Topik ini menjawab pertanyaan yang sering diajukan (FAQ) tentang PyODPS.
Error saat instalasi: "Warning: XXX not installed"
Penyebab: Error ini menunjukkan bahwa komponen yang diperlukan tidak tersedia.
Solusi: Identifikasi nama komponen yang hilang dari placeholder XXX dalam pesan error dan instal komponen tersebut dengan menggunakan perintah pip.
Error saat instalasi: "Project Not Found"
Error ini terjadi karena salah satu alasan berikut:
Konfigurasi endpoint salah: Endpoint dikonfigurasi secara tidak benar. Gunakan endpoint untuk proyek tujuan. Untuk informasi selengkapnya tentang endpoint, lihat Endpoint.
Posisi parameter salah: Parameter untuk objek entri MaxCompute ditentukan pada posisi yang salah. Verifikasi bahwa parameter dimasukkan dengan benar. Untuk informasi selengkapnya tentang parameter objek entri MaxCompute, lihat Migrasikan node PyODPS dari DataWorks ke lingkungan on-premises.
Error saat instalasi: "Syntax Error"
Error ini terjadi karena versi Python terlalu lama. PyODPS memerlukan Python 2.6, 2.7.6 atau yang lebih baru, atau 3.3 atau yang lebih baru. Versi Python 2.5 dan sebelumnya tidak didukung.
Error instalasi pada macOS: "Permission Denied"
Jalankan perintah berikut untuk menginstal PyODPS: sudo pip install pyodps.
Error instalasi pada macOS: "Operation Not Permitted"
Error ini disebabkan oleh System Integrity Protection (SIP). Untuk memperbaikinya, mulai ulang perangkat Anda dan tekan ⌘+R saat startup untuk masuk ke Recovery Mode. Kemudian, buka Terminal dan jalankan perintah berikut.
csrutil disable
reboot Untuk informasi selengkapnya, lihat Operation Not Permitted when on root - El Capitan (rootless disabled).
Error impor: "No Module Named ODPS"
Error ini menunjukkan bahwa paket ODPS tidak dapat dimuat. Penyebab yang mungkin termasuk:
Penyebab 1: Konflik nama dalam path pencarian
Path pencarian, yang biasanya merupakan direktori saat ini, berisi file bernama
odps.pyatau__init__.py, atau direktori bernama odps. Hal ini bertentangan dengan paket PyODPS yang telah diinstal.
Solusi:Jika ada direktori dengan nama yang bertentangan, ubah namanya.
Jika sebelumnya Anda menginstal paket Python lain bernama odps, uninstal dengan menjalankan
sudo pip uninstall odps.
Penyebab 2: Beberapa versi Python diinstal
Anda mungkin menjalankan skrip dalam lingkungan Python tempat PyODPS belum diinstal.
Solusi: Pastikan Anda menggunakan interpreter Python yang benar tempat PyODPS diinstal, atau instal PyODPS untuk versi yang sedang Anda gunakan.Penyebab 3: PyODPS belum diinstal
Paket tersebut belum pernah diinstal di lingkungan Python saat ini.
Solusi: Instal PyODPS. Untuk informasi selengkapnya, lihat Instal PyODPS.
Error impor: "Cannot Import Name ODPS"
Periksa apakah file bernama odps.py ada di direktori kerja saat ini. Jika ada, ubah namanya sebelum menjalankan pernyataan impor lagi.
Error impor: "Cannot Import Module odps"
Error ini biasanya menunjukkan masalah dependensi pada instalasi PyODPS Anda. Klik tautan ini untuk bergabung dengan grup DingTalk dukungan teknis PyODPS dan hubungi administrator grup untuk bantuan.
"ImportError" di IPython atau Jupyter
Coba tambahkan from odps import errors di awal kode Anda. Jika masalah tetap berlanjut, kemungkinan disebabkan oleh dependensi IPython yang hilang. Jalankan sudo pip install -U jupyter untuk mengatasi masalah tersebut.
