Topik ini menjelaskan cara mengembangkan aplikasi Spark di MaxCompute menggunakan PySpark.
Untuk mengakses tabel MaxCompute dalam aplikasi Anda, Anda harus mengkompilasi paket odps-spark-datasource. Untuk informasi lebih lanjut, lihat Menyiapkan lingkungan pengembangan Linux.
Mengembangkan aplikasi Spark SQL di Spark 1.6
Kode contoh:
from pyspark import SparkContext, SparkConf
from pyspark.sql import OdpsContext
if __name__ == '__main__':
conf = SparkConf().setAppName("odps_pyspark")
sc = SparkContext(conf=conf)
sql_context = OdpsContext(sc)
sql_context.sql("DROP TABLE IF EXISTS spark_sql_test_table")
sql_context.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
sql_context.sql("INSERT INTO TABLE spark_sql_test_table SELECT 'abc', 100000")
sql_context.sql("SELECT * FROM spark_sql_test_table").show()
sql_context.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()Jalankan perintah berikut untuk mengirim dan menjalankan kode:
./bin/spark-submit \
--jars cupid/odps-spark-datasource_xxx.jar \
example.pyMengembangkan aplikasi Spark SQL di Spark 2.3
Kode contoh:
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("spark sql").getOrCreate()
spark.sql("DROP TABLE IF EXISTS spark_sql_test_table")
spark.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
spark.sql("INSERT INTO spark_sql_test_table SELECT 'abc', 100000")
spark.sql("SELECT * FROM spark_sql_test_table").show()
spark.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()Kirim dan jalankan kode.
Jalankan perintah berikut untuk mengirim dan menjalankan kode dalam mode kluster:
spark-submit --master yarn-cluster \ --jars cupid/odps-spark-datasource_xxx.jar \ example.pyJalankan perintah berikut untuk mengirim dan menjalankan kode dalam mode lokal:
cd $SPARK_HOME ./bin/spark-submit --master local[4] \ --driver-class-path cupid/odps-spark-datasource_xxx.jar \ /path/to/odps-spark-examples/spark-examples/src/main/python/spark_sql.pyCatatanJika Spark berjalan dalam mode lokal, MaxCompute Tunnel diperlukan untuk mengakses tabel MaxCompute.
Jika Spark berjalan dalam mode lokal, gunakan opsi --driver-class-path alih-alih opsi --jars.
Mengembangkan aplikasi Spark SQL di Spark 2.4
Kode contoh berikut memberikan sebuah contoh. Buat proyek Python pada mesin lokal Anda dan paketkan proyek tersebut.
spark-test.py
# -*- coding: utf-8 -*- import os from pyspark.sql import SparkSession from mc.service.udf.udfs import udf_squared, udf_numpy def noop(x): import socket import sys host = socket.gethostname() + ' '.join(sys.path) + ' '.join(os.environ) print('host: ' + host) print('PYTHONPATH: ' + os.environ['PYTHONPATH']) print('PWD: ' + os.environ['PWD']) print(os.listdir('.')) return host if __name__ == '__main__': # Saat melakukan debugging lokal, Anda harus menambahkan kode berikut. Saat menjalankan pekerjaan MaxCompute, Anda harus menghapus kode berikut. Jika tidak menghapus kode, kesalahan akan dilaporkan. # .master("local[4]") \ spark = SparkSession \ .builder \ .appName("test_pyspark") \ .getOrCreate() sc = spark.sparkContext # Verifikasi variabel lingkungan sistem saat ini. rdd = sc.parallelize(range(10), 2) hosts = rdd.map(noop).distinct().collect() print(hosts) # Verifikasi fungsi yang ditentukan pengguna (UDFs). # https://docs.databricks.com/spark/latest/spark-sql/udf-python.html# spark.udf.register("udf_squared", udf_squared) spark.udf.register("udf_numpy", udf_numpy) tableName = "test_pyspark1" df = spark.sql("""select id, udf_squared(age) age1, udf_squared(age) age2, udf_numpy() udf_numpy from %s """ % tableName) print("rdf count, %s\n" % df.count()) df.show()udfs.py
# -*- coding: utf-8 -*- import numpy as np def udf_squared(s): """ spark udf :param s: :return: """ if s is None: return 0 return s * s def udf_numpy(): rand = np.random.randn() return rand if __name__ == "__main__": print(udf_numpy())
Kirim dan jalankan kode.
Gunakan klien Spark
Konfigurasikan pengaturan pada klien Spark.
