Anda dapat menggunakan fitur pemrosesan vektor Hologres dalam berbagai skenario, seperti pencarian kemiripan, pengambilan citra, dan pengenalan wajah. Fitur ini memungkinkan Anda meningkatkan pemrosesan dan analisis data serta menerapkan pencarian dan rekomendasi yang lebih akurat. Topik ini menjelaskan cara menggunakan Proxima untuk melakukan pemrosesan vektor di Hologres dan menyediakan contoh terkait.
Prosedur
Hubungkan ke instans Hologres.
Gunakan alat pengembangan untuk menghubungkan ke instans Hologres. Untuk informasi selengkapnya, lihat Ikhtisar. Jika Anda menggunakan driver Java Database Connectivity (JDBC) untuk menghubungkan ke instans Hologres, Anda harus menggunakan prepared statement.
Instal ekstensi Proxima.
Proxima terhubung ke Hologres sebagai ekstensi. Anda harus mengeksekusi pernyataan berikut untuk menginstal ekstensi Proxima sebagai superuser:
-- Instal ekstensi Proxima. CREATE EXTENSION proxima;Ekstensi Proxima bekerja pada tingkat database. Anda hanya perlu menginstalnya sekali untuk setiap database. Untuk menghapus ekstensi tersebut, eksekusi pernyataan berikut:
DROP EXTENSION proxima;PentingKami menyarankan agar Anda tidak mengeksekusi pernyataan
DROP EXTENSION <extension_name> CASCADE;untuk menghapus ekstensi. Pernyataan CASCADE tidak hanya menghapus ekstensi yang ditentukan, tetapi juga data ekstensi dan objek yang bergantung pada ekstensi tersebut. Data ekstensi mencakup data PostGIS, data bitmap roaring, data Proxima, data log biner, dan data BSI. Objek-objek tersebut mencakup metadata, tabel, tampilan, dan data server.Buat tabel vektor dan konfigurasikan indeks vektor.
Di Hologres, vektor merupakan array elemen FLOAT4. Untuk membuat tabel vektor, gunakan sintaks berikut.
CatatanIndeks vektor hanya didukung di tabel berorientasi kolom dan tabel hibrida baris-kolom.
Saat mendefinisikan vektor, Anda harus mengatur dimensi array menjadi
1. Parameter input kedua dariarray_ndimsdanarray_lengthharus diatur menjadi1.Di Hologres V2.0.11 dan versi yang lebih baru, Anda dapat mengimpor data sebelum membangun indeks vektor. Anda tidak perlu membangun indeks vektor untuk file dalam proses kompaksi. Hal ini mengurangi waktu pembuatan indeks.
Anda dapat membangun indeks vektor sebelum mengimpor data dalam skenario pemrosesan data real-time.
-- Konfigurasikan indeks tunggal. BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- Definisikan vektor. ); CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- Bangun indeks untuk bidang vektor. COMMIT; -- Konfigurasikan beberapa indeks. BEGIN; CREATE TABLE t1 ( f1 INT PRIMARY KEY, f2 FLOAT4[] NOT NULL CHECK(array_ndims(f2) = 1 AND array_length(f2, 1) = 4), f3 FLOAT4[] NOT NULL CHECK(array_ndims(f3) = 1 AND array_length(f3, 1) = 4) ); CALL set_table_property( 't1', 'proxima_vectors', '{"f2":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}, "f3":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;Anda dapat mengimpor data sebelum membangun indeks vektor dalam skenario pemrosesan data offline.
CatatanHologres V2.1.17 dan versi yang lebih baru mendukung fitur Serverless Computing. Fitur Serverless Computing cocok untuk skenario di mana Anda ingin mengimpor sejumlah besar data secara offline atau mengkueri sejumlah besar data dari tabel eksternal. Anda dapat menggunakan fitur Serverless Computing untuk melakukan operasi tersebut berdasarkan sumber daya komputasi tanpa server tambahan. Hal ini dapat menghilangkan kebutuhan untuk menyediakan sumber daya komputasi tambahan bagi instans. Ini meningkatkan stabilitas instans dan mengurangi terjadinya kesalahan kehabisan memori (OOM). Anda hanya dikenai biaya untuk sumber daya komputasi tanpa server tambahan yang digunakan oleh tugas. Untuk informasi selengkapnya tentang fitur Serverless Computing, lihat Ikhtisar Serverless Computing. Untuk informasi selengkapnya tentang cara menggunakan fitur Serverless Computing, lihat Panduan Serverless Computing.
