Hash clustering menyimpan data tabel berdasarkan distribusi hash dan pengurutan saat penulisan, sehingga MaxCompute dapat melewati operasi shuffle dan sort selama kueri. Hal ini mengurangi waktu CPU, durasi pekerjaan, dan konsumsi storage space untuk tabel besar dengan pola join atau agregasi yang berulang.
Kapan menggunakan hash clustering
Hash clustering paling efektif ketika tabel Anda memenuhi semua kondisi berikut:
Tabel berisi volume data yang besar.
Kueri sering melakukan filter, join, atau agregasi pada kolom yang sama.
Pola join atau agregasi yang sama dijalankan berulang kali terhadap tabel tersebut.
Tabel memiliki lifecycle yang panjang, sehingga penghematan storage space menjadi bernilai.
Jika kueri terhadap tabel menggunakan pola akses yang bervariasi dan tidak dapat diprediksi, manfaat hash clustering akan terbatas.
Cara kerja
Dalam banyak skenario, tabel perlu digabungkan (join). MaxCompute menyediakan metode join berikut:
Broadcast hash join: Jika salah satu tabel yang akan di-join merupakan tabel kecil, MaxCompute menyiarkan (broadcast) tabel kecil tersebut ke semua instans task join dan melakukan hash join antara tabel kecil dan tabel besar.
Shuffle hash join: Jika kedua tabel berukuran besar, MaxCompute melakukan hash shuffle pada kedua tabel berdasarkan kunci gabungan (join keys). Catatan (record) dengan nilai kunci yang sama didistribusikan ke instans task join yang sama, yang kemudian melakukan operasi join.
Sort merge join: Jika kedua tabel sangat besar (memori tidak cukup untuk membuat tabel hash), MaxCompute melakukan hash shuffle pada kedua tabel berdasarkan join keys, mengurutkan hasilnya, lalu menggabungkannya (merge). Dalam pekerjaan dengan M mapper dan R reducer, hal ini menghasilkan operasi I/O sebanyak M × R. Ini adalah metode join paling umum di MaxCompute.
