
| TIMESTAMP | java.sql.Timestamp | TimestampWritable |
| INTERVAL_YEAR_MONTH | N/A | IntervalYearMonthWritable |
| INTERVAL_DAY_TIME | N/A | IntervalDayTimeWritable |
| ARRAY | java.util.List | N/A |
| MAP | java.util.Map | N/A |
| STRUCT | com.aliyun.odps.data.Struct | N/A |
Menulis UDAF
Contoh 1: rata-rata (AggrAvg)
Contoh ini mengembangkan AggrAvg, sebuah UDAF yang menghitung rata-rata kolom DOUBLE, menggunakan MaxCompute Studio.
Buffer menyimpan dua field: jumlah berjalan dan jumlah baris. iterate() mengakumulasi setiap baris input selama fase map, merge() menggabungkan buffer parsial dari worker berbeda selama fase combine, dan terminate() membagi jumlah total dengan jumlah baris selama fase reduce.
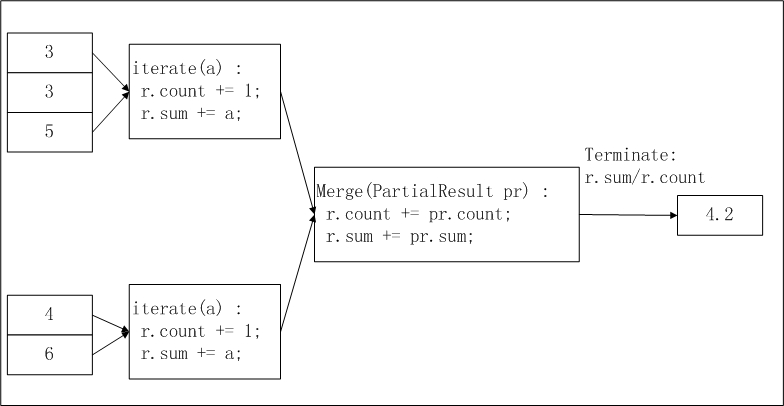
Data input diiris dan didistribusikan ke worker. Anda dapat mengonfigurasi parameter odps.stage.mapper.split.size untuk menyesuaikan ukuran setiap irisan. Setiap worker menghitung jumlah catatan dan total dalam irisannya (hasil antara), worker mengumpulkan informasi irisan, dan output akhir menghitung r.sum / r.count sebagai rata-rata.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Menginstal MaxCompute Studio. Lihat Instal MaxCompute Studio.
Menghubungkan MaxCompute Studio ke proyek. Lihat Hubungkan ke proyek MaxCompute.
Membuat modul Java MaxCompute. Lihat Buat modul Java MaxCompute.
Buat kelas UDAF
Pada tab Project, navigasi ke src > main > java, klik kanan java, lalu pilih New > MaxCompute Java.
Pada kotak dialog Create new MaxCompute java class, klik UDAF, masukkan nama kelas pada field Name, lalu tekan Enter. Contoh ini menggunakan
AggrAvg. Jika Anda belum membuat paket, tentukan field Name dalam formatpackagename.classname. Sistem akan menghasilkan paket secara otomatis.
Tulis kode UDAF di editor.
