Jika penulisan atau pembaruan data ke tabel Hologres Anda lebih lambat dari yang diharapkan, topik ini dapat membantu Anda mengidentifikasi penyebabnya. Penyebab umum meliputi pembacaan data hulu yang lambat atau bottleneck sumber daya Hologres. Setelah penyebab teridentifikasi, Anda dapat menerapkan metode penyetelan yang sesuai untuk meningkatkan performa tulis dan pembaruan.
Informasi latar belakang
Hologres adalah mesin gudang data real-time satu atap yang mendukung penulisan dan pembaruan real-time berkinerja tinggi untuk volume data besar. Kemampuan ini memenuhi persyaratan kinerja tinggi dan latensi rendah dalam skenario data besar.
Prinsip dasar
Sebelum mempelajari metode penyetelan untuk penulisan dan pembaruan, penting untuk memahami prinsip dasarnya. Pengetahuan ini membantu Anda memperkirakan performa penulisan berbagai mode tulis dengan lebih baik.
Performa penulisan dan pembaruan untuk format penyimpanan tabel yang berbeda.
Untuk penulisan atau pembaruan kolom penuh, peringkat performanya sebagai berikut.
Row-oriented > Column-oriented > Row-column hybrid.Untuk penulisan atau pembaruan sebagian kolom, peringkat performanya sebagai berikut.
Row-oriented > Row-column hybrid > Column-oriented.
Performa berbagai mode tulis.
Berikut adalah mode tulis yang didukung.
Mode tulis
Deskripsi
Insert
Menulis data dalam mode append-only. Tabel sink tidak memiliki primary key (PK).
InsertOrIgnore
Mengabaikan pembaruan selama penulisan. Tabel sink memiliki primary key. Selama penulisan real-time, jika primary key diduplikasi, catatan data berikutnya dibuang.
InsertOrReplace
Menimpa data selama penulisan. Tabel sink memiliki primary key. Selama penulisan real-time, jika primary key diduplikasi, catatan diperbarui berdasarkan primary key tersebut. Jika baris yang ditulis tidak berisi semua kolom, kolom yang hilang diisi dengan NULL.
InsertOrUpdate
Memperbarui data selama penulisan. Tabel sink memiliki primary key. Selama penulisan real-time, jika primary key diduplikasi, catatan diperbarui berdasarkan primary key tersebut. Ini mencakup pembaruan baris penuh dan pembaruan sebagian kolom. Untuk pembaruan sebagian kolom, jika baris yang ditulis tidak berisi semua kolom, kolom yang hilang tidak diperbarui.
Untuk tabel berorientasi kolom, performa berbagai mode tulis diberi peringkat sebagai berikut.
Performa tertinggi ketika tabel sink tidak memiliki primary key.
Ketika tabel sink memiliki primary key:
InsertOrIgnore > InsertOrReplace >= InsertOrUpdate (full row) > InsertOrUpdate (partial column).
Untuk tabel berorientasi baris, performa berbagai mode tulis diberi peringkat sebagai berikut.
InsertOrReplace = InsertOrUpdate (full row) >= InsertOrUpdate (partial column) >= InsertOrIgnore.
Untuk tabel dengan binary logging (Binlog) diaktifkan, performa penulisan dan pembaruan diberi peringkat sebagai berikut.
Row-oriented > Row-column hybrid > Column-oriented.
Identifikasi bottleneck tulis
Saat menulis atau memperbarui data tabel, jika performa tulis lambat, Anda dapat memeriksa metrik CPU Usage di Konsol Manajemen untuk mengidentifikasi bottleneck performa:
Penggunaan CPU rendah.
Ini menunjukkan bahwa sumber daya Hologres tidak dimanfaatkan sepenuhnya. Bottleneck performa bukan pada sisi Hologres. Periksa masalah seperti pembacaan data hulu yang lambat.
Penggunaan CPU tinggi (konsisten di 100%).
Ini menunjukkan bahwa telah tercapai bottleneck sumber daya Hologres. Anda dapat menangani masalah ini dengan cara berikut.
Gunakan metode penyetelan dasar untuk memeriksa apakah pengaturan dasar yang tidak tepat menyebabkan beban sumber daya tinggi dan memengaruhi performa tulis. Untuk informasi lebih lanjut, lihat Metode penyetelan dasar.
