Topik ini menjelaskan algoritma dan sintaksis yang digunakan untuk mendeteksi anomali pada data deret waktu.
Mesin dan versi yang berlaku
Sintaksis deteksi anomali deret waktu hanya berlaku untuk LindormTSDB dan didukung oleh semua versi LindormTSDB.
Batasan
Sintaksis deteksi anomali deret waktu harus digunakan bersama dengan klausa SAMPLE BY.
Ikhtisar
Deteksi anomali deret waktu menggunakan algoritma deteksi anomali online yang dikembangkan oleh Akademi DAMO untuk mengidentifikasi titik-titik abnormal dalam data deret waktu. Selama proses deteksi, algoritma terus mempelajari karakteristik data seperti tren atau periode untuk mendeteksi anomali pada titik-titik baru yang dimasukkan. Sebagai contoh, jika nilai suatu titik baru secara signifikan berbeda dari titik lainnya, algoritma akan menganggap titik tersebut sebagai potensi anomali.
Anda dapat menggunakan deteksi anomali deret waktu dengan klausa SAMPLE BY melalui metode berikut:
Gunakan klausa
SAMPLE BY 0untuk mendeteksi setiap titik data di seluruh deret waktu. Untuk detail lebih lanjut, lihat Contoh 1, Contoh 2, dan Contoh 3.Gunakan klausa
SAMPLE BY INTERVALuntuk menentukan interval downsampling dan menerapkan operator downsampling bertingkat seperti MIN, MAX, AVG, COUNT, dan SUM.PentingNilai INTERVAL tidak boleh 0.
Untuk informasi lebih lanjut, lihat Contoh 4.
Gunakan klausa
SAMPLE BY 0dan operator downsampling bertingkat seperti LATEST, DELTA, dan RATE untuk menanyakan data yang berbeda. Untuk detail lebih lanjut, lihat Contoh 5.
Sintaksis
select_sample_by_statement ::= SELECT ( select_clause )
FROM table_identifier
WHERE where_clause
SAMPLE BY 0
select_clause ::= selector [ AS identifier ] ( ',' selector [ AS identifier ] )
selector ::= tag_identifier, | time | anomaly_detect '(' field_identifier ',' algo_identifier | model_identifier [ ',' options] ')'
where_clause ::= relation ( AND relation )* (OR relation)*
relation ::= ( field_identifier| tag_identifier, ) operator term
operator ::= '=' | '<' | '>' | '<=' | '>=' | '!=' | IN | CONTAINS | CONTAINS KEYDalam sintaksis, anomaly_detect menunjukkan fungsi deteksi anomali. Tabel berikut menjelaskan parameter yang dapat dikonfigurasikan.
Parameter | Deskripsi |
field_identifier | Nama kolom bidang. Catatan Data di kolom bidang yang ditentukan tidak boleh bertipe VARCHAR atau BOOLEAN. |
algo_identifier | Nama algoritma yang digunakan untuk mendeteksi anomali. Algoritma deteksi anomali online yang dikembangkan oleh Akademi DAMO didukung.
Catatan Parameter algo_identifier berlaku untuk skenario di mana pembelajaran mesin dalam database tidak diaktifkan dan anomali terkait data deret waktu harus dideteksi. |
model_identifier | Nama model yang digunakan untuk mendeteksi anomali. Catatan
|
options | Opsi yang digunakan untuk menyesuaikan efek deteksi. Parameter ini opsional. Konfigurasikan opsi dalam format |
Kategori
Tabel berikut menjelaskan algoritma deteksi anomali yang didukung oleh LindormTSDB beserta skenario aplikasinya.