Konfigurasikan pengaturan pada klien Spark.
Untuk informasi lebih lanjut tentang cara mengonfigurasi lingkungan pengembangan Linux, lihat Menyiapkan lingkungan pengembangan Linux.
Untuk informasi lebih lanjut tentang cara mengonfigurasi lingkungan pengembangan Windows, lihat Menyiapkan lingkungan pengembangan Windows.
Tambahkan parameter berikut untuk sumber daya bersama ke file spark-defaults.conf di folder
confklien Spark:spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonCatatanParameter sebelumnya menentukan direktori paket Python. Anda dapat memilih untuk menggunakan paket Python yang diunduh atau paket sumber daya bersama.
Kirim dan jalankan kode.
# mc_pyspark-0.1.0-py3-none-any.zip adalah file yang berisi kode logika bisnis umum. spark-submit --py-files mc_pyspark-0.1.0-py3-none-any.zip spark-test.pyCatatanJika paket dependensi pihak ketiga yang diunduh tidak dapat diimpor, pesan kesalahan
ImportError: cannot import name _distributor_initmuncul. Kami sarankan Anda menggunakan paket sumber daya bersama. Untuk informasi lebih lanjut, lihat Versi Python PySpark dan dependensi yang didukung.
Gunakan node ODPS Spark DataWorks
Buat node ODPS Spark DataWorks. Untuk informasi lebih lanjut, lihat Mengembangkan tugas MaxCompute Spark.
Kirim dan jalankan kode.
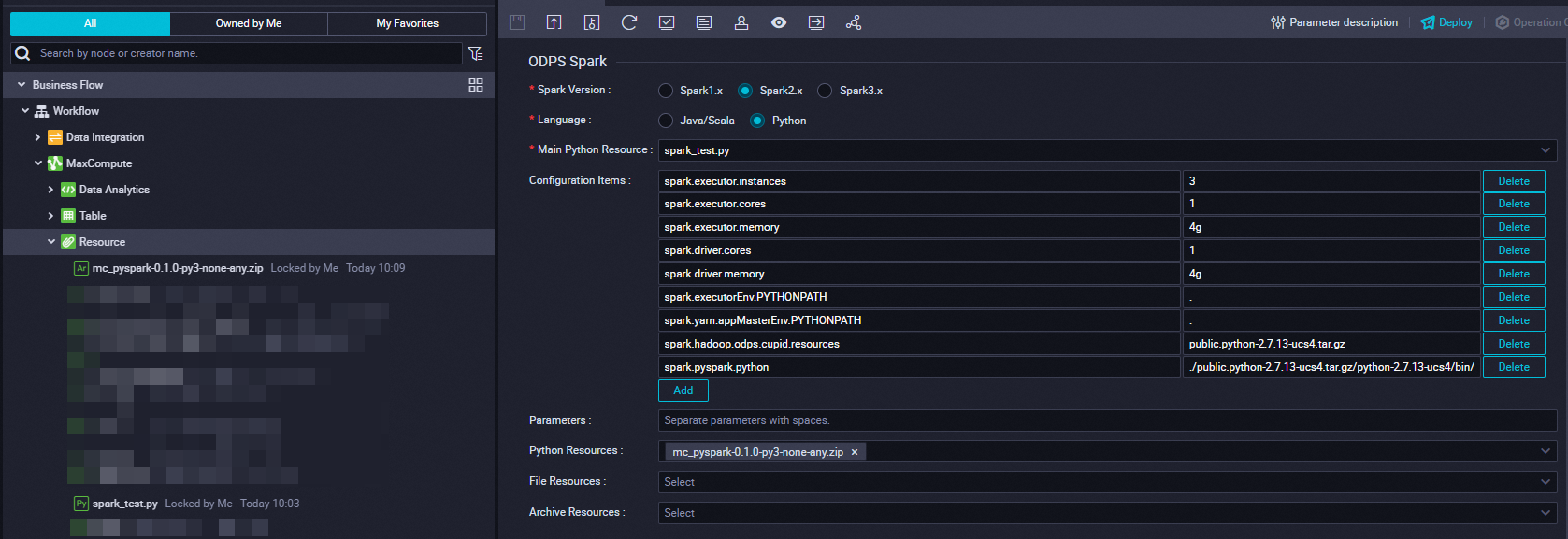
Tabel berikut menjelaskan parameter yang perlu Anda konfigurasikan saat membuat node ODPS Spark di konsol DataWorks.