Atribut size
Atribut size merepresentasikan ukuran fisik tabel.
Bagaimana cara mengatur Tunnel endpoint?
Gunakan options.tunnel.endpoint untuk mengatur tunnel endpoint. Untuk informasi selengkapnya, lihat dokumentasi opsi aliyun-odps-python-sdk.
Gunakan paket pihak ketiga CPython
Kami menyarankan untuk mengemasnya dalam format Wheel. Untuk informasi selengkapnya, lihat Cara membuat paket crcmod yang dapat digunakan di MaxCompute.
Batas pemrosesan data DataFrame
Sebuah DataFrame PyODPS tidak memiliki batas pada data yang dapat diproses karena operasi diterjemahkan menjadi pekerjaan MaxCompute. Namun, DataFrame pandas lokal dibatasi oleh memori yang tersedia di mesin Anda.
Bagaimana cara menggunakan max_pt dalam DataFrame?
Gunakan modul odps.df.func untuk memanggil fungsi bawaan MaxCompute.
from odps.df import func
df = o.get_table('your_table').to_df()
df[df.ds == func.max_pt('your_project.your_table')] # ds adalah kolom partisi. Apa perbedaan antara open_writer() dan write_table()?
Setiap kali Anda memanggil write_table(), MaxCompute membuat file baru di server, yang memiliki overhead waktu signifikan. Membuat terlalu banyak file kecil juga dapat menurunkan performa kueri berikutnya dan dapat menyebabkan error kehabisan memori di server. Oleh karena itu, saat menggunakan metode write_table(), kami menyarankan untuk menulis beberapa batch data sekaligus atau meneruskan objek generator. Untuk contoh penggunaan metode write_table(), lihat Tulis data ke tabel.
Sebaliknya, open_writer() membuat sesi yang memungkinkan Anda menulis data dalam blok, yang lebih efisien untuk unggahan data streaming atau iteratif.
Ketidaksesuaian data antara DataWorks dan skrip lokal
Secara default, Instance Tunnel dinonaktifkan di DataWorks. Artinya, instance.open_reader menggunakan API Result, yang dibatasi hingga 10.000 catatan.
Setelah Anda mengaktifkan Instance Tunnel, Anda dapat menggunakan reader.count untuk mendapatkan jumlah total catatan. Untuk mengiterasi semua data, Anda harus menonaktifkan batasan tersebut dengan mengatur options.tunnel.limit_instance_tunnel = False.
Bagaimana cara mendapatkan jumlah sebenarnya dari DataFrame?
Setelah Anda menginstal PyODPS, jalankan perintah berikut di lingkungan Python Anda untuk membuat DataFrame dari tabel MaxCompute.
iris = DataFrame(o.get_table('pyodps_iris'))Panggil metode
count()pada DataFrame untuk mendapatkan jumlah total baris.iris.count()Operasi pada DataFrame dieksekusi secara lazy. Operasi tersebut tidak dijalankan hingga Anda secara eksplisit memanggil metode aksi seperti
execute(). Untuk memaksa operasicount()dijalankan segera, rantai dengan metodeexecute().df.count().execute()
Untuk informasi selengkapnya tentang metode yang mengembalikan nilai aktual, lihat Operasi agregasi. Untuk informasi selengkapnya tentang eksekusi lazy di PyODPS, lihat Eksekusi.
Error "sourceIP is not in the white list"
Error ini menunjukkan bahwa proyek MaxCompute yang Anda coba akses dilindungi oleh daftar putih IP. Hubungi pemilik proyek untuk menambahkan alamat IP mesin Anda ke daftar putih IP proyek tersebut. Untuk informasi selengkapnya, lihat Kelola daftar putih IP.
options.sql.settings gagal mengatur lingkungan
Gejala
Sebelum menjalankan kueri SQL dengan menggunakan PyODPS, Anda menggunakan kode berikut untuk mengonfigurasi lingkungan runtime MaxCompute.