Algoritma | Skenario |
esd |
|
nsigma |
Catatan Kami merekomendasikan agar Anda tidak menggunakan algoritma ini untuk mendeteksi sejumlah kecil titik abnormal yang nilainya secara signifikan berbeda dari titik lainnya. Dalam hal ini, hasil deteksi yang dikembalikan oleh algoritma ini mungkin tidak akurat. |
ttest |
|
Incremental STL with ESD (istl-esd) | Algoritma ini berlaku untuk mendeteksi anomali dalam data periodik. Algoritma istl-esd adalah algoritma Incremental STL yang dikembangkan oleh Akademi DAMO. Algoritma Incremental STL dapat menguraikan data penambahan periodik menjadi komponen periodik, komponen tren, dan komponen residu. Algoritma istl-esd mengintegrasikan algoritma Incremental STL dengan algoritma esd. Algoritma Incremental STL digunakan untuk menguraikan data penambahan periodik, dan algoritma esd digunakan untuk mendeteksi anomali dalam komponen residu yang diuraikan dari data periodik. Algoritma esd dapat mendeteksi puncak non-periodik berdasarkan komponen residu yang diuraikan. |
Incremental STL with Nsigma (istl-nsigma) | Algoritma ini berlaku untuk mendeteksi anomali dalam data periodik. Algoritma Incremental STL dapat menguraikan data penambahan periodik menjadi komponen periodik, komponen tren, dan komponen residu. Algoritma istl-nsigma mengintegrasikan algoritma Incremental STL dengan algoritma nsigma. Algoritma Incremental STL digunakan untuk menguraikan data penambahan periodik, dan algoritma nsigma digunakan untuk mendeteksi anomali dalam komponen residu yang diuraikan dari data periodik. Algoritma nsigma dapat mendeteksi puncak non-periodik berdasarkan komponen residu yang diuraikan. |
Gambar-gambar berikut menunjukkan skenario aplikasi dari berbagai algoritma.
esd: Algoritma ini mendeteksi setiap titik data dalam deret waktu dan cocok untuk skenario dengan sejumlah kecil titik abnormal di antara banyak titik normal dengan nilai stabil.
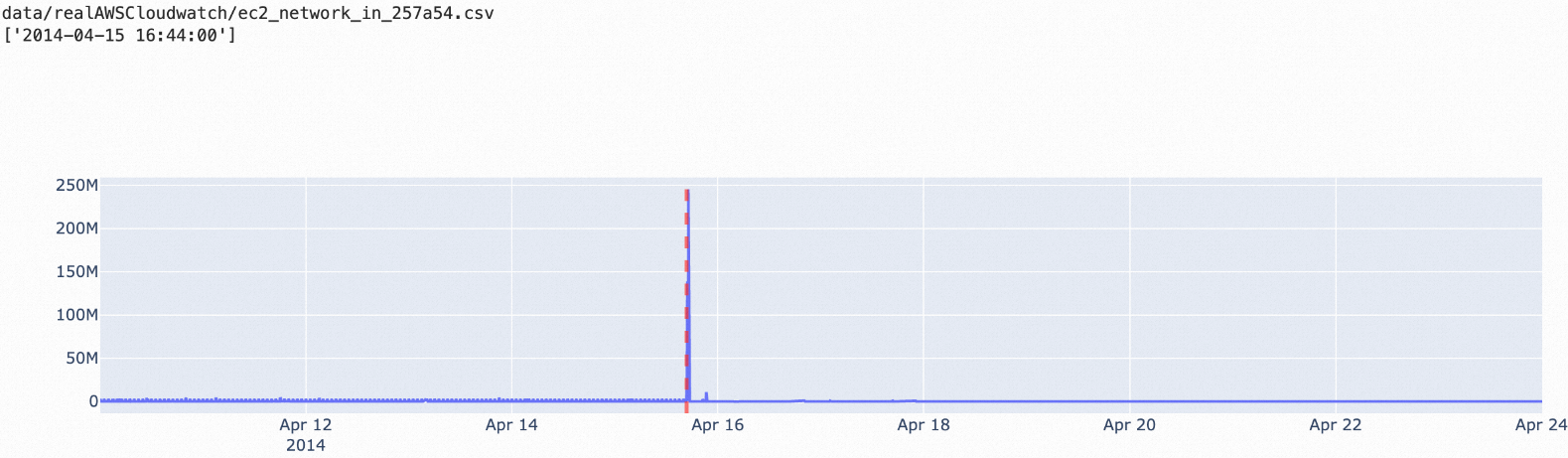
nsigma: Algoritma ini mendeteksi setiap titik data dalam deret waktu dan cocok untuk skenario di mana nilai-nilai titik abnormal berbeda signifikan dari nilai rata-rata historis. Parameter n dapat dikonfigurasi untuk menyesuaikan toleransi perbedaan.
