MaxCompute menyediakan solusi analitik data lake yang memungkinkan Anda membuat objek manajemen untuk mendefinisikan metadata dan metode akses data dari sumber data eksternal. Proyek Eksternal atau Skema Eksternal dapat dipetakan ke Catalog, Database, atau Schema dari sumber data eksternal sehingga Anda dapat langsung mengakses semua tabel di dalamnya. Solusi ini menghilangkan hambatan antara data lake dan gudang data dengan menggabungkan fleksibilitas serta ekosistem multi-engine yang kaya dari data lake dengan kemampuan tingkat enterprise dari gudang data untuk membangun platform manajemen data terintegrasi. Fitur ini berada dalam status pratinjau publik.
Gudang data dan data lake
Kategori | Kemampuan |
Gudang data | Gudang data menekankan manajemen dan pembatasan terhadap data terstruktur dan data semi-terstruktur. Gudang data mengandalkan manajemen yang kuat untuk mencapai kinerja komputasi yang lebih baik serta kemampuan manajemen yang lebih terstandarisasi. |
Data lake | Data lake menekankan penyimpanan data terbuka dan format data umum. Data lake mendukung berbagai engine yang menghasilkan atau mengonsumsi data sesuai kebutuhan. Untuk menjaga fleksibilitas, data lake hanya menyediakan kemampuan manajemen yang lemah. Data lake kompatibel dengan data tidak terstruktur dan mendukung pendekatan schema-on-read, sehingga memberikan cara yang lebih fleksibel dalam mengelola data. |
Gudang data MaxCompute
MaxCompute adalah gudang data cloud-native berbasis arsitektur serverless. Anda dapat melakukan operasi berikut:
Memodelkan gudang data menggunakan MaxCompute.
Menggunakan alat ekstrak, transformasi, dan muat (ETL) untuk memuat dan menyimpan data ke dalam tabel yang telah dimodelkan dengan skema yang telah ditentukan.
Memproses data berskala besar di dalam gudang data menggunakan mesin SQL standar serta menganalisis data tersebut menggunakan mesin OLAP MaxQA atau Hologres.
Skenario penggunaan MaxCompute dengan data lake dan kueri terfederasi
Dalam skenario data lake, data berada di dalam lake dan dihasilkan atau dikonsumsi oleh berbagai engine. Mesin komputasi MaxCompute dapat bertindak sebagai salah satu engine tersebut untuk memproses dan menggunakan data. Dalam kasus ini, MaxCompute perlu membaca data yang dihasilkan oleh sumber hulu di dalam data lake, kompatibel dengan berbagai format data open source utama, melakukan perhitungan di dalam engine-nya sendiri, serta menghasilkan data untuk alur kerja hilir.
Sebagai gudang data yang aman, berkinerja tinggi, dan hemat biaya yang mengagregasi data bernilai tinggi, MaxCompute juga perlu mengambil metadata dan data dari data lake. Hal ini memungkinkan komputasi langsung terhadap data eksternal dan kueri terfederasi dengan data internal guna mengekstraksi nilai serta mengonsolidasikannya ke dalam gudang data.
Selain data lake, MaxCompute sebagai gudang data juga perlu mengambil data dari berbagai sumber data eksternal lainnya, seperti Hadoop dan Hologres, untuk melakukan kueri terfederasi dengan data internalnya. Dalam skenario kueri terfederasi, MaxCompute juga harus mendukung pembacaan metadata dan data dari sistem eksternal.
Analitik data lake MaxCompute
Analitik data lake MaxCompute dibangun di atas mesin komputasi MaxCompute.
Solusi ini mendukung akses ke layanan metadata Alibaba Cloud atau Layanan Penyimpanan Objek melalui jaringan produk cloud yang saling terhubung. Jika sumber data berada di dalam VPC, Anda dapat menggunakan Jalur sewa untuk mengakses sumber data eksternal tersebut.