Setelah menerapkan metode penyetelan dasar, Anda dapat menggunakan metode penyetelan lanjutan untuk saluran tulis, seperti Flink dan Data Integration, serta untuk Hologres itu sendiri. Hal ini membantu Anda lebih lanjut mengidentifikasi dan mengatasi bottleneck tulis. Untuk informasi lebih lanjut, lihat Menyetel tulis Flink, Menyetel Data Integration, dan Metode penyetelan lanjutan.
Kueri dapat memengaruhi tulis. Menjalankan keduanya secara bersamaan dapat menyebabkan penggunaan CPU tinggi. Anda dapat memeriksa log kueri lambat untuk mengidentifikasi konsumsi CPU oleh kueri yang berjalan bersamaan. Jika kueri memengaruhi tulis, pertimbangkan untuk mengonfigurasi penerapan high availability (HA) dengan pemisahan baca/tulis untuk instans Anda. Untuk informasi lebih lanjut, lihat Menerapkan instans primer dan sekunder untuk pemisahan baca/tulis (shared storage).
Jika performa tulis masih belum memenuhi ekspektasi Anda setelah mencoba semua metode penyetelan, Anda dapat melakukan scale out instans Hologres sesuai kebutuhan.
Metode penyetelan dasar
Hologres biasanya memberikan performa tulis yang sangat tinggi. Jika performa selama penulisan data tidak memenuhi ekspektasi Anda, Anda dapat menggunakan metode berikut untuk penyetelan rutin.
Hindari menggunakan jaringan publik untuk mengurangi overhead jaringan.
Hologres menyediakan jenis jaringan seperti VPC, jaringan klasik, dan jaringan publik. Untuk informasi tentang skenario masing-masing jenis, lihat Konfigurasi jaringan. Saat menulis data, terutama saat menghubungkan ke Hologres dari aplikasi menggunakan Java Database Connectivity (JDBC) atau psql, gunakan koneksi VPC alih-alih koneksi jaringan publik. Jaringan publik memiliki batas trafik dan kurang stabil dibandingkan VPC.
Gunakan Fixed Plan untuk tulis bila memungkinkan.
Gambar berikut menunjukkan alur eksekusi pernyataan SQL di Hologres. Untuk informasi lebih lanjut tentang prinsipnya, lihat Execution engine.
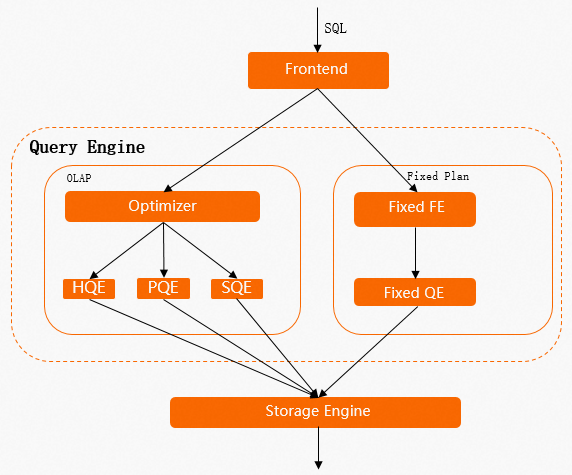
Jika pernyataan SQL digunakan untuk tulis OLAP (online analytical processing) normal, ia mengikuti jalur di sebelah kiri. Pernyataan tersebut melewati komponen seperti query optimizer (QO) dan query engine (QE). Saat data ditulis atau diperbarui, kunci ditempatkan pada seluruh tabel. Ini disebut table lock. Jika Anda menjalankan perintah
INSERT,UPDATE, atauDELETEsecara konkuren, pernyataan SQL tersebut saling menunggu untuk melepaskan kunci, yang menyebabkan latensi tinggi.Jika pernyataan SQL digunakan untuk point query atau point write, ia mengikuti jalur di sebelah kanan, yang disebut Fixed Plan. Kueri yang menggunakan Fixed Plan cukup sederhana sehingga menghindari overhead komponen seperti QO. Oleh karena itu, mereka menggunakan row locks untuk tulis atau pembaruan. Hal ini sangat meningkatkan konkurensi dan performa kueri.
Oleh karena itu, saat mengoptimalkan performa tulis atau pembaruan, prioritaskan agar kueri Anda menggunakan Fixed Plan.