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import com.aliyun.odps.io.Text; import com.aliyun.odps.io.Writable; import com.aliyun.odps.udf.Aggregator; import com.aliyun.odps.udf.UDFException; import com.aliyun.odps.udf.annotation.Resolve; // Masukan: kolom STRING, pemisah STRING. Keluaran: STRING yang digabungkan. @Resolve("string,string->string") public class AggrConcat extends Aggregator { // Penyangga: teks yang terakumulasi dan pemisah yang digunakan di antara nilai-nilai. private static class ConcatBuffer implements Writable { private StringBuilder sb = new StringBuilder(); private String separator = ","; @Override public void write(DataOutput out) throws IOException { // Serialisasi StringBuilder sebagai String agar tetap utuh selama transfer jaringan. out.writeUTF(sb.toString()); out.writeUTF(separator); } @Override public void readFields(DataInput in) throws IOException { sb = new StringBuilder(in.readUTF()); separator = in.readUTF(); } } private Text ret = new Text(); @Override public Writable newBuffer() { return new ConcatBuffer(); } // Fase Map: tambahkan setiap nilai yang tidak bernilai null ke penyangga. @Override public void iterate(Writable buffer, Writable[] args) throws UDFException { Text value = (Text) args[0]; Text sep = (Text) args[1]; ConcatBuffer buf = (ConcatBuffer) buffer; if (value != null) { if (sep != null) { buf.separator = sep.toString(); } if (buf.sb.length() > 0) { buf.sb.append(buf.separator); } buf.sb.append(value.toString()); } } // Fase Combine: gabungkan penyangga parsial dari pekerja lain. @Override public void merge(Writable buffer, Writable partial) throws UDFException { ConcatBuffer buf = (ConcatBuffer) buffer; ConcatBuffer p = (ConcatBuffer) partial; if (p.sb.length() > 0) { if (buf.sb.length() > 0) { buf.sb.append(buf.separator); } buf.sb.append(p.sb); } } // Fase Reduce: kembalikan hasil penggabungan. @Override public Writable terminate(Writable buffer) throws UDFException { ConcatBuffer buf = (ConcatBuffer) buffer; ret.set(buf.sb.toString()); return ret; } }
Debug secara lokal
Jalankan UDAF di mesin lokal Anda untuk memverifikasi logika sebelum deployment. Untuk langkah debugging, lihat bagian "Perform a local run to debug the UDF" dalam Develop a UDF.
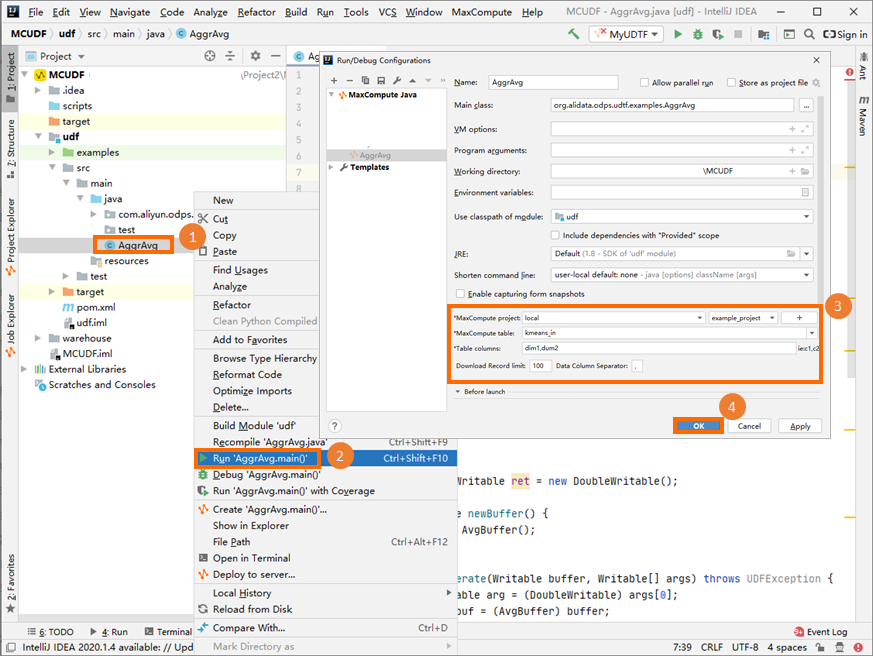
Pengaturan parameter pada gambar di atas hanya untuk referensi.