-- Konfigurasikan indeks tunggal. BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- Definisikan vektor. ); COMMIT; -- Opsional. Kami menyarankan agar Anda menggunakan fitur Serverless Computing untuk mengimpor sejumlah besar data secara offline dan menjalankan pekerjaan ekstrak, transformasi, dan muat (ETL). SET hg_computing_resource = 'serverless'; -- Impor data. INSERT INTO feature_tb ...; VACUUM feature_tb; -- Buat indeks untuk bidang vektor. CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- Atur ulang konfigurasi. Hal ini memastikan bahwa sumber daya komputasi tanpa server tidak digunakan untuk pernyataan SQL berikutnya. RESET hg_computing_resource;
Tabel berikut menjelaskan parameter dalam sintaks di atas.
Kategori
Parameter
Deskripsi
Contoh
Properti dasar vektor
feature_col
Nama bidang vektor.
feature
array_ndims
Dimensi vektor. Hanya vektor satu dimensi yang didukung.
Buat vektor satu dimensi dengan panjang 4.
feature float4[] check(array_ndims(feature) = 1 and array_length(feature, 1) = 4)array_length
Panjang vektor. Nilai maksimum: 1000000.
Pengaturan indeks vektor
proxima_vectors
Metode pembuatan indeks untuk bidang vektor. Parameter berikut bersarang di bawah parameter ini:
algorithm: algoritma yang digunakan untuk membangun indeks. Satu-satunya nilai yang valid adalah
Graph.distance_method: fungsi perhitungan jarak yang digunakan untuk membangun indeks. Hologres mendukung fungsi perhitungan jarak berikut:
SquaredEuclidean: menghitung jarak Euclidean kuadrat. Fungsi ini memberikan efisiensi kueri tertinggi. Kami menyarankan agar Anda menggunakan fungsi ini. Fungsi ini cocok untuk kueri yang menggunakan
pm_approx_squared_euclidean_distance.Euclidean: menghitung jarak Euclidean. Fungsi ini hanya cocok untuk kueri yang menggunakan
pm_approx_euclidean_distance. Jika Anda menggunakan fungsi perhitungan jarak lainnya, indeks tidak akan digunakan.InnerProduct: menghitung jarak inner-product. Metode perhitungan yang disediakan oleh fungsi ini dikonversi menjadi perhitungan jarak Euclidean di lapisan dasar. Oleh karena itu, fungsi ini menimbulkan overhead komputasi yang tinggi dalam pembuatan indeks dan kueri berbasis indeks serta tidak efisien. Kecuali jika ada persyaratan khusus, kami menyarankan agar Anda tidak menggunakan fungsi ini. Fungsi ini hanya cocok untuk kueri yang menggunakan
pm_approx_inner_product_distance.
build_params: ambang batas yang digunakan untuk membangun indeks. Nilai build_params adalah string JSON yang berisi parameter berikut:
min_flush_proxima_row_count: jumlah minimum baris yang diperlukan dalam bidang vektor tempat Anda ingin membangun indeks saat menulis data ke disk. Kami menyarankan agar Anda mengatur parameter ini ke 1000.
min_compaction_proxima_row_count: jumlah minimum baris yang diperlukan dalam bidang vektor tempat Anda ingin membangun indeks saat menggabungkan data di disk. Kami menyarankan agar Anda mengatur parameter ini ke 1000.
max_total_size_to_merge_mb: ukuran maksimum file yang datanya ingin Anda gabungkan di disk. Satuan: MB. Kami menyarankan agar Anda mengatur parameter ini ke 2000.
proxima_builder_thread_count: jumlah thread yang digunakan untuk membangun indeks vektor selama penulisan data. Nilai default adalah 4. Dalam kebanyakan kasus, Anda tidak perlu mengubah nilainya.
CatatanIndeks memberikan kinerja optimal dalam skenario tertentu.
Gunakan fungsi SquaredEuclidean untuk membangun indeks untuk bidang vektor.
call set_table_property( 'feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph", "distance_method":"SquaredEuclidean", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}');Impor data ke tabel vektor.
Anda dapat mengimpor data ke tabel vektor secara offline atau real-time berdasarkan kebutuhan bisnis Anda.Setelah Anda mengimpor beberapa entri data sekaligus, Anda perlu mengeksekusi pernyataan VACUUM atau ANALYZE untuk meningkatkan efisiensi kueri.