from odps import options options.sql.settings = {'odps.sql.mapper.split.size': 32}Setelah menjalankan tugas, hanya enam mapper yang dimulai, yang menunjukkan bahwa pengaturan tersebut tidak berlaku. Saat Anda menjalankan
set odps.stage.mapper.split.size=32di client, tugas selesai dalam waktu satu menit.Penyebab
Nama parameter yang digunakan di PyODPS berbeda dengan yang digunakan di client. Parameter client adalah
odps.stage.mapper.split.size, sedangkan parameter PyODPS adalahodps.sql.mapper.split.size.Solusi
Ubah nama parameter dalam kode Anda menjadi
odps.stage.mapper.split.size.
"IndexError" saat memanggil head()
Karena list[index] tidak ada atau list[index] berada di luar rentang.
Error saat mengunggah pandas DataFrame ke MaxCompute: "ODPSError"
Gejala
Saat Anda mengunggah pandas DataFrame ke MaxCompute, error berikut dikembalikan.
ODPSError: ODPS entrance should be provided.Penyebab
Titik masuk objek entri MaxCompute global tidak tersedia.
Solusi
Gunakan mekanisme Room
%enter, yang mengonfigurasi titik masuk global.Panggil metode
to_global()pada titik masuk objek entri MaxCompute Anda.Teruskan objek ODPS langsung sebagai parameter:
DataFrame(pd_df).persist('your_table', odps=odps).
Error "lifecycle is not specified"
Gejala
Saat Anda menulis data ke tabel dengan menggunakan DataFrame, error berikut dikembalikan.
table lifecycle is not specified in mandatory modePenyebab
Proyek tujuan mengharuskan lifecycle ditentukan untuk semua tabel, tetapi Anda belum menentukannya.
Solusi
Tentukan lifecycle tabel dalam skrip Anda sebelum melakukan operasi penulisan.
from odps import options options.lifecycle = 7 # Tentukan nilai lifecycle. Nilainya adalah bilangan bulat dalam satuan hari.
Error "datastream from server is crushed"
Error ini biasanya disebabkan oleh data yang rusak. Verifikasi bahwa data Anda memiliki jumlah kolom yang sama dengan tabel tujuan.
Error "Project is protected"
Error ini menunjukkan bahwa kebijakan keamanan pada proyek mencegah Anda membaca data dari tabel tersebut. Untuk mengakses set data lengkap, Anda dapat menggunakan salah satu metode berikut:
Hubungi pemilik proyek untuk menambahkan aturan pengecualian untuk akses Anda.
Gunakan DataWorks atau tool lain untuk mendesensitisasi data, ekspor ke proyek yang tidak dilindungi, lalu baca dari sana.
Jika Anda hanya perlu melihat subset data, Anda dapat menggunakan salah satu metode berikut, yang mungkin dibatasi hingga 10.000 catatan:
Gunakan metode execute_sql:
o.execute_sql('select * from <table_name>').open_reader().Konversi tabel menjadi DataFrame:
o.get_table('<table_name>').to_df().
Kegagalan intermiten "ConnectionError: timed out"
Error ini dapat disebabkan oleh hal-hal berikut:
Timeout koneksi: Timeout koneksi default untuk PyODPS adalah 5 detik. Jika jaringan tidak stabil, koneksi dapat gagal. Anda dapat menggunakan salah satu solusi berikut:
Tingkatkan interval timeout dengan menambahkan kode berikut di awal skrip Anda.
# Solusi untuk meningkatkan timeout from odps import options options.connect_timeout = 30Implementasikan mekanisme retry dalam kode Anda untuk menangani exception tersebut.
Batasan sandbox: Lingkungan sandbox mungkin memiliki batasan akses jaringan. Untuk mengatasi hal ini, kami menyarankan agar Anda menggunakan kelompok sumber daya penjadwalan eksklusif untuk menjalankan tugas tersebut.
Error "is not defined" untuk get_sql_task_cost()
Gejala
Saat Anda menjalankan fungsi get_sql_task_cost, error berikut dikembalikan.