Parameter
Nilai
Versi Spark
Spark2.x
Bahasa
Python
Sumber Daya Utama Python
spark_test.py
Item Konfigurasi
-- Item konfigurasi untuk permintaan sumber daya. spark.executor.instances=3 spark.executor.cores=1 spark.executor.memory=4g spark.driver.cores=1 spark.driver.memory=4g -- spark.executorEnv.PYTHONPATH=. spark.yarn.appMasterEnv.PYTHONPATH=. -- Tentukan sumber daya yang akan dirujuk. spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonSumber Daya Python
mc_pyspark-0.1.0-py3-none-any.zip
Unggah sumber daya.
# Ubah ekstensi paket kode logika bisnis menjadi .zip. cp /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.whl /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip # Jalankan perintah berikut untuk mengunggah paket ke MaxCompute sebagai sumber daya: # Direktif `-f` akan menimpa sumber daya dalam proyek MaxCompute yang memiliki nama yang sama. Harap konfirmasi apakah akan menimpa atau mengganti nama. add archive /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip -f;Konfigurasikan dan jalankan tugas.
Konfigurasi
Eksekusi
Unggah paket yang diperlukan
Cluster MaxCompute tidak mengizinkan instalasi pustaka Python. Jika aplikasi Spark di MaxCompute bergantung pada pustaka Python, plugin, atau proyek, Anda dapat memaketkan sumber daya yang diperlukan di mesin lokal dan menjalankan skrip spark-submit untuk mengunggah paket ke MaxCompute. Untuk beberapa sumber daya khusus, versi Python di mesin lokal yang digunakan untuk memaketkan sumber daya harus sama dengan versi Python di cluster MaxCompute tempat aplikasi berjalan. Pilih salah satu metode berikut untuk memaketkan sumber daya sesuai kompleksitas bisnis Anda.
Gunakan sumber daya publik tanpa pemaketan
Gunakan sumber daya publik untuk Python 2.7.13.
spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonPustaka pihak ketiga berikut tersedia:
$./bin/pip list Package Version ----------------------------- ----------- absl-py 0.11.0 aenum 2.2.4 asn1crypto 0.23.0 astor 0.8.1 astroid 1.6.1 atomicwrites 1.4.0 attrs 20.3.0 backports.functools-lru-cache 1.6.1 backports.lzma 0.0.14 backports.weakref 1.0.post1 beautifulsoup4 4.9.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bz2file 0.98 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.9.11 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 configparser 4.0.2 contextlib2 0.6.0.post1 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.5 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 enum34 1.1.10 fake-useragent 0.1.11 Fiona 1.8.17 funcsigs 1.0.2 functools32 3.2.3.post2 future 0.16.0 futures 3.3.0 gast 0.2.2 gensim 3.8.3 geopandas 0.6.3 getpass3 1.2 google-auth 1.23.0 google-auth-oauthlib 0.4.1 google-pasta 0.2.0 grpcio 1.33.2 h5py 2.7.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 ipaddress 1.0.23 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 kafka-python 1.4.6 kazoo 2.5.0 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.2 kiwisolver 1.1.0 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 MarkupSafe 1.0 matplotlib 2.2.5 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 more-itertools 5.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.16.1 oauthlib 3.1.0 opt-einsum 2.3.2 packaging 20.4 pandas 0.24.2 pandocfilters 1.4.2 parso 0.1.1 pathlib2 2.3.5 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pyasn1 0.4.8 pyasn1-modules 0.2.8 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 2.2.2 PyQRCode 1.2.1 pytest 4.6.11 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 redis 3.2.1 requests 2.25.0 requests-oauthlib 1.3.0 rope 0.10.7 rsa 4.5 ruamel.ordereddict 0.4.15 ruamel.yaml 0.11.14 s3transfer 0.2.0 scandir 1.10.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.2.3 seaborn 0.9.1 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 singledispatch 3.4.0.3 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 soupsieve 1.9.6 SQLAlchemy 1.3.20 statsmodels 0.11.0 subprocess32 3.5.4 tabulate 0.8.7 tensorflow 2.0.0 tensorflow-estimator 2.0.1 termcolor 1.1.0 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toolz 0.9.0 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 Werkzeug 1.0.1 wheel 0.35.1 wrapt 1.11.1 xgboost 0.82 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 1.2.0Gunakan sumber daya publik untuk Python 3.7.9.