Pernyataan VACUUM mengompaksi beberapa file backend menjadi satu file besar. Hal ini meningkatkan efisiensi kueri vektor. Namun, pernyataan VACUUM mengonsumsi sumber daya CPU. Semakin besar jumlah data di tabel vektor, semakin lama waktu yang diperlukan untuk mengeksekusi pernyataan VACUUM. Setelah mengeksekusi pernyataan VACUUM, tunggu hasil eksekusinya.
VACUUM <tablename>;Pernyataan ANALYZE mengumpulkan statistik untuk membantu Query Optimizer (QO) menghasilkan rencana eksekusi optimal. Hal ini meningkatkan kinerja kueri vektor.
analyze <tablename>;
Kueri data vektor.
Hologres mendukung kueri vektor berdasarkan pencocokan eksak dan pencocokan perkiraan. UDF yang diawali dengan
pm_digunakan untuk melakukan kueri pencocokan eksak. UDF yang diawali denganpm_approx_digunakan untuk melakukan kueri pencocokan perkiraan. Untuk skenario di mana indeks dibangun untuk bidang vektor, kami menyarankan agar Anda menggunakan UDF yang diawali dengan pm_approx_ untuk melakukan kueri pencocokan perkiraan. Dengan cara ini, indeks dapat terkena, dan kinerja kueri tinggi. Kami menyarankan agar Anda menggunakan indeks vektor untuk kueri pada satu tabel saja. Dalam kasus ini, indeks dapat terkena. Indeks vektor tidak disarankan untuk kueri join.Kueri pencocokan perkiraan (menggunakan indeks vektor)
Dalam kueri pencocokan perkiraan, indeks vektor dapat terkena. Kueri pencocokan perkiraan cocok untuk skenario di mana sejumlah besar data perlu dipindai dan efisiensi eksekusi yang tinggi diperlukan. Secara default, tingkat recall lebih dari 99%. Anda dapat menambahkan
approx_sebelum fungsi perhitungan jarak untuk menggunakan indeks vektor. Fungsi contoh:CatatanJika Anda menggunakan fungsi SquaredEuclidean atau Euclidean untuk melakukan kueri pencocokan perkiraan, indeks vektor hanya dapat terkena dalam skenario di mana
order by distance ascditentukan. Urutan menurun tidak didukung.Jika Anda menggunakan fungsi InnerProduct untuk melakukan kueri pencocokan perkiraan, indeks vektor hanya dapat terkena dalam skenario di mana
order by distance descditentukan. Urutan menaik tidak didukung.
FLOAT4 pm_approx_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_inner_product_distance(FLOAT4[], FLOAT4[])Fungsi perhitungan jarak yang Anda gunakan harus konsisten dengan nilai parameter
distance_methoddi bawahproxima_vectoryang ditentukan saat Anda membuat tabel vektor. Eksekusi pernyataan SQL berikut untuk menghitung top K item. Anda harus mengatur parameter kedua dalam pernyataan SQL kueri perkiraan menjadi konstan.CatatanKueri berbasis indeks tidak menjamin presisi 100%. Tingkat recall default lebih dari 99%.
-- Hitung top K item berdasarkan jarak Euclidean kuadrat. Dalam hal ini, Anda harus mengatur parameter distance_method di bawah proxima_vector menjadi SquaredEuclidean dalam pernyataan pembuatan tabel. SELECT pm_approx_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Hitung top K item berdasarkan jarak Euclidean. Dalam hal ini, Anda harus mengatur parameter distance_method di bawah proxima_vector menjadi Euclidean dalam pernyataan pembuatan tabel. SELECT pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Hitung top K item berdasarkan jarak inner product. Dalam hal ini, Anda harus mengatur parameter distance_method di bawah proxima_vector menjadi InnerProduct dalam pernyataan pembuatan tabel. SELECT pm_approx_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;Kueri pencocokan eksak (tanpa menggunakan indeks vektor)
Kueri pencocokan eksak cocok untuk skenario di mana sejumlah kecil data perlu dipindai oleh pernyataan SQL dan tingkat recall yang tinggi diperlukan. Fungsi perhitungan jarak Euclidean, SquaredEuclidean, dan InnerProduct digunakan untuk kueri pencocokan eksak:
FLOAT4 pm_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_inner_product_distance(FLOAT4[], FLOAT4[])Eksekusi pernyataan SQL berikut untuk mengkueri top K tetangga terdekat dari suatu vektor.