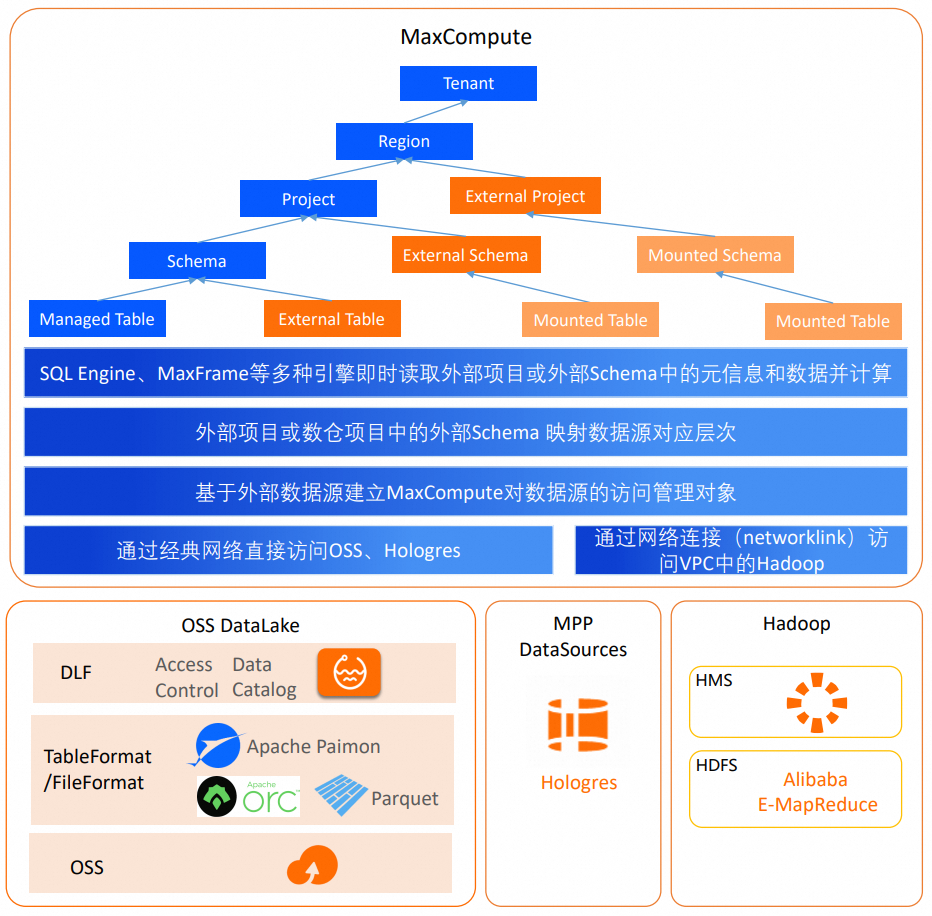
Solusi ini memungkinkan Anda membuat objek manajemen untuk mendefinisikan metadata dan metode akses data dari sumber data eksternal. Proyek Eksternal atau Skema Eksternal dapat dipetakan ke Catalog, Database, atau Schema dari sumber data eksternal sehingga Anda dapat langsung mengakses semua tabel dalam cakupan tersebut.
Konektivitas jaringan
Untuk informasi selengkapnya tentang Networklink, lihat Network Connection Flow. MaxCompute dapat menggunakan koneksi jaringan untuk mengakses sumber data di dalam VPC, seperti kluster E-MapReduce (EMR) dan instans ApsaraDB RDS (segera tersedia). Data Lake Formation (DLF), Object Storage Service (OSS), dan Hologres berada dalam jaringan layanan cloud yang saling terhubung. MaxCompute dapat langsung mengakses data di layanan-layanan tersebut tanpa perlu mengonfigurasi Networklink.
Foreign Server
Foreign Server berisi informasi metadata dan akses data, termasuk kredensial, lokasi, dan protokol koneksi. MaxCompute menggunakan Foreign Server untuk terhubung ke dan menggunakan metadata serta data dari sumber data. Foreign Server merupakan objek manajemen tingkat penyewa yang didefinisikan oleh administrator penyewa.