NameError: name 'get_task_cost' is not defined.Penyebab
Nama fungsi salah.
Solusi
Gunakan execute_sql_cost alih-alih get_sql_task_cost.
Bagaimana cara menampilkan karakter Tionghoa dengan benar dalam log PyODPS?
Anda dapat mengatasi hal ini dengan menggunakan string format print, misalnya, print ("My name is %s" % ('abc')). Masalah ini biasanya hanya terjadi di Python 2.
DATETIME menjadi STRING saat instance tunnel dinonaktifkan
Saat Open_Reader dipanggil, PyODPS secara default menggunakan antarmuka Result lama. Akibatnya, data yang dikembalikan dari server dalam format CSV, dan semua nilai DATETIME bertipe STRING.
Untuk mengatasi hal ini, aktifkan Instance Tunnel dengan mengatur options.tunnel.use_instance_tunnel = True. Hal ini membuat PyODPS menggunakan layanan Instance Tunnel, yang mempertahankan tipe data aslinya.
Implementasikan fitur lanjutan dengan Python
Tulis fungsi Python yang dapat digunakan kembali
Anda dapat mendefinisikan serangkaian fungsi untuk perhitungan umum, seperti menghitung jarak antara dua titik dengan menggunakan metode berbeda seperti jarak Euclidean atau Manhattan. Anda kemudian dapat memanggil fungsi yang sesuai sesuai kebutuhan.
def euclidean_distance(from_x, from_y, to_x, to_y): return ((from_x - to_x) ** 2 + (from_y - to_y) ** 2).sqrt() def manhattan_distance(from_x, from_y, to_x, to_y): return (from_x - to_x).abs() + (from_y - to_y).abs()Contoh pemanggilan:
In [42]: df from_x from_y to_x to_y 0 0.393094 0.427736 0.463035 0.105007 1 0.629571 0.364047 0.972390 0.081533 2 0.460626 0.530383 0.443177 0.706774 3 0.647776 0.192169 0.244621 0.447979 4 0.846044 0.153819 0.873813 0.257627 5 0.702269 0.363977 0.440960 0.639756 6 0.596976 0.978124 0.669283 0.936233 7 0.376831 0.461660 0.707208 0.216863 8 0.632239 0.519418 0.881574 0.972641 9 0.071466 0.294414 0.012949 0.368514 In [43]: euclidean_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.330221 1 0.444229 2 0.177253 3 0.477465 4 0.107458 5 0.379916 6 0.083565 7 0.411187 8 0.517280 9 0.094420 In [44]: manhattan_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.392670 1 0.625334 2 0.193841 3 0.658966 4 0.131577 5 0.537088 6 0.114198 7 0.575175 8 0.702558 9 0.132617Gunakan pernyataan kondisional dan loop Python
Jika Anda perlu memproses bidang tabel berdasarkan konfigurasi lalu melakukan operasi UNION atau JOIN di semua tabel, penggunaan SQL bisa menjadi kompleks. Namun, hal ini menjadi mudah dengan DataFrame PyODPS.
Misalnya, untuk menggabungkan 30 tabel menjadi satu tabel, Anda perlu menulis kueri SQL dengan 30 klausa UNION ALL. Dengan PyODPS, Anda dapat mencapai hasil yang sama dengan kode berikut.
table_names = ['table1', ..., 'tableN'] dfs = [o.get_table(tn).to_df() for tn in table_names] reduce(lambda x, y: x.union(y), dfs) # Pernyataan reduce setara dengan kode berikut. df = dfs[0] for other_df in dfs[1:]: df = df.union(other_df)
Bagaimana cara melakukan debug secara lokal dengan menggunakan backend pandas?
Anda dapat melakukan debug lokal dengan salah satu dari dua cara berikut. Metode inisialisasi berbeda, tetapi kode selanjutnya sama:
DataFrame PyODPS yang dibuat dari pandas DataFrame dapat melakukan komputasi lokal dengan menggunakan pandas.