Rencana eksekusi fisik pekerjaan Fuxi untuk sort merge join memerlukan dua tahap map dan satu tahap join. Operasi shuffle dan sort ditandai di bawah ini. 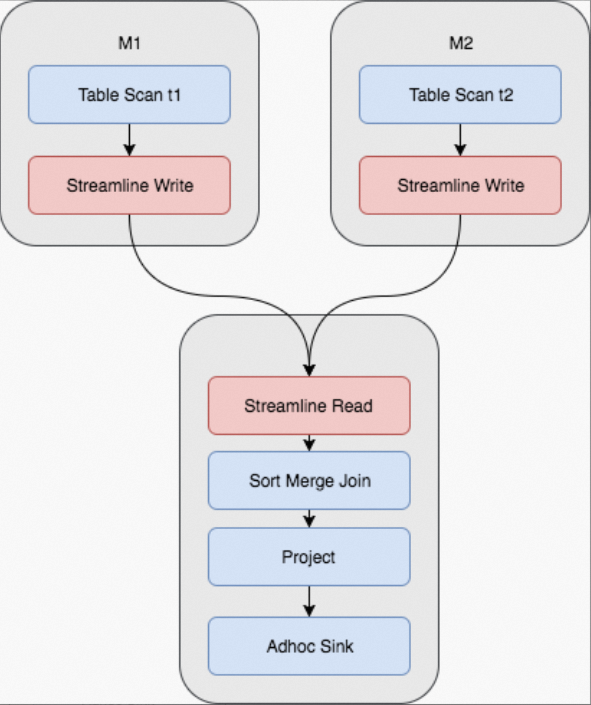
Dengan hash clustering, data didistribusikan ke dalam bucket berdasarkan nilai hash dan diurutkan di dalam setiap bucket saat penulisan. Kueri berikutnya yang melakukan join atau filter berdasarkan kunci kluster (cluster key) akan melewati seluruh proses shuffle dan sort, sehingga mengurangi pekerjaan Fuxi multi-tahap menjadi hanya satu tahap. 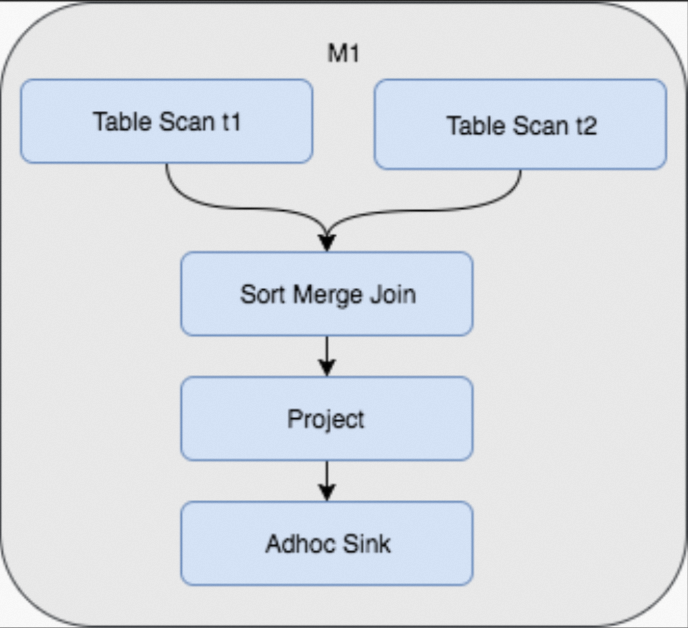
Tiga optimasi spesifik diterapkan:
Bucket pruning dan index lookup: Kueri dengan klausa WHERE pada cluster key hanya membaca bucket yang sesuai, bukan semua bucket. MaxCompute juga secara otomatis membuat indeks ketika SORTED BY ditetapkan, memungkinkan index lookup untuk menemukan catatan yang sesuai berdasarkan halaman. Sebagai contoh, kueri yang mencocokkan 26 catatan dari 42,7 miliar catatan dapat berkurang dari 1.111 mapper yang memindai seluruh data menjadi hanya 4 mapper yang memindai 10.000 catatan—mengurangi waktu proses dari 1 menit 48 detik menjadi 6 detik.
Optimasi agregasi: Kueri GROUP BY pada cluster key melewati shuffle dan sort. MaxCompute langsung melakukan stream aggregate pada data yang telah diurutkan sebelumnya.
Optimasi penyimpanan: MaxCompute menggunakan column store pada lapisan penyimpanan. Data yang diurutkan memiliki tingkat kompresi jauh lebih baik dibandingkan data yang tidak diurutkan karena catatan dengan nilai kunci yang mirip disimpan berdekatan. Dalam praktiknya, dataset yang sama dengan hash clustering menggunakan sekitar 10% lebih sedikit storage space; dalam kasus ekstrem, penghematan tersebut dapat mencapai 50%.