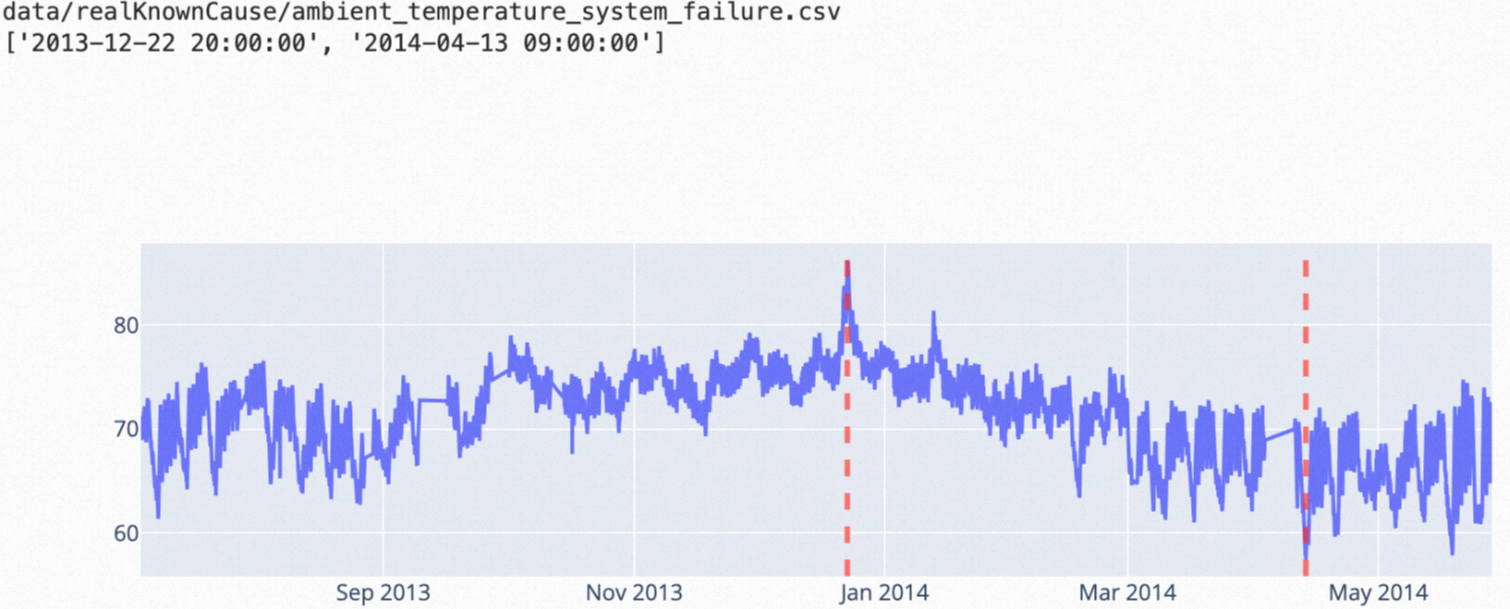
ttest: Algoritma ini mendeteksi anomali pada data deret waktu dalam jendela waktu tertentu dan cocok untuk skenario di mana nilai rata-rata metrik berubah secara signifikan antara dua jendela waktu berturut-turut.