DataFrame yang dibuat dari tabel MaxCompute berjalan di MaxCompute.
Kode contoh berikut menunjukkan cara beralih antara debug lokal dan eksekusi penuh di MaxCompute.
df = o.get_table('movielens_ratings').to_df()
DEBUG = True
if DEBUG:
# Gunakan subset data kecil untuk debug lokal
df = df[:100].to_pandas(wrap=True) Saat Anda selesai menulis kode, Anda dapat mengujinya secara lokal dengan kecepatan tinggi. Setelah pengujian selesai, ubah nilai DEBUG menjadi False untuk menjalankan komputasi penuh di MaxCompute.
Kami menyarankan menggunakan MaxCompute Studio untuk melakukan debug program PyODPS lokal.
Bagaimana cara menghindari eksekusi lambat dalam loop bersarang?
Untuk mengoptimalkan performa, kami menyarankan mengumpulkan hasil loop dalam dict atau list Python, lalu membuat objek DataFrame di luar loop. Jika Anda menempatkan kode pembuatan DataFrame seperti df=XXX di dalam loop luar, objek DataFrame baru akan dihasilkan pada setiap iterasi, yang secara signifikan memperlambat kecepatan eksekusi keseluruhan.
Bagaimana cara menghindari pengunduhan data ke mesin lokal?
Untuk informasi selengkapnya, lihat Gunakan node PyODPS untuk menghindari pengunduhan data ke mesin lokal.
Kapan mengunduh data untuk pemrosesan lokal
Anda dapat mengunduh data PyODPS untuk pemrosesan lokal dalam skenario berikut:
Jumlah data kecil dan dapat muat dalam memori mesin lokal Anda.
Anda perlu melakukan operasi baris per baris yang memperluas satu baris menjadi beberapa baris, atau menerapkan fungsi Python kompleks pada setiap baris. DataFrame PyODPS dapat menangani hal ini secara efisien dengan memanfaatkan kemampuan komputasi paralel MaxCompute.
Misalnya, jika Anda memiliki kolom yang berisi string JSON dan ingin memperluas setiap objek JSON menjadi beberapa baris berdasarkan pasangan kunci-nilainya, Anda dapat menggunakan kode berikut.
In [12]: df json 0 {"a": 1, "b": 2} 1 {"c": 4, "b": 3} In [14]: from odps.df import output In [16]: @output(['k', 'v'], ['string', 'int']) ...: def h(row): ...: import json ...: for k, v in json.loads(row.json).items(): ...: yield k, v ...: In [21]: df.apply(h, axis=1) k v 0 a 1 1 b 2 2 c 4 3 b 3
Bagaimana cara mengambil lebih dari 10.000 catatan dengan open_reader?
Gunakan CREATE TABLE ... AS SELECT ... untuk menyimpan hasil kueri SQL ke tabel baru, lalu gunakan table.open_reader untuk membaca data lengkap dari tabel tersebut.
Operator bawaan vs. UDF
Fungsi yang ditentukan pengguna (UDF) jauh lebih lambat daripada operator bawaan. Oleh karena itu, gunakan operator bawaan kapan pun memungkinkan.
Dalam pengujian pada dataset satu juta baris, menerapkan UDF pada setiap baris meningkatkan waktu eksekusi dari 7 menjadi 27 detik.
Nilai partisi kosong dari skema DataFrame
Hal ini terjadi karena DataFrame memperlakukan kolom partisi dan kolom biasa secara sama. Akibatnya, schema.partitions pada objek DataFrame tidak memberikan informasi tentang kolom partisi tabel yang mendasarinya. Anda dapat menyaring data dengan menggunakan kolom partisi sebagai kolom biasa.
df = o.get_table('your_table').to_df()
print(df[df.ds == 'your_partition_value'].execute())Untuk bekerja dengan metadata partisi, kami menyarankan menggunakan metode yang disediakan oleh objek tabel. Untuk informasi selengkapnya, lihat Tabel.