Memastikan kueri menggunakan Fixed Plan
Pernyataan SQL harus memenuhi kriteria tertentu untuk menggunakan Fixed Plan. Skenario umum di mana Fixed Plan tidak digunakan meliputi hal berikut:
Menggunakan sintaks
insert on conflictuntuk insert dan update multi-baris.INSERT INTO test_upsert(pk1, pk2, col1, col2) VALUES (1, 2, 5, 6), (2, 3, 7, 8) ON CONFLICT (pk1, pk2) DO UPDATE SET col1 = excluded.col1, col2 = excluded.col2;Menggunakan sintaks
insert on conflictuntuk pembaruan sebagian di mana kolom tabel sink tidak sesuai dengan kolom data yang dimasukkan.Tabel sink berisi kolom bertipe SERIAL.
Tabel sink memiliki properti
Defaultyang diatur.Operasi
updateataudeleteberdasarkan primary key. Contoh:update table set col1 = ?, col2 = ? where pk1 = ? and pk2 = ?;.Menggunakan tipe data yang tidak didukung oleh Fixed Plan.
Jika pernyataan SQL tidak menggunakan Fixed Plan, metrik pemantauan
Real-time Import RPSdi Konsol Manajemen menampilkan jenis insert sebagaiINSERT.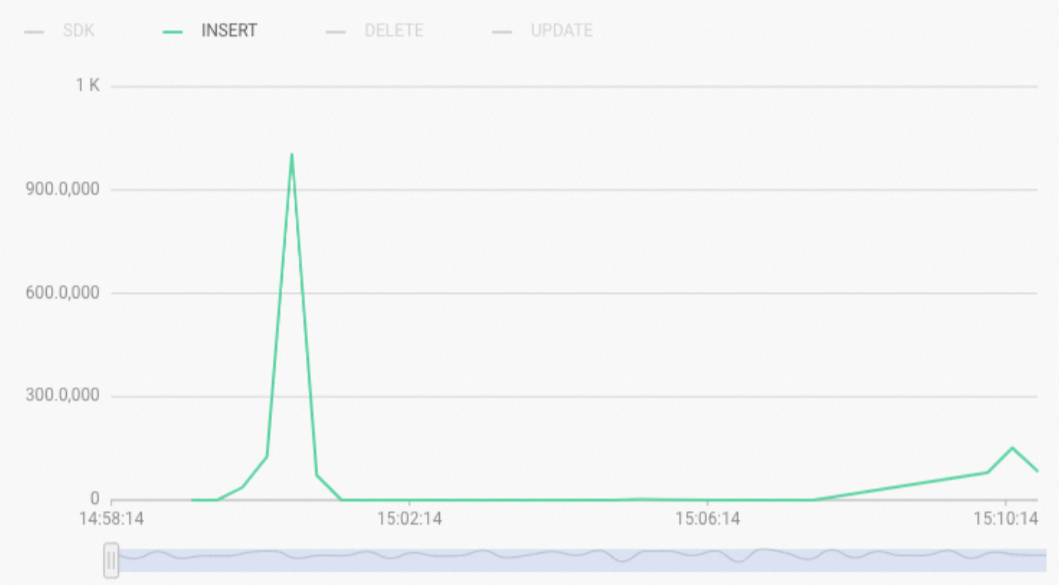 Untuk pernyataan SQL yang tidak menggunakan Fixed Plan, jenis execution engine-nya adalah HQE atau PQE. Dalam kebanyakan kasus, jenis engine untuk operasi tulis adalah HQE. Oleh karena itu, jika Anda menemukan bahwa operasi tulis atau pembaruan lambat, Anda dapat menjalankan pernyataan contoh berikut untuk mengkueri log kueri lambat dan memeriksa jenis execution engine kueri tersebut (`engine_type`).
Untuk pernyataan SQL yang tidak menggunakan Fixed Plan, jenis execution engine-nya adalah HQE atau PQE. Dalam kebanyakan kasus, jenis engine untuk operasi tulis adalah HQE. Oleh karena itu, jika Anda menemukan bahwa operasi tulis atau pembaruan lambat, Anda dapat menjalankan pernyataan contoh berikut untuk mengkueri log kueri lambat dan memeriksa jenis execution engine kueri tersebut (`engine_type`).-- Contoh ini mengkueri operasi insert, update, dan delete yang tidak menggunakan Fixed Plan dalam 3 jam terakhir. SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type ORDER BY query_start DESC LIMIT 500;Untuk meningkatkan performa, tulis ulang kueri dengan jenis engine HQE menjadi pernyataan SQL SDK yang memenuhi kriteria Fixed Plan. Perhatikan parameter GUC berikut. Kami menyarankan Anda mengaktifkannya di tingkat database. Untuk informasi lebih lanjut tentang cara menggunakan Fixed Plan, lihat Gunakan Fixed Plan untuk mempercepat eksekusi SQL.