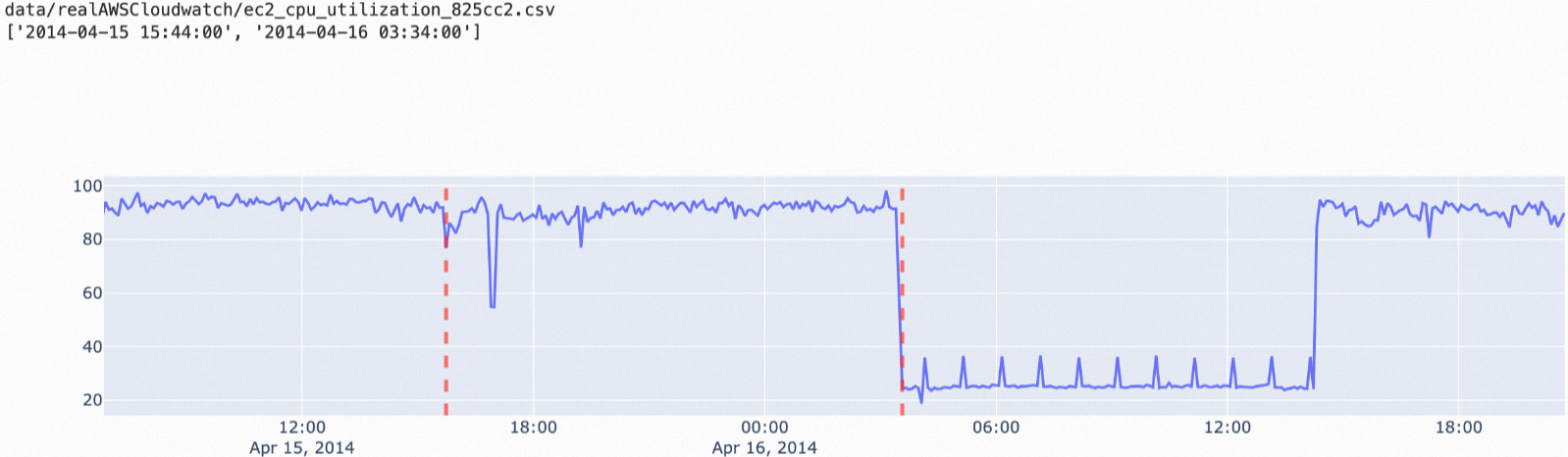
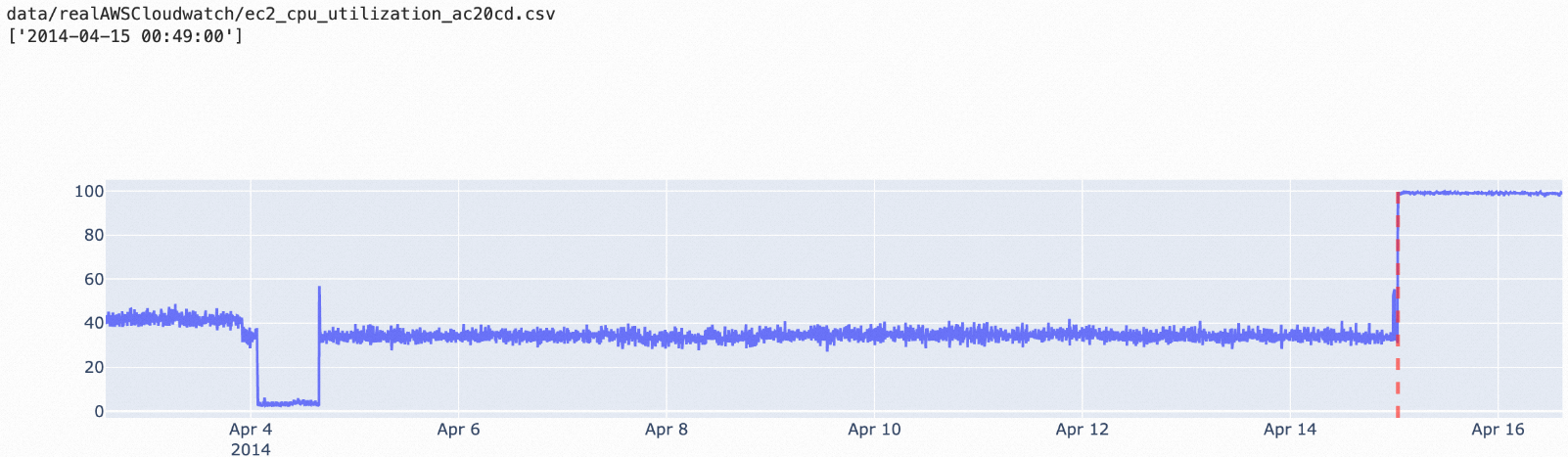
istl-esd: Algoritma ini digunakan untuk mendeteksi anomali dalam data deret waktu periodik. Algoritma ini menghilangkan komponen periodik dari data asli, lalu menggunakan algoritma esd untuk mendeteksi anomali. Algoritma istl-esd cocok untuk skenario di mana terdapat sejumlah kecil titik data abnormal di antara banyak titik data periodik normal dengan nilai stabil.