CatatanDalam contoh ini, kueri pencocokan eksak digunakan. Dalam proses eksekusi, semua data vektor di kolom fitur dipindai untuk menghitung dan mengurutkan jarak. Hasil 10 pertama dikembalikan. Jenis pernyataan SQL ini cocok untuk skenario di mana jumlah data kecil dan tingkat recall yang tinggi diperlukan.
-- Recall top 10 tetangga terdekat berdasarkan jarak Euclidean kuadrat. SELECT pm_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Recall top 10 tetangga terdekat berdasarkan jarak Euclidean. SELECT pm_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Recall top 10 tetangga dengan inner-product terbesar. SELECT pm_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;
Contoh
Dalam contoh ini, indeks Proxima digunakan untuk mengambil kembali 40 entri data teratas yang memiliki jarak Euclidean kuadrat terpendek dari tabel vektor empat dimensi yang memiliki 0,1 juta entri data.
Buat tabel vektor.
CREATE EXTENSION proxima; BEGIN; -- Buat kelompok tabel dengan jumlah shard 4. CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE feature_tb ( id BIGINT, feature FLOAT4[] CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = 4) ); CALL set_table_property ('feature_tb', 'table_group', 'test_tg_shard_4'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params": {"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;Impor data ke tabel vektor.
-- Opsional. Kami menyarankan agar Anda menggunakan fitur Serverless Computing untuk mengimpor sejumlah besar data secara offline dan menjalankan pekerjaan ETL. SET hg_computing_resource = 'serverless'; INSERT INTO feature_tb SELECT i, ARRAY[random(), random(), random(), random()]::FLOAT4[] FROM generate_series(1, 100000) i; ANALYZE feature_tb; VACUUM feature_tb; -- Atur ulang konfigurasi. Hal ini memastikan bahwa sumber daya komputasi tanpa server tidak digunakan untuk pernyataan SQL berikutnya. RESET hg_computing_resource;Kueri data dari tabel vektor.
-- Opsional. Kami menyarankan agar Anda menggunakan fitur Serverless Computing untuk menjalankan pekerjaan kueri berbasis vektor di mana sejumlah besar data dikueri. SET hg_computing_resource = 'serverless'; SELECT pm_approx_squared_euclidean_distance (feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance LIMIT 40; -- Atur ulang konfigurasi. Hal ini memastikan bahwa sumber daya komputasi tanpa server tidak digunakan untuk pernyataan SQL berikutnya. RESET hg_computing_resource;
Optimalkan kinerja
Buat indeks untuk bidang vektor
Jika tabel vektor memiliki jumlah data kecil, seperti puluhan ribu entri data, kami menyarankan agar Anda menghitung data tanpa membuat indeks. Jika instans Anda memiliki sumber daya yang cukup dan jumlah data yang ingin Anda kueri kecil, Anda juga dapat langsung menghitung data. Jika perhitungan langsung tidak memenuhi kebutuhan Anda, seperti kebutuhan mengenai latensi dan throughput, Anda dapat menggunakan indeks Proxima. Perhatikan hal-hal berikut:
Indeks Proxima adalah indeks lossy dan tidak menjamin akurasi hasil perhitungan. Artinya, jarak yang Anda hitung mungkin tidak akurat.
Jika Anda menggunakan indeks Proxima, jumlah entri data yang dikembalikan mungkin lebih sedikit daripada jumlah yang diharapkan. Misalnya, Anda menggunakan indeks Proxima dan menentukan
limit 1000dalam pernyataan SQL, tetapi hanya 500 entri data yang dikembalikan.Indeks Proxima tidak mudah digunakan.
Tentukan jumlah shard yang sesuai
Semakin besar jumlah shard, semakin banyak file yang dihasilkan saat indeks Proxima dibangun, dan semakin rendah throughput kueri. Oleh karena itu, kami menyarankan agar Anda menentukan jumlah shard yang sesuai berdasarkan sumber daya instans Anda. Dalam kebanyakan kasus, Anda dapat mengatur jumlah shard sama dengan jumlah node pekerja. Misalnya, Anda dapat mengatur jumlah shard menjadi 4 untuk instans dengan 64 core. Jika Anda ingin mengurangi latensi kueri tunggal, Anda dapat mengurangi jumlah shard. Namun, operasi ini menurunkan kinerja penulisan.