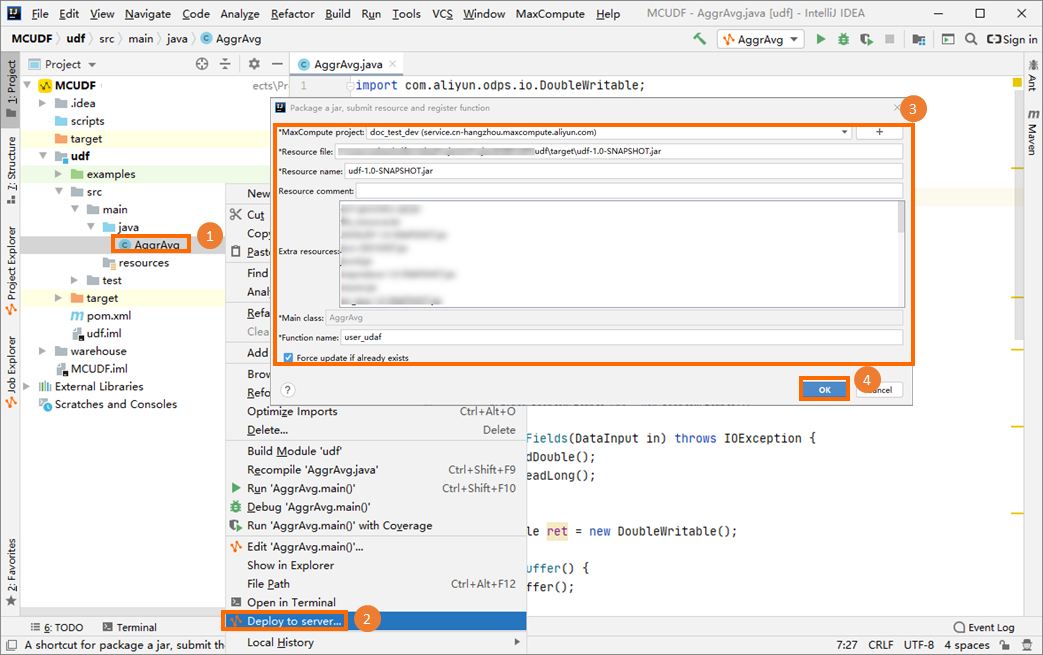
Paket dan daftarkan UDAF
Paket kode UDAF ke dalam file JAR, unggah ke proyek MaxCompute Anda, dan buat UDAF tersebut. Untuk langkah pengemasan, lihat bagian "Procedure" dalam Package a Java program, upload the package, and create a MaxCompute UDF.
Contoh ini mendaftarkan UDAF sebagai user_udaf.
Panggil UDAF
Pada Project Explorer, klik kanan proyek MaxCompute Anda untuk membuka klien MaxCompute, lalu jalankan pernyataan SQL untuk memanggil UDAF.
Diberikan tabel input berikut (my_table):
+------------+------------+
| col0 | col1 |
+------------+------------+
| 1.2 | 2.0 |
| 1.6 | 2.1 |
+------------+------------+Jalankan pernyataan berikut:
SELECT user_udaf(col0) AS c0 FROM my_table;Hasil:
+----+
| c0 |
+----+
| 1.4|
+----+Contoh 2: penggabungan string (AggrConcat)
AggrAvg menggunakan buffer numerik sederhana. Contoh ini menunjukkan pola yang lebih realistis: mengumpulkan nilai string dari beberapa baris dan menggabungkannya dengan pemisah.
Buffer menyimpan StringBuilder dan string pemisah. Karena StringBuilder tidak dapat diserialisasi secara langsung, buffer menyerialisasikannya sebagai String biasa. Ini adalah pola yang harus diikuti ketika buffer Anda menyimpan tipe non-primitif—serialisasi ke bentuk yang aman untuk transmisi dalam write() dan rekonstruksi bentuk dalam memori dalam readFields().
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
// Input: kolom STRING, pemisah STRING. Output: STRING yang digabungkan.
@Resolve("string,string->string")
public class AggrConcat extends Aggregator {
// Buffer: teks yang terakumulasi dan pemisah yang digunakan antar nilai.
private static class ConcatBuffer implements Writable {
private StringBuilder sb = new StringBuilder();
private String separator = ",";
@Override
public void write(DataOutput out) throws IOException {
// Serialisasi StringBuilder sebagai String agar bertahan dalam transfer jaringan.
out.writeUTF(sb.toString());
out.writeUTF(separator);
}
@Override
public void readFields(DataInput in) throws IOException {
sb = new StringBuilder(in.readUTF());
separator = in.readUTF();
}
}
private Text ret = new Text();
@Override
public Writable newBuffer() {
return new ConcatBuffer();
}
// Fase Map: tambahkan setiap nilai non-null ke dalam buffer.
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
Text value = (Text) args[0];
Text sep = (Text) args[1];
ConcatBuffer buf = (ConcatBuffer) buffer;
if (value != null) {
if (sep != null) {
buf.separator = sep.toString();
}
if (buf.sb.length() > 0) {
buf.sb.append(buf.separator);
}
buf.sb.append(value.toString());
}
}
// Fase Combine: gabungkan buffer parsial dari worker lain.