Skenario
Pengaturan GUC
Deskripsi
Dukungan tulis Fixed Plan untuk beberapa catatan yang menggunakan sintaks
insert on conflict.alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_multi_values =on;Kami menyarankan Anda mengaktifkannya di tingkat database.
Dukungan tulis Fixed Plan untuk tabel yang berisi kolom bertipe SERIAL.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_autofill_series =on;Kami tidak menyarankan menetapkan tipe SERIAL untuk tabel karena dapat menurunkan performa tulis. Parameter GUC ini diatur ke
onsecara default di Hologres V1.3.25 dan versi selanjutnya.Dukungan tulis Fixed Plan untuk kolom dengan properti Default.
Di Hologres V1.3 dan versi selanjutnya, jika Anda menggunakan sintaks
insert on conflictuntuk menulis data yang berisi bidang dengan properti Default, operasi tulis secara default menggunakan Fixed Plan.Kami tidak menyarankan menetapkan properti Default untuk tabel karena dapat menurunkan performa tulis. Hologres V1.1 tidak mendukung Fixed Plan untuk bidang dengan properti Default. Fitur ini didukung di Hologres V1.3 dan versi selanjutnya.
Operasi UPDATE berdasarkan primary key.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_update =on;Parameter GUC ini diatur ke
onsecara default di Hologres V1.3.25 dan versi selanjutnya.Operasi DELETE berdasarkan primary key.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_delete =on;Parameter GUC ini diatur ke
onsecara default di Hologres V1.3.25 dan versi selanjutnya.Jika pernyataan SQL menggunakan Fixed Plan, jenis metrik
Real-time Import RPSadalahSDK, seperti yang ditunjukkan pada gambar berikut. Di log kueri lambat,engine_typedari pernyataan SQL jugaSDK.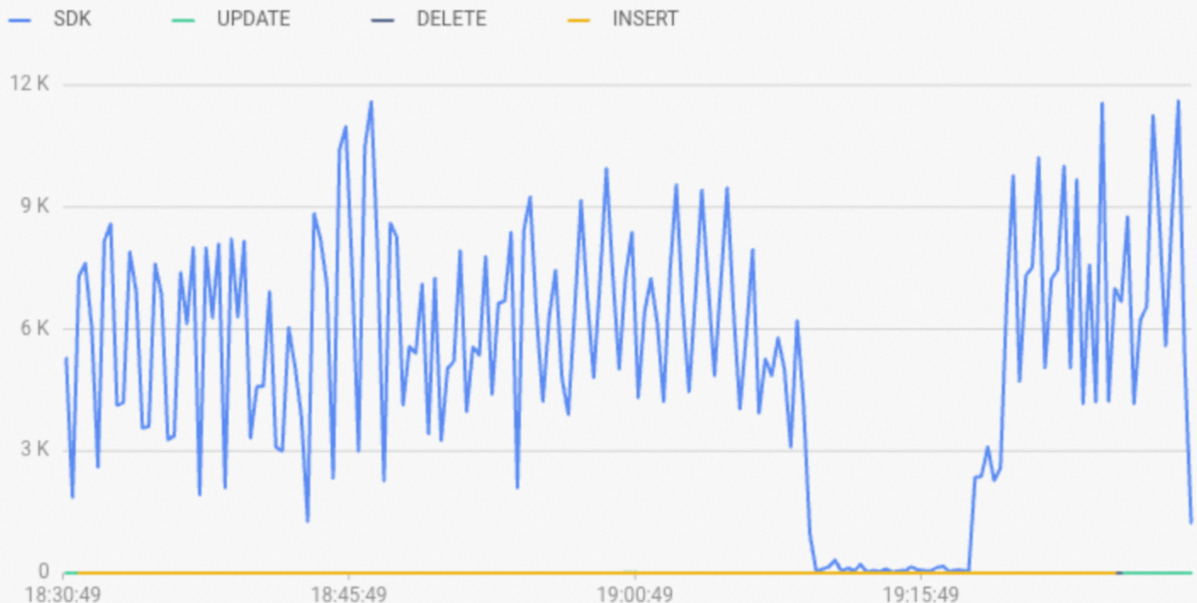
Performa tulis tetap lambat setelah Fixed Plan dieksekusi.