spark.hadoop.odps.cupid.resources = public.python-3.7.9-ucs4.tar.gz spark.pyspark.python = ./public.python-3.7.9-ucs4.tar.gz/python-3.7.9-ucs4/bin/python3Pustaka pihak ketiga berikut tersedia:
Package Version ----------------------------- ----------- appnope 0.1.0 asn1crypto 0.23.0 astroid 1.6.1 attrs 20.3.0 autopep8 1.3.4 backcall 0.2.0 backports.functools-lru-cache 1.5 backports.weakref 1.0rc1 beautifulsoup4 4.6.0 bidict 0.17.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bs4 0.0.1 bz2file 0.98 cached-property 1.5.2 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.11.28 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.21 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 fake-useragent 0.1.11 Fiona 1.8.17 future 0.16.0 gensim 3.8.3 geopandas 0.8.0 getpass3 1.2 h5py 3.1.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 iniconfig 1.1.1 ipykernel 5.3.4 ipython 7.19.0 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 jupyter-client 6.1.7 jupyter-core 4.6.3 kafka-python 1.4.6 kazoo 2.5.0 kiwisolver 1.3.1 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 Mako 1.0.10 MarkupSafe 1.0 matplotlib 3.3.3 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.19.4 packaging 20.4 pandas 1.1.4 pandocfilters 1.4.2 parso 0.1.1 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 plotly 4.12.0 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pycodestyle 2.3.1 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 3.0.0.post1 PyQRCode 1.2.1 pytest 6.1.2 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 pyzmq 17.0.0 qtconsole 4.3.1 redis 3.2.1 requests 2.25.0 retrying 1.3.3 rope 0.10.7 ruamel.yaml 0.16.12 ruamel.yaml.clib 0.2.2 s3transfer 0.2.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.5.4 seaborn 0.11.0 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 SQLAlchemy 1.3.20 statsmodels 0.12.1 tabulate 0.8.7 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toml 0.10.2 toolz 0.9.0 tornado 6.1 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 wheel 0.35.1 wrapt 1.11.1 xgboost 1.2.1 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 1.2.0
Unggah paket wheel tunggal
Jika beberapa dependensi Python diperlukan, Anda hanya dapat mengunggah satu paket wheel. Dalam kebanyakan kasus, paket wheel manylinux yang diunggah. Untuk mengunggah paket wheel tunggal, lakukan langkah-langkah berikut:
Kemas paket wheel menjadi paket ZIP. Sebagai contoh, kemas paket pymysql.whl menjadi paket pymysql.zip.
Unggah paket ZIP dan simpan paket tersebut dengan kelas penyimpanan Archive.
Pilih paket ZIP pada tab konfigurasi node Spark di konsol DataWorks.
Ubah variabel lingkungan dalam kode untuk mengimpor paket ZIP.
sys.path.append('pymysql') import pymysql
Gunakan file requirements.txt
Jika sejumlah besar dependensi tambahan diperlukan, Anda harus mengulangi prosedur untuk mengunggah paket wheel beberapa kali. Dalam hal ini, Anda dapat mengunduh skrip dan membuat file requirements.txt yang mencantumkan dependensi yang diperlukan dan menggunakan skrip dan file requirements.txt untuk menghasilkan paket lingkungan Python. Kemudian, Anda dapat mengembangkan aplikasi Spark di MaxCompute menggunakan PySpark.
Penggunaan
$ chmod +x generate_env_pyspark.sh $ generate_env_pyspark.sh -h Penggunaan: generate_env_pyspark.sh [-p] [-r] [-t] [-c] [-h] Deskripsi: -p ARG, versi python, saat ini mendukung versi python 2.7, 3.5, 3.6 dan 3.7. -r ARG, jalur lokal dari persyaratan python Anda. -t ARG, direktori keluaran paket terkompresi gz. -c, mode bersih, kami hanya akan memaketkan python sesuai dengan persyaratan Anda, tanpa dependensi lain yang disediakan sebelumnya. -h, tampilkan bantuan skrip ini.Contoh
# Hasilkan paket lingkungan Python dengan dependensi yang telah diinstal sebelumnya. $ generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory # Hasilkan paket lingkungan Python dalam mode bersih. Dengan cara ini, paket yang Anda hasilkan tidak berisi dependensi yang telah diinstal sebelumnya. generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory -cCatatan
Skrip ini dapat berjalan pada sistem operasi macOS atau Linux. Untuk menggunakan skrip, Anda harus menginstal Docker terlebih dahulu. Untuk informasi lebih lanjut tentang cara menginstal Docker, lihat Dokumentasi Docker.