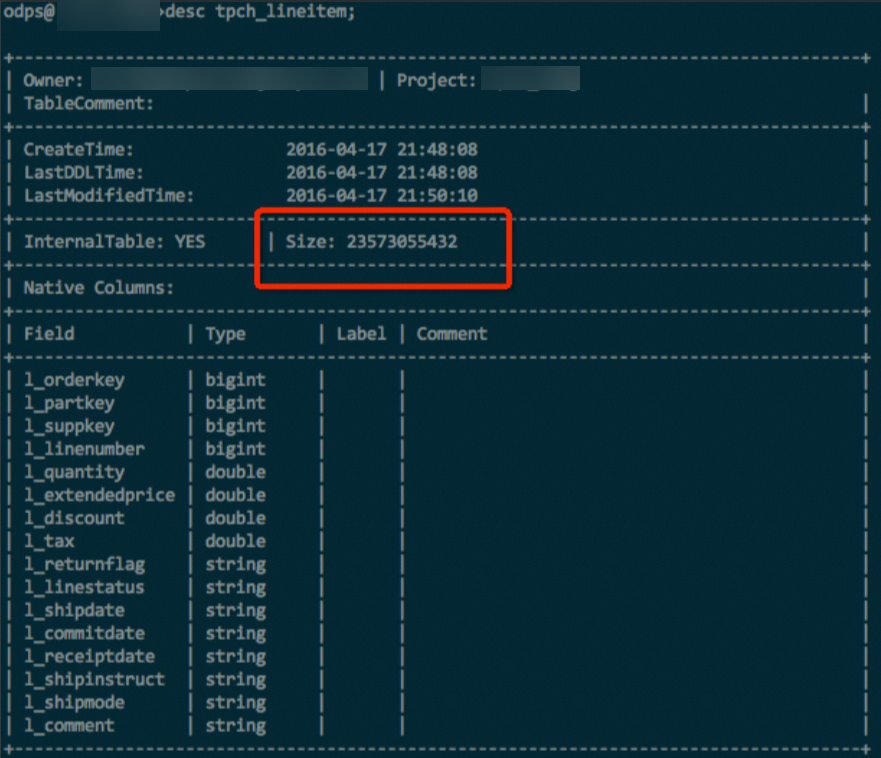
Hash clustering tidak digunakan.
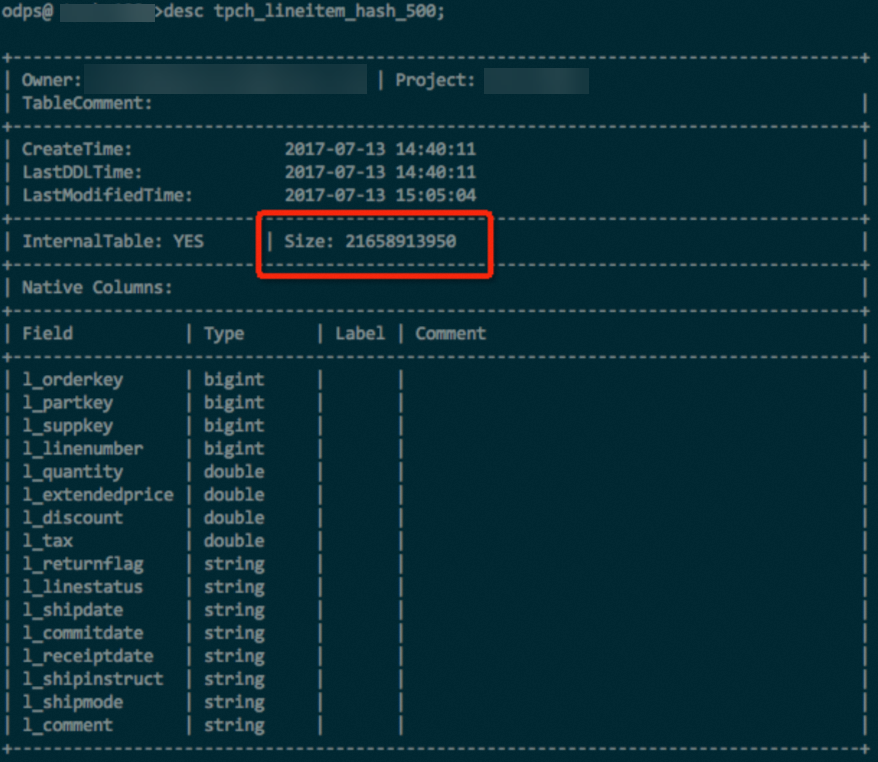
Hash clustering digunakan.
Hasil benchmark TPC-H: Pada data sebesar 1 TB yang tersebar di 500 bucket, hash clustering mengurangi total waktu CPU sekitar 17,3% dan total durasi pekerjaan sekitar 12,8%. Untuk kueri yang memanfaatkan clustering secara efektif—seperti TPC-H Q4, Q12, dan Q10—peningkatannya masing-masing mencapai 68%, 62%, dan 47%.