Jika pernyataan SQL sudah menggunakan Fixed Plan tetapi tetap membutuhkan waktu lama untuk dieksekusi, kemungkinan penyebabnya sebagai berikut.
Umumnya, hal ini terjadi ketika sebuah tabel memiliki tulis atau pembaruan SDK Fixed Plan dan tulis atau pembaruan HQE secara bersamaan. HQE menggunakan table locks, yang dapat menyebabkan tulis SDK menunggu kunci dan menghasilkan waktu eksekusi yang lama. Anda dapat menjalankan pernyataan SQL berikut untuk memeriksa apakah tabel memiliki operasi HQE. Kemudian, Anda dapat mengoptimalkannya menjadi pernyataan SQL SDK berdasarkan kebutuhan bisnis Anda. Anda juga dapat menggunakan Query Insights di HoloWeb untuk dengan cepat mengidentifikasi apakah kueri Fixed Plan dipengaruhi oleh kunci HQE. Untuk informasi lebih lanjut, lihat Query Insights.
-- Mengkueri operasi insert, update, dan delete pada tabel yang tidak menggunakan Fixed Plan dalam 3 jam terakhir. SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type AND table_write = '<table_name>' ORDER BY query_start DESC LIMIT 500;Jika semua tulis ke tabel adalah tulis SDK tetapi tetap lambat, periksa metrik
CPU Usage. Jika penggunaan CPU konsisten tinggi, instans mungkin telah mencapai bottleneck sumber daya. Dalam hal ini, Anda dapat melakukan scale out instans sesuai kebutuhan.
Mengaktifkan Binlog mengurangi throughput tulis.
Hologres Binlog mencatat perubahan data, seperti INSERT, UPDATE, dan DELETE. Binlog mencatat secara lengkap perubahan untuk setiap baris. Saat Anda mengaktifkan Binlog untuk sebuah tabel, pertimbangkan contoh pernyataan UPDATE berikut:
update tbl set body =new_body where id='1';Karena Binlog mencatat data untuk semua bidang dalam satu baris, Binlog perlu melakukan point query pada seluruh baris tabel tujuan menggunakan bidang filter (bidang
iddalam contoh). Untuk tabel berorientasi kolom, jenis point query ini mengonsumsi lebih banyak sumber daya dibandingkan tabel berorientasi baris. Oleh karena itu, untuk tabel dengan Binlog diaktifkan, performa tulis diberi peringkat sebagai berikut:row-oriented table > column-oriented table.Hindari tulis real-time dan offline konkuren ke tabel yang sama.
Tulis offline, seperti menulis dari MaxCompute ke Hologres, menggunakan table locks. Sebagian besar tulis real-time, seperti dari Flink atau integrasi data DataWorks, adalah tulis Fixed Plan yang menggunakan row locks. Jika Anda melakukan tulis offline dan real-time ke tabel yang sama secara konkuren, tulis offline mendapatkan table lock. Tulis real-time kemudian harus menunggu kunci tersebut, yang mengakibatkan performa tulis lambat. Oleh karena itu, Anda harus menghindari tulis real-time dan offline konkuren ke tabel yang sama.
Menyetel tulis Holo Client atau JDBC
Saat Anda menulis data menggunakan klien seperti Holo Client atau JDBC, Anda dapat menggunakan metode berikut untuk meningkatkan performa tulis.
Tulis data dalam batch.
Saat menulis data menggunakan klien, menulis dalam batch memberikan throughput lebih tinggi dibandingkan menulis catatan tunggal. Metode ini meningkatkan performa tulis.
Holo Client secara otomatis membuat batch data. Kami menyarankan Anda menggunakan parameter konfigurasi default untuk Holo Client. Untuk informasi lebih lanjut, lihat Holo Client.