Bagaimana cara melakukan Produk Kartesius dengan DataFrame PyODPS?
Untuk informasi selengkapnya, lihat Cara menangani Produk Kartesius dalam DataFrame PyODPS.
Bagaimana cara mengimplementasikan segmentasi kata Tionghoa Jieba di PyODPS?
Untuk informasi selengkapnya, lihat Gunakan node PyODPS untuk melakukan segmentasi kata Tionghoa dengan Jieba.
Bagaimana cara mengunduh set data lengkap dengan menggunakan PyODPS?
Secara default, PyODPS tidak membatasi jumlah data yang dibaca dari Instance. Namun, untuk proyek MaxCompute yang dilindungi, pengunduhan data melalui Tunnel dibatasi. Dalam kasus ini, jika options.tunnel.limit_instance_tunnel tidak diatur, batasan ukuran data diaktifkan secara otomatis. Jumlah catatan yang dapat diunduh kemudian dibatasi oleh konfigurasi MaxCompute, yang biasanya 10.000 catatan. Jika Anda perlu mengambil semua data secara iteratif, Anda harus menonaktifkan limit. Anda dapat menggunakan pernyataan berikut untuk mengaktifkan Instance Tunnel secara global dan menonaktifkan limit.
options.tunnel.use_instance_tunnel = True
options.tunnel.limit_instance_tunnel = False # Nonaktifkan batasan untuk membaca semua data.
with instance.open_reader() as reader:
# Anda dapat membaca set data lengkap melalui Instance Tunnel.execute_sql vs. DataFrame untuk perhitungan laju null
DataFrame memberikan performa yang lebih baik untuk agregasi. Kami menyarankan menggunakan DataFrame untuk melakukan operasi agregasi.
Bagaimana cara mengonfigurasi tipe data di PyODPS?
Jika Anda menggunakan PyODPS, Anda dapat menggunakan salah satu metode berikut untuk mengaktifkan tipe data baru:
Untuk mengaktifkan tipe data baru dengan menggunakan metode
execute_sql, jalankano.execute_sql('set odps.sql.type.system.odps2=true;query_sql', hints={"odps.sql.submit.mode" : "script"}).Untuk mengaktifkan tipe data baru untuk operasi DataFrame seperti
persist,execute, atauto_pandas, Anda dapat menggunakan parameterhints. Pengaturan yang ditentukan dengan cara ini hanya berlaku untuk satu pekerjaan.from odps.df import DataFrame users = DataFrame(o.get_table('odps2_test')) users.persist('copy_test',hints={'odps.sql.type.system.odps2':'true'})Untuk mengaktifkan pengaturan secara global untuk semua operasi DataFrame, atur parameter opsi
options.sql.use_odps2_extension = True.
"ValueError" dengan tipe Decimal
Anda dapat mengatasi masalah ini dengan salah satu cara berikut:
Upgrade SDK ke V0.8.4 atau yang lebih baru.
Tambahkan pernyataan berikut ke kode Anda:
from odps.types import Decimal Decimal._max_precision=38
Bagaimana cara mengatasi eksekusi SQL yang lambat di PyODPS?
PyODPS tidak melakukan operasi intensif sebelum mengirimkan tugas SQL. Dalam kebanyakan kasus, eksekusi SQL yang lambat tidak terkait dengan PyODPS. Anda dapat mengikuti langkah-langkah berikut untuk mengidentifikasi penyebabnya:
Periksa latensi jaringan dan server
Periksa latensi di server proxy atau tautan jaringan yang dilewati pengiriman tugas.
Periksa masalah di sisi server, seperti penundaan antrian tugas.