Gambar berikut menunjukkan rencana eksekusi pekerjaan Fuxi untuk kueri TPC-H Q4 pada tabel biasa. 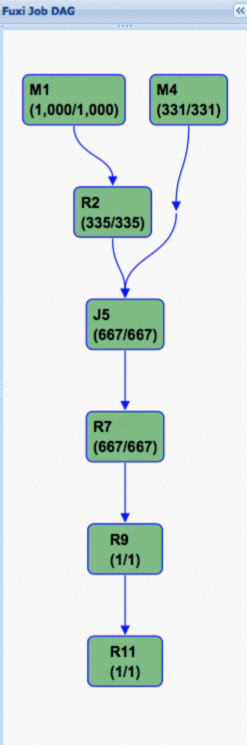 Gambar berikut menunjukkan rencana eksekusi setelah hash clustering diaktifkan. Grafik asiklik terarah (DAG) menjadi jauh lebih sederhana, yang merupakan kunci peningkatan performa.
Gambar berikut menunjukkan rencana eksekusi setelah hash clustering diaktifkan. Grafik asiklik terarah (DAG) menjadi jauh lebih sederhana, yang merupakan kunci peningkatan performa. 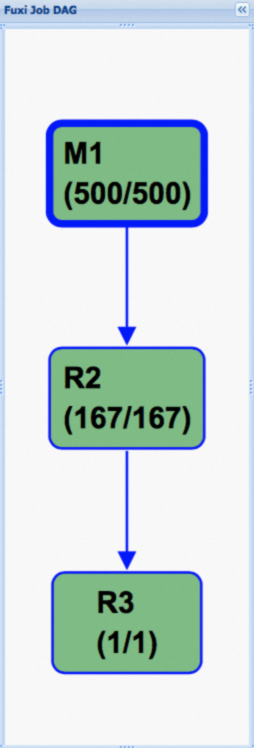
Membuat tabel hash-clustered
Sintaksis
CREATE TABLE [IF NOT EXISTS] <table_name>
[(<col_name> <data_type> [COMMENT <col_comment>], ...)]
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type> [COMMENT <col_comment>], ...)]
[CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS] [AS <select_statement>]Parameter
`CLUSTERED BY` (wajib)
Menentukan kunci kluster—kolom yang digunakan MaxCompute untuk melakukan hash dan mendistribusikan data ke dalam bucket. Untuk mencegah masalah kesenjangan data (data skew) dan hot spot serta meningkatkan efisiensi eksekusi konkuren, tentukan kolom dengan rentang nilai besar dan sedikit nilai duplikat. Untuk mengoptimalkan operasi join, pilih kunci join atau kunci agregasi yang umum digunakan.
`SORTED BY` (opsional)
Menentukan urutan pengurutan di dalam setiap bucket. Tetapkan ini ke kolom yang sama dengan CLUSTERED BY untuk mengaktifkan index lookup dan meningkatkan performa kueri untuk filter equality dan range. MaxCompute secara otomatis menghasilkan indeks ketika SORTED BY ditentukan.
`INTO <number_of_buckets> BUCKETS` (wajib)
Menentukan jumlah bucket. Tentukan jumlah ini berdasarkan volume data:
Targetkan ukuran bucket antara 500 MB hingga 1 GB.
Untuk tabel yang sangat besar, Anda dapat meningkatkan target ukuran bucket.
Tetapkan jumlah bucket sebagai pangkat dari 2 (misalnya, 512, 1.024, 2.048, atau 4.096) agar MaxCompute dapat secara otomatis membagi dan menggabungkan bucket.
Untuk optimasi join antara dua tabel, jumlah bucket pada satu tabel harus merupakan kelipatan dari jumlah bucket pada tabel lainnya (misalnya, 256 dan 512).
Contoh
Tabel non-partisi:
CREATE TABLE T1 (a string, b string, c bigint)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;Tabel partisi:
CREATE TABLE T1 (a string, b string, c bigint)
PARTITIONED BY (dt string)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;Memodifikasi properti clustering tabel
Untuk tabel partisi, gunakan ALTER TABLE untuk menambahkan atau menghapus properti hash clustering.