Saat menggunakan JDBC, Anda dapat mengonfigurasi
WriteBatchedInserts=truedalam string koneksi JDBC untuk mengaktifkan batching, seperti yang ditunjukkan pada contoh berikut. Untuk informasi lebih lanjut tentang JDBC, lihat JDBC.jdbc:postgresql://{ENDPOINT}:{PORT}/{DBNAME}?ApplicationName={APPLICATION_NAME}&reWriteBatchedInserts=true
Contoh berikut menunjukkan cara mengonversi pernyataan SQL non-batch menjadi pernyataan SQL batch.
-- Dua pernyataan SQL non-batch insert into data_t values (1, 2, 3); insert into data_t values (2, 3, 4); -- Pernyataan SQL batch insert into data_t values (1, 2, 3), (4, 5, 6); -- Cara lain menulis pernyataan batch insert into data_t select unnest(ARRAY[1, 4]::int[]), unnest(ARRAY[2, 5]::int[]), unnest(ARRAY[3, 6]::int[]);Gunakan mode Prepared Statement untuk menulis data.
Hologres kompatibel dengan ekosistem PostgreSQL. Hologres mendukung mode Prepared Statement berdasarkan protokol ekstensi PostgreSQL. Mode ini menyimpan cache hasil kompilasi SQL di server, yang mengurangi overhead komponen seperti frontend (FE) dan QO serta meningkatkan performa tulis.
Untuk informasi tentang cara menggunakan mode Prepared Statement untuk menulis data dengan JDBC dan Holo Client, lihat JDBC.
Menyetel tulis Flink
Perhatikan poin-poin berikut untuk berbagai jenis tabel.
Tabel sumber Binlog
Saat Flink mengonsumsi data Binlog Hologres, Flink hanya mendukung jumlah terbatas tipe data. Jika Anda menggunakan tipe data yang tidak didukung, seperti SMALLINT, pekerjaan mungkin gagal online, bahkan jika Anda tidak mengonsumsi bidang tersebut. Di Flink engine Ververica Runtime (VVR) 6.0.3-Flink-1.15 dan versi selanjutnya, Anda dapat mengonsumsi data Binlog Hologres dalam mode JDBC. Mode ini mendukung lebih banyak tipe data.
Untuk tabel Hologres dengan Binlog diaktifkan, kami menyarankan Anda menggunakan tabel berorientasi baris. Mengaktifkan Binlog untuk tabel berorientasi kolom mengonsumsi lebih banyak sumber daya dan memengaruhi performa tulis.
Tabel dimensi
Tabel dimensi harus berupa tabel berorientasi baris atau tabel hybrid baris-kolom. Tabel berorientasi kolom memiliki overhead performa tinggi dalam skenario point query.
Saat membuat tabel berorientasi baris, Anda harus menetapkan primary key. Performa lebih baik ketika primary key juga dikonfigurasi sebagai clustering key.
Primary key tabel dimensi harus merupakan bidang yang digunakan dalam klausa `JOIN ON` Flink. Bidang dalam klausa `JOIN ON` juga harus merupakan primary key lengkap tabel. Keduanya harus sesuai secara tepat.
Tabel sink
Untuk penggabungan tabel lebar atau pembaruan sebagian, tabel Hologres yang sesuai harus memiliki primary key. Setiap tabel sink harus mendeklarasikan dan menulis ke bidang primary key. Anda harus menggunakan mode tulis
InsertOrUpdate. Propertiignoredeletesetiap tabel sink harus diatur ketrueuntuk mencegah pesan retraction menghasilkan permintaan DELETE.Dalam skenario penggabungan tabel lebar untuk tabel berorientasi kolom, penggunaan CPU bisa tinggi pada jumlah catatan per detik (RPS) yang tinggi. Kami menyarankan Anda menonaktifkan
Dictionary Encodinguntuk bidang-bidang dalam tabel.Jika tabel sink memiliki primary key, kami menyarankan Anda menetapkan
segment_key. Hal ini membantu menemukan file dasar tempat data berada dengan cepat selama tulis dan pembaruan. Kami menyarankan Anda menggunakan bidang timestamp atau tanggal sebagaisegment_key. Pastikan data dalam bidang ini memiliki korelasi kuat dengan waktu tulis.
Pengaturan parameter Flink yang direkomendasikan.
Nilai default parameter Hologres Connector optimal untuk sebagian besar skenario. Jika terjadi masalah berikut, Anda dapat memodifikasi parameter sesuai kebutuhan.