Versi Python berikut didukung: Python 2.7, Python 3.5, Python 3.6, dan Python 3.7. Jika Anda tidak memiliki persyaratan khusus untuk versi Python, kami sarankan Anda menggunakan Python 3.7.
Opsi
-cmenentukan apakah akan mengaktifkan mode bersih. Dalam mode bersih, dependensi yang telah diinstal sebelumnya tidak dapat dipaketkan. Oleh karena itu, paket Python berukuran kecil. Untuk informasi lebih lanjut tentang dependensi setiap versi Python, lihat Dependensi yang telah diinstal sebelumnya dari Python 2.7, Dependensi yang telah diinstal sebelumnya dari Python 3.5, Dependensi yang telah diinstal sebelumnya dari Python 3.6, dan Dependensi yang telah diinstal sebelumnya dari Python 3.7.MaxCompute memungkinkan Anda mengunggah paket sumber daya dengan ukuran maksimum 500 MB. Jika sebagian besar dependensi yang telah diinstal sebelumnya tidak digunakan, kami sarankan Anda mengonfigurasi opsi
-cuntuk memaketkan sumber daya dalam mode bersih.
Gunakan paket dalam Spark
Anda dapat menggunakan skrip generate_env_pyspark.sh untuk menghasilkan paket .tar.gz dari versi Python tertentu di jalur tertentu. Opsi
-tmenentukan jalur, dan opsi-pmenentukan versi Python. Sebagai contoh, jika Python 3.7 digunakan, paket py37.tar.gz dihasilkan. Anda dapat mengunggah paket tersebut sebagai sumber daya dengan kelas penyimpanan Archive di MaxCompute. Anda dapat mengunggah paket tersebut menggunakan klien MaxCompute atau SDK MaxCompute. Untuk informasi lebih lanjut tentang operasi sumber daya, lihat Operasi sumber daya. Untuk menggunakan klien MaxCompute untuk mengunggah paket py37.tar.gz, lakukan langkah-langkah berikut:Jalankan perintah berikut pada klien MaxCompute untuk menambahkan paket sebagai sumber daya:
# Direktif `-f` akan menimpa sumber daya dalam proyek MaxCompute yang memiliki nama yang sama. Harap konfirmasi apakah akan menimpa atau mengganti nama. add archive /your/path/to/py37.tar.gz -f;Tambahkan pengaturan parameter berikut ke konfigurasi pekerjaan Spark Anda:
spark.hadoop.odps.cupid.resources = your_project.py37.tar.gz spark.pyspark.python = your_project.py37.tar.gz/bin/pythonJika pengaturan parameter di atas tidak berlaku, Anda harus menambahkan konfigurasi berikut ke konfigurasi pekerjaan Spark Anda. Sebagai contoh, jika Anda menggunakan Apache Zeppelin untuk men-debug PySpark, Anda harus menambahkan konfigurasi lingkungan Python berikut ke notebook Apache Zeppelin.
spark.yarn.appMasterEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python spark.executorEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python
Gunakan kontainer Docker
Metode ini cocok untuk skenario berikut:
Jika Anda ingin memaketkan file .so, Anda tidak dapat menggunakan metode yang dijelaskan dalam "Unggah paket wheel tunggal" atau menjalankan
pip install.Versi Python yang Anda gunakan bukan Python 2.7, Python 3.5, Python 3.6, atau Python 3.7.
Dalam skenario di atas, Anda harus memastikan bahwa lingkungan Python yang Anda paketkan sama dengan lingkungan Python tempat pekerjaan Spark Anda berjalan. Sebagai contoh, lingkungan Python yang Anda paketkan dalam sistem operasi macOS mungkin tidak kompatibel dengan lingkungan Python tempat pekerjaan Spark Anda berjalan. Untuk memaketkan lingkungan Python 3.7 menggunakan kontainer Docker, lakukan langkah-langkah berikut:
Buat Dockerfile di host Docker Anda.