-- Buat tabel vektor dalam kelompok tabel dengan jumlah shard 4. BEGIN; CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE proxima_test ( id BIGINT NOT NULL, vectors FLOAT4[] CHECK (array_ndims(vectors) = 1 AND array_length(vectors, 1) = 128), PRIMARY KEY (id) ); CALL set_table_property ('proxima_test', 'proxima_vectors', '{"vectors":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params":{}, "searcher_init_params":{}}}'); CALL set_table_property ('proxima_test', 'table_group', 'test_tg_shard_4'); COMMIT;(Disarankan) Lakukan kueri tanpa menggunakan kondisi filter
Jika Anda menggunakan kondisi filter
where, kinerja indeks akan terpengaruh negatif. Kami menyarankan agar Anda melakukan kueri tanpa menggunakan kondisi filter. Untuk kueri tanpa menggunakan kondisi filter, kasus idealnya adalah setiap shard hanya memiliki satu file indeks. Dalam kasus ini, setiap kueri dapat dilakukan pada shard tertentu.Sintaks pembuatan tabel berikut biasanya digunakan untuk melakukan kueri tanpa menggunakan kondisi filter:
BEGIN; CREATE TABLE feature_tb ( uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) -- Definisikan vektor. ); CALL set_table_property ('feature_tb', 'shard_count', '?'); -- Tentukan jumlah shard berdasarkan kebutuhan bisnis Anda. Anda juga dapat mempertahankan jumlah shard default. CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}'); -- Buat indeks untuk bidang vektor. END;Lakukan kueri dengan menggunakan kondisi filter
Jika Anda melakukan jenis kueri ini, Anda dapat mengonfigurasi kondisi filter dengan salah satu metode berikut:
Metode 1: Konfigurasikan string sebagai kondisi filter
Anda dapat mengonfigurasi string sebagai kondisi filter jika ingin mengkueri data vektor suatu organisasi, seperti mengkueri data wajah suatu kelas. Pernyataan contoh:
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE uuid = 'x' ORDER BY d limit 10;Kami menyarankan agar Anda mengoptimalkan pernyataan dengan melakukan operasi berikut:
Konfigurasikan identifier unik universal (UUID) sebagai kunci distribusi tabel vektor. Dengan cara ini, data duplikat yang dikembalikan disimpan di shard yang sama, dan setiap kueri hanya dilakukan pada satu shard.
Konfigurasikan UUID sebagai kunci pengelompokan tabel vektor. Dengan cara ini, data yang dikembalikan diurutkan dalam file berdasarkan kunci pengelompokan.
Metode 2: Konfigurasikan bidang waktu sebagai kondisi filter
Anda dapat mengonfigurasi bidang waktu sebagai kondisi filter jika ingin memfilter data vektor berdasarkan bidang waktu. Kami menyarankan agar Anda mengonfigurasi bidang waktu time_field sebagai kunci segmen tabel vektor untuk dengan cepat menemukan file tempat entri data tertentu berada. Pernyataan contoh:
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE time_field BETWEEN '2020-08-30 00:00:00' AND '2020-08-30 12:00:00' ORDER BY d limit 10;
Sintaks pembuatan tabel berikut biasanya digunakan untuk melakukan kueri berdasarkan kondisi filter:
BEGIN; CREATE TABLE feature_tb ( time_field timestamptz NOT NULL, uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) ); CALL set_table_property ('feature_tb', 'distribution_key', 'uuid'); CALL set_table_property ('feature_tb', 'segment_key', 'time_field'); CALL set_table_property ('feature_tb', 'clustering_key', 'uuid'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); COMMIT; -- Jika Anda tidak memfilter data berdasarkan waktu, Anda dapat menghapus indeks yang terkait dengan time_field.
Tanya Jawab Umum
Apa yang harus saya lakukan jika pesan kesalahan berikut dikembalikan:
ERROR: function pm_approx_inner_product_distance(real[], unknown) does not exist?Penyebab: Pernyataan
create extension proxima;tidak dieksekusi di database untuk menginisialisasi Plugin Proxima.Solusi: Eksekusi pernyataan
create extension proxima;untuk menginisialisasi Plugin Proxima.Apa yang harus saya lakukan jika pesan kesalahan berikut dikembalikan:
Writing column: feature with array size: 5 violates fixed size list (4) constraint declared in schema?Penyebab: Dimensi data yang ditulis ke bidang vektor karakteristik berbeda dari dimensi yang didefinisikan untuk bidang vektor di tabel.