Evaluasi efisiensi pembacaan data
Jika eksekusi SQL Anda melibatkan pembacaan data dalam jumlah besar, periksa apakah kecepatan baca lambat karena volume data besar atau jumlah shard data yang berlebihan. Lakukan langkah-langkah berikut:
Anda dapat mencoba memisahkan pengiriman tugas dari pembacaan data. Untuk melakukannya, kirimkan tugas dengan menggunakan run_sql, tunggu hingga tugas selesai dengan menggunakan instance.wait_for_success, lalu baca data dengan menggunakan instance.open_reader untuk menentukan latensi yang disebabkan oleh setiap pernyataan. Berikut adalah contoh pemisahan ini:
Sebelum pemisahan:
with o.execute_sql('select * from your_table').open_reader() as reader: for row in reader: print(row)Setelah pemisahan:
inst = o.run_sql('select * from your_table') inst.wait_for_success() with inst.open_reader() as reader: for row in reader: print(row)
Verifikasi status pekerjaan DataWorks (jika berlaku)
Untuk pekerjaan yang dikirimkan di DataWorks, periksa apakah ada tugas SQL yang berhasil dikirim tetapi gagal menghasilkan Logview, terutama saat versi PyODPS lebih rendah dari 0.11.6. Tugas-tugas ini biasanya dikirimkan dengan menggunakan metode execute_sql atau run_sql.
Analisis faktor lingkungan lokal
Untuk menentukan apakah masalah terkait dengan lingkungan lokal Anda, kami menyarankan mengaktifkan logging debug. PyODPS mencetak semua permintaan dan tanggapan, yang memungkinkan Anda mengidentifikasi lokasi penundaan.
Contoh:
import datetime import logging from odps import ODPS logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') o = ODPS(...) # Masukkan kredensial Anda di sini. Abaikan ini jika entri MaxCompute sudah disediakan di lingkungan. # Cetak waktu lokal untuk menentukan kapan operasi lokal dimulai. print("Check time:", datetime.datetime.now()) # Kirimkan tugas. inst = o.run_sql("select * from your_table")Output standar harus mirip dengan hasil berikut:
Check time: 2025-01-24 15:34:21.531330 2025-01-24 15:34:21,532 - odps.rest - DEBUG - Start request. 2025-01-24 15:34:21,532 - odps.rest - DEBUG - POST: http://service.<region>.maxcompute.aliyun.com/api/projects/<project>/instances 2025-01-24 15:34:21,532 - odps.rest - DEBUG - data: b'<?xml version="1.0" encoding="utf-8"?>\n<Instance>\n <Job>\n <Priority>9</Priority>\n <Tasks>\n <SQL>\n .... 2025-01-24 15:34:21,532 - odps.rest - DEBUG - headers: {'Content-Type': 'application/xml'} 2025-01-24 15:34:21,533 - odps.rest - DEBUG - request url + params /api/projects/<project>/instances?curr_project=<project> 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers before signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736'} 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers to sign: OrderedDict([('content-md5', ''), ('content-type', 'application/xml'), ('date', 'Fri, 24 Jan 2025 07:34:21 GMT')]) 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - canonical string: POST application/xml Fri, 24 Jan 2025 07:34:21 GMT /projects/maxframe_ci_cd/instances?curr_project=maxframe_ci_cd 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers after signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736', .... 2025-01-24 15:34:21,533 - urllib3.connectionpool - DEBUG - Resetting dropped connection: service.<region>.maxcompute.aliyun.com 2025-01-24 15:34:22,027 - urllib3.connectionpool - DEBUG - http://service.<region>.maxcompute.aliyun.com:80 "POST /api/projects/<project>/instances?curr_project=<project> HTTP/1.1" 201 0 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.status_code 201 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.headers: {'Server': '<Server>', 'Date': 'Fri, 24 Jan 2025 07:34:22 GMT', 'Content-Type': 'text/plain;charset=utf-8', 'Content-Length': '0', 'Connection': 'close', 'Location': .... 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.content: b''Output ini menunjukkan waktu saat kode memulai tugas (2025-01-24 15:34:21.531), waktu saat permintaan dikirim (2025-01-24 15:34:21.533), dan waktu saat server mengembalikan respons (2025-01-24 15:34:22.027). Hal ini memungkinkan Anda menentukan biaya waktu setiap tahap.