Latensi tinggi dalam konsumsi Binlog:
Ukuran batch default untuk membaca data Binlog (
binlogBatchReadSize) adalah 100. Jikabyte sizesatu baris kecil, Anda dapat meningkatkan parameter ini untuk mengoptimalkan latensi konsumsi.Performa buruk untuk point query tabel dimensi:
Atur parameter
asyncketrueuntuk mengaktifkan mode asinkron. Mode ini dapat memproses beberapa permintaan dan tanggapan secara konkuren, yang menghilangkan blocking antar permintaan berurutan dan meningkatkan throughput kueri. Namun, mode asinkron tidak menjamin urutan absolut permintaan.Jika tabel dimensi berisi banyak data dan jarang diperbarui, kami menyarankan Anda menggunakan cache tabel dimensi untuk mengoptimalkan performa kueri. Parameter yang sesuai diatur ke
cache = 'LRU'. Nilai defaultcacheSizeadalah 10.000 baris yang konservatif, dan kami menyarankan Anda meningkatkan nilai ini berdasarkan kebutuhan aktual Anda.
Koneksi tidak mencukupi:
connectormenggunakan JDBC secara default. Jika Anda memiliki banyak pekerjaan Flink, Anda mungkin kehabisan koneksi ke Hologres. Dalam hal ini, Anda dapat menggunakan parameterconnectionPoolName. Parameter ini memungkinkan tabel dengan nama pool koneksi yang sama dalam TaskManager yang sama untuk berbagi koneksi.
Rekomendasi pengembangan pekerjaan.
Dibandingkan dengan DataStream, Flink SQL lebih mudah dirawat dan portabel. Oleh karena itu, kami menyarankan Anda menggunakan Flink SQL untuk mengimplementasikan pekerjaan. Jika bisnis Anda memerlukan DataStream, kami menyarankan Anda menggunakan Hologres DataStream Connector. Untuk informasi lebih lanjut, lihat Hologres DataStream Connector. Untuk mengembangkan pekerjaan DataStream kustom, kami menyarankan Anda menggunakan Holo Client alih-alih JDBC. Metode pengembangan pekerjaan yang direkomendasikan diberi peringkat sebagai berikut:
Flink SQL > Flink DataStream (connector) > Flink DataStream (holo-client) > Flink DataStream (JDBC).Penyelesaian masalah tulis lambat.
Dalam banyak kasus, tulis lambat dapat disebabkan oleh langkah-langkah lain dalam pekerjaan Flink. Anda dapat membagi node pekerjaan Flink dan memeriksa backpressure. Jika backpressure terjadi di sumber data atau di node komputasi kompleks, laju aliran data ke tabel sink Hologres menjadi lambat. Dalam hal ini, Anda harus terlebih dahulu memeriksa peluang optimasi di sisi Flink.
Jika penggunaan CPU instans Hologres tinggi (misalnya, konsisten di 100%) dan latensi tulis juga tinggi, masalah kemungkinan besar ada di sisi Hologres.
Untuk error umum lainnya dan metode troubleshooting, lihat FAQ dan diagnostik Blink dan Flink.
Menyetel Data Integration
Hubungan antara konkurensi dan koneksi.
Di Data Integration, pekerjaan dalam mode wizard menggunakan tiga koneksi per thread konkuren. Untuk pekerjaan dalam mode editor kode, Anda dapat menggunakan parameter
maxConnectionCountuntuk mengonfigurasi jumlah total koneksi untuk tugas, atau parameterinsertThreadCountuntuk mengonfigurasi jumlah koneksi per thread konkuren. Dalam kebanyakan kasus, Anda dapat mencapai performa baik tanpa memodifikasi pengaturan konkurensi dan koneksi. Anda dapat memodifikasinya sesuai kebutuhan.Kelompok sumber daya eksklusif.
Sebagian besar pekerjaan Data Integration memerlukan kelompok sumber daya eksklusif. Spesifikasi kelompok sumber daya eksklusif menentukan batas atas performa tugas. Untuk performa optimal, kami menyarankan satu thread konkuren per core kelompok sumber daya eksklusif. Jika kelompok sumber daya terlalu kecil tetapi konkurensi tugas tinggi, masalah seperti memori JVM tidak mencukupi dapat terjadi. Demikian pula, jika bandwidth kelompok sumber daya eksklusif jenuh, batas atas performa tugas tulis juga terpengaruh. Jika hal ini terjadi, kami menyarankan Anda memecah tugas besar menjadi tugas-tugas kecil dan menugaskannya ke kelompok sumber daya yang berbeda. Untuk informasi lebih lanjut tentang spesifikasi dan metrik kelompok sumber daya eksklusif untuk Data Integration, lihat Metrik performa.
