Setelah mengimpor volume besar data offline atau menjalankan banyak operasi delete atau update, fragmentasi file data dapat menurunkan performa baca dan tulis. Dalam kasus seperti ini, Anda dapat menjalankan operasi compaction. Compaction menggabungkan beberapa file data menjadi satu file yang lebih besar, sehingga menyusun ulang struktur penyimpanan data untuk meningkatkan efisiensi baca dan tulis. Topik ini menjelaskan cara melakukan compaction di Hologres.
Informasi latar belakang
Hologres menggunakan struktur data yang mirip dengan LSM-Tree untuk penulisan data. Semua data ditulis ke penyimpanan secara append-only. Struktur ini mengubah penulisan acak menjadi penulisan berurutan, sehingga mengoptimalkan throughput tulis. File data harus digabung melalui compaction menjadi file yang lebih besar.
Hologres mendukung dua jenis compaction:
Auto Compaction
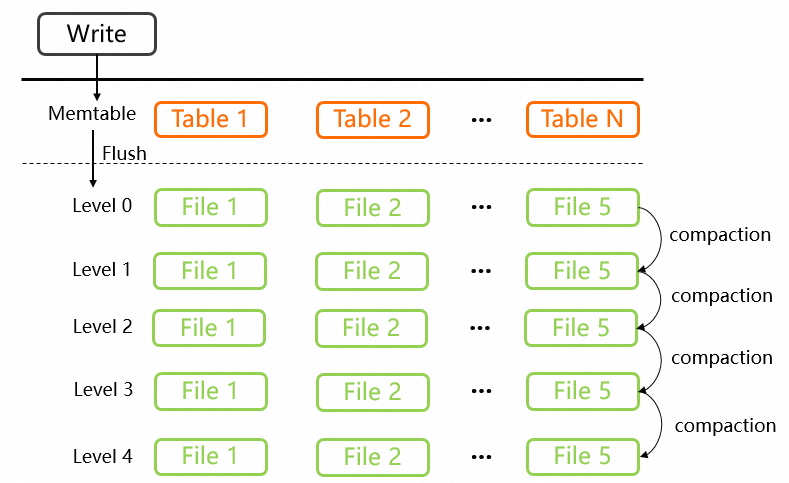
Hologres menerapkan auto compaction hierarkis hingga lima level. Saat suatu level berisi lebih dari lima file, compaction akan dipicu secara otomatis. File hasil penggabungan tersebut dipindahkan ke level berikutnya. Misalnya, ketika Level 0 mencapai lima file, file-file tersebut akan digabung secara otomatis. File hasil penggabungan memiliki ukuran maksimum default 64 MB. Jika melebihi 64 MB, beberapa file akan dibuat dan dipindahkan ke Level 1, seperti yang ditunjukkan pada gambar berikut:
Full Compaction
Auto compaction hanya menggabungkan file dalam level yang sama dan tidak pernah lintas level. Full compaction menggabungkan semua file dari seluruh level menjadi file baru, masing-masing dengan ukuran maksimum default 64 MB, yang ditempatkan di level terakhir.
Batasan
Hanya Hologres V2.1 dan versi yang lebih baru yang mendukung pemicuan manual full compaction. Jika instans Anda menjalankan versi sebelumnya, Anda dapat meng-upgrade instans Anda atau bergabung dengan kelompok pengguna Hologres untuk meminta peningkatan. Untuk detailnya, lihat Bagaimana cara mendapatkan dukungan online lebih lanjut?
Hanya tabel berorientasi kolom dan tabel hybrid baris-kolom yang mendukung full compaction manual.
Untuk tabel hybrid baris-kolom, full compaction hanya berlaku pada bagian column store.
Penggunaan
Skenario:
Anda dapat memicu full compaction secara manual dalam skenario berikut untuk menggabungkan file kecil dan meningkatkan performa kueri:
Setelah mengimpor volume besar data offline.
Setelah menjalankan banyak operasi
deleteatauupdate.
CatatanFull compaction mengonsumsi sumber daya I/O dan CPU yang signifikan. Disarankan untuk menjalankannya pada periode dengan aktivitas tulis rendah. Eksekusi biasanya memerlukan waktu lebih dari 10 menit.
Sintaks:
SELECT hologres.hg_full_compact_table( '<schema_name.table_name>' [,'max_file_size_mb=<value>'] );Deskripsi:
Nama Parameter
Deskripsi
Wajib
Default
schema_name.table_name
Nama tabel yang akan dikompaksi.
Ya
Tidak ada
max_file_size_mb
(Jangan ubah nilai ini kecuali benar-benar diperlukan.) Ukuran maksimum dalam
MBuntuk file yang dihasilkan setelah full compaction. Nilainya harus berupa bilangan bulat positif.Mengatur nilai ini terlalu rendah akan menghasilkan terlalu banyak file, yang memperlambat kueri.
Tidak
64
Contoh:
Anda dapat menjalankan full compaction pada tabel
public.lineitem:SELECT hologres.hg_full_compact_table( 'public.lineitem');Anda dapat menjalankan full compaction pada tabel
public.lineitemdan mengatur ukuran maksimum file output menjadi 256 MB:SELECT hologres.hg_full_compact_table( 'public.lineitem', 'max_file_size_mb=256' );
Jalankan compaction menggunakan Serverless Computing
Lihat Jalankan tugas compaction menggunakan Serverless Computing.