Bagaimana cara mendapatkan jumlah file dan waktu modifikasi terakhir tabel MaxCompute dengan menggunakan PyODPS?
Deskripsi masalah
Saat menjalankan DESC EXTENDED table_name atau DESC EXTENDED table_name PARTITION (xxx='xxx') melalui client MaxCompute (odpscmd) atau node SQL MaxCompute DataWorks, output mencakup metadata tabel terperinci seperti jumlah file (file_num), ukuran fisik, dan waktu modifikasi terakhir.
Namun, menjalankan DESC EXTENDED melalui metode run_sql() atau execute_sql() PyODPS tidak mengembalikan informasi extended lengkap (seperti field file_num), sehingga tidak mungkin mengekstrak metrik kunci secara terstruktur.

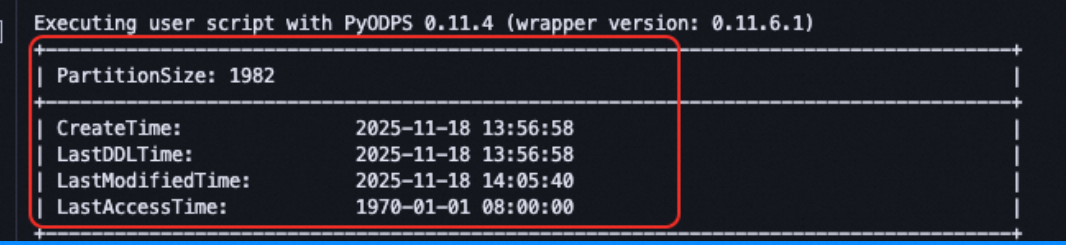
Solusi
Gunakan antarmuka SDK native PyODPS seperti table.reload_extend_info() atau partition.reload() untuk mendapatkan statistik ini. Klik tautan ini untuk melihat kode sumber.
Contoh berikut menunjukkan cara mendapatkan jumlah file setiap partisi:
from odps.models import Partition # Ganti dengan nama tabel sebenarnya table_name = 'your_real_table_name' # ========== 1. Dapatkan objek tabel ========== try: # Asumsikan bahwa o adalah objek ODPS yang telah diinisialisasi # Di node PyODPS DataWorks, hapus komentar baris berikut # o = odps table = o.get_table(table_name) print(f"Objek tabel diperoleh: {table_name}") except Exception as e: print(f"Error: Gagal memperoleh tabel '{table_name}'. Penyebab: {str(e)}") raise # ========== 2. Periksa apakah tabel dipartisi ========== if not table.table_schema.partitions: print(f"Tabel '{table_name}' bukan tabel partisi. Kueri partisi tidak didukung.") else: print(f"Tabel '{table_name}' adalah tabel partisi. Mengiterasi semua partisi...") print("=" * 60) # ========== 3. Iterasi partisi dengan menggunakan table.partitions ========== partition_count = 0 try: for partition in table.partitions: try: part_spec = partition.spec if not part_spec: part_spec = 'Partisi tidak diketahui' # partition.reload() memuat metadata partisi terperinci # Ini memicu satu atau beberapa panggilan API ke MaxCompute Metastore partition.reload() print(f"Spesifikasi Partisi: {part_spec}") print(f" - Waktu Pembuatan : {partition.creation_time}") print(f" - Waktu Modifikasi Terakhir : {partition.last_data_modified_time}") print(f" - Ukuran Fisik : {partition.physical_size} byte") print(f" - Jumlah File : {partition.file_num}") print(f" - Diarsipkan : {partition.is_archived}") print("-" * 60) partition_count += 1 except Exception as e_inner: print(f"Peringatan: Gagal memuat detail untuk partisi {partition.spec or ''}. Penyebab: {str(e_inner)}") print("-" * 60) continue print(f"Iterasi selesai: {partition_count} partisi diproses.") except Exception as e_outer: print(f"Error fatal selama iterasi partisi. Penyebab: {str(e_outer)}")