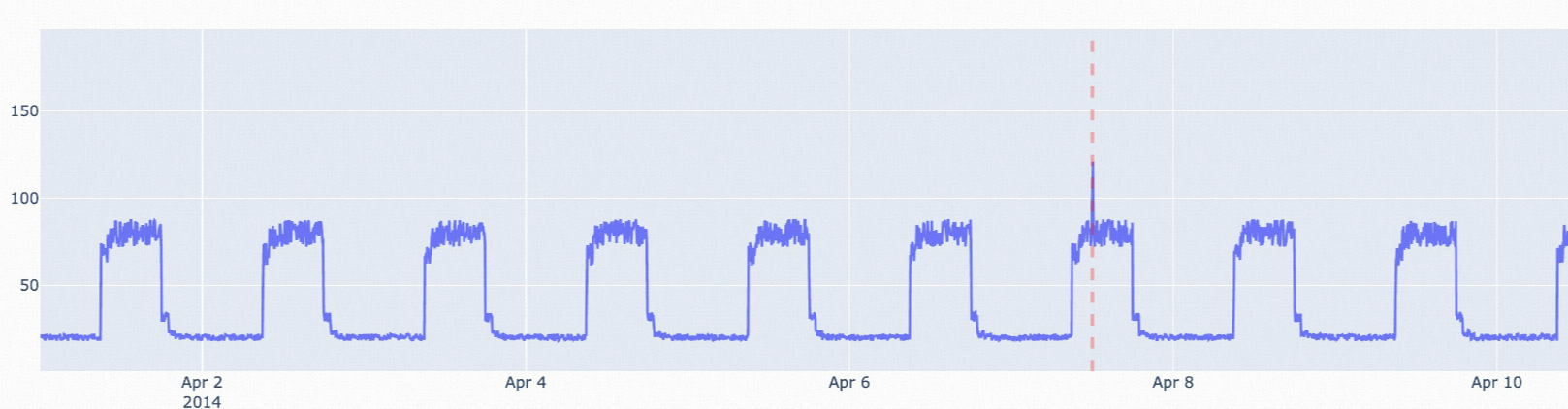
istl-nsigma: Algoritma ini mendeteksi anomali dalam data deret waktu periodik dengan menghilangkan komponen periodik dan menggunakan algoritma nsigma. Cocok untuk skenario di mana nilai-nilai titik abnormal berbeda signifikan dari nilai rata-rata historis.
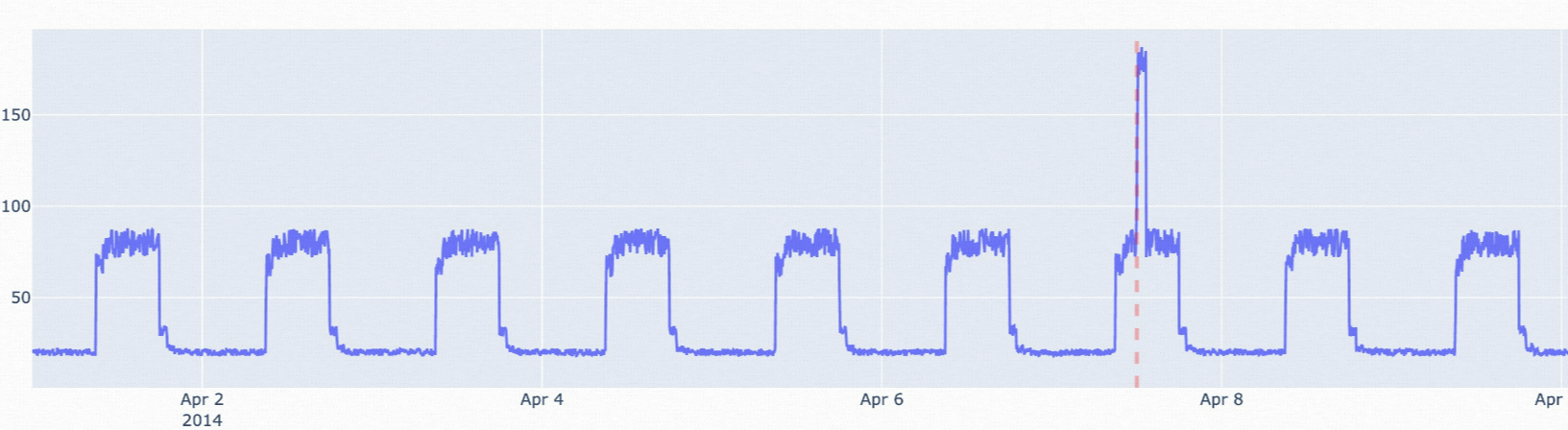
Parameter
Anda dapat mengonfigurasi parameter untuk algoritma deteksi anomali yang digunakan. Parameter ini mencakup parameter umum, pelatihan, dan inferensi. Parameter opsional options dapat ditentukan untuk menyesuaikan kinerja algoritma.