Solusi: Periksa apakah ada data kotor.
Apa yang harus saya lakukan jika pesan kesalahan berikut dikembalikan:
The size of two arrays must be the same in DistanceFunction, size of left array: 4, size of right array:?Penyebab: Dalam fungsi
pm_xx_distance(left, right), dimensi variabel kiri berbeda dari dimensi variabel kanan.Solusi: Ubah dimensi variabel kiri agar sama dengan dimensi variabel kanan dalam fungsi
pm_xx_distance(left, right).Apa yang harus saya lakukan jika pesan kesalahan berikut dikembalikan selama penulisan data real-time:
BackPresure Exceed Reject Limit ctxId: XXXXXXXX, tableId: YY, shardId: ZZ?Penyebab: Pekerjaan penulisan real-time mengalami bottleneck, dan terjadi kesalahan tekanan balik. Overhead yang ditimbulkan oleh pekerjaan tersebut tinggi, dan operasi penulisan memakan waktu lama. Dalam kebanyakan kasus, masalah ini terjadi karena min_flush_proxima_row_count diatur ke nilai kecil tetapi laju input real-time tinggi. Akibatnya, overhead yang ditimbulkan oleh pekerjaan untuk membangun indeks meningkat, dan pekerjaan menjadi macet.
Solusi: Atur min_flush_proxima_row_count ke nilai yang lebih besar.
Bagaimana cara menulis data ke bidang vektor dalam Java?
Blok kode berikut memberikan contoh cara menulis data ke bidang vektor dalam Java:
private static void insertIntoVector(Connection conn) throws Exception { try (PreparedStatement stmt = conn.prepareStatement("insert into feature_tb values(?,?);")) { for (int i = 0; i < 100; ++i) { stmt.setInt(1, i); Float[] featureVector = {0.1f,0.2f,0.3f,0.4f}; Array array = conn.createArrayOf("FLOAT4", featureVector); stmt.setArray(2, array); stmt.execute(); } } }Bagaimana cara memeriksa apakah indeks Proxima digunakan berdasarkan rencana eksekusi?
Jika
Proxima filter: xxxxada dalam rencana eksekusi, indeks digunakan, seperti yang ditunjukkan pada gambar berikut. Jika tidak, indeks tidak digunakan. Dalam kebanyakan kasus, hal ini disebabkan oleh ketidaksesuaian antara pernyataan pembuatan tabel dan pernyataan kueri.
Fungsi perhitungan jarak
Hologres mendukung fungsi berikut yang digunakan untuk menghitung jarak vektor:
Fungsi SquaredEuclidean menggunakan rumus perhitungan berikut.
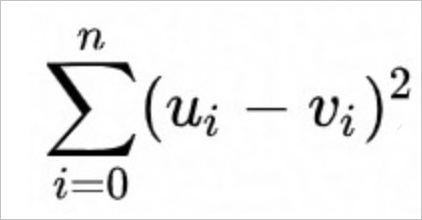
Fungsi Euclidean menggunakan rumus perhitungan berikut.
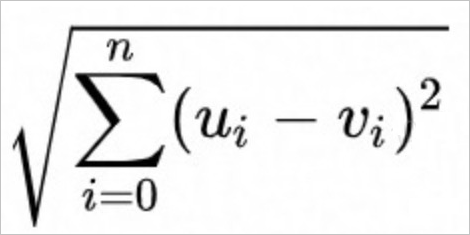
Fungsi InnerProduct menggunakan rumus perhitungan berikut.
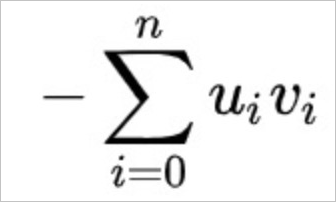
Sebagai contoh, Anda menggunakan fungsi Euclidean atau SquaredEuclidean untuk melakukan pemrosesan vektor. Dibandingkan dengan fungsi Euclidean, fungsi SquaredEuclidean tidak perlu mengekstrak akar kuadrat untuk mendapatkan top K item yang sama seperti fungsi Euclidean. Oleh karena itu, fungsi SquaredEuclidean memberikan kinerja yang lebih tinggi. Jika persyaratan fitur terpenuhi, kami menyarankan agar Anda menggunakan fungsi SquaredEuclidean.