-- Menambahkan hash clustering ke tabel partisi yang sudah ada
ALTER TABLE <table_name> [CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS];
-- Menghapus hash clustering dari tabel partisi
ALTER TABLE <table_name> NOT CLUSTERED;Catatan penggunaan
ALTER TABLEhanya berlaku untuk tabel partisi. Properti clustering tabel non-partisi tidak dapat dimodifikasi setelah ditetapkan.ALTER TABLEhanya berlaku untuk partisi baru—termasuk partisi yang ditulis olehINSERT OVERWRITE. Partisi yang sudah ada tetap mempertahankan format penyimpanan aslinya.Anda tidak dapat menargetkan partisi tertentu dalam pernyataan
ALTER TABLE.
Memverifikasi properti hash clustering
Setelah membuat tabel hash-clustered, jalankan DESC EXTENDED untuk mengonfirmasi properti clustering. Cari konfigurasi hash clustering di bagian Extended Info pada output.
DESC EXTENDED <table_name>;Gambar berikut menunjukkan contoh hasil yang dikembalikan. 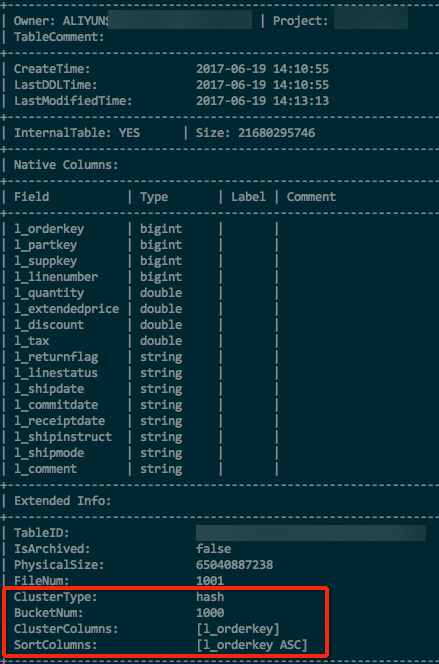
Untuk tabel partisi, periksa juga partisi tertentu:
DESC EXTENDED <table_name> PARTITION (<pt_spec>);Gambar berikut menunjukkan contoh hasil yang dikembalikan. 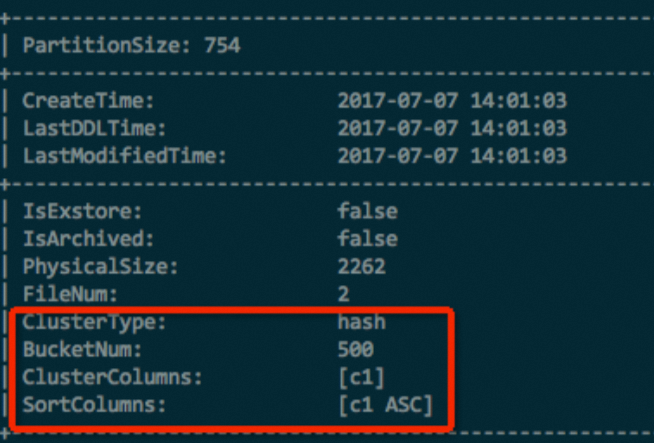
Detail optimasi penyimpanan
Eksperimen sederhana dilakukan menggunakan tabel lineitem dengan data sebesar 100 GB dari dataset TPC-H. Tabel tersebut berisi data berbagai tipe seperti INT, DOUBLE, dan STRING. Dengan data dan metode kompresi yang sama, tabel hash-clustered menghemat sekitar 10% storage space. Dalam beberapa kasus pengujian ekstrem, tabel yang diurutkan dapat menghemat hingga 50% storage space dibandingkan tabel yang tidak diurutkan.
Langkah selanjutnya
Partition tables — manage table partitions in MaxCompute
Optimize query performance — additional techniques for improving query efficiency