Cara menentukan apakah tulis lambat disebabkan oleh Data Integration, hulu, atau Hologres?
Saat Data Integration menulis ke Hologres, jika waktu tunggu di ujung baca lebih lama daripada waktu tunggu di ujung tulis, penyebabnya biasanya ujung baca yang lambat.
Jika penggunaan CPU instans Hologres tinggi (misalnya, konsisten di 100%) dan latensi tulis juga tinggi, masalah kemungkinan besar ada di sisi Hologres.
Metode penyetelan lanjutan
Metode penyetelan dasar mencakup cara-cara mendasar untuk meningkatkan performa tulis. Jika digunakan dengan benar, metode ini dapat membantu Anda mencapai performa tulis yang sangat baik. Namun, dalam praktiknya, faktor-faktor lain dapat memengaruhi performa, seperti pengaturan indeks dan distribusi data. Metode penyetelan lanjutan yang dijelaskan dalam bagian ini membangun di atas metode dasar. Metode ini menjelaskan cara lebih lanjut untuk memecahkan masalah dan meningkatkan performa tulis. Metode ini cocok untuk pengguna yang memiliki pemahaman lebih mendalam tentang prinsip Hologres.
Tulis lambat yang disebabkan oleh data skew.
Jika data miring atau kunci distribusi diatur tidak tepat, sumber daya komputasi instans Hologres dapat menjadi miring. Kondisi ini mencegah pemanfaatan sumber daya secara efisien dan memengaruhi performa tulis. Untuk informasi tentang cara memeriksa data skew dan menyelesaikan masalah terkait, lihat Lihat hubungan skew Worker.
Tulis lambat yang disebabkan oleh segment key yang tidak tepat.
Saat Anda menulis ke tabel berorientasi kolom, segment key yang tidak tepat dapat sangat menurunkan performa tulis. Penurunan performa menjadi lebih terlihat seiring peningkatan volume data dalam tabel. Hal ini karena segment key digunakan untuk membagi file dasar. Selama tulis atau pembaruan, Hologres mencari data lama berdasarkan primary key. Untuk tabel berorientasi kolom, operasi pencarian ini memerlukan segment key untuk dengan cepat menemukan file dasar tempat data berada. Jika tabel berorientasi kolom tidak memiliki segment key, segment key diatur ke bidang yang tidak tepat, atau data dalam bidang segment key tidak memiliki korelasi kuat dengan waktu tulis (misalnya, sebagian besar tidak berurutan), pencarian perlu memindai jumlah file yang sangat besar. Proses ini tidak hanya melibatkan banyak operasi I/O tetapi juga mengonsumsi banyak CPU. Hal ini memengaruhi performa tulis dan beban seluruh instans. Dalam kasus ini, metrik
IO Throughputdi halaman pemantauan di konsol menunjukkan nilaiReadyang tinggi, meskipun beban kerja terutama terdiri dari pekerjaan tulis.Oleh karena itu, kami menyarankan Anda menggunakan bidang timestamp atau tanggal sebagai segment key. Pastikan data dalam bidang ini memiliki korelasi kuat dengan waktu tulis.
Tulis lambat yang disebabkan oleh clustering key yang tidak tepat
Saat tabel memiliki primary key (PK), Hologres mencari data lama berdasarkan primary key selama tulis atau pembaruan.
Untuk tabel berorientasi baris, jika clustering key berbeda dari PK, operasi pencarian perlu dilakukan dua kali: sekali menggunakan indeks PK dan sekali menggunakan indeks clustering key. Perilaku ini meningkatkan latensi tulis. Oleh karena itu, untuk tabel berorientasi baris, kami menyarankan Anda menjaga clustering key dan PK tetap sama.
Untuk tabel berorientasi kolom, pengaturan clustering key terutama memengaruhi performa kueri, bukan performa tulis. Anda dapat mengabaikan pengaturan ini untuk saat ini.