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
ConcatBuffer buf = (ConcatBuffer) buffer;
ConcatBuffer p = (ConcatBuffer) partial;
if (p.sb.length() > 0) {
if (buf.sb.length() > 0) {
buf.sb.append(buf.separator);
}
buf.sb.append(p.sb);
}
}
// Fase Reduce: kembalikan hasil penggabungan.
@Override
public Writable terminate(Writable buffer) throws UDFException {
ConcatBuffer buf = (ConcatBuffer) buffer;
ret.set(buf.sb.toString());
return ret;
}
}Keputusan desain utama:
| Keputusan | Penjelasan |
|---|---|
Serialisasi StringBuilder sebagai String | StringBuilder tidak dapat diserialisasi. Konversi ke String dalam write() dan bangun ulang dalam readFields(). |
Simpan separator dalam buffer | Pemisah diberikan sebagai argumen ke iterate() tetapi harus bertahan dalam serialisasi hingga merge(). Simpan dalam buffer. |
Lindungi dari buffer parsial kosong dalam merge() | Jika partisi worker tidak memiliki baris yang cocok, buffernya kosong. Periksa sebelum menambahkan untuk menghindari pemisah di awal. |
Urutan penggabungan string tidak dijamin antar worker karena penugasan partisi fase map ditentukan oleh mesin eksekusi, bukan oleh urutan baris. Jika urutan penting, gunakan klausa ORDER BY dalam pernyataan SQL Anda dan strategi single-reducer, atau urutkan output penggabungan setelahnya.Panggil UDAF dalam SQL
Setelah mengembangkan dan mendaftarkan UDAF Java, panggil dalam SQL MaxCompute. Untuk proses pengembangan lengkap, lihat bagian "Development process" dalam Ikhtisar.
Dua metode pemanggilan tersedia:
Dalam proyek: Panggil UDAF seperti fungsi bawaan.
Antar proyek: Panggil UDAF dari proyek B di dalam proyek A menggunakan sintaks di bawah. Untuk detail berbagi antar proyek, lihat Akses resource antar proyek berbasis paket.
SELECT B:udf_in_other_project(arg0, arg1) AS res FROM table_t;
Batasan
Akses Internet
Secara default, MaxCompute tidak mengizinkan UDAF mengakses Internet. Untuk mengaktifkan akses Internet, ajukan formulir permohonan koneksi jaringan sesuai kebutuhan bisnis Anda. Setelah disetujui, tim dukungan teknis MaxCompute akan membantu Anda membuat koneksi tersebut. Untuk petunjuk pengisian formulir, lihat Proses koneksi jaringan.
Akses VPC
Secara default, MaxCompute tidak mengizinkan UDAF mengakses resource di virtual private cloud (VPC). Untuk mengaktifkan akses VPC, buat koneksi jaringan antara MaxCompute dan VPC. Lihat Gunakan UDF untuk mengakses resource di VPC.
Batasan pembacaan tabel
UDF, UDAF, dan fungsi bernilai tabel yang didefinisikan pengguna (UDTF) tidak dapat membaca data dari jenis tabel berikut:
Tabel yang telah menjalani evolusi skema
Tabel yang berisi tipe data kompleks
Tabel yang berisi tipe data JSON
Tabel transaksional
Catatan penggunaan
Jangan memaketkan kelas dengan nama yang sama tetapi logika berbeda ke dalam file JAR untuk UDAF berbeda. Jika dua UDAF berbagi nama kelas (misalnya,
com.aliyun.UserFunction.class) di file JAR terpisah dan dipanggil dalam pernyataan SQL yang sama, MaxCompute akan memuat kelas dari salah satu file secara tidak terduga—menyebabkan hasil salah atau kegagalan kompilasi.Tipe data Java dalam UDAF adalah tipe objek. Huruf pertama harus kapital (misalnya,
String, bukanstring).Nilai NULL dalam SQL MaxCompute dipetakan ke
nulldalam Java. Jangan gunakan tipe primitif Java—tipe tersebut tidak dapat merepresentasikannull.
Lanjutan
Untuk menambahkan UDF yang lebih kompleks seperti fungsi bernilai tabel, lihat Ikhtisar.
Untuk mempelajari semua tipe data dan edisi yang didukung, lihat Edisi tipe data.