Parameter umum, pelatihan, dan inferensi dikonfigurasikan dalam daftar yang sama. Contohnya, konfigurasi untuk algoritma ttest dapat ditulis sebagai:
lenDetectWindow=100,adhoc_stat=true.Untuk panduan lebih lanjut tentang penyetelan parameter, lihat Penyetelan parameter untuk algoritma statistik dan Penyetelan parameter untuk algoritma dekomposisi.
Parameter umum
Parameter umum mengontrol debugging, diagnosis, dan perilaku lain selama deteksi anomali. Parameter ini berlaku untuk semua algoritma deteksi anomali yang didukung. Tabel berikut menjelaskan parameter umum yang dapat dikonfigurasikan.
Parameter | Tipe | Nilai default | Deskripsi |
verbose | BOOLEAN | FALSE | Menentukan apakah akan mengembalikan informasi rinci dan mengidentifikasi hasil deteksi kolom yang ditentukan. Informasi yang dikembalikan bervariasi dengan algoritma yang Anda gunakan. Nilai valid:
Jika Anda menetapkan parameter ini ke |
adhoc_state | BOOLEAN | FALSE | Menentukan apakah status deteksi anomali algoritma hanya tersedia dalam kueri saat ini. Untuk informasi lebih lanjut tentang status deteksi anomali, lihat Status deteksi pengecualian. |
direction | VARCHAR | UP | Jenis anomali yang ingin Anda deteksi. Nilai valid:
|
Parameter Pelatihan
Parameter pelatihan menentukan model yang digunakan untuk mendeteksi anomali. Nilai parameter ini akan dihapus setelah LindormTSDB di-restart, sehingga perlu dikonfigurasi ulang untuk melatih model. Model dilatih secara real-time untuk beradaptasi dengan karakteristik data deret waktu.
Perhatikan hal berikut saat mengonfigurasi parameter pelatihan:
Nama parameter tidak peka terhadap huruf besar atau kecil.
Nilai parameter dapat berupa digit atau string, dan tidak boleh NULL.
Nilai parameter harus berada dalam rentang tertentu.