Kode contoh dalam Python 3:
FROM centos:7.6.1810 RUN set -ex \ # Pra-instal komponen yang diperlukan. && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tgz \ && tar -zxvf Python-3.7.0.tgz \ && cd Python-3.7.0 \ && ./configure prefix=/usr/local/python3 \ && make \ && make install \ && make clean \ && rm -rf /Python-3.7.0* \ && yum install -y epel-release \ && yum install -y python-pip # Tetapkan versi Python default ke Python 3. RUN set -ex \ # Cadangkan sumber daya Python 2.7. && mv /usr/bin/python /usr/bin/python27 \ && mv /usr/bin/pip /usr/bin/pip-python27 \ # Tetapkan versi Python default ke Python 3. && ln -s /usr/local/python3/bin/python3.7 /usr/bin/python \ && ln -s /usr/local/python3/bin/pip3 /usr/bin/pip # Perbaiki bug YUM yang disebabkan oleh perubahan versi Python. RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # Perbarui versi pip. RUN pip install --upgrade pipKode contoh dalam Python 2:
FROM centos:7.6.1810 RUN set -ex \ # Pra-instal komponen yang diperlukan. && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/2.7.18/Python-2.7.18.tgz \ && tar -zxvf Python-2.7.18.tgz \ && cd Python-2.7.18 \ && ./configure prefix=/usr/local/python2 \ && make \ && make install \ && make clean \ && rm -rf /Python-2.7.18* # Tetapkan versi Python default. RUN set -ex \ && mv /usr/bin/python /usr/bin/python27 \ && ln -s /usr/local/python2/bin/python /usr/bin/python RUN set -ex \ && wget https://bootstrap.pypa.io/get-pip.py \ && python get-pip.py RUN set -ex \ && rm -rf /usr/bin/pip \ && ln -s /usr/local/python2/bin/pip /usr/bin/pip # Perbaiki bug YUM yang disebabkan oleh perubahan versi Python. RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # Perbarui versi pip. RUN pip install --upgrade pip
Bangun gambar dan jalankan kontainer Docker.
# Jalankan perintah berikut di jalur tempat Dockerfile disimpan: docker build -t python-centos:3.7 docker run -itd --name python3.7 python-centos:3.7Instal pustaka Python yang diperlukan di dalam kontainer.
docker attach python3.7 pip install [Pustaka yang diperlukan]Kompres semua pustaka Python menjadi satu paket.
cd /usr/local/ zip -r python3.7.zip python3/Salin paket lingkungan Python dari kontainer ke host Anda.
# Keluar dari kontainer. ctrl+P+Q # Jalankan perintah berikut di host: docker cp python3.7:/usr/local/python3.7.zipUnggah paket Python3.7.zip sebagai sumber daya MaxCompute. Anda dapat menggunakan DataWorks untuk mengunggah paket dengan ukuran maksimum 50 MB. Jika ukuran paket melebihi 50 MB, Anda dapat menggunakan klien MaxCompute untuk mengunggah paket dan menyimpan paket dengan kelas penyimpanan Archive. Untuk informasi lebih lanjut tentang cara mengunggah sumber daya, lihat Tambahkan sumber daya.
# Direktif `-f` akan menimpa sumber daya dalam proyek MaxCompute yang memiliki nama yang sama. Harap konfirmasi apakah akan menimpa atau mengganti nama. add archive /path/to/python3.7.zip -f;Saat Anda mengirim pekerjaan, tambahkan konfigurasi berikut ke file spark-defaults.conf atau konfigurasi DataWorks:
spark.hadoop.odps.cupid.resources=[Nama proyek].python3.7.zip spark.pyspark.python=./[Nama proyek].python3.7.zip/python3/bin/python3.7CatatanSaat memaketkan sumber daya dalam kontainer Docker, Anda harus secara manual menempatkan paket .so di lingkungan Python jika paket .so tidak ditemukan. Dalam kebanyakan kasus, paket .so dapat ditemukan di dalam kontainer. Setelah Anda menemukan paket ini, tambahkan variabel lingkungan berikut ke konfigurasi pekerjaan Spark Anda:
spark.executorEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[Nama proyek].python3.7.zip/python3/[Direktori paket .so] spark.yarn.appMasterEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[Nama proyek].python3.7.zip/python3/[Direktori paket .so]
Rujuk paket Python kustom
Dalam kebanyakan kasus, Anda akan perlu menggunakan file Python kustom. Untuk mencegah beban kerja yang disebabkan oleh pengunggahan berurutan beberapa file '.py', Anda dapat memaketkan file-file ini dengan mengikuti langkah-langkah berikut:
Buat file kosong bernama __init__.py dan kemas kode menjadi paket ZIP.
Unggah paket ZIP sebagai sumber daya MaxCompute dan ubah nama paket. Paket ini diekstraksi ke direktori kerja.
CatatanUntuk informasi lebih lanjut tentang jenis sumber daya yang dapat Anda unggah ke MaxCompute, lihat Sumber Daya.
Konfigurasikan parameter
spark.executorEnv.PYTHONPATH=.Impor file Python utama ke jalur yang ditentukan oleh spark.executorEnv.PYTHONPATH=.