External Schema
External Schema adalah jenis khusus schema dalam proyek gudang data MaxCompute. Seperti yang ditunjukkan pada gambar sebelumnya, External Schema dapat dipetakan ke Database sumber data (untuk skenario DLF_legacy atau Hive) atau Schema (untuk skenario Hologres). Hal ini memungkinkan Anda langsung mengakses tabel dan data dalam cakupan tersebut. Tabel yang tidak dibuat di metadata MaxCompute tetapi dipetakan dari sumber data eksternal melalui External Schema dikenal sebagai federated foreign tables (Mounted Tables).
Federated foreign table tidak menyimpan metadata di dalam MaxCompute. Sebaliknya, MaxCompute mengambil metadata tersebut secara real time dari layanan metadata yang ditentukan dalam objek Foreign Server. Saat menjalankan kueri, Anda tidak perlu membuat tabel eksternal menggunakan pernyataan DDL. Anda dapat langsung mereferensikan tabel asli dengan menggunakan nama proyek dan nama External Schema sebagai namespace. Jika struktur tabel atau data di sumber berubah, federated foreign table akan langsung mencerminkan kondisi terbaru tersebut. Tingkat hierarki sumber data yang dipetakan oleh External Schema bergantung pada hierarki sumber data dan tingkat akses yang didefinisikan dalam Foreign Server.
External Project
Dalam Data Lakehouse Solution 1.0, External Project menggunakan model dua lapis. Mirip dengan External Schema, External Project dipetakan ke Database sumber data (untuk skenario DLF_legacy atau Hive) atau Schema (untuk skenario Hologres) dan memerlukan proyek gudang data sebagai lingkungan runtime untuk membaca dan menghitung data eksternal. Namun, pemetaan Database atau Schema pada tingkat proyek menghasilkan terlalu banyak External Project. Selain itu, MaxCompute kini merekomendasikan model proyek tiga lapis agar lebih selaras dengan hierarki Catalog tiga lapis dari sumber data eksternal. External Project dua lapis dari Data Lakehouse Solution 1.0 tidak kompatibel dengan proyek gudang data tiga lapis yang baru. Oleh karena itu, MaxCompute sedang menghentikan penggunaan External Project dari Data Lakehouse Solution 1.0. Anda dapat melakukan migrasi External Project yang ada ke External Schema. Untuk detail migrasi, lihat Migrate External Projects in Data Lakehouse Solution 1.0 to External Schemas in Data Lakehouse 2.0.
Dalam analitik data lake, External Project yang baru secara langsung dipetakan ke Catalog sumber data tiga lapis (untuk skenario DLF) atau Database (untuk skenario Hologres). Hal ini memberikan visibilitas langsung ke Database di bawah Catalog DLF atau Schema di bawah Database Hologres. Tingkat menengah ini, yang dipetakan secara langsung tanpa dibuat di MaxCompute, disebut Mounted Schema. Anda kemudian dapat mengakses tabel sumber sebagai federated foreign tables.
Jenis sumber data | Hierarki server asing | Pemetaan Skema Eksternal | Pemetaan External Project | Pemetaan Proyek Eksternal Lama | Metode autentikasi |
DLF_legacy+OSS | Layanan DLF dan OSS tingkat wilayah | DLF Catalog.Database | Tidak didukung | DLF Catalog.Database | RAMRole |
Hive+HDFS | Instans E-MapReduce | Database Hive | Tidak didukung | Database Hive | Tanpa autentikasi |
Hologres | Database dari instans Hologres | Schema | - | Tidak didukung | RAMRole |
- | Database | Tidak didukung | Otentikasi identitas SLR dan pengguna saat ini | ||
DLF | Layanan DLF tingkat wilayah | Tidak didukung | DLF Catalog | Tidak didukung | Otentikasi identitas SLR dan pengguna saat ini |
Filesystem Catalog | Direktori tingkat Catalog Paimon di OSS | Tidak didukung | Catalog yang diurai dari direktori tingkat Catalog Paimon | Tidak didukung | RAMRole |
Berbagai sumber data mendukung jenis autentikasi yang berbeda. MaxCompute akan mendukung lebih banyak metode autentikasi di rilis mendatang, seperti menggunakan identitas pengguna saat ini untuk mengakses Hologres atau menggunakan Otentikasi Kerberos untuk mengakses Hive.