Algoritma | Parameter | Tipe | Nilai valid | Deskripsi |
esd | compression | INTEGER | Bilangan bulat positif. Nilai valid: | Kompleksitas spasial dari struktur data dalam algoritma. Nilai parameter yang lebih besar menunjukkan bahwa algoritma menggunakan lebih banyak memori selama deteksi dan mengembalikan hasil yang lebih akurat. |
lenHistoryWindow | INTEGER | Nilai valid: bilangan bulat positif yang sama dengan atau lebih besar dari 20. Nilai default: null. | Panjang jendela waktu referensi. Jika Anda menentukan jendela waktu referensi yang pendek, hanya titik data terbaru dalam jendela waktu yang digunakan sebagai referensi selama deteksi. Jika Anda mengatur parameter ini ke null, semua titik data yang dimasukkan setelah deteksi pertama digunakan sebagai referensi. | |
nsigma | lenHistoryWindow | INTEGER | Nilai valid: bilangan bulat positif yang sama dengan atau lebih besar dari 20. Nilai default: null. | Panjang jendela waktu referensi. Jika Anda menentukan jendela waktu referensi yang pendek, hanya titik data terbaru dalam jendela waktu yang digunakan sebagai referensi selama deteksi. Jika Anda mengatur parameter ini ke null, semua titik data yang dimasukkan setelah deteksi pertama digunakan sebagai referensi. |
ttest | lenDetectWindow | INTEGER | Bilangan bulat positif. Nilai default: 10. | Panjang jendela waktu terbaru di mana Anda ingin mendeteksi anomali. |
lenHistoryWindow | INTEGER | Nilai valid: bilangan bulat positif yang sama dengan atau lebih besar dari 20. Nilai default: 100. | Panjang jendela waktu referensi. Jika Anda menentukan jendela waktu referensi yang pendek, hanya titik data terbaru dalam jendela waktu yang digunakan sebagai referensi selama deteksi. Jika Anda mengatur parameter ini ke Catatan Nilai parameter ini harus lebih besar dari nilai lenDetectWindow. | |
istl-esd | frequency | VARCHAR | String yang terdiri dari digit dan unit waktu. Contoh: 5M, 24H, dan 1D. Unit waktu yang valid:
| Frekuensi pengumpulan data deret waktu. Misalnya, jika satu titik data deret waktu dikumpulkan per jam, atur parameter ini ke Penting
|
periods | VARCHAR | String yang terdiri dari digit dan unit waktu. Contoh: 5M, 24H, dan 1D. Unit waktu yang valid:
| Total panjang periode data periodik. Anda dapat menggunakan indeks untuk menentukan beberapa panjang periode. Contoh: Catatan Jika parameter ini tidak ditentukan, algoritma secara otomatis menghitung periode. | |
esd.* | N/A | Parameter pelatihan yang diperlukan untuk mendefinisikan algoritma esd. Parameter ini sama dengan parameter pelatihan yang dijelaskan di bagian esd tabel ini. Anda dapat menambahkan awalan esd. ke parameter pelatihan algoritma esd untuk mengonfigurasi parameter ini. Contoh: | ||
istl-nsigma | frequency | VARCHAR | String yang terdiri dari digit dan unit waktu. Contoh: 5M, 24H, dan 1D. Unit waktu yang valid:
| Frekuensi pengumpulan data deret waktu. Misalnya, jika satu titik data deret waktu dikumpulkan per jam, atur parameter ini ke Penting
|
periods | VARCHAR | String yang terdiri dari digit dan unit waktu. Contoh: 5M, 24H, dan 1D. Unit waktu yang valid:
| Total panjang periode data periodik. Anda dapat menggunakan indeks untuk menentukan beberapa panjang periode. Contoh: Catatan Jika parameter ini tidak ditentukan, algoritma secara otomatis menghitung periode. | |
nsigma.* | N/A | Parameter pelatihan yang diperlukan untuk mendefinisikan algoritma nsigma. Parameter ini sama dengan parameter pelatihan yang dijelaskan di bagian nsigma tabel ini. Anda dapat menambahkan awalan nsigma. ke parameter pelatihan algoritma nsigma untuk mengonfigurasi parameter ini. Contoh: | ||
Parameter Inferensi
Parameter inferensi hanya berlaku selama deteksi anomali dan tidak peka terhadap huruf besar atau kecil.
Algoritma | Parameter | Tipe | Nilai valid | Deskripsi |
esd | alpha | DOUBLE | Nilai default: 0,1. Nilai valid: | Tingkat sensitivitas deteksi anomali. Nilai parameter yang lebih besar menunjukkan bahwa algoritma lebih sensitif terhadap anomali dan melaporkan lebih banyak anomali. |
direction | VARCHAR | Nilai default: Up. | Jenis anomali yang ingin Anda deteksi.
| |
maxAnomalyRatio | DOUBLE | Nilai default: 0,3. Nilai valid: | Rasio maksimum berdasarkan mana anomali dideteksi. Sebagai contoh, jika Anda mengatur maxAnomalyRatio menjadi 0,3 dan direction menjadi Up, titik data yang nilainya kurang dari persentil ke-70 tidak akan dideteksi sebagai anomali.
| |
warmupCount | INTEGER | Bilangan bulat positif. Nilai default: 20. | Jumlah minimum titik data yang diperlukan agar algoritma mulai melaporkan anomali. Sebagai contoh, jika Anda mengatur parameter ini ke 20, algoritma tidak akan melaporkan anomali ketika jumlah titik data yang perlu dideteksi kurang dari 20. | |
nsigma | n | DOUBLE | Bilangan floating-point bukan nol. Nilai default: 3,0. |
|
warmupCount | INTEGER | Bilangan bulat positif. Nilai default: 20. | Jumlah minimum titik data yang diperlukan agar algoritma mulai melaporkan anomali. Sebagai contoh, jika Anda mengatur parameter ini ke 20, algoritma tidak akan melaporkan anomali ketika jumlah titik data yang perlu dideteksi kurang dari 20. | |
ttest | alpha | DOUBLE | Nilai default: 0,05. Nilai valid: | Tingkat sensitivitas deteksi anomali. Nilai parameter yang lebih besar menunjukkan bahwa algoritma lebih sensitif terhadap anomali dan melaporkan lebih banyak anomali. |
direction | VARCHAR | Nilai default: Up. | Jenis anomali yang ingin Anda deteksi.
| |
istl-esd | esd.* | N/A | Parameter inferensi yang diperlukan untuk mendefinisikan algoritma esd. Parameter ini sama dengan parameter inferensi yang dijelaskan dalam bagian esd tabel ini. Anda dapat menambahkan awalan | |
istl-nsigma | nsigma.* | N/A | Mendefinisikan parameter inferensi yang diperlukan oleh algoritma nsigma. Untuk informasi lebih lanjut, lihat Parameter inferensi algoritma nsigma. Anda dapat menambahkan awalan | |
Contoh
Contoh 1: Gunakan algoritma esd untuk mendeteksi anomali dalam data suhu pada rentang waktu tertentu di tabel deret waktu bernama sensor.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;Hasil berikut dikembalikan:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | | F07A1261 | south-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:02+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:03+08:00 | false | +-----------+----------+---------------------------+---------------+Contoh 2: Gunakan algoritma esd untuk mendeteksi anomali dalam data suhu perangkat F07A1260 pada rentang waktu tertentu di tabel sensor.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;Hasil berikut dikembalikan:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+Contoh 3: Gunakan algoritma esd dengan konfigurasi parameter untuk mendeteksi anomali dalam data suhu perangkat F07A1260 pada rentang waktu tertentu di tabel sensor.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd', 'lenHistoryWindow=30,maxAnomalyRatio=0.1') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;Hasil berikut dikembalikan:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+Contoh 4: Gunakan operator downsampling bertingkat MAX dalam pernyataan dan tentukan interval downsampling sebagai 1 menit.
SELECT time, anomaly_detect(max(temperature), 'esd') AS ad_result, max(temperature) AS rawVal FROM sensor SAMPLE BY 1m;Hasil berikut dikembalikan:
+---------------------------+-----------+-------------+ | time | ad_result | rawVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | null | 923091.3175 | | 2022-04-11T08:00:00+08:00 | null | 8035700 | | 2022-04-11T09:00:00+08:00 | null | 8035690.25 | | 2022-04-11T10:00:00+08:00 | null | 3306277.545 | | 2022-04-11T11:00:00+08:00 | null | 5921167.787 | | 2022-04-11T12:00:00+08:00 | null | 833541.304 | +---------------------------+-----------+-------------+Contoh 5: Gunakan operator non-downsampling bertingkat LATEST dalam pernyataan dan tentukan interval downsampling sebagai 0.
SELECT time, anomaly_detect(latest(temperature), 'esd') AS ad_result, latest(temperature) AS latestVal FROM sensor SAMPLE BY 0;Hasil berikut dikembalikan:
+---------------------------+-----------+-------------+ | time | ad_result | latestVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | false | 923091.3175 | | 2022-04-13T07:00:00+08:00 | false | 8037506.75 | | 2022-04-13T07:00:00+08:00 | false | 50490.2 | +---------------------------+-----------+-------------+